
Research Data Management
- File Formats
- About Research Data Management
- Data Management Plans
- Organization and File Names
- Storage and Backup
- File Versioning
- Documentation and Metadata
- Data Citations
- Human Subjects Data
- Data Sharing Methods
- Data Archives and Repositories
- Resources at Duke
Contact us at datamanagement @ duke (dot) edu or attend one of our data management workshops .

File Formats for Preservation and Reuse
File formats can affect long-term preservation and reuse. While researchers may use proprietary file formats for analysis, converting data to open and/or standard formats will help ensure the data can be rendered and accessed in the future. Researchers can also chose to make data available in both preservation-friendly formats and original file formats.
Best practice suggests selecting formats that are open/documented standards, non-proprietary, unencrypted, uncompressed, and commonly used by your research community. For example, when you have spreadsheet-based (aka tabular) data save the file as Comma-separated values (.csv) instead of Excel (.xls, .xlsx) and for text files use Plain text (.txt) or PDF/A (.pdf) instead of Microsoft Word (.doc, .docx).
Repositories may provide a list of preferred files formats (see Dryad’s File Types Guidance ). The Library of Congress also provides information on recommended file formats.
Common Data Formats
The definition of what "data" are varies by discipline. In some fields, a published article or report could be considered data, but in others, the "bones" of that article - the data behind figures, tables, graphics, and other conclusions - are what could be considered data. If a research funding agency requires a formal Data Management Plan, they will often provide some guidance as to what they would consider data.
| Text | Hand-written, docx, wpd, odt, rtf, txt, html, xml, pdf | , , |
| Tabular Simple (minimal metadata) | csv, tsv, pipe-delimited, xls(x), ods, dif, xps | |
| Tabular Extensive | sav (SPSS), sas7bdat or xpt (SAS), dta (STATA) | csv, txt with or associated script (r or m) |
| Database | mdb, dbf, sql, sqlite, db, db3, xml | xml, |
| Visual | static: pdf, jpeg, tiff, png, gif, bmp, moving: mpeg, mov, avi, mxf | PDF/A, , |
| Audio | wav(e), mp3, mp2, aiff, wma, aac, dct, flac, ogg, |
For more, see the UK Data Service Recommended Formats or the Recommended Formats Statement of the Library of Congress
- << Previous: Documentation and Metadata
- Next: Data Citations >>
- Last Updated: Jan 11, 2024 11:23 AM
- URL: https://guides.library.duke.edu/research-data-management

Services for...
- Faculty & Instructors
- Graduate Students
- Undergraduate Students
- International Students
- Patrons with Disabilities
- Harmful Language Statement
- Re-use & Attribution / Privacy
- Support the Libraries

The Research Data Management Workbook
Chapter 3 file organization and naming.
Good file organization and naming are foundational data management practices, as they help you find files quickly when you need them. To set up file organization and naming conventions, this chapter offers two exercises: a card-sorting process for brainstorming a file organization system; and a worksheet for creating a file naming convention for a group of files.
3.1 Set Up a File Organization System
Description: Implementing a file organization system is the first step toward creating order for your research data. Well-organized files make it easier to find the data you need without spending lots of time searching your computer. Every researcher organizes their files slightly differently, but the actual organizational system is less important that having a place where all of your files should logically go. This exercise prompts you to brainstorm organizational groupings and hierarchies to come up with an order for managing your research data.
Instructions: This is a card-sorting exercise, meaning you will need a stack of note cards or post-it notes to do this activity, ideally in three different colors. Follow the instructions to label cards and move them around until you develop your organizational system. There is no one correct way to do this so feel free to play around, add new cards, and move cards however you want! Once you put your new organizational system into place, be sure to always put your files where they’re supposed to go.

Example of organizational exercise. Image is of blue group folders (text in [] brackets), pink single folders (text in “” quotes), and yellow file types (regular text) sticky notes, each with its own label, organized hierarchically on a wooden desktop.
- Analyzed data
- Article drafts
- My publications
- Literature PDFs
- Grant documents
- Research notes
- Move cards around and group together file-type cards that you want to store together. Files that will be stored near each other in a folder hierarchy, but not together, should be placed near each other while file types expected to be stored completely separately should be away from other cards.
- Cards in the second color represent a single folder. These should be labeled with the folder name in quotations (e.g. “Literature” or “My publications”).
- Cards in the third color represent a group of folders, such as for folders organized by date or by project. Use only one card to represent the organizational pattern that will be repeated. These cards should be labeled with the organizational system in square brackets (e.g. [By date] or [By project]). Note: folders organized by date should, in real life, be labelled using the convention YYYYMMDD or YYYY-MM-DD to facilitate chronological sorting.
- Move existing file-type cards/groups of file-type cards underneath the new folder cards to show the hierarchy of how a file type will be saved in a specific folder or group of folders. Organizational-group folders (cards in the third color) only need to be represented once in the card sorting, as they are assumed to represent multiple folders on a computer.
- Make copies of any type of card and add folder levels, as needed. Adjust placement and hierarchies until you are happy with the organizational system you developed.
- Record your organizational system in your lab notebook and/or a README.txt .
3.2 Create a File Naming Convention
Description: File naming conventions are a simple way to add order to your files and help to find them later. Rich and descriptive file names make it easier to search for files, understand at a glance what they contain, and tell related files apart. This exercise guides researchers through the process of creating a file naming convention for a group of related files.
Instructions: Fill in each section for a group of related files following the instructions; an example for microscopy files is provided. This exercise may be redone as needed, as different groups of files require different naming conventions.
Source: This exercise is based on the “File Naming Convention Worksheet” ( K. A. Briney, 2020a ) .

Screenshot of article pdf’s in a file system with consistent file names. File names use the convention FirstAuthorLastName_YEAR_ShortTitle.pdf
1. What group of files will this naming convention cover?
You can use different conventions for different file sets.
Example: This convention will apply to all of my microscopy files, from raw image through processed image.
2. What information (metadata) is important about these files and makes each file distinct?
Ideally, pick three pieces of metadata; use no more than five. This metadata should be enough for you to visually scan the file names and easily understand what’s in each one.
Example: For my images, I want to know date, sample ID, and image number for that sample on that date.
3. Do you need to abbreviate any of the metadata or encode it?
If any of the metadata from step 2 is described by lots of text, decide what shortened information to keep. If any of the metadata from step 2 has regular categories, standardize the categories and/or replace them with 2- or 3-letter codes; be sure to document these codes.
Example: Sample ID will use a code made up of: a 2-letter project abbreviation (project 1 = P1, project 2 = P2); a 3-letter species abbreviation (mouse = “MUS,” fruit fly = “DRS”); and 3-digit sample ID (assigned in my notebook).
4. What is the order for the metadata in the file name?
Think about how you want to sort and search for your files to decide what metadata should appear at the beginning of the file name. If date is important, use ISO 8601-formatted dates (YYYYMMDD or YYYY-MM-DD) at the beginning of the file names so dates sort chronologically.
Example: My sample ID is most important so I will list it first, followed by date, then image number.
5. What characters will you use to separate each piece of metadata in the file name?
Many computer systems cannot handle spaces in file names. To make file names both computer- and human-readable, use dashes (-), underscores (_), and/or capitalize the first letter of each word in the file names. A good convention is to use underscores to separate unrelated pieces of metadata and dashes to separate related pieces of metadata for parsing and readability.
Example: I will use underscores to separate metadata and dashes between parts of my sample ID.
6. Will you need to track different versions of each file?
You can track versions of a file by appending version information to end of the file name. Consider using a version number (e.g. “v01”) or the version date (use ISO 8601 format: YYYYMMDD or YYYY-MM-DD).
Example: As each image goes through my analysis workflow, I will append the version type to the end of the file name (e.g. “_raw,” “_processed,” and “_composite”).
7. Write down your naming convention pattern.
Make sure the convention only uses alphanumeric characters, dashes, and underscores. Ideally, file names will be 32 characters or less.
Example: My file naming convention is “SA-MPL-EID_YYYYMMDD_###_status.tif” Examples are “P1-MUS-023_20200229_051_raw.tif” and “P2-DRS-285_20191031_062_composite.tif.”
8. Document this convention in a README.txt (or save this worksheet) and keep it with your files.
The Writing Guide
- The First Thing
- Step 1: Understanding the essay question
- Step 2: Critical note-taking
- Step 3: Planning your assignment
- Step 4a: Effective writing
- Step 4b: Summarizing & paraphrasing
- Step 4c: Academic language
- Step 5: Editing and reviewing
- Getting started with research
- Working with keywords
- Evaluating sources
- Research file
What's a research file?
The cornell method of critical note-taking, tools for creating research files.
- Reading Smarter
- Sample Essay
- What, why, where, when, who?
- Referencing styles
- Writing Resources
- Exams and Essay Questions
Keep notes of your research process!
A research file could be a word document, or a notebook, or a pile of paper in a folder, or a program like EverNote or OneNote, or a bibliographic software like EndNote. It's simply a place were you keep notes about the things you found.
Taking notes about your research is something that can save your sanity.
Be kind to your future self:
- Copy and paste your search strings (especially the ones that gave good results) into a document, and note what databases gave you the best results (you may have to go looking again).
- Every time you find something that seems even remotely interesting, make a note about it so you can go back to it later. This will help you in the wee hours of the morning when you are desperately trying to remember where you read something.
- Remember, if you are using someone else's information, y ou have to cite it . If you can't cite it you can't use it - so take notes on who said what.
The simplest (and best) thing you can do is always note the core referencing details whenever you read something, and leave a few notes to remind yourself what it was about (and take note of anything that stuck out - even if you didn't think it was particularly useful to you at the time). You will almost certainly find yourself trying to remember it in the middle of the night when you need to get your assignment finished.
Remember the Cornell Method of note-taking we talked about in Step 2 of the Writing Process? This template encourages you to take critical notes when reading journal articles, course readings and text book chapters - and keep the citation details with your notes.
- Cornell Method Template This simple description explains the purpose and layout of the Cornell method of note-taking
- Cornell Method Template with Critical Questions
- OneDrive Use your JCU email account to access 7GB of online cloud-based file storage
- Dropbox Bring your photos, docs and videos anywhere
- Evernote Evernote's "Basic" plan is free, and allows you to keep snippets of websites you are looking at along with notes of various kinds.
- Diigo Collect and highlight and then remember
- Endnote EndNote is a bibiographic software tool that allows you to keep copies of your documents inside records that also contain all of the information you need to cite that document, and notes that you have made about it. It can also be used to construct your references. It is not a "magic bullet", and you shouldn't use it for your referencing until you are comfortable with referencing on your own so you can see when you need to fix things. We recommend only using the referencing side of things from 2nd Year onwards.
- << Previous: Evaluating sources
- Next: Reading Smarter >>
- Last Updated: Jul 12, 2024 4:02 PM
- URL: https://libguides.jcu.edu.au/writing


How To Search Google By Filetype
Updated: June 9, 2023.
Discover how to search Google by filetype and improve your search skills.
In this article, I’ll show you how to search Google by filetype . This technique is useful for anyone who needs to find specific filetypes like PDFs, Word documents, or spreadsheets, including SEO professionals and researchers.
My goal is to help you become familiar with Google’s filetype search operator to allow you to find the resources you need more easily and efficiently.

Search Google by filetype: TL;DR
To search Google by filetype , you simply need to use the filetype: search operator together with your query. This will filter the results to only show the file type you specified. The most common file types include PDF, PPT, DOC, TXT, & XSL.

To learn more about this type of search, I encourage you to read the entire article (below).
How to search Google by filetype
Here is all you need to know about searching Google for file types, tips, and practical examples.
Google’s filetype search operator
The filetype : search operator lets you narrow down your search results on Google by specifying the desired file format. Thanks to this operator, you can filter the results to show only specific file types, which makes it simpler to locate the resources you’re seeking.
To use the filetype search operator, just type filetype: followed by the required file extension in your Google search query.
For instance, if you want to search for PDF files containing SEO strategies, your search query would be:
SEO strategies filetype:pdf

Together with the filetype: search operator, you can also use other Google search operators to further narrow down your search.
Examples of file types to search for
Google can index an extensive range of filetypes .
Here are examples of using the filetype: search operator to look for specific file types in Google.
- PDF files (Adobe Portable Document Format) – Search for ebooks or whitepapers on link-building strategies:
- PPT or PPTX files (Microsoft PowerPoint) – Find presentations on on-page optimization techniques:
- DOC or DOCX files (Microsoft Word) – Look for articles, guides, or checklists about keyword research:
- XLS or XLSX files (Microsoft Excel) – Locate spreadsheets or datasets on domain authority and page authority:
- ODP files (OpenOffice Presentation) – Discover presentations on SEO audit best practices:
- ODS files (OpenOffice Spreadsheet) – Search for spreadsheets on backlink analysis:
- ODT files (OpenOffice Text) – Find comprehensive guides on mobile SEO optimization:
- RTF files (Rich Text Format) – Look for resources on local SEO tactics:
- SVG files (Scalable Vector Graphics) – Search for visual representations of SEO ranking factors:
- TEX files (TeX/LaTeX) – Discover academic papers or research on search engine algorithms:
- TXT files (Text) – Find plain text resources on SEO content writing tips:
- XML files (XML) – Search for sitemap files for well-structured websites in your niche:
site:example.com sitemap filetype:xml
Tips & tricks for filetype searching on Google
To maximize your filetype search results, try combining the filetype operator with other search operators and strategies:
- Use multiple filetypes in one query: To search for multiple filetypes simultaneously, use the “OR” operator in your query. For example, SEO strategies filetype:pdf OR filetype:doc .

- Combine with other search operators: Enhance your filetype search by incorporating other search operators, such as quotes for exact phrases ( "SEO strategies" filetype:pdf ) or site: to search within specific websites ( site:example.com SEO filetype:pdf ).
- If you’re looking for a PDF guide on optimizing title tags for SEO, instead of using a general query like SEO filetype:pdf , use a more specific query like title tag optimization guide filetype:pdf .
- When searching for an Excel spreadsheet with a list of SEO tools, rather than using a broad query like SEO tools filetype:xls , opt for a more targeted query like SEO tools list filetype:xls OR filetype:xlsx .
- Utilize advanced search settings: Make use of Google’s advanced search settings to further filter and refine your search results, such as searching within a date range or language. If you want to find recent PowerPoint presentations on voice search optimization, go to Google’s advanced search settings, and specify a date range (e.g., within the last year). Alternatively, you can use a query like seo audit filetype:ppt OR filetype:pptx after:2020-01-08.

- Search within specific domains: Use the site: operator to search for filetypes within particular websites or domains to find niche-specific content ( site:example.com filetype:pdf ).

- Try alternative file extensions: Some filetypes may have alternative extensions (e.g., .jpg and .jpeg for images). Include them in your search to find more results.
- Experiment with filetype variations : When searching for a specific resource, try different filetypes, as the content you’re seeking may be available in multiple formats (e.g., PDF, DOC, PPT).
- Use search terms related to the desired filetype: When searching for a specific filetype, include search terms that are commonly associated with that filetype (e.g., ‘template’ when searching for spreadsheets, or ‘infographic’ for images).
Check similar guides:
- How To Exclude A Website From Google Search
- How To Exclude Words From Google Search Results
- Bing Search Operators
Real-life examples of doing filetype search on Google
Let’s consider a few real-life examples to help you better understand how to utilize filetype searching for your SEO efforts:
1. Google filetype search for competitor analysis
Suppose you want to analyze the content strategy of a competitor website. Using filetype search, you can quickly find resources like eBooks, presentations, or checklists they’ve created, which might provide valuable insights into their approach. For instance, you can use the following query:
2. Google filetype search to discover SEO templates and resources
When you’re looking for readily available templates or resources to help with your SEO projects, filetype search can come in handy. For example, if you want to find a content calendar template in an Excel format, you can use the following query:

3. Google filetype search to find industry-specific research papers
If you want to find research papers on a specific topic within the SEO industry, filetype searching can make it easier to locate the resources you need. For example, if you want to find research papers on Google patents, you can use the following query:
4. Google filetype search to identify visual assets
File type search can help you find visual assets, such as infographics or diagrams, that can enhance your SEO-related content. For example, if you’re looking for an infographic on link-building strategies, you can use the following query:
By experimenting with different file types and search techniques, you can make the most of your search efforts and gather valuable resources to improve your SEO knowledge and skillset.
Google filetype search – FAQs
Here are the most often asked questions about Google file type search:
What is Google Filetype Search?
Google Filetype Search is a search technique that utilizes the filetype: search operator in Google to filter search results based on specific file types like PDFs, Word documents, or spreadsheets.
How do I search Google by filetype?
To search Google by filetype, type filetype: followed by the required file extension in your Google search query. For example, if you’re searching for PDF files about SEO audits, your query would be “seo audit filetype:pdf”.
Which file types can I search for on Google?
Google can index a wide range of file types, including but not limited to PDF, DOC, DOCX, PPT, PPTX, XLS, XLSX, ODP, ODT, SVG, RTF, TEX, TXT, and XML.
Can I search for multiple file types at once?
Can i combine the file type search operator with other google search operators.
Yes, the filetype: operator can be combined with other Google search operators to further refine your search. For example, you can use quotes for exact phrases (“climate change” filetype:pdf) or site: to search within specific websites (site:example.com filetype:pdf).
How can I use Google filetype search for competitor analysis?
You can use the filetype: search operator in combination with the site: operator to analyze the content strategy of a competitor’s website. For instance, “site:competitor.com filetype:pdf” would bring up all PDF files on your competitor’s website.
Can I use Google filetype search to find SEO templates and resources?
Absolutely! For example, if you’re looking for an Excel content calendar template, you could search “content calendar template filetype:xls OR filetype:xlsx”.
How can I find industry-specific research papers using Google filetype search?
You can find industry-specific research papers by searching for specific topics followed by the filetype: operator. For instance, “quantum computing research filetype:pdf” would yield PDF files related to quantum computing research.
Can I use Google filetype search to find ebooks?
Yes, ebooks are often published in PDF format, so using the filetype:pdf operator with your search terms can help you find ebooks on the subject.
What are some tips to get more accurate results using Google file type search?
Some tips include using specific and relevant keywords related to your desired filetype content, combining the file type operator with other search operators, utilizing Google’s advanced search settings, and trying alternative file extensions.
Can Google file type search be used to find documents in different languages?
Yes, as long as the document is in a file type that Google can index. You can add language-specific keywords to your search query to refine results.
Can Google filetype search help me in finding code snippets?
Yes, Google can index source code in common programming languages including Basic (.bas), C/C++ (.c, .cc, .cpp, .cxx, .h, .hpp), C# (.cs), Java (.java), Perl (.pl), and Python (.py). By using the filetype operator, you can find specific code snippets available online.
Can the filetype operator be used with non-English languages?
Yes, the file type operator works with non-English languages. It’s based on file extensions which are language independent.
What types of files does the filetype operator not seem to work with?
The filetype:svg search does not seem to provide results despite SVG (Scalable Vector Graphics) being a common file type. This is likely due to the way Google indexes and categorizes these files.
Can I find industry-specific research papers using Google filetype search?
Yes, you can find research papers on a specific topic within any industry. For example, to find research papers on Google patents, you can use the query: “Google patents research filetype:pdf OR filetype:tex”.
Can I search for file types within a specific website or domain?
Yes, you can use the “site:” operator to search for file types within a specific website or domain. For example, “site:example.com filetype:pdf”.
- 50+ Google Search Operators That Work On Google Search
- How To Search for PDFs on Google
- 50+ Gmail Search Operators
- Do Google Sites Rank Better?
- Is My Site Penalized By Google?

Do you need help with SEO? Do you want an SEO expert to audit your site? I'm here to help!
Privacy Overview
| Cookie | Duration | Description |
|---|---|---|
| cookielawinfo-checkbox-analytics | 11 months | This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics". |
| cookielawinfo-checkbox-functional | 11 months | The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional". |
| cookielawinfo-checkbox-necessary | 11 months | This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary". |
| cookielawinfo-checkbox-others | 11 months | This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other. |
| cookielawinfo-checkbox-performance | 11 months | This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance". |
| viewed_cookie_policy | 11 months | The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data. |
Research Data Management
- Research Data Management at UVA
- About Research Data Management
- Data Privacy and Human Subjects
- File Management Best Practices
- Metadata and Documentation
- Data Storage, Backup and Security
- Data Citations
- Licensing Data & Code
- Data Rights and Policies
- Open Science and Open Data
Your Research Data Management Team
Research data management librarian.

Senior Research Data Management Librarian

Project and File Organization
File Management Principles
The way project directories are structured and folders are organized is an underappreciated but important aspect of research data management. Of course, sensible file organization schemes are highly context-dependent and will vary from project to project and across domains. That said, there are some general principles and guidelines that apply broadly:
- Plan it early : Don't wait until partway through a project to devise an organization plan. It will be easier to follow a plan if you do it from the beginning, before it involves moving or renaming anything.
- Write it down : You will want to document your file organization scheme for several reasons, including making it easier for students or collaborators to follow, ensuring you understand the organization if you come back to a project after a long pause, and for use in your final documentation that you submit to a repository at the end of the project.
- Time period
- Researcher/project staff
- File type or function
- Research activity or experiment
- Or some other way your data and files naturally group together.
- Follow it consistently : However you choose to organize your project folders and files, it is crucial to follow your scheme consistently. It is too easy to forget to go back and fix instances where the scheme wasn't followed, likely leading to confusion. If the plan needs to be changed, change the written plan and reorganize the project files systematically.
- Avoid encoding information in the directory structure : You should be able to understand the contents of a file independently of the directory structure. In other words, they should be described sufficiently by their file name alone. See the next section on file naming conventions.
Example Directory Structure
Below is a diagram of an example directory structure. Again, there is no right answer, and you may choose to organize your project folders differently (for instance, you might keep code and results together, or you may choose to keep documentation specific to each experiment or sub-study).

(Example file directory image created by Michael and licensed CC-BY)
- Organize your files (MIT Libraries) A page from MIT Libraries containing tips, worksheets, and workshop materials on file naming and organization.
- File Organization (NYU Libraries) NYU Libraries' LibGuide page on file organization and file naming practices.
File Naming Conventions
Best practice for file naming is that the names are descriptive of the contents of the file. The goal is to be able to understand and recall at a glance what is in any given file. Some potential attributes and information to include are:
- Date and time
- Researcher name or laboratory
- Version number and/or status
- Data collection location
- Type of experiment or observation
- Type of instrumentation or equipment used
Some technical formatting guidelines for file naming:
- Be consistent : Just as with your organizing scheme, a naming scheme is most effective when followed consistently. This applies especially to the order you use the above-mentioned elements in names. Also be consistent with case (lower case, UPPER CASE, or CamelCase).
- Avoid spaces and special characters : Use only letters, numbers, and underscores or dashes.
- Use a date format : YYYY-MM-DD or YYYYMMDD is common, and will sort chronologically.
- Pad with zeroes : If you expect at least e.g. 100 numbered files, start with 001, not 1. This again allows for proper sorting.
- Limit to 32 characters : Longer filenames can be unwieldy, but more importantly can cause issues with some computer file systems which may have length limits on filepaths.
- Avoid vague terms : Both overly common terms ("data", "sample") and vague versioning terms ("revision", "final") should be avoided when possible. Use version numbers, dates, or other forms of version control for the latter case.
- Bulk Rename Utility (Windows)
- Advanced Renamer (Windows)
- Renamer 7 (Mac, paid)
- Batch Renaming Tool Handout (MIT Libraries)
File Types and Formats
About File Formats
File formats should be chosen to enable sharing, long-term access, and preservation of your data. Ideally, this means standard and open (non-proprietary) formats, but this may not always be possible depending on the file type and project needs. Researchers of course must consider which formats are best suited to data creation/collection and analysis vs. which are most easily preserved and shared.
When open formats are an option, however, openly available documentation and continued community support for these formats increase the likelihood that such files will be successfully preserved and able to be (re)used down the road by a wider audience.
If you use a program with a proprietary file format as a part of your research, we recommend exporting a copy of that data/file in an open format if possible (e.g. exporting tabular data from Excel as a comma-separated value file), especially when it comes time to deposit and share your data. Please note and be aware that such format conversions may result in the loss of data, metadata, formatting, or other information in some cases. For this reason, we also recommend you keep the original data files , as they may be the files with the most complete version of your dataset.
For certain file types such as images, audio, and video, you will have a choice between lossy and lossless formats. Lossy formats employ (irreversible) compression to reduce filesize, at the cost of fidelity. Lossless formats are generally preferred unless storage space is at a premium.
Recommended Digital Formats Overview (for preservation):
- Text : Plain text (.txt), Rich text (.rtf), Markdown, XML, HTML, PDF/A
- Raster image : TIFF (uncompressed), JPEG2000 (lossless), PNG
- Vector image : SVG
- Tabular data : CSV, TSV, JSON
- Database : XML, CSV, .db/.db3, SQLite
- Statistical : .R/.Rmd/.Rdata, .por (SPSS portable), .do/.dta (STATA), SAS formats
- Geospatial : ESRI shapefiles, GML, NetCDF, GeoTIFF, GeoJSON
- Audio : FLAC, WAV, AIFF
- Video/Moving image : MPEG-4, MOV, AVI, MXF
- Code : Uncompiled source code (.py, .c, .cpp, .java, .js, .php, etc.)
The above are just common suggestions. If you have a repository in mind, check their site to see what they recommend. If you do convert your files or export copies of your files in standard/open formats, consider adjusting filenames to make this clear, as the differences between these files will not necessarily be obvious from the file extensions/types alone.
If you have questions about file types/formats and are wondering which are best for your project, reach out to us .
- Data Types & File Formats (UVA) Our page on file formats.
- UK Data Service Recommended Formats
- Library of Congress Recommended Formats The LoC Recommended Formats Statement 2023-2024. Often considered the authoritative resource by American librarians.
- Dryad Preferred Formats
Version Control
It is often important when working with research files to be able to track changes and revert to an earlier version of a file. Version control refers to both the process of tracking multiple versions of a file and also to software that implements such a functionality. Many folks might be familiar with version control as something that programmers use and need, but it has benefits for various types of research and data files besides code. These benefits may be particularly useful for datasets that require complex processing and for collaborative research projects where many people edit the same files.
If you want to employ version control in your project's file management, there are a few ways to do it:
- Keeping numbered or dated versions of them as you make edits, revisions, additions, or transformations
- Including file history or version control information notes in the files themselves
- Using a dedicated table or file to record version information as you change and update files
- File sharing platforms : Some common file sharing platforms have versioning functionality. This includes UVA Box, Open Science Framework, Google Docs, and Google Drive.
- Repository hosting platforms : GitHub, GitLab and Bitbucket are examples of file/repository hosting platforms that are built on a version control backbone (in this case, Git - see #4). These are a flexible and powerful option for research projects that involve code.
- Version control software : There is dedicated version control software that allows for the most control over the version control process, at the cost of a steeper technical learning curve. Git is the most popular and well-known of these, though some other examples include Mercurial, Apache Subversion, and SmartSVN.
- Electronic lab notebooks : Some electronic lab notebooks (ELNs) come with built-in version control.
Some best practices for manual version control:
- Decide on a system for identifying versions and stick with it
- Record all changes made to a file, whether in the file itself, in a changelog file, or in the documentation
- Identify "milestone" versions to keep (e.g. if you update to version 3.0, you might keep 2.0 but not 2.1 and 2.2)
- Decide how many versions of files to keep, for how long, and how you will organize them
- Version Control with Git Software Carpentry lessons introducing version control using Git.
- Intro to Version Control (UVA Library) Notes for the UVA Library Version Control workshop.
- GitLab tutorials Tutorials provided as part of GitLab's documentation. Ones suitable for beginners are marked with a star.
- Version Control Guidance (Aberdeen) Guidance on manual version control from University of Aberdeen.
- << Previous: Data Privacy and Human Subjects
- Next: Metadata and Documentation >>
- Last Updated: Aug 6, 2024 4:13 PM
- URL: https://guides.lib.virginia.edu/RDM
- 434-924-3021
- [email protected]
- Ask a Librarian
- UVA Shannon Library P.O. Box 400113 160 McCormick Road Charlottesville, VA 22904
About the Library
- Staff Directory
- Fellowships
Using the Library
- Library Use Policies
- Off-Grounds Access
- ITS Computing Accounts
- Accessibility Services
- Emergency Information
- UVA Privacy Policy
- Tracking Opt-out
Other Sites
- Cavalier Advantage
- Library Staff Site

- Harvard Library
- Research Guides
- Harvard Graduate School of Education - Gutman Library
File Naming Best Practices
- Best Practices for File Naming
- Gutman Library Recommendations
- Tools and Resources
Your Digital Content Management Librarian

Formatting Your File Names
What makes a good file naming convention, what should i include in a file naming convention, what should i avoid in a file naming convention.
You should be consistent and descriptive in naming and organizing files so that it is obvious where to find specific data and what the files contain.
It's a good idea to set up a clear directory structure that includes information like the project title, a date, and some type of unique identifier. Individual directories may be set up by date, researcher, experimental run, or what makes sense for you and your research.
Consider the following…
20200528-ThesisTOCV001-DOC.doc
20190519-S515FINALV001-PDF.pdf
19780130-FAMILYVACATION-JPG.jpg
The second lets the user know quickly the date, subject, and file format making it easier to locate files quickly and easily.
Filenames should have a precise name that allows you to quickly identify what the file contains.
Some information may include:
Project name or acronym
Location/spatial coordinates
Researcher name/initials
Date or date range of project
Type of data
Version number of file
Three-letter file extension for application-specific files
A good format for date designations is YYYYMMDD or YYMMDD. This format makes sure all of your files stay in chronological order.
Do not make file names too long, since long file names do not work well with all types of software. Also, file names that are too long can easily be corrupted increasing the risk of losing your work.
Do not use special characters such as ~ ! @ # $ % ^ & * ( ) ` ; < > ? , [ ] { } ' " and |. Do not use spaces. Some software will not recognize file names with spaces, and file names with spaces must be enclosed in quotes. Recommended options include:
Underscores: file_name
Dashes: file-name
No separation: filename
Camel case: FileName
- << Previous: Best Practices for File Naming
- Next: Gutman Library Recommendations >>
- Last Updated: May 29, 2020 2:20 PM
- URL: https://guides.library.harvard.edu/c.php?g=1033502
Harvard University Digital Accessibility Policy
University Libraries
- Research Guides
- Blackboard Learn
- Interlibrary Loan
- Study Rooms
- University of Arkansas
Data File Management
- File Formats
- File naming
- File Versioning
Data Services
For more information or for assistance, please contact Data Services at [email protected].
Introduction to data file formats
Research data takes many forms. any one project may have multiple examples of these types of data..
- Documents, spreadsheets
- Questionnaires, surveys
- Laboratory and field notebooks
- Audio and video files
- Photographs, film, slides
- Digital objects
- Artifacts, samples, specimens
- Procedures and protocols
Open and Reproducible Data Practices
While gathering your data, you may not have a choice as to the formats you are using to retain your data. However, when saving or sharing your data it is a BEST PRACTICE to follow open data guidelines. Open guidelines help your work to tolerate software and operating system changes. You or someone else may need to use your data in the future!
When sharing data
Keep data files in their original raw format AND
Save data to share in a non-proprietary (open) file format. If conversion to an open data format will result in some data loss from your files, you might consider saving the data in both the proprietary format and an open format. When it is necessary to save files in a proprietary format, consider including a readme.txt file in your directory that documents the name and version of the software used to generate the file, as well as the company who made the software.
Elements of an appropriate file format
When selecting file formats for longer storage, the formats should ideally be:
- Non-proprietary (use open software)
- Not encrypted
- Not compressed
- Familiar to your research community
- Fully published and available royalty-free
- Fully and independently implementable by multiple software providers on multiple platforms without any intellectual property restrictions for necessary technology
- Developed and maintained by an open standards organization with a well-defined inclusive process for evolution of the standard.
The Library of Congress has published a Recommended Formats Statement that discusses this topic in great depth.
Best practices in file formats
Proprietary file types should be avoided, and the open file types are preferred:.
|
|
|
|
|---|---|---|
|
|
| TAR, GZIP, ZIP |
|
|
| XML, CSV |
|
| Word (DOC, DOCX) | ODF (Open Document Format), TXT, PDF/A, XML, HTML |
|
| Excel (XLS, XLSX) | CSV, TSV, TAB |
|
| Photoshop (PSD), Illustrator (AI) | TIFF, JPG/JPEG 2000, PNG, BMP, GIF |
|
| Windows Media Audio (WMA) | FLAC, WAV, AIFF, MXF |
|
| Windows Media Video (WMV) | MOV, MPEG-4, AVI, MXF |
|
| Windows PowerPoint (PPT, PPTX) | PDF/A, EPUB |
|
| CAD (DXF), MapInfo (MIF) | GeoTIFF, GeoPDF, Shapefile (SHP, SHX, PRJ, DBF), NetCDF |
See the Library of Congress' Sustainability of Digital Formats web site for more complete listings and discussions of formats.
- << Previous: Home
- Next: File naming >>
- Last Updated: Apr 29, 2024 1:15 PM
- URL: https://uark.libguides.com/FileManagement
- See us on Instagram
- Follow us on Twitter
- Phone: 479-575-4104
- Chester Fritz Library
- Library of the Health Sciences
- Thormodsgard Law Library
Data Management
- How to use the guide
- Funder requirements
- File types and naming
Choosing file formats
Naming your files.
- Find Datasets (external guide) This link opens in a new window
- Storing your data
- Topics in Scholarly Communications This link opens in a new window
The file formats you choose to store your data in will depend on the needs of your research project. Some questions to keep in mind when making format decisions should include:
- What program is needed to open these files? Is it commonly available? Will it limit my ability to access files later?
- Will this format be accessible to other users? Will I need to convert my data to another format if asked to share it?
If possible opt for standardized open source formats over proprietary formats. Standardized open source formats can be more robust than proprietary formats because they are not reliant on the continuing existence of a single company to be maintained. Some preferred open formats include:
- Text: ASCII, UTF-8, XML, PDF/A, HTML
- Images: TIFF, JPEG 2000, PNG, GIF
- Tabular data: XML, CSV
- Video: MOV, MPEG, AVI, MXF
- Sounds: WAVE, AIFF, MP3
- Statistics: ASCII, DTA, POR, SAS, SAV
For more tips on choosing appropriate file formats see Stanford University Library's Best Practices for File Formats .
How you name your files will have a big impact on your ability to identify and retrieve your files later. Your names should be consistent and descriptive so it's clear what each file contains. Some basic guidelines to follow are:
- Use file names that indicate what is in the file and what version it is.
- Include creation dates in a yyyy-mm-dd format. This ensures your files will be sorted chronologically.
- Avoid using spaces or special characters (ex. *%$) in your files names. Instead use the underscore (_) as a delimiter. Some software will not recognize spaces or special characters in file names.
- Keep names as short as possible. This makes files easier to browse at a glance.
See this article Folder and File Naming Convention – 10 Rules for Best Practice for more tips on creating file names.
- << Previous: Organizing your data
- Next: Metadata >>
- Last Updated: Aug 8, 2024 11:27 AM
- URL: https://libguides.und.edu/data-management
Research Data Management
- File Format Selection
- File Organization
- Documenting Your Work
- Storage & Backup
- Version Control
- Jupyter notebooks
- Selecting a Repository
- Code & Data Licensing
- Open Science Framework
- Data Ownership @ NYU ↗
- Code sharing & reproducibility ↗
- Share in NYU's repository ↗
- Open Access Publishing ↗
- DATA MANAGEMENT PLAN
- CLASS MATERIALS
DATA MANAGEMENT APPOINTMENTS
General information.
For assistance, please submit a request . You can also reach us via the chat below, email [email protected] , or join Discord server .
If you've met with us before, tell us how we're doing .
Service Desk and Chat
Bobst Library , 5th floor
Staffed Hours: Summer 2024
Mondays: 12pm - 5pm Tuesdays: 12pm - 5pm Wednesdays: 12pm - 5pm Thursdays: 12pm - 5pm Fridays: 12pm - 5pm
Data Services closes for winter break at the end of the day on Friday, Dec. 22, 2023. We will reopen on Wednesday, Jan. 3, 2024.
Further Resources and Bibliography
- CSV resources from the Library of Congress
- Digital Preservation Coalition: List of Digitally Endangered File Types
- File format summary from UK Data Archive
- PRONOM registry of file formats
FILE FORMAT SELECTION
Ideally, file types for a project should be standard, non-proprietary, and open source. If these features are not possible, at the very least file format selection should be made with sustainability and long-term use in mind. Try opening a Windows 95 Word Document on your modern computer, and you'll understand why (hint: you will get only wingdings)!
Many software you will have to use often relies on proprietary file formats that do not last long as new versions are created, or tools lose relevance. Where possible, export data files to stable formats for long-term access to your data, or convert proprietary files into equivalent standardized files that will be able to represent that data (like going from .xlsx to .csv).
A proprietary format can refer to:
- The secrecy means that specific hardware and software (designed and sold by the authors) can interpret the format better than others (like opening a .psd file in PhotoShop is more seamless than in Glimpse)
- a file format that is openly documented but whose use is restricted through licenses
An open format is:
- An open format is one that is platform independent, machine readable, and made available to the public without restrictions that would impede the re-use of that information". -- Open Government Directive
- There are no restrictions on the type of software or hardware that can use these by design (like how a .csv can be used by Google Sheets, Excel, and LibreOffice Calc)
Examples of sustainable formats
Long-term formats for data.
HTML (.htm)
OpenDocument Format (e.g. OpenDocument Text, .odt)
Plain text (.txt)
Markdown and other human-readable markup languages deploying plain-text editing
Character-delimited files such as Comma Separated Value (.csv) or Tab Delimited (.tab)
Uncompressed TIFF (.tif)
JPEG 2000 (.mj2)
MPEG-4 (.mp4)
Free Lossless Audio Codec (.flac)
ESRI Shapefiles and supporting files (.shp, .shx, .dbf, .prj, .sbx, .sbn)
GeoTIFF (.tif, .tfw)
Mid-term formats for data
Statistical
SPSS portable format (.por)
R file formats, i.e. script files (.R) data (.Rda, .Rdata) or markdown files (.Rmd)
Stata file formats, i.e. do-files (.do) and data files (.dta)
SAS file formats (.sas, .xpt, etc.)
JPEG (.jpeg, .jpg)
Photoshop files (.psd)
ESRI geodatabase formats (.gdb, .mdb)
Where possible given the limits of file formatting, encoding should be done using the Unicode system (UTF-8 or UTF-16), or using the older ASCII system that has been incorporated into Unicode.

- << Previous: STARTING OUT
- Next: File Organization >>
- Last Updated: May 23, 2024 2:40 PM
- URL: https://guides.nyu.edu/data_management
Have a language expert improve your writing
Run a free plagiarism check in 10 minutes, generate accurate citations for free.
- Knowledge Base
- Research paper
- Research Paper Format | APA, MLA, & Chicago Templates
Research Paper Format | APA, MLA, & Chicago Templates
Published on November 19, 2022 by Jack Caulfield . Revised on January 20, 2023.
The formatting of a research paper is different depending on which style guide you’re following. In addition to citations , APA, MLA, and Chicago provide format guidelines for things like font choices, page layout, format of headings and the format of the reference page.
Scribbr offers free Microsoft Word templates for the most common formats. Simply download and get started on your paper.
APA | MLA | Chicago author-date | Chicago notes & bibliography
- Generate an automatic table of contents
- Generate a list of tables and figures
- Ensure consistent paragraph formatting
- Insert page numbering
Instantly correct all language mistakes in your text
Upload your document to correct all your mistakes in minutes

Table of contents
Formatting an apa paper, formatting an mla paper, formatting a chicago paper, frequently asked questions about research paper formatting.
The main guidelines for formatting a paper in APA Style are as follows:
- Use a standard font like 12 pt Times New Roman or 11 pt Arial.
- Set 1 inch page margins.
- Apply double line spacing.
- If submitting for publication, insert a APA running head on every page.
- Indent every new paragraph ½ inch.
Watch the video below for a quick guide to setting up the format in Google Docs.
The image below shows how to format an APA Style title page for a student paper.

Running head
If you are submitting a paper for publication, APA requires you to include a running head on each page. The image below shows you how this should be formatted.

For student papers, no running head is required unless you have been instructed to include one.
APA provides guidelines for formatting up to five levels of heading within your paper. Level 1 headings are the most general, level 5 the most specific.

Reference page
APA Style citation requires (author-date) APA in-text citations throughout the text and an APA Style reference page at the end. The image below shows how the reference page should be formatted.

Note that the format of reference entries is different depending on the source type. You can easily create your citations and reference list using the free APA Citation Generator.
Generate APA citations for free
Receive feedback on language, structure, and formatting
Professional editors proofread and edit your paper by focusing on:
- Academic style
- Vague sentences
- Style consistency
See an example

The main guidelines for writing an MLA style paper are as follows:
- Use an easily readable font like 12 pt Times New Roman.
- Use title case capitalization for headings .
Check out the video below to see how to set up the format in Google Docs.
On the first page of an MLA paper, a heading appears above your title, featuring some key information:
- Your full name
- Your instructor’s or supervisor’s name
- The course name or number
- The due date of the assignment

Page header
A header appears at the top of each page in your paper, including your surname and the page number.

Works Cited page
MLA in-text citations appear wherever you refer to a source in your text. The MLA Works Cited page appears at the end of your text, listing all the sources used. It is formatted as shown below.

You can easily create your MLA citations and save your Works Cited list with the free MLA Citation Generator.
Generate MLA citations for free
The main guidelines for writing a paper in Chicago style (also known as Turabian style) are:
- Use a standard font like 12 pt Times New Roman.
- Use 1 inch margins or larger.
- Place page numbers in the top right or bottom center.

Chicago doesn’t require a title page , but if you want to include one, Turabian (based on Chicago) presents some guidelines. Lay out the title page as shown below.

Bibliography or reference list
Chicago offers two citation styles : author-date citations plus a reference list, or footnote citations plus a bibliography. Choose one style or the other and use it consistently.
The reference list or bibliography appears at the end of the paper. Both styles present this page similarly in terms of formatting, as shown below.

To format a paper in APA Style , follow these guidelines:
- Use a standard font like 12 pt Times New Roman or 11 pt Arial
- Set 1 inch page margins
- Apply double line spacing
- Include a title page
- If submitting for publication, insert a running head on every page
- Indent every new paragraph ½ inch
- Apply APA heading styles
- Cite your sources with APA in-text citations
- List all sources cited on a reference page at the end
The main guidelines for formatting a paper in MLA style are as follows:
- Use an easily readable font like 12 pt Times New Roman
- Include a four-line MLA heading on the first page
- Center the paper’s title
- Use title case capitalization for headings
- Cite your sources with MLA in-text citations
- List all sources cited on a Works Cited page at the end
The main guidelines for formatting a paper in Chicago style are to:
- Use a standard font like 12 pt Times New Roman
- Use 1 inch margins or larger
- Place page numbers in the top right or bottom center
- Cite your sources with author-date citations or Chicago footnotes
- Include a bibliography or reference list
To automatically generate accurate Chicago references, you can use Scribbr’s free Chicago reference generator .
Cite this Scribbr article
If you want to cite this source, you can copy and paste the citation or click the “Cite this Scribbr article” button to automatically add the citation to our free Citation Generator.
Caulfield, J. (2023, January 20). Research Paper Format | APA, MLA, & Chicago Templates. Scribbr. Retrieved August 12, 2024, from https://www.scribbr.com/research-paper/research-paper-format/
Is this article helpful?

Jack Caulfield
Other students also liked, apa format for academic papers and essays, mla format for academic papers and essays, chicago style format for papers | requirements & examples, what is your plagiarism score.
Check out our new Consent management feature here
- Case Studies
- Book a Demo
Detecting File Types: The Art of Data Identification
Learn the art of data identification and discover effective techniques for detecting file types in this comprehensive article.
In the world of digital asset management, the ability to accurately detect file types is a crucial skill. With the amount of data being generated and stored every day, it is essential to be able to quickly identify and organize files based on their format. This article will explore the intricacies of file type detection, discussing various methods and technologies that aid in this process.
1. Introduction to File Types and Data Identification
Before delving into the details of file type detection, it is important to understand the significance of identifying different file formats. Data identification forms the foundation of digital asset management, enabling organizations to efficiently organize, classify, and retrieve files. Without accurate file type detection, the management of digital assets becomes a challenging task, leading to increased complexity and reduced productivity.
Understanding the importance of identifying file types
File types serve as a vital piece of information that guides the interpretation and manipulation of data. From images and audio files to documents and spreadsheets, each file format requires specific software to access and process the content effectively. By identifying file types, businesses can ensure the seamless integration of their digital assets into their workflows.
Moreover, accurate identification of file types allows organizations to implement appropriate security measures. For instance, sensitive documents can be encrypted, ensuring that only authorized individuals can access them. By understanding the importance of file types, organizations can safeguard their valuable digital assets and protect them from unauthorized access.
Overview of different file formats and their characteristics
There is a wide array of file formats, each designed to cater to specific needs and requirements. Understanding the characteristics of different file formats is essential for accurate file type detection. For example, the Portable Document Format (PDF) is widely used for document sharing due to its platform independence and consistent layout. On the other hand, the Joint Photographic Experts Group (JPEG) format is commonly used for image compression, striking a balance between image quality and file size.
In addition to their technical characteristics, file formats often have historical and cultural significance. For instance, the MP3 format revolutionized the music industry by enabling the widespread distribution of digital music. Understanding the historical context of file formats can provide valuable insights into their usage patterns and evolution over time.
Manual methods for identifying file types
Before the advent of automated tools, file type identification was primarily done manually. This involved examining file extensions, analyzing file headers, and inspecting file signatures. Although manual methods can be time-consuming and prone to errors, they still play a role in certain scenarios where automated tools may fall short.
Manual file type identification often requires a deep understanding of file formats and their underlying structures. Experts in the field can examine the raw binary data of a file and deduce its format based on specific patterns and markers. This hands-on approach allows for a meticulous examination of files and can uncover valuable information that automated tools might miss.
Automated tools and algorithms for file type detection
With advancements in technology, automated tools and algorithms have revolutionized the field of file type detection. These tools employ machine learning techniques, such as pattern recognition, to accurately identify file types based on their underlying structures. By analyzing byte patterns and statistical features, these algorithms can quickly and reliably detect file formats, significantly reducing the manual effort required.
Automated file type detection tools are especially beneficial in scenarios where large volumes of files need to be processed. For instance, in a digital forensics investigation, automated tools can quickly analyze thousands of files to identify potentially malicious or suspicious content. This saves investigators valuable time and allows them to focus on deeper analysis and interpretation of the identified files.
Dealing with file format inconsistencies and variations
File formats are not always consistent, and variations can pose challenges during the file type detection process. For example, proprietary formats or encrypted files often require specialized algorithms or decryption keys for identification. By developing robust techniques that handle such inconsistencies, digital asset management systems can cater to a wide range of file types and ensure comprehensive file organization.
Moreover, file format inconsistencies can arise due to the evolution of file formats over time. New versions of file formats may introduce additional features or change the underlying structure, making it necessary to update file type detection algorithms. Keeping up with these variations and incorporating them into automated tools is crucial for accurate and reliable file type detection.
Handling encrypted or compressed files during identification
Encryption and compression play a pivotal role in securing and reducing the size of files, respectively. However, they can complicate the file type detection process. Digital asset management systems need to include algorithms and libraries that handle encrypted and compressed files effectively. By decrypting or decompressing files before the identification process, these systems can accurately categorize and manage digital assets.
Handling encrypted files requires specialized knowledge of encryption algorithms and keys. Decryption algorithms need to be integrated into file type detection tools to unlock the encrypted content and determine the file type. Similarly, compressed files need to be decompressed to access the underlying data and identify the file type accurately.
Case studies on real-world scenarios of file type detection
To truly understand the significance of file type detection, it is crucial to examine real-world scenarios and case studies. By exploring various industries and domains, we can uncover the practical applications of file type detection. These case studies will highlight the challenges faced, the solutions implemented, and the benefits derived from accurate file type identification.
For example, in the healthcare industry, accurate file type detection is essential for managing medical records and imaging data. Different file formats, such as DICOM for medical images and HL7 for electronic health records, require specialized handling and integration into healthcare systems. Case studies in this domain can shed light on the importance of file type detection in ensuring patient safety and efficient healthcare delivery.
Best practices for accurate and efficient file type identification
Accurate and efficient file type identification relies on following established best practices. These practices include utilizing a combination of manual and automated methods, employing a diverse array of algorithms, and keeping up-to-date with new file formats and technologies. By implementing these best practices, organizations can ensure smooth digital asset management processes and avoid potential pitfalls.
Furthermore, collaboration and knowledge sharing among experts in the field are crucial for advancing file type detection techniques. Regular conferences, workshops, and online forums provide opportunities for professionals to exchange ideas, discuss challenges, and propose innovative solutions. By actively participating in these communities, organizations can stay at the forefront of file type detection advancements and contribute to the field's growth.
How file type detection aids in data organization and classification
File type detection forms the backbone of data organization and classification. By accurately identifying file formats, digital assets can be categorized and tagged accordingly. This enables streamlined searching, improved retrieval times, and enhanced data integrity. Whether it's arranging files by file type, content, or date, file type detection plays a vital role in efficient digital asset management.
Moreover, file type detection facilitates the implementation of metadata standards. Metadata, such as file creation date, author information, and keywords, can be automatically extracted and associated with files during the identification process. This metadata enhances data organization and enables advanced search capabilities, making it easier to locate specific files within a vast digital asset repository.
Integration of file type detection in data processing workflows
To maximize the benefits of file type detection, it is crucial to integrate it seamlessly into data processing workflows. By incorporating file type detection algorithms and libraries into data pipelines, organizations can automate the identification process and ensure consistent and accurate file categorization. This integration enables efficient data processing, enhances data quality, and simplifies overall digital asset management.
Integration of file type detection with other data processing tasks, such as data extraction or transformation, further enhances the value derived from digital assets. For example, in an e-commerce setting, file type detection can be integrated with product data processing workflows to automatically extract relevant information from product images or descriptions. This streamlines the product catalog management process and ensures accurate and up-to-date product information.
Advancements in machine learning and artificial intelligence for file type identification
Machine learning and artificial intelligence (AI) continue to drive advancements in file type identification. These technologies enable algorithms to learn from vast amounts of data and improve their identification accuracy over time. As machine learning becomes more sophisticated, the potential for accurate and efficient file type detection grows exponentially, revolutionizing digital asset management processes.
AI-powered file type detection systems can adapt to new file formats and variations without requiring manual intervention. By continuously analyzing and learning from new data, these systems can stay up-to-date with the evolving landscape of file formats. This adaptability allows organizations to handle emerging file formats seamlessly and ensure accurate file type detection even in rapidly changing environments.
Emerging technologies and their impact on data identification techniques
Emerging technologies, such as blockchain and decentralized file storage, are reshaping the landscape of data identification techniques. These technologies offer new opportunities and challenges for file type detection and digital asset management as a whole. By staying abreast of these innovations and assessing their impact, organizations can leverage emerging technologies to enhance their data identification strategies.
For instance, blockchain technology can provide tamper-proof records of file types and their associated metadata. By leveraging blockchain, organizations can ensure the integrity and authenticity of file type information, enhancing trust and reliability in digital asset management systems. Similarly, decentralized file storage systems can distribute file type detection algorithms across a network, improving scalability and resilience.
Recap of the importance of file type detection
As we draw closer to the end of this article, it is essential to recap the importance of file type detection in digital asset management. Accurate file type detection ensures efficient organization, enhanced searchability, and improved data integrity. Without proper file type identification, managing digital assets becomes a daunting and laborious task, hindering productivity and impeding business operations.
By investing in robust file type detection techniques, organizations can unlock the full potential of their digital assets, making them more accessible and valuable. Whether it's for compliance purposes, data analytics, or content distribution, file type detection is a critical component of effective digital asset management.
Final thoughts on the art of data identification
In conclusion, detecting file types is an art in the realm of digital asset management. By combining the right mix of manual methods and automated tools, organizations can unlock the full potential of their digital assets. As technology advances and new file formats emerge, the ability to adapt and refine file type detection techniques becomes paramount. By mastering the art of data identification, businesses can streamline their operations, optimize their workflows, and effectively manage their digital asset repositories.
How to search Google by file type
- September 26, 2022
- Head of Rush Analytics Dmitriy Tsytrosh
- Updated December 25, 2023 Last update
Last update
On various websites files are offered for download. Via a detour, it is possible to search Google specifically for a file type – for example, to find documents, PDF files and so on. Below, we explain how to do it.
Search using Google’s advanced settings
Search using the operators in the search field.
On the Internet, there are not only static homepages, but also those from which content is downloaded. This can be specifically set for a search query via Google in the following way:
- Open Google’s home page, for example, by clicking on the Google logo
- Now click on “Settings” at the bottom and on the far right
- In the menu that now appears, click on “Advanced Search”

- On the page that appears, click on “Narrow results” under “File type” (where it says “All formats”)
- Now select the desired file type and click on it
- After you have made your choice, click on the blue button “Advanced search”

- Adobe Acrobat PDF (.pdf)
- Adobe PostScript (.ps)
- Autodesk DWF (.dwf)
- Google Earth (.kml and .kmz)
- Microsoft Office (.doc, .ppt and .xls)
- Rich Text Format (.rtf)
- Shockwave Flash (.swf)
To do this, simply add the command “filetype:…” at the end of your search, where the ellipsis is the extension of the file you are looking for.
This will all become clearer with an example. Imagine you are looking for a PDF document on “cleaner checklist”. We type “cleaner checklist” into the search box and then add “filetype:pdf”. This will only find files with that extension.
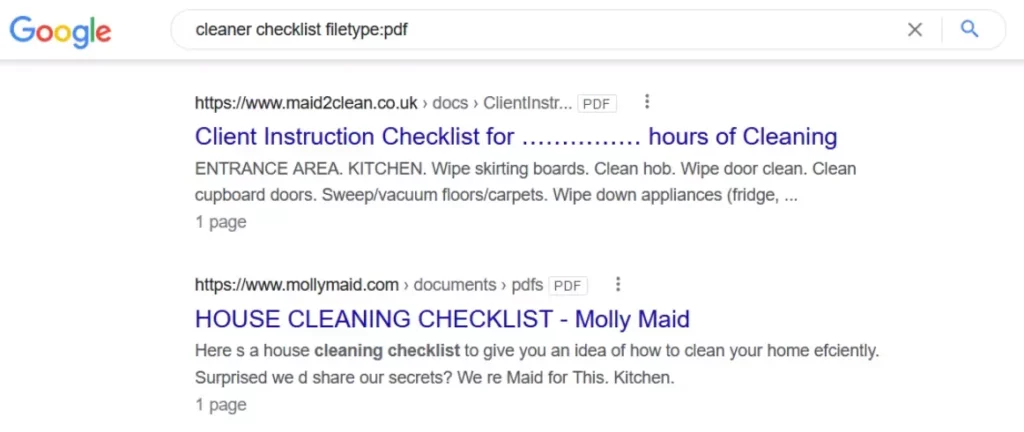
The same happens if we want to find a document with this topic, we write “cleaner checklist filetype:doc” or “cleaner checklist filetype:docx”. We can try other file types such as excel documents, AVI videos or even MP3 sounds and SWF flash presentations.
This trick also works if entered in the address bar of Chrome or Firefox (if Google is the default search engine). In short, a simple trick that can be very useful and doesn’t involve much mystery, but it will save precious time when searching for a particular file.
All operators for possible file types can be viewed here: https://support.google.com/webmasters/answer/35287?hl=en
- New articles
- Popular articles
- Minimize the impact of website migration on SEO
- 8 tools to monitor everything you want to know about your competitors
- How to check your position in Google
- Content pillars in social networks
- How to find all pages on a website
- How to find page views in Google Analytics
Other articles
- 🫂 Social Media
Our common goal is to take your social media presence to the next level with strategic fundamentals. To do this, we give you the basics of social media strategy as a set of tactics to achieve the set goal: The effective management of social media content that engages users and contributes to the achievement of your business goals.
- Rush Analytics
- May 19, 2022
- 🚀 Technical SEO
Another important piece of information is the link weight. You should evenly distribute the link...
- Dmitriy Tsytrosh
- June 16, 2022
These predictive searches are usually based on several factors such as our history, recent searches,...
- George Rossoshansky
Get 7 days free trial access to all tools.
Pick the right keywords from Google, YouTube and Yandex suggestions
Privacy Overview
| Cookie | Duration | Description |
|---|---|---|
| cookielawinfo-checkbox-analytics | 11 months | This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics". |
| cookielawinfo-checkbox-functional | 11 months | The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional". |
| cookielawinfo-checkbox-necessary | 11 months | This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary". |
| cookielawinfo-checkbox-others | 11 months | This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other. |
| cookielawinfo-checkbox-performance | 11 months | This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance". |
| viewed_cookie_policy | 11 months | The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data. |
How to Research a File Type
First, we'll assume that you actually used the FILExt search for information on the file you can't open. If not, see instructions on how to use FILExt .
Nobody can know everything so it's a certainty that there are many file types not listed in the FILExt database. When that happens you might have to search further to find the information you want. This page will offer some suggestions on doing that...
Using Internet Search Engines
Internet search engines can help you search for a particular file type to match an unknown file extension. First search on the full file name. If that does not yield any useful results consider using the search term: .ext file
Replace ".ext" above with the extension of interest and leave the word "file" with it for your search. This combination tends to produce useful results although you may have to scroll through hundreds in order to find something you can use. When the Google results show up tap the keychord Control-F and type the ".ext" part, with the period, into the search box and then let it find the various instances of the extension. You need to do this because Google's results will ignore the period but you usually want to find it. ( Hint : When you click on a link to see if it's really what you want, right click on the link and open a new browser window or new browser tab. That way you don't have to reload the search results if it's not what you want.)
If a search of the Web comes up with no significant results don't forget to also search the newsgroups, forums, discord, etc. This is particularly true if the file might be a game-related file. Many Internet newsgroup discussions revolve around "cracking" various data files and/or converting the data from one format to another. Your particular file type just might be one of these and you'll find pointers to your answer in the newsgroup discussions and comments.
Use the context of the file
Where a file is located, how it was obtained, and the file's date and time can all be used as clues to the nature of the file. Consider these tips...
- Where and how did you get the file? The answer to these two questions can give you major clues as to the file's contents and what might be used to open it. If downloaded from the Web go back to the site where you got the file and look around for clues about the file. If necessary, write to the site's owner and ask them about the file.
- Where exactly is the file stored on your system? A computer's hard disk is usually organized like a filing cabinet. Files are stored in folders and the folders are organized according to their use. Folders found within the"Program Files" folder are usually programs and/or files necessary for the running of programs. So, files found there are usually associated somehow with the particular program represented by the folder the file is located in. Files in "My Pictures" are usually graphic files. And so on. Look at the full file name and the directory structure where the file is located and you can sometimes deduce what program that file works with or what type of program it is. Right click on the file and select Properties to see the file's location on the disk (you may have to click on the location and scroll to see the entire list of directories for the file).
- What were you doing when...? The date and time a file on your system was created, last modified and accessed are part of the Properties listing when you right click on a file and select that option. Think carefully about what you were doing at the time the file was created or last modified. You just might happen to remember and make a connection between a particular program and the file of interest. (This is a longshot, but worth considering if the other tips yield nothing.)
Examine the File with an Editor
FILExt has a whole page on looking into a file . A summary of the information is here.
Basically, you would be looking into a file to attempt to find some data in the file that gives a hint as to the proper association for the file. Lacking that, it might be possible to use the data found in the file to determine what sort of file it is and deduce the program association or, at a minimum, perhaps extract what's important to you in its raw form in order to use within some other program.
The FILExt Online File Viewer can help. There are also several programs that allow you to open any file type. For this summary FILExt will simply point you to the shareware program EditPad Pro ( http://www.editpadpro.com/ ). When you open a binary file in EditPad Pro you see both the binary bytes and the ASCII equivalents. If you're lucky, when you do this on an unknown file you can often find hints about the file's creator. For example, if someone sends you a .PSPIMAGE file and you open it in EditPad Pro you might see...
Note that right at the top of the .PSPIMAGE file it tells you that the file was created by Paint Shop Pro and is an image file. Unfortunately, not all files are that easy to figure out. However, if you scroll through the file you just might find a copyright notice or some other indicator of what the file type is.
There are other possible indicators of a file's type, including the first several characters in the file for some file types (a few of these are listed on the more complete page about looking into a file ).
Use TrID or Other File Identification Programs
TrId is a program that reads a file and compares its structure with a number of known structures. If a match is found you are presented with the alternatives. TrID is free and comes as a program you can load on your system or in an on-line version where you upload the file to their server for analysis there. [Note: With permission, FILExt uses the TrID data in its listings so TrID is best used to either narrow down your choices if a FILExt search results in multiple possibilities or if the file has no file extension (or might have the wrong one).
A similar product made by Forensic Innovations, Inc. would be FI Tools . This product has a trial version that might help in single-file circumstances or you can purchase a license for extended use.
Use Process Monitor
If the file is on your system and you don't know what made the file, you can perhaps find out using Process Monitor . Process Monitor will display and log all current activities on your computer. To use this tool for file type research you need to know that the file in question is being written while Process Monitor is running; so, this tool is only good for research if you have unknown files that are frequently updated or created as your computer is running.
When Process Monitor is running you will see an activity log being created as your computer runs. After a short period and/or when you know one of the unknown files has been created then stop the logging activity (Control-E) and then use the search function to search for the file's name. You may have to look at a number of entries to figure out what program or process created or wrote to the file. These logs can get very large and will continue to grow until you stop the logging so be certain to stop the logging before doing the search or the search itself will make the log grow faster than your search will run.
Post In A Forum
Search a forum for the purpose of asking questions. You can read past responses to questions there and, if you don't find an answer, you can post a new question. If you are asking about a particular file and how to read it, it would help if you post the first 256 bytes of the file along with your message (there is often useful information in that part of a file). There is a free tool called Minidumper which can help you do this and even provide the output in a format you can post directly into the forum message so all you have to do is Copy the output to your clipboard (actually just click on a button) and then Paste the results into your forum message. For example...
Other hints would be helpful. Like...
- What did you think it should be?
- If you got it by E-mail what did the sender say created it? (If not, ask.)
- If you found it on your system and are just curious where was it? What program was it with?
- Have you run it by TrID (online or offline if it's a large file)?
- What does the first part of the file consist of? (Run Minidumper .)
- And so forth.
Any information that might help would be useful in your post. A simple post that just says: "How do I open a ??? file?" is fairly useless is unlikely to yield an answer.
Try Other Extension Collections...
There are a large number of file extension collections on the Web. If the extension is not in the FILExt collection then it just might be in one of those.
When you find the answer...
...please don't forget to come back to FILExt if you find out more information about this file (particularly the program, the function of the extension, and the Web address for the program site). Others may be interested in that file type and you can help by submitting the information for inclusion into the database. Don't forget to bring the link where you found the information for your submittal. It helps a great deal when entering the data.
.RIS File Extension
Research information systems citation file.
| Developer | Research Information Systems |
| Popularity | 3.5 | 236 Votes |
What is a RIS file?
An RIS file is a bibliographic citation file saved in a format developed by Research Information Systems (RIS). It contains a series of two-letter tags and citation information associated with those tags. This information might include a cited work's type, author, publication date, title, and more.
More Information

RIS created the RIS format to allow for standardized exchange of citation information between digital libraries. The files are saved in a standard, human-readable plain text format, to make them easy to open, read, edit, and manage.
An RIS file may contain one or more citations. Each citation must begin with the TY tag, which denotes the type of publication from which the citation was drawn. For example, the text TY - JOUR denotes that the citation references a journal article. Typically, each citation then goes on to include the cited work's author ( AU ) or A1 ), title ( TI or T1 ), publication date (often divided into multiple sections for year and month), and other metadata . In multi-citation RIS files, each citation ends with the tag ER .
How to open a RIS file

You can open an RIS file with Microsoft Notepad (Windows), Apple TextEdit (Mac), or any other text editor. You can also import an RIS file into many citation management programs, including but not limited to:
- Clarivate EndNote (Multiplatform)
- ProQuest RefWorks (Web)
- BibDesk (Mac)
How to convert a RIS file
You can use Online RIS2BIB (Web) to convert RIS files to the .BIB (BibTeX Bibliography Database) format. You can use Clarivate EndNote (Multiplatform) to convert RIS files to many other formats, including .BIB , .ENL , and .XML .
Programs that open RIS files
Verified by fileinfo.com.
The FileInfo.com team has independently researched the Research Information Systems Citation file format and Mac, Windows, and Linux apps listed on this page. Our goal is 100% accuracy and we only publish information about file types that we have verified.
If you would like to suggest any additions or updates to this page, please let us know .
PAGE CONTENTS
- Google Search Central
- Español – América Latina
- Português – Brasil
- Tiếng Việt
- Documentation
- Search Central
File types indexable by Google
Google can index the content of most text-based files and certain encoded document formats. The most common file types we index include:
- Adobe Portable Document Format (.pdf)
- Adobe PostScript (.ps)
- Comma-Separated Values (.csv)
- Electronic Publication (.epub)
- Google Earth (.kml, .kmz)
- GPS eXchange Format (.gpx)
- Hancom Hanword (.hwp)
- HTML (.htm, .html, other file extensions)
- Microsoft Excel (.xls, .xlsx)
- Microsoft PowerPoint (.ppt, .pptx)
- Microsoft Word (.doc, .docx)
- OpenOffice presentation (.odp)
- OpenOffice spreadsheet (.ods)
- OpenOffice text (.odt)
- Rich Text Format (.rtf)
- Scalable Vector Graphics (.svg)
- TeX/LaTeX (.tex)
- Basic source code (.bas)
- C/C++ source code (.c, .cc, .cpp, .cxx, .h, .hpp)
- C# source code (.cs)
- Java source code (.java)
- Perl source code (.pl)
- Python source code (.py)
- Wireless Markup Language (.wml, .wap)
Google can also index the following media formats:
- Image formats: BMP, GIF, JPEG, PNG, WebP, and SVG
- Video formats: 3GP, 3G2, ASF, AVI, DivX, M2V, M3U, M3U8, M4V, MKV, MOV, MP4, MPEG, OGV, QVT, RAM, RM, VOB, WebM, WMV, and XAP
Search by file type
You can use the filetype: operator in Google Search to limit results to a specific file type or file extension. For example, filetype:rtf galway will search for RTF files and URLs ending in .rtf whose content contains the term " galway ".
Except as otherwise noted, the content of this page is licensed under the Creative Commons Attribution 4.0 License , and code samples are licensed under the Apache 2.0 License . For details, see the Google Developers Site Policies . Java is a registered trademark of Oracle and/or its affiliates.
Last updated 2024-05-24 UTC.
Stack Exchange Network
Stack Exchange network consists of 183 Q&A communities including Stack Overflow , the largest, most trusted online community for developers to learn, share their knowledge, and build their careers.
Q&A for work
Connect and share knowledge within a single location that is structured and easy to search.
Searching Windows by File Type
Although Windows defines the file type on the basis of the file extension, some types cover multiple extensions (e.g., "JPEG Image" covers .JPG and .JPEG ), and others use extensions that are substrings of other extensions for unrelated types (e.g., "Markdown files" are .md , which is a substring of .mdb (an Access database) and .mdi (Microsoft Document Image file). If I want to search for "JPEG Image", or "Markdown file", and get only the required file types... how do I do it?
- Explorer, batch, or PowerShell solutions are acceptable.
- The ideal solution will work for both Windows 7 and Windows 10, but separate solutions for Windows 7 and Windows 10 are also acceptable.
- I would prefer not having to analyze and use explicit file extensions in the search.
- I'm unsure what you are asking. Are you trying to sort or search for files with a specific type? If you are trying to search for a specific type (Like .JPEG ), why do you not wish to search by the extension? – Cheesus Crust Commented May 16, 2017 at 19:47
- 1 Search, not sort; and searching by the extension in some cases will not get all of the files of the type (e.g., .JPEG misses the "JPEG Images" that are .JPG ), and in other cases will get too many files (e.g., .md in the Explorer search box will get not only "Markdown files", but "Access database files" ( .mdb )). – Jeff Zeitlin Commented May 16, 2017 at 19:49
- For the case of .JPG and .JPEG , since they are both technically .JPEG files. You can search using explorer by typing type:=.JPEG in the search box and it should find all .JPEG files, regardless of their extension – Cheesus Crust Commented May 16, 2017 at 19:53
- 1 Nope. type:=.JPEG omits .JPG . – Jeff Zeitlin Commented May 16, 2017 at 19:55
- Sorry, I mistyped. Give type:.jpeg a try. I just tested it now and it returned both .jpg and .jpeg files. – Cheesus Crust Commented May 16, 2017 at 20:00
2 Answers 2
A few things about Windows and the search function in the File Explorer:
- Windows doesn't know about mime-types such as "JPEG Image" or "Markdown file" (or their respective (sub-/super-)types
- The search is very powerful, if used correctly.
To answer your question:
To search for a specific extension (file type in Windows) use the search query:
- Search for all .md files and only those files (should be markdown files): type:".md" (remember the quotation marks, if you want an exact match)
- Search for all images: kind:=image (yes, you can search for this)
- You can combine all filters and search terms how you like it.
More info and examples here: https://www.howtogeek.com/73065/learn-the-advanced-search-operators-in-windows-7/
- +1. Although you can search for some files regardless of the sub types. Not sure about all types, but some allow you to. Such as .JPEG , which will find all of the sub types such as .JPE .JPG .JFIF if you search with type:.jpeg Also, it does not seem quotations are required, but return the same result. – Cheesus Crust Commented May 16, 2017 at 20:15
- @CheesusCrust the quotation marks are required when searching for an exact match. Otherwise .mdb files (like the OP stated) are found. – GiantTree Commented May 16, 2017 at 20:43
- Ah, I see. I thought the OP meant to find more rather than less. Whoops! Thanks for sharing the link too. – Cheesus Crust Commented May 16, 2017 at 20:44
- 2 type:".md" did not work (false negatives - no matches) when I tried it on Windows 10 (in a folder with 11 .md files). – Peter Mortensen Commented Aug 1, 2018 at 14:00
- 2 @GiantTree, as Peter Mortensen explains, type:".md" is not correct. It should be type:=".md" with an =. I'd suggest testing it, and then please update your answer. – Codesmith Commented Feb 12, 2021 at 16:26
To search in Windows using the "type:" syntax, you want to do
type:~ Note the tilde.
For example I wanted to find Word Documents, where if you're looking in explorer browser, the "Type" column will identify as "Microsoft Word Document", I used:
type:~"Microsoft Word Document"
The results returnd only Word Docs and even highlighted the text in the "Type" column.
I had tried repeatedly with type: and type:= to no avail, only the tilde ~ worked.
Hope this helps someone.
- Does this work for partial matches, and is it case-sensitive? For example, do I have to use "Microsoft Word Document", or is "word doc" going to be adequate (assuming that I don't have another application that calls itself "«something» Word") – Jeff Zeitlin Commented Jan 31, 2019 at 12:12
- In any search I've done anywhere the tilde has always meant partial match search or similar, so I'm going to say yes. – Mike Dannyboy Commented Feb 1, 2019 at 13:43
- In spite of the time lapse, I've rechecked this, and I need explicit wildcards to match on the "type name" - that is, if I want to match Word documents (and I don't have something other than MSWord that calls itself "Word"), I need to use type:~"*Word*" – Jeff Zeitlin Commented Jun 17, 2022 at 19:39
You must log in to answer this question.
Not the answer you're looking for browse other questions tagged windows search ..
- The Overflow Blog
- Scaling systems to manage all the metadata ABOUT the data
- Navigating cities of code with Norris Numbers
- Featured on Meta
- We've made changes to our Terms of Service & Privacy Policy - July 2024
- Introducing an accessibility dashboard and some upcoming changes to display...
Hot Network Questions
- Every time I see her, she said you've not been doing me again
- Is there a reason SpaceX does not spiral weld Starship rocket bodies?
- Why does a electron loses its energy when it enters a energy level in comparing of when in free state?
- How can electrons hop large distances if they are connected to the atom which is stationary in an lattice?
- To "Add Connector" or not to "Add Connector", that is a question
- Claims of "badness" without a moral framework?
- Why don't programming languages or IDEs support attaching descriptive metadata to variables?
- Embedding rank of finite groups and quotients
- How is delayed luggage returned to its owners in this situation?
- Do I need to verify file integrity after running qemu-img convert?
- test & train for very very small data
- What is the meaning of 'in the note'?
- What was I thinking when I drew this diagram?
- Why isn't the Liar's Paradox just accepted to be complete nonsense?
- How much air escapes into space every day, and how long before it makes Earth air pressure too low for humans to breathe?
- Proving an inequality involving a definite integral.
- Why is "a black belt in Judo" a metonym?
- I'm 78 and 57 years ago I was a 1 dan. Started karate at 5. I quit karate at 21 for reasons. Want to start again. Do not remember much. What do I do.?
- Sums of X*Y chunks of the nonnegative integers
- How does the Israeli administration of the Golan Heights affect its current non-Jewish population?
- Direct limits in homotopy category
- Looking for a story about a colonized solar system that has asteroid belts but no habitable planet
- Is it okay to mix accidentals when writing enharmonic notes in different parts?
- What is the interpretation of the word ' quickly' as used by Jesus in Jn 13:26-27?
- University of Michigan Library
- Research Guides
All About Images
- Image File Formats
- Raster vs. Vector Images
- Color Modes
- What is Resolution?
- What is Resizing?
- Use GIMP to Change Resolution
- Use GIMP to Resize an Image
RGB and CMYK
RGB or Red, Green and Blue, are additive colors and are what we see when we look at our computer monitors and televisions screens. The tiny dots that make up our displays are composed of RGB information. The RGB color space is very large and is ideal for images that would be used for web and presentation purposes.
CMYK or Cyan, Magenta, Yellow and Black, are subtractive colors are the standard ink colors for printing. This means that whenever we print an image, we are using CMYK inks to produce the print. Many professional printers or publishers require that images for print must be converted to CMYK before being printed. This is because the RGB color spectrum (displays) is much more wide then the CMYK spectrum (ink) and during conversion from RGB to CMYK, the appearance of certain colors may look different.
Image Transparency
What does it mean to save an image with transparency.
Notice the two images below:
- The image on the left was saved using a file format that did not support transparency and displays with an unwanted white background.
- The image on the right was saved using a transparency supported format and looks very crisp and clean on this colored background.
File types that support transparency: TIFF, PNG, GIF
Native File Fomats
Native file formats.
Not only are there image formats, but many applications have their own native file format. It is important to understand that there is a difference between a native file types and an image file types.
An example of a native file type is a .PSD which stands for Photoshop Document. This file is created only by Adobe Photoshop and can retain information such as layers, adjustments, masks, and other Photoshop adjustments.
It is always good to save a version of an image in the native format if you plan to make future edits to the image, because the native file format will keep all editing information.
Image Editors
Adobe Photoshop - (.PSD)
GIMP - (.XCF)
Illustration/Vector Art
Adobe Illustrator - (.AI)
CorelDRAW - (.CDR)
Common Image File Formats
There are numerous image file types out there so it can be hard to know which file type best suits your image needs. Some image types such as TIFF are great for printing while others, like JPG or PNG, are best for web graphics.
The list below outlines some of the more common file types and provides a brief description, how the file is best used, and any special attributes the file may have.
TIFF (.tif, .tiff)
TIFF or Tagged Image File Format are lossless images files meaning that they will not lose any image quality or information (although there are options for compression), allowing for very high-quality images but also larger file sizes.
Compression: Lossless - no compression. Very high-quality images. Best For: High quality prints, professional publications, archival copies Special Attributes: Can save transparencies Learn more about TIFF file types
Bitmap (.bmp)
BMP or Bitmap Image File is a format developed by Microsoft for Windows. There is no compression or information loss with BMP files which allow images to have very high quality, but also very large file sizes. Due to BMP being a proprietary format, it is generally deprecated in favor of TIFF files.
Compression: None Best For: High quality scans, archival copies Learn more about BMP file types
JPEG (.jpg, .jpeg)
GIF or Graphics Interchange Format files are widely used for web graphics, because they are limited to only 256 colors, can allow for transparency, and can be animated. GIF files are typically small in size and are very portable.
Compression: Lossless - compression without loss of quality Best For: Web Images Special Attributes: Can be Animated, Can Save Transparency Learn more about GIF file types
PNG or Portable Network Graphics files are a lossless image format originally designed to improve upon and replace the gif format. PNG files are able to handle up to 16 million colors, unlike the 256 colors supported by GIF.
Compression: Lossless - compression without loss of quality Best For: Web Images Special Attributes: Save Transparency Learn more about PNG file types
An EPS or Encapsulated PostScript file is a common vector file type. EPS files can be opened in many illustration applications such as Adobe Illustrator or CorelDRAW.
Compression: None - uses vector information Best For: Vector artwork, illustrations Special Attributes: Saves vector information Learn more about EPS file types
RAW Image Files (.raw, .cr2, .nef, .orf, .sr2, and more)
RAW images are images that are unprocessed that have been created by a camera or scanner. Many digital SLR cameras can shoot in RAW, whether it be a .raw, .cr2, or .nef. These RAW images are the equivalent of a digital negative, meaning that they hold a lot of image information, but still need to be processed in an editor such as Adobe Photoshop or Lightroom.
Compression: None Best For: Photography Special Attributes: Saves metadata, unprocessed, lots of information Learn more about RAW file types
Research Data Management Resources
- UMass Chan Data Resources
- NIH Data Management and Sharing Policy
- Data Privacy and Ethics
- Data Analysis and Cleaning
- Data Documentation
- File Management
Why Organize?
Good habits for structuring folders and files, good habits for file naming.
- File Storage and Backup
- Data Sharing Policies and Copyright
- Data Retention
- Data Citation
Sally Gore, MS, MS LIS Manager, Research & Scholarly Communication Services [email protected]
Tess Grynoch, MLIS Research Data & Scholarly Communications Librarian [email protected]
Leah Honor, MLIS Research Data & Scholarly Communications Librarian [email protected]
Lisa Palmer, MSLS, AHIP Institutional Repository Librarian [email protected]
Good management of data files allows you to efficiently identify, locate, and use your data. You can:
- Manage large amounts of various data files.
- Locate and browse for files easily.
- Distinguish different files and versions of files within a folder.
- Prevent confusion when working on teams or sharing files.
- Prevent data loss by accidentally overwriting or deleting files.
- Provide context for retrieval and storage of data.
File management encompasses:
- Structuring the hierarchical organization of file folders in a logical and clear way;
- Planning for the syntax and vocabulary of individual file names;
- Using agreed-upon conventions consistently.

- Consider all the types of files that you will handle during the course of the project.
- Develop a nested folder structure that makes the most sense for your project or team’s retrieval needs (think about categories and granularity).
- Name folders clearly, without special characters or floats, and avoid redundancy.
- Use a standard folder structure for each project or subproject (including making empty folders for files not yet created)
- Create a reference document that notes the purpose of different folders.
A key to well-organized data is a consistent file naming convention. Filenames can communicate much about a data file in less than 25 characters.
A filename is the chief identifier for a data file. ( MANTRA )
- Keep the filename short (about 25 characters)
- Use consistent elements, consistently
- Use the standard format for dates and times (YYYY-MM-DD-THH-MM-SS eg. 1999-09-19-T12-54-32).
- Avoid special characters, spaces, and case dependency
- When numbering, use the number of leading zeros necessary for the scale of your project (eg. up to 999 files, start with 001)
- Have a strategy for documenting versions
- Don’t overwrite file extensions
Filenames need to make sense for you and your project or team. Some elements to consider for a filename include:
- Project name
- Name of file creator
- Project number
- Sequence ID
- Accession number
- Date of creation
- Version number

- Best Practices for File Naming Compiled by the Stanford University Libraries. Includes links to two case studies, one highlighting poor file naming practices and one highlighting good file naming practices.
- Folder and File Naming -- 10 Rules for Best Practice Written by Vincent Santaguida of MultiCIM Technologies (2010).
- MIT Data Management MIT resources on organizing data, including links to workshop materials on file naming and versioning. Available under a CC-BY-NC-SA license.
- Bulk Rename Utility Free file-renaming utility for Windows enables quick naming of files and folders.
- Namechanger Free, filenaming utility for Mac with flexible commands and options for selective renaming.
- << Previous: Data Documentation
- Next: File Storage and Backup >>
- Last Updated: Aug 6, 2024 1:37 PM
- URL: https://libraryguides.umassmed.edu/research_data_management_resources
Research Data Management
- Directory Structures
File Organization
One of the most essential aspects of data management is organizing your data. This includes several elements, including thinking through names, structures, and relationships.
Researchers are advised to structure their folders (whether paper or electronic in form) to correspond to how the records were generated and to complement proposed or existing workflows.
- Filing structures enable research processes to be more transparent, make it easier for investigators to determine where files should be saved, and ultimately make retrieval and archiving more efficient
- Established file plans demonstrate consistency and continuity in recordkeeping
- Before you even start collecting or working with data, you should decide how you will structure and name files and folders to allow for standardized data collecting and analysis by many team members
- Dryad's Good data practices includes examples of how to organize files in a logical schema
Organization Strategies
Organize your data hierarchically, and identify ways to divide your data into categories (or attributes):
Within folders, files can be maintained chronologically, by classification or code, or alphabetically (depending on the types of files)
- Folder and subfolder names should reflect the content of the folder, not the names of researchers or staff
- Document your file directory structure and describe the kinds of records that should be maintained in those folders to ensure compliance
- Include basic information, such as project titles, dates, and some type of unique identifier (such as a grant number)
- Restrict access at the appropriate folder level
- << Previous: Data Policies & Compliance
- Next: File Naming Conventions >>
- Data Management Plans
- Data Policies & Compliance
- File Naming Conventions
- Roles & Responsibilities
- Collaborative Tools & Software
- Electronic Lab Notebooks
- Documentation & Metadata
- Reproducibility
- Analysis Ready Datasets
- Image Management
- Version Control
- Data Storage
- Data & Safety Monitoring
- Data Privacy & Confidentiality
- Retention & Preservation
- Data Destruction
- Data Sharing
- Public Access
- Data Transfer Agreements
- Intellectual Property & Copyright
- Unique Identifiers
- Data Repositories
Research Support
Request a data management services consultation.
Email [email protected] to schedule a consultation related to the organization, storage, preservation, and sharing of data.
- Last Updated: May 23, 2024 10:37 AM
- URL: https://guides.library.ucdavis.edu/data-management
- Privacy Policy
Home » Table of Contents – Types, Formats, Examples
Table of Contents – Types, Formats, Examples
Table of Contents

Definition:
Table of contents (TOC) is a list of the headings or sections in a document or book, arranged in the order in which they appear. It serves as a roadmap or guide to the contents of the document, allowing readers to quickly find specific information they are looking for.
A typical table of contents includes chapter titles, section headings, subheadings, and their corresponding page numbers.
The table of contents is usually located at the beginning of the document or book, after the title page and any front matter, such as a preface or introduction.
Table of Contents in Research
In Research, A Table of Contents (TOC) is a structured list of the main sections or chapters of a research paper , Thesis and Dissertation . It provides readers with an overview of the organization and structure of the document, allowing them to quickly locate specific information and navigate through the document.
Importance of Table of Contents
Here are some reasons why a TOC is important:
- Navigation : It serves as a roadmap that helps readers navigate the document easily. By providing a clear and concise overview of the contents, readers can quickly locate the section they need to read without having to search through the entire document.
- Organization : A well-structured TOC reflects the organization of the document. It helps to organize the content logically and categorize it into easily digestible chunks, which makes it easier for readers to understand and follow.
- Clarity : It can help to clarify the document’s purpose, scope, and structure. It provides an overview of the document’s main topics and subtopics, which can help readers to understand the content’s overall message.
- Efficiency : This can save readers time and effort by allowing them to skip to the section they need to read, rather than having to go through the entire document.
- Professionalism : Including a Table of Contents in a document shows that the author has taken the time and effort to organize the content properly. It adds a level of professionalism and credibility to the document.
Types of Table of Contents
There are different types of table of contents depending on the purpose and structure of the document. Here are some examples:
Simple Table of Contents
This is a basic table of contents that lists the major sections or chapters of a document along with their corresponding page numbers.
Example: Table of Contents
I. Introduction …………………………………………. 1
II. Literature Review ………………………………… 3
III. Methodology ……………………………………… 6
IV. Results …………………………………………….. 9
V. Discussion …………………………………………. 12
VI. Conclusion ……………………………………….. 15
Expanded Table of Contents
This type of table of contents provides more detailed information about the contents of each section or chapter, including subsections and subheadings.
A. Background …………………………………….. 1
B. Problem Statement ………………………….. 2
C. Research Questions ……………………….. 3
II. Literature Review ………………………………… 5
A. Theoretical Framework …………………… 5
B. Previous Research ………………………….. 6
C. Gaps and Limitations ……………………… 8 I
II. Methodology ……………………………………… 11
A. Research Design ……………………………. 11
B. Data Collection …………………………….. 12
C. Data Analysis ……………………………….. 13
IV. Results …………………………………………….. 15
A. Descriptive Statistics ……………………… 15
B. Hypothesis Testing …………………………. 17
V. Discussion …………………………………………. 20
A. Interpretation of Findings ……………… 20
B. Implications for Practice ………………… 22
VI. Conclusion ……………………………………….. 25
A. Summary of Findings ……………………… 25
B. Contributions and Recommendations ….. 27
Graphic Table of Contents
This type of table of contents uses visual aids, such as icons or images, to represent the different sections or chapters of a document.
I. Introduction …………………………………………. [image of a light bulb]
II. Literature Review ………………………………… [image of a book]
III. Methodology ……………………………………… [image of a microscope]
IV. Results …………………………………………….. [image of a graph]
V. Discussion …………………………………………. [image of a conversation bubble]
Alphabetical Table of Contents
This type of table of contents lists the different topics or keywords in alphabetical order, along with their corresponding page numbers.
A. Abstract ……………………………………………… 1
B. Background …………………………………………. 3
C. Conclusion …………………………………………. 10
D. Data Analysis …………………………………….. 8
E. Ethics ……………………………………………….. 6
F. Findings ……………………………………………… 7
G. Introduction ……………………………………….. 1
H. Hypothesis ………………………………………….. 5
I. Literature Review ………………………………… 2
J. Methodology ……………………………………… 4
K. Limitations …………………………………………. 9
L. Results ………………………………………………… 7
M. Discussion …………………………………………. 10
Hierarchical Table of Contents
This type of table of contents displays the different levels of headings and subheadings in a hierarchical order, indicating the relative importance and relationship between the different sections.
A. Background …………………………………….. 2
B. Purpose of the Study ……………………….. 3
A. Theoretical Framework …………………… 5
1. Concept A ……………………………….. 6
a. Definition ………………………….. 6
b. Example ……………………………. 7
2. Concept B ……………………………….. 8
B. Previous Research ………………………….. 9
III. Methodology ……………………………………… 12
A. Research Design ……………………………. 12
1. Sample ……………………………………. 13
2. Procedure ………………………………. 14
B. Data Collection …………………………….. 15
1. Instrumentation ……………………….. 16
2. Validity and Reliability ………………. 17
C. Data Analysis ……………………………….. 18
1. Descriptive Statistics …………………… 19
2. Inferential Statistics ………………….. 20
IV. Result s …………………………………………….. 22
A. Overview of Findings ……………………… 22
B. Hypothesis Testing …………………………. 23
V. Discussion …………………………………………. 26
A. Interpretation of Findings ………………… 26
B. Implications for Practice ………………… 28
VI. Conclusion ……………………………………….. 31
A. Summary of Findings ……………………… 31
B. Contributions and Recommendations ….. 33
Table of Contents Format
Here’s an example format for a Table of Contents:
I. Introduction
C. Methodology
II. Background
A. Historical Context
B. Literature Review
III. Methodology
A. Research Design
B. Data Collection
C. Data Analysis
IV. Results
A. Descriptive Statistics
B. Inferential Statistics
C. Qualitative Findings
V. Discussion
A. Interpretation of Results
B. Implications for Practice
C. Limitations and Future Research
VI. Conclusion
A. Summary of Findings
B. Contributions to the Field
C. Final Remarks
VII. References
VIII. Appendices
Note : This is just an example format and can vary depending on the type of document or research paper you are writing.
When to use Table of Contents
A TOC can be particularly useful in the following cases:
- Lengthy documents : If the document is lengthy, with several sections and subsections, a Table of contents can help readers quickly navigate the document and find the relevant information.
- Complex documents: If the document is complex, with multiple topics or themes, a TOC can help readers understand the relationships between the different sections and how they are connected.
- Technical documents: If the document is technical, with a lot of jargon or specialized terminology, This can help readers understand the organization of the document and locate the information they need.
- Legal documents: If the document is a legal document, such as a contract or a legal brief, It helps readers quickly locate specific sections or provisions.
How to Make a Table of Contents
Here are the steps to create a table of contents:
- Organize your document: Before you start making a table of contents, organize your document into sections and subsections. Each section should have a clear and descriptive heading that summarizes the content.
- Add heading styles : Use the heading styles in your word processor to format the headings in your document. The heading styles are usually named Heading 1, Heading 2, Heading 3, and so on. Apply the appropriate heading style to each section heading in your document.
- Insert a table of contents: Once you’ve added headings to your document, you can insert a table of contents. In Microsoft Word, go to the References tab, click on Table of Contents, and choose a style from the list. The table of contents will be inserted into your document.
- Update the table of contents: If you make changes to your document, such as adding or deleting sections, you’ll need to update the table of contents. In Microsoft Word, right-click on the table of contents and select Update Field. Choose whether you want to update the page numbers or the entire table, and click OK.
Purpose of Table of Contents
A table of contents (TOC) serves several purposes, including:
- Marketing : It can be used as a marketing tool to entice readers to read a book or document. By highlighting the most interesting or compelling sections, a TOC can give readers a preview of what’s to come and encourage them to dive deeper into the content.
- Accessibility : A TOC can make a document or book more accessible to people with disabilities, such as those who use screen readers or other assistive technologies. By providing a clear and organized overview of the content, a TOC can help these readers navigate the material more easily.
- Collaboration : This can be used as a collaboration tool to help multiple authors or editors work together on a document or book. By providing a shared framework for organizing the content, a TOC can help ensure that everyone is on the same page and working towards the same goals.
- Reference : It can serve as a reference tool for readers who need to revisit specific sections of a document or book. By providing a clear overview of the content and organization, a TOC can help readers quickly locate the information they need, even if they don’t remember exactly where it was located.
About the author

Muhammad Hassan
Researcher, Academic Writer, Web developer
You may also like

Research Techniques – Methods, Types and Examples

What is a Hypothesis – Types, Examples and...

Research Paper Outline – Types, Example, Template

Informed Consent in Research – Types, Templates...

Research Paper Format – Types, Examples and...

Research Summary – Structure, Examples and...
- Trending Now
- Foundational Courses
- Data Science
- Practice Problem
- Machine Learning
- System Design
- DevOps Tutorial
List of File Formats with Types and Extensions
File Formats store a large variety of raw information in a structured format so that the data can be easily stored, processed, and harnessed. A file format is a standard way of storing data on a computer file. There are multiple types of file formats present which can be used to store and retrieve data efficiently. We will discuss the unique features and use cases for different kinds of file formats and compare them.

As the technology is growing it has become more important to save the data in an organised and structured manner.
Table of Content
Most Used file formats
Text file formats, image file formats, audio file formats, video file formats, program file formats, compressed/archive file formats, web page file formats, features of file formats.
Explore a wide range of common file formats and learn how to work with them effectively.
- Text: This type of file contains only text without any formatting and can be opened with any text editor. Different types of text formats include: .doc, .docx, .rtf, .pdf, .wpd
- Image: This file type includes binary information about images and defines how the image will be stored and compressed. Different types of Image File Format include: .JPEG, .PNG, .GIF, .HEIF
- Audio: This type of file format stores audio data. It stores raw data in an encoded format and uses codec to perform compression and decompression. Different types of Audio file formats include .aac, .mp3, .wav
- Video: This type of file format contains digital video data. It performs lossy compression to store video data where audio and video are separately encoded and stored. Different types of Video File Formats include: .amv, .mpeg, .flv, .avi
- Program: These file formats store codes that can be run on the computer through compiling or interpreting. Different types of Programming File Formats include: .c, .java, .py, .js
- Compressed/Archive: These files store data in a compressed format on the computer and can be used to easily transport data between computers. These files need to be decompressed before use. Different types of Compressed File Formats include: .iso, .rar, .tar, .7z
- Web page: These files include information related to the website, web pages, and server. these generally include programming scripts for static or dynamic web pages. Different types of Web Page File Format include: .html, .asp, .css, .xps.
Recent File format published articles .
| Plain Text | The most basic text file format, containing only ASCII characters and carriage returns to separate lines. | |
| Rich Text Format | A more advanced text file format that allows basic formatting like bold, italics, and font styles. | |
| Word Open XML Document | Commonly used by Microsoft Word for storing and saving documents | |
| Comma-Separated Values | A simple format for storing tabular data, with each row representing a data record and commas separating fields. | |
| Word Document | Used for word processing documents stored in Microsoft Word Binary File Format | |
| WPS Office Word Document | A proprietary document file format developed by Kingsoft Office. | |
| WordPerfect Document | A document file format associated with WordPerfect, a word processing software. | |
|
| Message | Microsoft Outlook message format; contains email messages with formatting, attachments, and other information. |
| .jpg | Joint Photographic Experts Group | A lossy compression format that is commonly used for photographs and other images with a lot of detail. |
|---|---|---|
| .png | Portable Network Graphics | A lossless compression format that is commonly used for images with sharp edges or text. |
| .webp | Web Picture Format | It Supports both lossy and lossless image compression with support of 24-bit RGB color. |
| Graphics Interchange Format | The limited-color format is commonly used for animations and small images. | |
| .tif | Tagged Image File Format | High-quality format that is commonly used for professional photography and printing. |
| .bmp | Bitmap | An uncompressed format that is commonly used by Microsoft Windows. |
| .eps | Encapsulated PostScript file | A vector format that is commonly used for print graphics. |
| .mp3 | MP3 Audio File | Commonly used for storing and distributing music. |
|---|---|---|
| Windows Media Audio | Developed by Microsoft for audio compression, often used for streaming and downloading music. | |
| Sound | A generic file extension for sound files, often associated with audio data. | |
| WAVE Audio File | Commonly used for storing and recording audio. | |
| RealAudio | It’s a playlist file format that is commonly used for storing and distributing playlists. | |
|
| Audio | Used for storing audio data, commonly associated with Sun Microsystems. |
|
| Advanced Audio Coding | Used as an in-vogue sound field design for packed virtual sound and tune data. |
| MPEG-4 Video File | Multimedia container format that commonly stores video and audio data. | |
| .3gp | 3GPP Multimedia File | Multimedia container format that is commonly used for mobile phones. |
| .avi | Audio Video Interleave File | An older multimedia container format that is still supported by many devices. |
| .mpg | MPEG Video File | Older video compression format that is still supported by some devices. |
| Apple QuickTime Movie | The format that is commonly used by Apple devices. | |
| Windows Media Video File | The format that is commonly used by Microsoft devices. |
| C/C++ Source Code File | General-purpose programming language developed by Dennis Ritchie at Bell Labs between 1969 and 1972. | |
| C++ source Code File | A general-purpose programming language developed by Bjarne Stroustrup as an extension to the C programming language. | |
| Java Source Code File | Programming language created by Sun Microsystems that is now owned by Oracle Corporation. | |
| Python script | The programming language was developed by Guido van Rossum and first released in 1991. | |
| JavaScript | A scripting language that is primarily used to add interactivity to web pages. | |
| TypeScript | A superset of JavaScript that adds optional static typing. | |
| C# Ssource Code File | A programming language developed by Microsoft as part of the .NET framework. | |
| Swift Source Code File | Programming language developed by Apple for developing iOS, macOS, watchOS, tvOS, and Linux applications | |
| .dta | Document Type Definition File | A data storage format commonly used by Stata, a statistical software program. |
| Perl Script | A programming language developed by Larry Wall at the University of California, Santa Cruz in the early 1980s. | |
| .sh | Bash Shell Script | A shell scripting language commonly used to automate tasks on Unix-like operating systems |
|
| Batch file | Batch file format used to automate tasks on Windows systems; contains a series of commands to be executed by the command interpreter. |
|
| Command file | A COM file is an executable file format used for programs on older Windows systems. COM files have limited functionality compared to modern formats. |
|
| Executable file | An executable file is a type of computer file that contains compiled code that can be run directly by the operating system. Executable files are commonly used to run programs. |
| WinRAR Compressed Archive | A proprietary file archiver developed by Eugene Roshal. | |
| Zipped File | A lossless data compression format that packages multiple files into a single archive file. | |
| BinHex | A Macintosh binary-to-text encoding format, often used to transfer binary files through email. | |
| Archived by Robert Jung | A file compression format, similar to ZIP and RAR, used to compress and archive files. | |
| Compressed Tarball File | This file archiving format groups multiple files into a single archive file. | |
|
| ARC archive file | An ARC file is an archive file format used for compressing and storing files. ARC is an outdated format and has been replaced by ZIP and other newer options. |
|
| StuffIt archive file | A SIT file is an archive file format used on Macintosh systems. SIT is similar to ARC but is specific to Macs. |
|
| GZIP compressed file | A GZ file is a file format created with gzip compression. Gzip shrinks the size of files for storage and transmission. |
|
| Compressed file | A Z file is a compressed file format associated with the “compress” compression program on Unix systems. |
| HyperText Markup Language File | HTML is the standard markup language for creating web pages. | |
|
| HyperText Markup Language File | Hypertext Markup Language (HTML) document format with the less common file extension; identical to .html files. |
| .xhtml | Extensible Hypertext markup language File | This is a markup language that combines HTML with XML. |
| .asp | Active Server page | A web development technology that allows developers to create dynamic web pages using server-side scripting. |
| Cascading Style Sheet | This is a style sheet language used to describe the presentation of a web page. | |
| .aspx | Active Server Page Extended File | This allows developers to create dynamic web pages using server-side scripting in ASP.NET. |
| Rich Site Summary | This is a web feed format that allows users to subscribe to updates from websites. |
- Structure Data: File Formats have a basic structure of how data should be stored in the file.
- Extension: Extensions are useful so that the operating system can check which type of file is being used.
- Metadata: This is the data that stores useful information about the file such as author name, license, etc.
- Interoperability: This feature enables multiple systems to use the same file format.
FAQs(Frequently Asked Questions):
What is the importance of file formats.
Ans. File formats are necessary as they help to determine in what structure the data will be stored, accessed, processed, archived and processed. It sets a standard to store information in a computer file.
What is a file extension and why it is important?
Ans. File extension are characters written after period symbol in a file name. They are used by the operating systems to define which program is the file associated with. File extensions indicate the file format and cannot be renamed.
What are JSON, CSV and XMl file formats used for?
Ans. JSON is used for data exchange in modern day web development as it is lightweight and compact. CSV is used when the amount of data to send is large and there are bandwidth issues. XML was used in document markups and its popularity has decreased after the introduction of JSON.
How to choose a file format for storing data for a project?
Ans. To choose a data format, we should have a clear understanding of what type of data we are going to work with. If the data is to be kept lightweight and compact we should prefer JSON format for storing data. If we want a structure data in format of row and column an the amount of data is large we should use XML anf if we are working on legacy projects we will generally work with XML data format for document markups.
Please Login to comment...
- File Formats
Improve your Coding Skills with Practice
What kind of Experience do you want to share?
- UNC Libraries
- Course Guides
- ENGL105 - Scholarly Articles 101
Types of Scholarly Articles
Engl105 - scholarly articles 101: types of scholarly articles.
- Peer-review
- Other Types of Sources
Research Articles
Review articles, tips & practice.
- How to Read a Scholarly Article
- Extend Your Knowledge
Sometimes a professor might ask you to find original research or may ask you to not use literature reviews/systematic reviews as sources, but what do those terms mean? How can we tell if our potential source meets our professor's criteria?
In a research article, an original study is conducted by the authors. They collect and analyze data, sharing their methods and results, and then draw conclusions from their analysis. The kind of study performed can vary (surveys, interviews, experiments, etc.), but in all cases, data is analyzed and a new argument is put forth. Research articles are considered primary sources.
- Note: research articles will often contain a section titled "literature review" - this is a section that looks at other existing research as a foundation for their new idea. Simply seeing the words "literature review" does not automatically mean an article is a review article- it is important to look closer
Below is a screenshot of the abstract of the article Effectiveness of Health Coaching in Diabetes Control and Lifestyle Improvement: A Randomized-Controlled Trial , with some words underlined that let us know that a study was conducted and that this is a research article.

A review article gathers multiple research articles on a certain topic, summarizing and analyzing the arguments made in those articles. A review article might highlight patterns or gaps in the research, might show support for existing theories, or suggest new directions for research, but does not conduct original research on a subject. Review articles can be a great place to get an overview of the existing research on a subject. A review article is a secondary source.
- Looking in the reference section of a literature or systematic review can be a good place to find original research studies.
Below is a screenshot of the abstract of the article The Effect of Dietary Glycaemic Index on Glycaemia in Patients with Type 2 Diabetes: A Systematic Review and Meta-Analysis of Randomized Controlled Trials , with words underlined that clue us in that this is a review article.

Tips for identifying article type
Start by looking at the abstract to determine if a source might be a research article or a review article. If you're not sure after looking at the abstract, find the methods section for the source - what methods did the authors use? If they mention searching databases, it's most likely a review and if they mention conducting an experiment, survey, interview, etc., it's most likely a research article. If you're still unsure, feel free to reach out to a librarian and ask !
Let's Practice
Below are two different scholarly articles. Look at the abstract and the methods section- Which one is an original research study? Which one is a literature review?
- Article 1- Research or Review?
- Article 2- Research or Review?
Research & Instruction Associate

- << Previous: Anatomy of a Scholarly Article
- Next: How to Read a Scholarly Article >>
- Last Updated: Aug 7, 2024 2:00 PM
- URL: https://guides.lib.unc.edu/scholarly-articles-101
IMAGES
COMMENTS
For example, when you have spreadsheet-based (aka tabular) data save the file as Comma-separated values (.csv) instead of Excel (.xls, .xlsx) and for text files use Plain text (.txt) or PDF/A (.pdf) instead of Microsoft Word (.doc, .docx). Repositories may provide a list of preferred files formats (see Dryad's File Types Guidance).
Hi, You can use the syntax ext:<extension name> in searching for files based on the file type or extension. For example, to look for .txt files, you can use ext:.txt as a search query. The complete documentation regarding the Advanced Query Syntax (AQS) for Microsoft Windows Desktop Search (WDS) can be found on this link. Regards.
3.1 Set Up a File Organization System. Description: Implementing a file organization system is the first step toward creating order for your research data. Well-organized files make it easier to find the data you need without spending lots of time searching your computer. Every researcher organizes their files slightly differently, but the actual organizational system is less important that ...
Data types generally fall into five categories: Observational. - Captured in situ. - Can't be recaptured, recreated or replaced. - Examples: Sensor readings, sensory (human) observations, survey results. Experimental. - Data collected under controlled conditions, in situ or laboratory-based. - Should be reproducible, but can be expensive.
A research file could be a word document, or a notebook, or a pile of paper in a folder, or a program like EverNote or OneNote, or a bibliographic software like EndNote. It's simply a place were you keep notes about the things you found. Taking notes about your research is something that can save your sanity. Be kind to your future self:
To search Google by filetype, you simply need to use the filetype: search operator together with your query. This will filter the results to only show the file type you specified. The most common file types include PDF, PPT, DOC, TXT, & XSL. To learn more about this type of search, I encourage you to read the entire article (below).
File Naming Conventions. Best practice for file naming is that the names are descriptive of the contents of the file. The goal is to be able to understand and recall at a glance what is in any given file. Some potential attributes and information to include are: Date and time. Researcher name or laboratory. Data type.
Location/spatial coordinates. Researcher name/initials. Date or date range of project. Type of data. Conditions. Version number of file. Three-letter file extension for application-specific files. A good format for date designations is YYYYMMDD or YYMMDD. This format makes sure all of your files stay in chronological order.
Research data takes many forms. Any one project may have multiple examples of these types of data. Documents, spreadsheets; Questionnaires, surveys; ... Proprietary file types should be avoided, and the open file types are preferred: Data Type. Proprietary (AVOID) Open (PREFERRED) Containers . TAR, GZIP, ZIP. Databases . XML, CSV. Text.
Standardized open source formats can be more robust than proprietary formats because they are not reliant on the continuing existence of a single company to be maintained. Some preferred open formats include: Text: ASCII, UTF-8, XML, PDF/A, HTML. Images: TIFF, JPEG 2000, PNG, GIF. Tabular data: XML, CSV. Video: MOV, MPEG, AVI, MXF.
FILE FORMAT SELECTION. Ideally, file types for a project should be standard, non-proprietary, and open source. If these features are not possible, at the very least file format selection should be made with sustainability and long-term use in mind. Try opening a Windows 95 Word Document on your modern computer, and you'll understand why (hint ...
Formatting a Chicago paper. The main guidelines for writing a paper in Chicago style (also known as Turabian style) are: Use a standard font like 12 pt Times New Roman. Use 1 inch margins or larger. Apply double line spacing. Indent every new paragraph ½ inch. Place page numbers in the top right or bottom center.
Handling encrypted files requires specialized knowledge of encryption algorithms and keys. Decryption algorithms need to be integrated into file type detection tools to unlock the encrypted content and determine the file type. Similarly, compressed files need to be decompressed to access the underlying data and identify the file type accurately.
Now click on "Settings" at the bottom and on the far right. google settings to search by file type. In the menu that now appears, click on "Advanced Search". On the page that appears, click on "Narrow results" under "File type" (where it says "All formats") Now select the desired file type and click on it. After you have ...
Using Internet Search Engines. Internet search engines can help you search for a particular file type to match an unknown file extension. First search on the full file name. If that does not yield any useful results consider using the search term: .ext file. Replace ".ext" above with the extension of interest and leave the word "file" with it ...
Research paper format is an essential aspect of academic writing that plays a crucial role in the communication of research findings.The format of a research paper depends on various factors such as the discipline, style guide, and purpose of the research. It includes guidelines for the structure, citation style, referencing, and other elements of the paper that contribute to its overall ...
An RIS file is a bibliographic citation file saved in a format developed by Research Information Systems (RIS). It contains a series of two-letter tags and citation information associated with those tags. This information might include a cited work's type, author, publication date, title, and more.
This is a list of file formats used by computers, organized by type. Filename extension is usually noted in parentheses if they differ from the file format's name or abbreviation. Many operating systems do not limit filenames to one extension shorter than 4 characters, as was common with some operating systems that supported the File Allocation Table (FAT) file system.
Google can index the content of most text-based files and certain encoded document formats. The most common file types we index include: Adobe Portable Document Format (.pdf) Adobe PostScript (.ps) Comma-Separated Values (.csv) Electronic Publication (.epub)
To answer your question: To search for a specific extension (file type in Windows) use the search query: Search for all .md files and only those files (should be markdown files): type:".md" (remember the quotation marks, if you want an exact match) Search for all images: kind:=image (yes, you can search for this) You can combine all filters and ...
The list below outlines some of the more common file types and provides a brief description, how the file is best used, and any special attributes the file may have. TIFF (.tif, .tiff) TIFF or Tagged Image File Format are lossless images files meaning that they will not lose any image quality or information (although there are options for ...
File Extensions . FM research has looked at file types or extensions, in terms of their numbers, for the most common types of files stored (Agrawal, Bolosky, Douceur & Lorch, 2007; Jensen, et al., 2010; Henderson, 2011; Dinneen & Julien, 2019). But, in terms of their usefulness in the practice of file management, little can be found. Blanc-Brude &
Manage large amounts of various data files. Locate and browse for files easily. Distinguish different files and versions of files within a folder. Prevent confusion when working on teams or sharing files. Prevent data loss by accidentally overwriting or deleting files. Provide context for retrieval and storage of data. File management encompasses:
Table 1 lists most research works and software in the literature for file type identification. We can draw the following conclusions. All scientific papers on file type identification are based on machine learning (Sester et al., 2021).The number of file types (or classes in this case) is quite low since the approach does not scale very well.
Filing structures enable research processes to be more transparent, make it easier for investigators to determine where files should be saved, and ultimately make retrieval and archiving more efficient ... File type; Within folders, files can be maintained chronologically, by classification or code, or alphabetically (depending on the types of ...
In Microsoft Word, go to the References tab, click on Table of Contents, and choose a style from the list. The table of contents will be inserted into your document. Update the table of contents:If you make changes to your document, such as adding or deleting sections, you'll need to update the table of contents.
Most Used file formats. Explore a wide range of common file formats and learn how to work with them effectively. Text: This type of file contains only text without any formatting and can be opened with any text editor. Different types of text formats include: .doc, .docx, .rtf, .pdf, .wpd Image: This file type includes binary information about images and defines how the image will be stored ...
Types of Scholarly Articles. ... Research Articles. In a research article, an original study is conducted by the authors. They collect and analyze data, sharing their methods and results, and then draw conclusions from their analysis. The kind of study performed can vary (surveys, interviews, experiments, etc.), but in all cases, data is ...