- COVID-19 Tracker
- Biochemistry
- Anatomy & Physiology
- Microbiology
- Neuroscience
- Animal Kingdom
- NGSS High School
- Latest News
- Editors’ Picks
- Weekly Digest
- Quotes about Biology

DNA Replication
Reviewed by: BD Editors
DNA replication is a process that occurs during cellular division where two identical molecules of DNA are created from a single molecule of DNA. As a semiconservative process, a single molecule containing two strands of DNA in double helix formation is separated, where each strand serves as a template for the new DNA molecules. Because the double helix is anti-parallel and DNA polymerase only synthesizes new DNA from 5′-3′, the template strand reading 3′-5′ results in a continuous, leading strand, while the template strand reading 5′-3′ results in a discontinuous, lagging strand. Being a highly regulated process, multiple proteins are required both during and following replication to quickly correct mistakes and damages.

Deoxyribonucleic acid, known simply as DNA, is the blueprint of all living things. DNA contains genes that code for the physical and metabolic information expressed in an individual while having the potential to be passed down to future offspring. Almost all cells have DNA, which is typically stored in the nucleus. Notable cells that lack DNA include anucleate cells (or cells that lack a nucleus, such as red blood cells). Additionally, some cells may still have DNA despite not having a nucleus, such as with bacterial cells.
DNA Nucleotides
DNA is made up of four building block monomers that are known as nucleotides . Nucleotides consists of three groups:
- A deoxyribose sugar group
- A phosphate group
- A nitrogenous base

All of the nucleotides have the same sugar group and phosphate group, but different nitrogenous bases. The nitrogenous bases in DNA are adenine, guanine, cytosine, and thymine. Adenine and guanine are classified as purines , while cytosine and thymine are classified as pyrimidines . Purines have two rings in their base structures, while pyrimidines have a single ring in their base structures.
(Helpful hint: A simple pneumonic to remember adenine and guanine as purines is “ Pur e A s G old”!)
DNA Structure
Nucleotides are arranged into chains that become individual strands of DNA, which is half of a full DNA molecule. Each strand has a sugar-phosphate backbone that is created when the phosphate of one nucleotide binds to the sugar of the next using a covalent phosphodiester bond . Specifically, the phosphate is found on the 5′ carbon of one nucleotide, while a hydroxyl group (-OH) is found on the 3′ carbon of the next nucleotide’s sugar group. The -OH of the 3′ carbon is removed, where the phosphate group on the 5′ carbon now also bonds to the 3′ carbon.

The nitrogenous bases stick out from this backbone. A second DNA strand is matched to this first strand based on complimentary base pairing , where a single purine pairs with a single pyrimidine. Specifically, adenine pairs with thymine and guanine pairs with cytosine. Hydrogen bonds connect the complimentary base pairs, where an adenine- thymine pair has two hydrogen bonds and a guanine-cytosine pair has three hydrogen bonds. A single DNA molecule results in double helix formation when two DNA strands are matched and bonded.
DNA has directionality that can run either 3′-5′ or 5′-3′ based off of the carbons in the sugar group. The two strands of DNA in the double helix must run opposite to each other in an anti-parallel fashion. Therefore, if the first strand starts at the 3′ end and finishes at the 5′ end, then the second strand must run opposite, starting at the 5′ end and finishing at the 3′ end.
3′- AATCGTAA -5′
5′- TTAGCATT -3′
DNA Replication Is Semiconservative
DNA must be fully replicated before cells divide via mitosis to ensure all daughter cells have identical DNA. It was discovered that DNA replication is semiconservative . In semiconservative replication, the double helix splits into two separate strands. During the replication process, an entirely new strand of DNA is created by using the original template strand and matching the complimentary bases.
DNA Replication Process

Proteins in DNA Replication
DNA replication is highly regulated and requires multiple proteins to run efficiently. A majority of these proteins act as stabilizers and enzymes, with enzymes being proteins that behave as catalysts to create and speed up biochemical reactions.
Some of the major proteins in DNA replication include the following:
Helicase : An enzyme that opens the double helix by breaking the hydrogen bonds between complimentary base pairs
Single-strand DNA- binding proteins (SSBPs) : These proteins stabilize the individual strands of DNA to prevent them from reconnecting.
Topoisomerase : Because unwinding of the DNA by helicase creates tension further down the strand, this enzyme relieves tension by making cuts in the DNA and rejoining them before the replication fork arrives.
Primase : An enzyme that adds a primer (which is a short segment of ribonucleic acid, known as RNA) where DNA polymerase III will attach
DNA polymerase III : An enzyme that creates the new DNA strand by adding nucleotides that are complimentary to the template strand
DNA polymerase I : An enzyme that replaces the RNA primer with DNA
DNA ligase : An enzyme that connects the Okazaki fragments on the lagging strand by closing the sugar-phosphate backbone, creating a single DNA strand
Sliding clamp : A protein that holds DNA polymerase III in place
The Replication Bubble
When DNA begins to replicate, a replication bubble is formed that can be detected visually by electron microscopy. A specific sequence of bases- known as the origin of replication – determines where this replication bubble begins. Inside of the bubble, two Y-shaped replication forks result where DNA is actively replicated on either side of the region. The replication forks are formed as the double strands of DNA are separated by helicase in both directions away from the origin of replication. It is at the replication fork that DNA replication proteins attach to fulfill their functions.
Replicating the Leading Strand
As mentioned previously, DNA strands have an anti-parallel nature, where one strand will run 3’-5’ and the other will run opposite from 5’- 3’. DNA polymerase can only synthesize new strands of DNA in the 5’-3’ direction. In order for DNA polymerase to do this, it must read the template strand from 3′-5′. Therefore, replicating the template strand that runs 3’-5’ results in the synthesis of the leading strand . The leading strand is a new strand of DNA that is synthesized in a single, continuous chain that starts at the 5’ end and finishes at the 3’ end.

DNA replication of the leading strand when the 3’-5’ template strand is used is as follows:
- The DNA double helix is opened by helicase into individual strands. Topoisomerase relieves the tension further down the double helix.
- SSBPs stabilize the single DNA strands to prevent them from reconnecting.
- An RNA primer is added to the leading strand at complimentary bases by primase.
- DNA polymerase III attaches to the primer. The sliding clamp stabilizes DNA polymerase III.
- DNA polymerase III moves down the leading strand towards the replication fork , adding bases to the new strand from the 5’ end to the 3’ end.
Replicating the Lagging Strand
DNA polymerase can only create new DNA strands from 5’-3’. Therefore, when the 5′-3′ template strand is being replicated- where the new strand must run opposite in the 3′-5′ direction- the new strand cannot be synthesized in a continuous fashion as the leading strand was. To overcome this challenge, additional steps are needed to replicate the 5′-3′ template strand, where this newly synthesized strand is known as the lagging strand .
In order for the lagging strand to be synthesized, DNA needs to be broken down into smaller segments known as Okazaki fragments . Because of these multiple segments, the lagging strand is also known as the discontinuous strand . By creating these multiple segments, DNA polymerase III is able to synthesize a small portion of the new DNA strand away from the replication fork in the correct 5′-3′ direction. As the replication fork continues down the double helix in the 3′ direction of the template strand, another Okazaki fragment can be created closer to the fork. DNA polymerase III binds again to synthesize another portion of the new DNA strand away from the fork until it reaches the previous portion already synthesized. These fragments are then connected, resulting in a single DNA strand. This process continues down the entire length of the DNA.

DNA replication of the lagging strand when the 5’-3’ template strand is used is as follows:
- SSBPs stabilize the single DNA strands.
- Primase adds an RNA primer to the lagging strand.
- DNA polymerase III binds to the primer and creates a short segment of newly synthesized DNA from 5′-3′, synthesizing in the opposite direction of the replication fork . This is the first Okazaki fragment.
- As helicase further unwinds the double helix and the replication fork moves down the strand, another primer is added closer to the fork. DNA polymerase III attaches to this primer to synthesize a second Okazaki fragment in the 5′-3′ direction away from the replication fork.
- Once DNA polymerase III reaches the first Okazaki fragment primer, DNA polymerase I removes the primer and replaces them with the proper complementary bases.
- DNA ligase connects the segments of DNA by closing the sugar-phosphate backbone. The two segments are now connected into a single strand.
- This process repeats as the replication fork continues down the length of the DNA.
Prokaryotes vs. Eukaryotes
DNA replication overall is fairly conserved across life. However, general differences exist in the enzymes and mechanisms used , as well as time required between species. The largest differences are between the domains of prokaryotes (bacteria and archaea) and eukaryotes (all other plant and animal cells).
Minor differences between these groups include faster replication time in prokaryotes and shorter Okazaki fragments in eukaryotes. Additionally, prokaryotes only have a single origin of replication, while eukaryotes have multiple origins of replication. The most noteworthy difference between these groups however, is that prokaryotes have circular DNA while eukaryotes have linear DNA. Linear eukaryotic DNA creates an additional challenge that must be regulated. This brings us to telomeres.

Because eukaryotic DNA is linear, they have ends that create a challenge. For the leading strand, DNA polymerase III can continue down the entire length of DNA. However, in the lagging strand, a primer must be added in front of the Okazaki fragment being synthesized before DNA polymerase III can attach and synthesize the new DNA strand opposite of the replication fork. Once the last Okazaki fragment is synthesized, a small DNA segment is leftover at the tip of the strand. This segment cannot be left unattended . If this DNA isn’t replicated, then genetic material will be lost each time replication occurs. After several replication cycles, this can result in lost information that could be critical for the individual to survive.
To solve this issue, telomeres are present in eukaryotes. Telomeres are short, repeating segments of DNA that are found at the end of each chromosome and do not contain any coding sequences. These telomeres are synthesized by telomerase , which is an enzyme that contains a short RNA template used to extend the length of the lagging strand. Primers are placed on the telomere where DNA polymerase III can attach to synthesize the final portion of DNA leftover on the lagging strand.

Telomere replication on the lagging strand is as follows:
- Telomerase attaches to the very end of the lagging strand, overhanging the unreplicated portion of DNA.
- Using its own RNA template, telomerase synthesizes the extending telomere, adding additional bases to the 3’ end of the lagging strand.
- Primase adds the primer on the telomere.
- DNA polymerase III binds to the primer and moves opposite of telomerase to complete the synthesis of the lagging strand.
Telomeres Affect Cell Age
Telomerase is most commonly active in cell types that divide rapidly, such as with embryonic cells, stem cells, sperm cells, and immune cells. In most other cell types, telomerase activity is turned off, and telomeres become shorter with each DNA replication. This means that cells have a limited number of times that they are able to divide via mitosis before signals are sent to prevent further divisions and DNA damage. As a result, cells have age.
Research has found that increasing telomere length can also increase the lifespan of the cell. While this offers a potential treatment to growth limiting cellular diseases, it also unfortunately assists cancer persistence and survival. Approximately 90% of cancer cells have mutated to turn on telomerase activity in cell types where it should be turned off. This causes another mechanism in which cancer cells can continue to divide without control and become immortalized. Research is ongoing to determine if/how deactivating telomerase activity can either slow or stop cancer progression.

DNA Repair and Damage
Incorrect replication.
DNA replication must be fast, but it must also be extremely accurate. DNA replication occurs trillions of times in a single human. Even if there was only a single mistake in each replication, that would add up to trillions of errors that could be detrimental to the individual’s life. So how are mistakes regulated?
The first way this is done is by DNA polymerase proofreading its own work. Each complimentary pair of nucleotides has a distinct shape. Therefore, when the wrong base is placed, the shape is different enough that DNA polymerase can recognize its own mistake. DNA polymerase can then cut out this wrong match and replace it with the correct base.

While DNA polymerase is able to proofread its own work, sometimes mistakes still goes amiss. Once DNA polymerase continues down the length of the strand, mismatch repair proteins are able to edit any additional mistakes. By using markers on the old strand of DNA, the mismatch repair proteins can distinguish sequence errors on the new strand. They then remove the mismatched nucleotide and replace it accordingly. With both DNA polymerase proofreading and the mismatch repair proteins correcting additional mistakes, there is roughly only one mistake for every 1 billion nucleotides synthesized.
Environmental Damage
Environmental factors- such a UV radiation, X-rays, and chemical exposure- can damage DNA. For example, UV radiation found in sunlight and tanning booths can create a thymine dimer where two thymine bases next to each other form a covalent bond. This thus creates a bump in the DNA strand that prevents DNA polymerase from synthesizing past this point. These circumstances can become detrimental, and systems must be put into place to repair damages such as this.
In the case of the UV radiation, eukaryotic cells have adapted a nucleotide excision repair system that is able to detect deformities in the shape of the DNA helix. At least 18 different proteins work together to remove this deformity, using the non-damaged strand as a template to repair the damaged strand. Prokaryotic cells have a simpler but similar nucleotide excision repair system that only requires three proteins. However, for UV radiation specifically, prokaryotes use an enzyme known as photolyase to detect this damage and make repairs.

DNA replication is a highly regulated molecular process where a single molecule of DNA is duplicated to result in two identical DNA molecules. As a semiconservative process, the double helix is broken down into two strands, where each strand serves as the template for the newly synthesized strand by matching complementary bases. Because DNA polymerase III can only synthesize the new strands from 5′-3′, this results in a leading strand that is continuously synthesized and a lagging strand that requires the use of Okazaki fragments. Meanwhile, because eukaryotes have linear DNA, telomeres are needed to ensure genetic information is not lost during replication. Because DNA is critical to life, research continues to better understand and treat diseases caused by mutations and damages in an individual’s DNA.
1. In double-stranded DNA, which nucleotide does adenine pair with?
2. What direction does DNA polymerase synthesize new DNA strands?
3. When the leading strand is being synthesized, what direction is the template strand?
4. When the lagging strand is being synthesized, what direction is the template strand?
5. DNA polymerase synthesizes new strands by matching complimentary base pairs from an external DNA template strand. There is not an external template for telomerase to use when synthesizing telomeres however. How does telomerase recognize what bases to add to the lagging strand and where to start?
Enter your email to receive results:
Bibliography
- Freeman, S., Quillin, K., Allison, L. A., Black, M., Podgorski, G., Taylor, E., & Carmichael, J. (2017). “Biological science (Sixth edition.).” Boston: Pearson Learning.
- Miesfeld, R. & McEvoy, M. (2017). “Biochemistry (Preliminary Edition).” New York: W.W. Norton & Company.
- Srinivas, N., Rachakonda, S., & Kumar, R. (2020). “Telomeres and Telomere Length: A General Overview.” Cancers , 12 (3), 558.
Cite This Article
Subscribe to our newsletter, privacy policy, terms of service, scholarship, latest posts, white blood cell, t cell immunity, satellite cells, embryonic stem cells, popular topics, scientific method, digestive system, natural selection, mitochondria.
9.2 DNA Replication
Learning objectives.
- Explain the process of DNA replication
- Explain the importance of telomerase to DNA replication
- Describe mechanisms of DNA repair
When a cell divides, it is important that each daughter cell receives an identical copy of the DNA. This is accomplished by the process of DNA replication. The replication of DNA occurs during the synthesis phase, or S phase, of the cell cycle, before the cell enters mitosis or meiosis.
The elucidation of the structure of the double helix provided a hint as to how DNA is copied. Recall that adenine nucleotides pair with thymine nucleotides, and cytosine with guanine. This means that the two strands are complementary to each other. For example, a strand of DNA with a nucleotide sequence of AGTCATGA will have a complementary strand with the sequence TCAGTACT ( Figure 9.8 ).
Because of the complementarity of the two strands, having one strand means that it is possible to recreate the other strand. This model for replication suggests that the two strands of the double helix separate during replication, and each strand serves as a template from which the new complementary strand is copied ( Figure 9.9 ).
During DNA replication, each of the two strands that make up the double helix serves as a template from which new strands are copied. The new strand will be complementary to the parental or “old” strand. Each new double strand consists of one parental strand and one new daughter strand. This is known as semiconservative replication . When two DNA copies are formed, they have an identical sequence of nucleotide bases and are divided equally into two daughter cells.
DNA Replication in Eukaryotes
Because eukaryotic genomes are very complex, DNA replication is a very complicated process that involves several enzymes and other proteins. It occurs in three main stages: initiation, elongation, and termination.
Recall that eukaryotic DNA is bound to proteins known as histones to form structures called nucleosomes. During initiation, the DNA is made accessible to the proteins and enzymes involved in the replication process. How does the replication machinery know where on the DNA double helix to begin? It turns out that there are specific nucleotide sequences called origins of replication at which replication begins. Certain proteins bind to the origin of replication while an enzyme called helicase unwinds and opens up the DNA helix. As the DNA opens up, Y-shaped structures called replication forks are formed ( Figure 9.10 ). Two replication forks are formed at the origin of replication, and these get extended in both directions as replication proceeds. There are multiple origins of replication on the eukaryotic chromosome, such that replication can occur simultaneously from several places in the genome.
During elongation, an enzyme called DNA polymerase adds DNA nucleotides to the 3' end of the template. Because DNA polymerase can only add new nucleotides at the end of a backbone, a primer sequence, which provides this starting point, is added with complementary RNA nucleotides. This primer is removed later, and the nucleotides are replaced with DNA nucleotides. One strand, which is complementary to the parental DNA strand, is synthesized continuously toward the replication fork so the polymerase can add nucleotides in this direction. This continuously synthesized strand is known as the leading strand . Because DNA polymerase can only synthesize DNA in a 5' to 3' direction, the other new strand is put together in short pieces called Okazaki fragments . The Okazaki fragments each require a primer made of RNA to start the synthesis. The strand with the Okazaki fragments is known as the lagging strand . As synthesis proceeds, an enzyme removes the RNA primer, which is then replaced with DNA nucleotides, and the gaps between fragments are sealed by an enzyme called DNA ligase .
The process of DNA replication can be summarized as follows:
- DNA unwinds at the origin of replication.
- New bases are added to the complementary parental strands. One new strand is made continuously, while the other strand is made in pieces.
- Primers are removed, new DNA nucleotides are put in place of the primers and the backbone is sealed by DNA ligase.
Visual Connection
You isolate a cell strain in which the joining together of Okazaki fragments is impaired and suspect that a mutation has occurred in an enzyme found at the replication fork. Which enzyme is most likely to be mutated?
Telomere Replication
Because eukaryotic chromosomes are linear, DNA replication comes to the end of a line in eukaryotic chromosomes. As you have learned, the DNA polymerase enzyme can add nucleotides in only one direction. In the leading strand, synthesis continues until the end of the chromosome is reached; however, on the lagging strand there is no place for a primer to be made for the DNA fragment to be copied at the end of the chromosome. This presents a problem for the cell because the ends remain unpaired, and over time these ends get progressively shorter as cells continue to divide. The ends of the linear chromosomes are known as telomeres , which have repetitive sequences that do not code for a particular gene. As a consequence, it is telomeres that are shortened with each round of DNA replication instead of genes. For example, in humans, a six base-pair sequence, TTAGGG, is repeated 100 to 1000 times. The discovery of the enzyme telomerase ( Figure 9.11 ) helped in the understanding of how chromosome ends are maintained. The telomerase attaches to the end of the chromosome, and complementary bases to the RNA template are added on the end of the DNA strand. Once the lagging strand template is sufficiently elongated, DNA polymerase can now add nucleotides that are complementary to the ends of the chromosomes. Thus, the ends of the chromosomes are replicated.
Telomerase is typically found to be active in germ cells, adult stem cells, and some cancer cells. For her discovery of telomerase and its action, Elizabeth Blackburn ( Figure 9.12 ) received the Nobel Prize for Medicine and Physiology in 2009. Later research using HeLa cells (obtained from Henrietta Lacks) confirmed that telomerase is present in human cells. And in 2001, researchers including Diane L. Wright found that telomerase is necessary for cells in human embryos to rapidly proliferate.
Telomerase is not active in adult somatic cells. Adult somatic cells that undergo cell division continue to have their telomeres shortened. This essentially means that telomere shortening is associated with aging. In 2010, scientists found that telomerase can reverse some age-related conditions in mice, and this may have potential in regenerative medicine. 1 Telomerase-deficient mice were used in these studies; these mice have tissue atrophy, stem-cell depletion, organ system failure, and impaired tissue injury responses. Telomerase reactivation in these mice caused extension of telomeres, reduced DNA damage, reversed neurodegeneration, and improved functioning of the testes, spleen, and intestines. Thus, telomere reactivation may have potential for treating age-related diseases in humans.
DNA Replication in Prokaryotes
Recall that the prokaryotic chromosome is a circular molecule with a less extensive coiling structure than eukaryotic chromosomes. The eukaryotic chromosome is linear and highly coiled around proteins. While there are many similarities in the DNA replication process, these structural differences necessitate some differences in the DNA replication process in these two life forms.
DNA replication has been extremely well-studied in prokaryotes, primarily because of the small size of the genome and large number of variants available. Escherichia coli has 4.6 million base pairs in a single circular chromosome, and all of it gets replicated in approximately 42 minutes, starting from a single origin of replication and proceeding around the chromosome in both directions. This means that approximately 1000 nucleotides are added per second. The process is much more rapid than in eukaryotes. Table 9.1 summarizes the differences between prokaryotic and eukaryotic replications.
| Property | Prokaryotes | Eukaryotes |
|---|---|---|
| Origin of replication | Single | Multiple |
| Rate of replication | 1000 nucleotides/s | 50 to 100 nucleotides/s |
| Chromosome structure | circular | linear |
| Telomerase | Not present | Present |
Link to Learning
Click through a tutorial on DNA replication.
DNA polymerase can make mistakes while adding nucleotides. It edits the DNA by proofreading every newly added base. Incorrect bases are removed and replaced by the correct base, and then polymerization continues ( Figure 9.13 a ). Most mistakes are corrected during replication, although when this does not happen, the mismatch repair mechanism is employed. Mismatch repair enzymes recognize the wrongly incorporated base and excise it from the DNA, replacing it with the correct base ( Figure 9.13 b ). In yet another type of repair, nucleotide excision repair , the DNA double strand is unwound and separated, the incorrect bases are removed along with a few bases on the 5' and 3' end, and these are replaced by copying the template with the help of DNA polymerase ( Figure 9.13 c ). Nucleotide excision repair is particularly important in correcting thymine dimers, which are primarily caused by ultraviolet light. In a thymine dimer, two thymine nucleotides adjacent to each other on one strand are covalently bonded to each other rather than their complementary bases. If the dimer is not removed and repaired it will lead to a mutation. Individuals with flaws in their nucleotide excision repair genes show extreme sensitivity to sunlight and develop skin cancers early in life.
Most mistakes are corrected; if they are not, they may result in a mutation —defined as a permanent change in the DNA sequence. Mutations in repair genes may lead to serious consequences like cancer.
- 1 Mariella Jaskelioff, et al., “Telomerase reactivation reverses tissue degeneration in aged telomerase-deficient mice,” Nature , 469 (2011):102–7.
This book may not be used in the training of large language models or otherwise be ingested into large language models or generative AI offerings without OpenStax's permission.
Want to cite, share, or modify this book? This book uses the Creative Commons Attribution License and you must attribute OpenStax.
Access for free at https://openstax.org/books/concepts-biology/pages/1-introduction
- Authors: Samantha Fowler, Rebecca Roush, James Wise
- Publisher/website: OpenStax
- Book title: Concepts of Biology
- Publication date: Apr 25, 2013
- Location: Houston, Texas
- Book URL: https://openstax.org/books/concepts-biology/pages/1-introduction
- Section URL: https://openstax.org/books/concepts-biology/pages/9-2-dna-replication
© Jul 10, 2024 OpenStax. Textbook content produced by OpenStax is licensed under a Creative Commons Attribution License . The OpenStax name, OpenStax logo, OpenStax book covers, OpenStax CNX name, and OpenStax CNX logo are not subject to the Creative Commons license and may not be reproduced without the prior and express written consent of Rice University.
If you're seeing this message, it means we're having trouble loading external resources on our website.
If you're behind a web filter, please make sure that the domains *.kastatic.org and *.kasandbox.org are unblocked.
To log in and use all the features of Khan Academy, please enable JavaScript in your browser.
AP®︎/College Biology
Course: ap®︎/college biology > unit 6.
- Antiparallel structure of DNA strands
- Leading and lagging strands in DNA replication
- Speed and precision of DNA replication
- Semi-conservative replication
- Molecular mechanism of DNA replication
DNA structure and replication review
- Replication
| Term | Meaning |
|---|---|
| DNA (deoxyribonucleic acid) | Nucleic acid that transmits genetic information from parent to offspring and codes for the production of proteins |
| Nucleotide | Building block of nucleic acids |
| Double helix | Structure of two strands, intertwining around an axis like a twisted ladder |
| DNA replication | Process during which a double-stranded DNA molecule is copied to produce two identical DNA molecules |
| Base pairing | Principle in which the nitrogenous bases of the DNA molecules bond with one another |
DNA structure
Nucleotides, chargaff's rules, double helix, dna replication, the replication process, leading and lagging strands, example: determining a complementary strand, common mistakes and misconceptions.
- DNA replication is not the same as cell division. Replication occurs before cell division, during the S phase of the cell cycle. However, replication only concerns the production of new DNA strands, not of new cells.
- Some people think that in the leading strand, DNA is synthesized in the 5’ to 3’ direction, while in lagging strand, DNA is synthesized in the 3’ to 5’ direction. This is not the case. DNA polymerase only synthesizes DNA in the 5’ to 3’ direction only. The difference between the leading and lagging strands is that the leading strand is formed towards replication fork, while the lagging strand is formed away from replication fork.
Want to join the conversation?
- Upvote Button navigates to signup page
- Downvote Button navigates to signup page
- Flag Button navigates to signup page

DNA Replication as a Semiconservative Process Essay
- To find inspiration for your paper and overcome writer’s block
- As a source of information (ensure proper referencing)
- As a template for you assignment
The process of DNA replication has been studied extensively as the pathway to understanding the processes of inheritance and the possible platform for addressing a range of health issues occurring as a result of DNA mutations.
However, the subject matter is still plagued by grey areas that require further analysis, the very properties of the process being one of the core issues of debating. Specifically, whether DNA replication can be deemed as semiconservative remains largely an unanswered question (Georgia Highlands College, n.d.). I believe that, despite the lack of certainty regarding the problem under analysis, it would be reasonable to believe that DNA replication is semiconservative since it is consistent with the fact that, during the reproduction process, DNS is separated into two bands.
The statement concerning DNA replication being a semiconservative process that leads to the development of two separate strands of DNA material has been supported by a vast range of evidence. Recent experiments point to the correctness of the semiconservative framework as the most legitimate theory that allows describing the process of DNA replication in the greatest detail possible (Georgia Highlands College, n.d.). In order to concede that the process of DNA replication is semiconservative, one should take a closer look at the outcomes of the experiment performed.
Since the test performed by Meselson and Stahl showed that the amount of the DNA material was equal in two daughter cells, yet the density thereof was different, the presence of semiconservative properties in DNA replication can be regarded as proven. By asserting that the observed tendency could be found in not only the strands of E.coli but also in other species, Meselson and Stahl made it evident that the DNA replication did, in fact, show semiconservative properties (Georgia Highlands College, n.d.). Thus, I insist that the existing evidence points to the DNA replication process being semiconservative.
The described outcomes of the experiment also lead to a vast range of conclusions concerning the nature and outcomes of DNA replications in different species. By defining DNA replication as semiconservative, the researchers made it evident that every double helix axis in the DNA structure built with the help of DNA polymerases leads to the creation of an entirely new strand that acts as complementary (Georgia Highlands College, n.d.).
It should also be borne in mind that the specified characteristic of the DNA structure makes it possible for the new strand, which is also known as the leading one, to emerge as a continuous piece, whereas the complementary one, or the lagging strand, occurs as a combination of smaller pieces (Georgia Highlands College, n.d.). By applying the notion of the DNA replication process being semiconservative, one can explain the observed changes within the DNA framework and provide the foundation for the further analysis of the subject matter.
Indeed, the results of the experiment described above cannot be deemed as consistent with the theory of dispersive replication, which has been offered as the alternative to the semiconservative framework. Using isotopes of nitrogen as the tools for labeling the DNA of the studied bacteria, Meselson and Stahl staged an experiment in the course of which the nature of the DNA replication process and the basis for its implementation were studied (Georgia Highlands College, n.d.). The semiconservative assumption made by the scientists implied that, in the process of replication, entirely new strands of DNA were produced with the help of the ones that were already present in the cells of the bacteria under analysis.
During the experiment, it was discovered that each of the nitrogenous bases presented in the DNA structure is only capable of connecting to its corresponding complementary partner. For adenine, the process of pairing occurs with thymine, whereas cytosine is connected to guanine in the process (Georgia Highlands College, n.d.). The resulting replication process, thus, takes place due to the combination of the helicase and DNA polymerase procedures (Georgia Highlands College, n.d.). Therefore, I strongly believe that the principle of DNA replication as the notion based on the semiconservative framework seems to be quite valid, given the vast amount of supportive evidence that has been collected.
Based on the outcomes of the Meselson–Stahl experiment, during which the DNA showed a strong propensity toward splitting into two distinct brands, the assumption that the DNA process is semiconservative can be regarded as confirmed. Even though it could be alleged that the current research has been erroneous and that the process of DNA replication may involve different processes and be based on an entirely different principle, the veracity of the identified statement is quite feeble. Thus, the stages of DNA replication can be seen as the semiconservative process. The presence of a synthesized strand along with the preexisting template one has proven to be the most sensible way of looking at the DNA replication stage.
Georgia Highlands College. (n.d.). Chapter 14 – DNA structure and function . Web.
- Plasmids, Their Characteristics and Role in Genetics
- "COMT Val158Met Polymorphism Modulates Huntington's Disease Progression" by de Diego-Balaguer et al.
- Interesting and Relevant Applications of DNA Technology
- Infectious Bacterial Identification From DNA Sequencing
- Database Replication Among Geographically Remote Sites
- The Dangers of Genetic Engineering and the Issue of Human Genes’ Modification
- "How One Cell Gives Rise to an Entire Body" by Pennisi
- Sickle Cell Disease and Scientific Inventions
- Gene Therapy: Risks and Benefits
- Dr. Michio Kaku's Predictions of the DNA Screening
- Chicago (A-D)
- Chicago (N-B)
IvyPanda. (2021, June 2). DNA Replication as a Semiconservative Process. https://ivypanda.com/essays/dna-replication-as-a-semiconservative-process/
"DNA Replication as a Semiconservative Process." IvyPanda , 2 June 2021, ivypanda.com/essays/dna-replication-as-a-semiconservative-process/.
IvyPanda . (2021) 'DNA Replication as a Semiconservative Process'. 2 June.
IvyPanda . 2021. "DNA Replication as a Semiconservative Process." June 2, 2021. https://ivypanda.com/essays/dna-replication-as-a-semiconservative-process/.
1. IvyPanda . "DNA Replication as a Semiconservative Process." June 2, 2021. https://ivypanda.com/essays/dna-replication-as-a-semiconservative-process/.
Bibliography
IvyPanda . "DNA Replication as a Semiconservative Process." June 2, 2021. https://ivypanda.com/essays/dna-replication-as-a-semiconservative-process/.

Want to create or adapt books like this? Learn more about how Pressbooks supports open publishing practices.
Chapter 14. DNA Replication

Chapter Outline
- 14.1 Historical Basis of Modern Understanding
- 14.2 Overview of DNA Replication
- 14.3 DNA Replication in Prokaryotes
- 14.4 DNA Replication in Eukaryotes
- 14.5 DNA Repair
Introduction
The three letters “DNA” have now become synonymous with crime solving, paternity testing, human identification, and genetic testing. DNA can be retrieved from hair, blood, or saliva. Each person’s DNA is unique, and it is possible to detect differences between individuals within a species on the basis of these unique features. DNA analysis has many practical applications beyond forensics. In humans, DNA testing is applied to numerous uses: tracing genealogy, identifying pathogens, archeological research, tracing disease outbreaks, and studying human migration patterns. In the medical field, DNA is used in diagnostics, new vaccine development, and cancer therapy. It is now possible to determine predisposition to diseases by looking at genes.
Each human cell has 23 pairs of chromosomes: one set of chromosomes is inherited from the mother and the other set is inherited from the father. There is also a mitochondrial genome, inherited exclusively from the mother, which can be involved in inherited genetic disorders. On each chromosome, there are thousands of genes, sequences of DNA that code for a functional product, that are responsible for determining the genotype and phenotype of the individual. The human haploid genome contains 3 billion base pairs and has between 20,000 and 25,000 functional genes.
In order for DNA to serve its role as the genetic material, all organisms must be able to faithfully copy the entire genome. This process, DNA replication , is the precursor to all forms of cell division.
14.1 | Historical Basis of Modern Understanding
Learning Objectives
By the end of this section, you will be able to:
- Explain transformation of DNA.
- Describe the key experiments that helped identify that DNA is the genetic material.
- State and explain Chargaff’s rules
Modern understandings of DNA have evolved from the discovery of nucleic acids to the development of the double-helix model. In the 1860s, Friedrich Miescher ( Figure 14.2 ), a physician by profession, was the first person to isolate phosphate- rich chemicals from white blood cells or leukocytes. He named these chemicals (which would eventually be known as RNA and DNA) nuclein because they were isolated from the nuclei of the cells.

A half century later, British bacteriologist Frederick Griffith was perhaps the first person to show that hereditary information could be transferred from one cell to another “horizontally,” rather than by descent. In 1928, he reported the first demonstration of bacterial transformation , a process in which external DNA is taken up by a cell, thereby changing morphology and physiology. He was working with Streptococcus pneumoniae, the bacterium that causes pneumonia. Griffith worked with two strains, rough (R) and smooth (S). The R strain is non-pathogenic (does not cause disease) and is called rough because its outer surface is a cell wall and lacks a capsule; as a result, the cell surface appears uneven under the microscope. The S strain is pathogenic (disease-causing) and has a capsule outside its cell wall. As a result, it has a smooth appearance under the microscope. Griffith injected the live R strain into mice and they survived. In another experiment, when he injected mice with the heat-killed S strain, they also survived. In a third set of experiments, a mixture of live R strain and heat-killed S strain were injected into mice, and—to his surprise—the mice died. Upon isolating the live bacteria from the dead mouse, only the S strain of bacteria was recovered. When this isolated S strain was injected into fresh mice, the mice died. Griffith concluded that something had passed from the heat-killed S strain into the live R strain and transformed it into the pathogenic S strain, and he called this the transforming principle ( Figure 11.3 ). These experiments are now famously known as Griffith’s transformation experiments.

Scientists Oswald Avery, Colin MacLeod, and Maclyn McCarty (1944) were interested in exploring this transforming principle further. They isolated the S strain from the dead mice and isolated the proteins and nucleic acids, namely RNA and DNA, as these were possible candidates for the molecule of heredity. They conducted a systematic elimination study. They used enzymes that specifically degraded each component and then used each mixture separately to transform the R strain. They found that when DNA was degraded, the resulting mixture was no longer able to transform the bacteria, whereas all of the other combinations were able to transform the bacteria. This led them to conclude that DNA was the transforming principle.
Experiments conducted by Martha Chase and Alfred Hershey in 1952 provided confirmatory evidence that DNA was the genetic material and not proteins. Chase and Hershey were studying a bacteriophage, which is a virus that infects bacteria. Viruses typically have a simple structure: a protein coat, called the capsid, and a nucleic acid core that contains the genetic material, either DNA or RNA. The bacteriophage infects the host bacterial cell by attaching to its surface, and then it injects its nucleic acids inside the cell. The phage DNA makes multiple copies of itself using the host machinery, and eventually the host cell bursts, releasing a large number of bacteriophages. Hershey and Chase labeled one batch of phage with radioactive sulfur, 35 S, to label the protein coat. Another batch of phage were labeled with radioactive phosphorus, 32 P. Because phosphorous is found in DNA, but not protein, the DNA and not the protein would be tagged with radioactive phosphorus.
Each batch of phage was allowed to infect the cells separately. After infection, the phage bacterial suspension was put in a blender, which caused the phage coat to be detached from the host cell. The phage and bacterial suspension was spun down in a centrifuge. The heavier bacterial cells settled down and formed a pellet, whereas the lighter phage particles stayed in the supernatant (the liquid above the pellet). In the tube that contained phage labeled with 35 S, the supernatant contained the radioactively labeled phage, whereas no radioactivity was detected in the pellet. In the tube that contained the phage labeled with 32 P, the radioactivity was detected in the pellet that contained the heavier bacterial cells, and no radioactivity was detected in the supernatant. Hershey and Chase concluded that it was the phage DNA that was injected into the cell and carried information to produce more phage particles, thus providing evidence that DNA was the genetic material and not proteins ( Figure 14.4 ).

Around this same time, Austrian biochemist Erwin Chargaff examined the content of DNA in different species and found that the amounts of adenine, thymine, guanine, and cytosine were not found in equal quantities, and that it varied from species to species, but not between individuals of the same species. He found that the amount of adenine equals the amount of thymine, and the amount of cytosine equals the amount of guanine, or A = T and G = C. These are also known as Chargaff’s rules. This finding proved immensely useful when Watson and Crick were getting ready to propose their DNA double helix model, discussed in Chapter 5.
14.2 | Overview of DNA Replication
- Explain how the structure of DNA reveals the replication process.
- Describe the Meselson and Stahl experiments.
The elucidation of the structure of the double helix provided a hint as to how DNA divides and makes copies of itself. This model suggests that the two strands of the double helix separate during replication, and each strand serves as a template from which the new complementary strand is copied. What was not clear was how the replication took place. There were three models suggested ( Figure 14.5 ): conservative, semi-conservative, and dispersive.
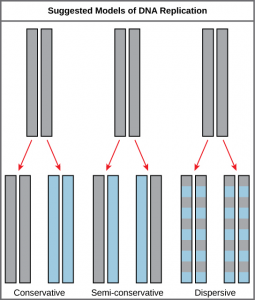
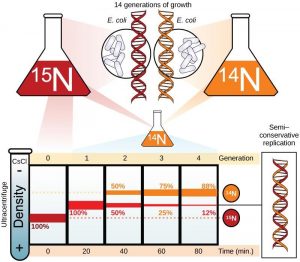
In conservative replication, the parental DNA remains together, and the newly formed daughter strands are together. The semi-conservative method suggests that each of the two parental DNA strands act as a template for new DNA to be synthesized; after replication, each double-stranded DNA includes one parental or “old” strand and one “new” strand. In the dispersive model, both copies of DNA have double-stranded segments of parental DNA and newly synthesized DNA interspersed. Meselson and Stahl were interested in understanding how DNA replicates. They grew E. coli for several generations in a medium containing a “heavy” isotope of nitrogen ( 15 N) that gets incorporated into nitrogenous bases, and eventually into the DNA ( Figure 14.6 ).
The E. coli culture was then shifted into medium containing 14 N and allowed to grow for one generation. The cells were harvested and the DNA was isolated. The DNA was centrifuged at high speeds in an ultracentrifuge. Some cells were allowed to grow for one more life cycle in 14 N and spun again. During the density graditent centrifugation, the DNA is loaded into a gradient (typically a salt such as cesium chloride or sucrose) and spun at high speeds of 50,000 to 60,000 rpm. Under these circumstances, the DNA will form a band according to its density in the gradient. DNA grown in 15 N will band at a higher density position than that grown in 14 N. Meselson and Stahl noted that after one generation of growth in 14 N after they had been shifted from 15 N, the single band observed was intermediate in position in between DNA of cells grown exclusively in 15 N and 14 N. This suggested either a semi-conservative or dispersive mode of replication. The DNA harvested from cells grown for two generations in 14 N formed two bands: one DNA band was at the intermediate position, between 15 N and 14 N and the other corresponded to the band of 14 N DNA. These results could only be explained if DNA replicates in a semi-conservative manner. Therefore, the other two modes were ruled out.
During DNA replication, each of the two strands that make up the double helix serves as a template from which new strands are copied. The new strand will be complementary to the parental or “old” strand. When two daughter DNA copies are formed, they have the same sequence and are divided equally into the two daughter cells.
14.3 | DNA Replication in Prokaryotes
- Explain the process of DNA replication in prokaryotes.
- Discuss the role of different enzymes and proteins in supporting this process.
DNA replication has been extremely well studied in prokaryotes primarily because of the small size of the genome and the mutants that are available. E. coli has 4.6 million base pairs in a single circular chromosome and all of it gets replicated in approximately 42 minutes, starting from a single origin of replication and proceeding around the circle in both directions. This means that approximately 1000 nucleotides are added per second. The process is quite rapid and occurs without many mistakes.
DNA replication employs a large number of proteins and enzymes, each of which plays a critical role during the process. One of the key players is the enzyme DNA polymerase, also known as DNA pol, which adds nucleotides one by one to the growing DNA chain that are complementary to the template strand. The addition of nucleotides requires energy; this energy is obtained from the nucleotides that have three phosphates attached to them, similar to ATP which has three phosphate groups attached. When the bond between the phosphates is broken, the energy released is used to form the phosphodiester bond between the incoming nucleotide and the growing chain. In prokaryotes, three main types of polymerases are known: DNA pol I, DNA pol II, and DNA pol III. It is now known that DNA pol III is the enzyme required for DNA synthesis; DNA pol I and DNA pol II are primarily required for repair.
How does the replication machinery know where to begin? It turns out that there are specific nucleotide sequences called origins of replication where replication begins. In E. coli, which has a single origin of replication on its one chromosome (as do most prokaryotes), it is approximately 245 base pairs long and is rich in AT sequences. The origin of replication is recognized by certain proteins that bind to this site. An enzyme called helicase unwinds the DNA by breaking the hydrogen bonds between the nitrogenous base pairs. ATP hydrolysis is required for this process. As the DNA opens up, Y-shaped structures called replication forks are formed. Two replication forks are formed at the origin of replication and these get extended bi- directionally as replication proceeds. Single-strand binding proteins coat the single strands of DNA near the replication fork to prevent the single-stranded DNA from winding back into a double helix. DNA polymerase is able to add nucleotides only in the 5′ to 3′ direction (a new DNA strand can be only extended in this direction). It also requires a free 3′- OH group to which it can add nucleotides by forming a phosphodiester bond between the 3′-OH end and the 5′ phosphate of the next nucleotide. This essentially means that it cannot add nucleotides if a free 3′-OH group is not available. Then how does it add the first nucleotide? The problem is solved with the help of a primer that provides the free 3′-OH end. Another enzyme, RNA primase , synthesizes an RNA primer that is about five to ten nucleotides long and complementary to the DNA. Because this sequence primes the DNA synthesis, it is appropriately called the primer. DNA polymerase can now extend this RNA primer, adding nucleotides one by one that are complementary to the template strand ( Figure 14.7 ).
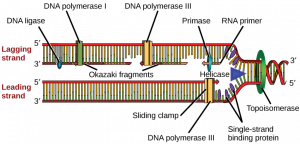
The replication fork moves at the rate of 1000 nucleotides per second. DNA polymerase can only extend in the 5′ to 3′ direction, which poses a slight problem at the replication fork. As we know, the DNA double helix is anti-parallel; that is, one strand is in the 5′ to 3′ direction and the other is oriented in the 3′ to 5′ direction. One strand, which is complementary to the 3′ to 5′ parental DNA strand, is synthesized continuously towards the replication fork because the polymerase can add nucleotides in this direction. This continuously synthesized strand is known as the leading strand . The other strand, complementary to the 5′ to 3′ parental DNA, is extended away from the replication fork, in small fragments known as Okazaki fragments , each requiring a primer to start the synthesis. Okazaki fragments are named after the Japanese scientist who first discovered them. The strand with the Okazaki fragments is known as the lagging strand .
Concept check
You isolate a cell strain in which the joining together of Okazaki fragments is impaired and suspect that a mutation has occurred in an enzyme found at the replication fork. Which enzyme is most likely to be mutated?
The leading strand can be extended by one primer alone, whereas the lagging strand needs a new primer for each of the short Okazaki fragments. The overall direction of the lagging strand will be 3′ to 5′, and that of the leading strand 5′ to 3′. A protein called the sliding clamp holds the DNA polymerase in place as it continues to add nucleotides. The sliding clamp is a ring-shaped protein that binds to the DNA and holds the polymerase in place. Topoisomerase prevents the over-winding of the DNA double helix ahead of the replication fork as the DNA is opening up; it does so by causing temporary nicks in the DNA helix and then resealing it. As synthesis proceeds, the RNA primers are replaced by DNA. The primers are removed by the exonuclease activity of DNA pol I, and the gaps are filled in by deoxyribonucleotides. The nicks that remain between the newly synthesized DNA (that replaced the RNA primer) and the previously synthesized DNA are sealed by the enzyme DNA ligase that catalyzes the formation of phosphodiester linkage between the 3′-OH end of one nucleotide and the 5′ phosphate end of the other fragment.
Once the chromosome has been completely replicated, the two DNA copies move into two different cells during cell division. The process of DNA replication can be summarized as follows:
- DNA unwinds at the origin of replication.
- Helicase opens up the DNA-forming replication forks; these are extended bidirectionally.
- Single-strand binding proteins coat the DNA around the replication fork to prevent rewinding of the DNA.
- Topoisomerase binds at the region ahead of the replication fork to prevent supercoiling.
- Primase synthesizes RNA primers complementary to the DNA strand.
- DNA polymerase starts adding nucleotides to the 3′-OH end of the primer.
- Elongation of both the lagging and the leading strand continues.
- RNA primers are removed by exonuclease activity.
- Gaps are filled by DNA pol by adding dNTPs.
- The gap between the two DNA fragments is sealed by DNA ligase, which helps in the formation of phosphodiester bonds.
Table 11.1 Prokaryotic DNA replication: enzymes and their functions.
|
|
|
| DNA pol I | Exonuclease activity removes RNA primer and replaces with newly synthesized DNA |
| DNA pol II | Repair function |
| DNA pol III | Main enzyme that adds nucleotides in the 5′-3′ direction |
| Helicase | Opens the DNA helix by breaking hydrogen bonds between the nitrogenous bases |
| Ligase | Seals the gaps between the Okazaki fragments to create one continuous DNA strand |
| Primase | Synthesizes RNA primers needed to start replication |
| Sliding Clamp | Helps to hold the DNA polymerase in place when nucleotides are being added |
| Topoisomerase | Helps relieve the stress on DNA when unwinding by causing breaks and then resealing the DNA |
| Single-strand binding proteins (SSB) | Binds to single-stranded DNA to avoid DNA rewinding back. |
14.4 | DNA Replication in Eukaryotes
- Discuss the similarities and differences between DNA replication in eukaryotes and prokaryotes.
- State the role of telomerase in DNA replication.
14.4.1 Prokaryote vs. Eukaryote Replication
Eukaryotic genomes are much more complex and larger in size than prokaryotic genomes. The human genome has three billion base pairs per haploid set of chromosomes, and 6 billion base pairs are replicated during the S phase of the cell cycle. There are multiple origins of replication on the eukaryotic chromosome; humans can have up to 100,000 origins of replication. The rate of replication is approximately 100 nucleotides per second, much slower than prokaryotic replication. In yeast, which is a eukaryote, special sequences known as Autonomously Replicating Sequences (ARS) are found on the chromosomes. These are equivalent to the origin of replication in E. coli.
The number of DNA polymerases in eukaryotes is much more than prokaryotes: 14 are known, of which five are known to have major roles during replication and have been well studied. They are known as pol α, pol β, pol γ, pol δ, and pol ε.
The essential steps of replication are the same as in prokaryotes. Before replication can start, the DNA has to be made available as template. Eukaryotic DNA is bound to basic proteins known as histones to form structures called nucleosomes. The chromatin (the complex between DNA and proteins) may undergo some chemical modifications, so that the DNA may be able to slide off the proteins or be accessible to the enzymes of the DNA replication machinery. At the origin of replication, a pre-replication complex is made with other initiator proteins. Other proteins are then recruited to start the replication process ( Table 11.2 ).
A helicase using the energy from ATP hydrolysis opens up the DNA helix. Replication forks are formed at each replication origin as the DNA unwinds. The opening of the double helix causes over-winding, or supercoiling, in the DNA ahead of the replication fork. These are resolved with the action of topoisomerases. Primers are formed by the enzyme primase, and using the primer, DNA pol can start synthesis. While the leading strand is continuously synthesized by the enzyme pol δ, the lagging strand is synthesized by pol ε. A sliding clamp protein known as PCNA (Proliferating Cell Nuclear Antigen) holds the DNA pol in place so that it does not slide off the DNA. RNase H removes the RNA primer, which is then replaced with DNA nucleotides. The Okazaki fragments in the lagging strand are joined together after the replacement of the RNA primers with DNA. The gaps that remain are sealed by DNA ligase, which forms the phosphodiester bond.
Table 11.2 Differences between Prokaryotic and Eukaryotic Replication
|
|
|
|
| Origin of replication | Single | Multiple |
| Rate of replication | 1000 nucleotides/s | 50 to 100 nucleotides/s |
| DNA polymerase types | 5 | 14 |
| Telomerase | Not present | Present |
| RNA primer removal | DNA pol I | RNase H |
| Strand elongation | DNA pol III | Pol δ, pol ε |
| Sliding clamp | Sliding clamp | PCNA |
14.4.2 Telomere Replication
Unlike prokaryotic chromosomes, eukaryotic chromosomes are linear. As you’ve learned, the enzyme DNA pol can add nucleotides only in the 5′ to 3′ direction. In the leading strand, synthesis continues until the end of the chromosome is reached. On the lagging strand, DNA is synthesized in short stretches, each of which is initiated by a separate primer. When the replication fork reaches the end of the linear chromosome, there is no place for a primer to be made for the DNA fragment to be copied at the end of the chromosome. These ends thus remain unpaired, and over time these ends may get progressively shorter as cells continue to divide.
The ends of the linear chromosomes are known as telomeres , which have repetitive sequences that code for no particular gene. In a way, these telomeres protect the genes from getting deleted as cells continue to divide. In humans, a six base pair sequence, TTAGGG, is repeated 100 to 1000 times. The discovery of the enzyme telomerase ( Figure 14.8 ) helped in the understanding of how chromosome ends are maintained. The telomerase enzyme contains a catalytic part and a built-in RNA template. It attaches to the end of the chromosome, and complementary bases to the RNA template are added on the 3′ end of the DNA strand. Once the 3′ end of the lagging strand template is sufficiently elongated, DNA polymerase can add the nucleotides complementary to the ends of the chromosomes. Thus, the ends of the chromosomes are replicated.

Telomerase is typically active in germ cells and adult stem cells. It is not active in adult somatic cells. For her discovery of telomerase and its action, Elizabeth Blackburn ( Figure 14.9 ) received the Nobel Prize for Medicine and Physiology in 2009.
Telomerase and Aging
Cells that undergo cell division continue to have their telomeres shortened because most somatic cells do not make telomerase. This essentially means that telomere shortening is associated with aging. With the advent of modern medicine, preventative health care, and healthier lifestyles, the human life span has increased, and there is an increasing demand for people to look younger and have a better quality of life as they grow older.
In 2010, scientists found that telomerase can reverse some age-related conditions in mice. This may have potential in regenerative medicine [1] . Telomerase-deficient mice were used in these studies; these mice have tissue atrophy, stem cell depletion, organ system failure, and impaired tissue injury responses. Telomerase reactivation in these mice caused extension of telomeres, reduced DNA damage, reversed neurodegeneration, and improved the function of the testes, spleen, and intestines. Thus, telomere reactivation may have potential for treating age-related diseases in humans.
Cancer is characterized by uncontrolled cell division of abnormal cells. The cells accumulate mutations, proliferate uncontrollably, and can migrate to different parts of the body through a process called metastasis. Scientists have observed that cancerous cells have considerably shortened telomeres and that telomerase is active in these cells. Interestingly, only after the telomeres were shortened in the cancer cells did the telomerase become active. If the action of telomerase in these cells can be inhibited by drugs during cancer therapy, then the cancerous cells could potentially be stopped from further division.
14.5 | DNA Repair
- Discuss the different types of mutations in DNA.
- Explain DNA repair mechanisms.
DNA replication is a highly accurate process, but mistakes can occasionally occur, such as a DNA polymerase inserting a wrong base. Uncorrected mistakes may sometimes lead to serious consequences, such as cancer. Repair mechanisms correct the mistakes. In rare cases, mistakes are not corrected, leading to mutations; in other cases, repair enzymes are themselves mutated or defective.
Most of the mistakes during DNA replication are promptly corrected by DNA polymerase by proofreading the base that has been just added ( Figure 14.10 ). In proofreading , the DNA pol reads the newly added base before adding the next one, so a correction can be made. The polymerase checks whether the newly added base has paired correctly with the base in the template strand. If it is the right base, the next nucleotide is added. If an incorrect base has been added, the enzyme makes a cut at the phosphodiester bond and releases the wrong nucleotide. This is performed by the exonuclease action of DNA pol III. Once the incorrect nucleotide has been removed, a new one will be added again.

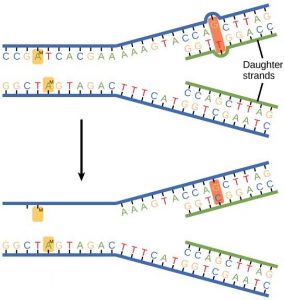
Some errors are not corrected during replication, but are instead corrected after replication is completed; this type of repair is known as mismatch repair ( Figure 14.11 ). The enzymes recognize the incorrectly added nucleotide and excise it; this is then replaced by the correct base. If this remains uncorrected, it may lead to more permanent damage. How do mismatch repair enzymes recognize which of the two bases is the incorrect one? In E. coli , after replication, the nitrogenous base adenine acquires a methyl group; the parental DNA strand will have methyl groups, whereas the newly synthesized strand lacks them. Thus, DNA polymerase is able to remove the wrongly incorporated bases from the newly synthesized, non- methylated strand. In eukaryotes, the mechanism is not very well understood, but it is believed to involve recognition of unsealed nicks in the new strand, as well as a short-term continuing association of some of the replication proteins with the new daughter strand after replication has completed.
In another type of repair mechanism, nucleotide excision repair , enzymes replace incorrect bases by making a cut on both the 3′ and 5′ ends of the incorrect base ( Figure 14. 12 ). The segment of DNA is removed and replaced with the correctly paired nucleotides by the action of DNA pol. Once the bases are filled in, the remaining gap is sealed with a phosphodiester linkage catalyzed by DNA ligase. This repair mechanism is often employed when UV exposure causes the formation of pyrimidine dimers.

A well-studied example of mistakes not being corrected is seen in people suffering from xeroderma pigmentosa ( Figure 14. 13 ). Affected individuals have skin that is highly sensitive to UV rays from the sun. When individuals are exposed to UV, pyrimidine dimers, especially those of thymine, are formed; people with xeroderma pigmentosa are not able to repair the damage. These are not repaired because of a defect in the nucleotide excision repair enzymes, whereas in normal individuals, the thymine dimers are excised and the defect is corrected. The thymine dimers distort the structure of the DNA double helix, and this may cause problems during DNA replication. People with xeroderma pigmentosa may have a higher risk of contracting skin cancer than those who dont have the condition.

Errors during DNA replication are not the only reason why mutations arise in DNA. Mutations , variations in the nucleotide sequence of a genome, can also occur because of damage to DNA. Such mutations may be of two types: induced or spontaneous. Induced mutations are those that result from an exposure to chemicals, UV rays, x-rays, or some other environmental agent. Spontaneous mutations occur without any exposure to any environmental agent; they are a result of natural reactions taking place within the body.
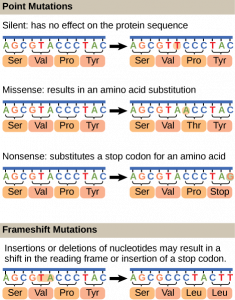
Mutations may have a wide range of effects. Some mutations are not expressed; these are known as silent mutations . Point mutations are those mutations that affect a single base pair. The most common nucleotide mutations are substitutions, in which one base is replaced by another. These can be of two types, either transitions or transversions . Transition substitution refers to a purine or pyrimidine being replaced by a base of the same kind; for example, a purine such as adenine may be replaced by the purine guanine. Transversion substitution refers to a purine being replaced by a pyrimidine, or vice versa; for example, cytosine, a pyrimidine, is replaced by adenine, a purine. Mutations can also be the result of the addition of a base, known as an insertion , or the removal of a base, also known as deletion . Sometimes a piece of DNA from one chromosome may get translocated to another chromosome or to another region of the same chromosome; this is also known as translocation . Some of these mutation types are shown in Figure 14.14.
Mutations in repair genes have been known to cause cancer. Many mutated repair genes have been implicated in certain forms of pancreatic cancer, colon cancer, and colorectal cancer. Mutations can affect either somatic cells or germ cells. If many mutations accumulate in a somatic cell, they may lead to problems such as the uncontrolled cell division observed in cancer. If a mutation takes place in germ cells, the mutation will be passed on to the next generation, as in the case of hemophilia and xeroderma pigmentosa.
- Jaskelioff et al., “Telomerase reactivation reverses tissue degeneration in aged telomerase-deficient mice,” Nature 469 (2011): 102-7. ↵
Introduction to Molecular and Cell Biology Copyright © 2020 by Katherine R. Mattaini is licensed under a Creative Commons Attribution-NonCommercial 4.0 International License , except where otherwise noted.
Share This Book
Microbe Notes
DNA Replication: Enzymes, Mechanism, Steps, Applications
DNA replication is the process of producing two identical copies of DNA from one original DNA molecule.
- DNA is made up of millions of nucleotides, which are composed of deoxyribose sugar, with phosphate and a base.
- The complementary pairing of these bases keeps the double strands intact. So, to make two copies of one DNA, these hydrogen bonds in between the bases should be broken to begin replication.
- DNA replication is semi-conservative, meaning that each strand in the DNA acts as a template for the synthesis of a new complementary strand. Semi conservative because once DNA molecule is synthesized it has one strand from the parent and the other strand is a newly formed strand.
- DNA replication starts by taking one DNA molecule and giving two daughter molecules, with each newly synthesized molecule containing one new and one old strand.
- DNA replication simply is the process by which a DNA makes a copy of itself. Though easy as it may sound it’s a complex process happening inside of our cells, and many enzymes, proteins, and metal ions should work coherently to make this process happen.
Table of Contents
Interesting Science Videos
Mechanism of DNA Replication
Summary : DNA replication takes place in three major steps.
- Opening of the double-stranded helical structure of DNA and separation of the strands
- Priming of the template strands
- Assembly of the newly formed DNA segments.
- During the separation of DNA, the two strands uncoil at a specific site known as the origin . With the involvement of several enzymes and proteins, they prepare (prime) the strands for duplication.
- At the end of the process, DNA polymerase enzyme starts to organize the assembly of the new DNA strands.
- These are the general steps of DNA replication for all cells but they may vary specifically, depending on the organism and cell type.
- Enzymes play a major role in DNA replication because they catalyze several important stages of the entire process.
- DNA replication is one of the most essential mechanisms of a cell’s function and therefore intensive research has been done to understand its processes.
- The mechanism of DNA replication is well understood in Escherichia coli, which is also similar to that in eukaryotic cells.
- In E.coli, DNA replication is initiated at the oriClocus (oriC), to which DnaA protein binds while hydrolyzing of ATP takes place.
Enzymes and Proteins Used in DNA Replication
- A nuclease is an enzyme that can cleave the phosphodiester bonds present in between the nucleotides.
- On the basis where they cleave, they are characterized as Exo and endonucleases.
- Exonucleases cleave nucleotides from their respective ends. Corresponding to this fact, these exonucleases show activity from both directions 5′ to 3′ and 3′ to 5′.
- Endonucleases act on the region in the middle of the targeted nucleotide. They are also endonucleases that are selective to which molecule they cleave and are sub-divided as DNase for DNA for cleaving and RNase for RNA cleaving. Additionally, recently discovered nucleases are also being used for gene editing such as Cas9 in the CRISPR genome editing technique.
- Restrictive endonuclease or restriction enzymes are the ones that cleave DNA into fragments at or near the specific recognition sites within the molecule known as restriction sites.
- To cleave the DNA, restriction endonuclease makes two incisions, once through each sugar-phosphate backbone of the DNA double helix. These endonucleases recognize a specific sequence of nucleotides and produce a double-stranded cut in the DNA.
- This specific sequence is usually 4 – 8 bases and is present in the recognition site.
- DNA Polymerase

- DNA polymerases are the enzyme that is responsible for adding new nucleotides and synthesizing a new strand of DNA by taking the old fragmented strand as a template.
- DNA Polymerases also possess exonuclease activity, that cuts incorrectly added nucleotides, and allows the DNA replication to happen without errors.
- DNA Polymerase is of many types and functions based on the cell they are found in.
- In prokaryotic cells, there are three DNA polymerases: DNA Polymerase Ι, DNA Polymerase ΙΙ and DNA Polymerase ΙΙΙ.
- DNA polymerase Ι is a repair polymerase with 5′ to 3′ and 3′ to 5′ exonuclease activity. It is involved in the processing of Okazaki fragments during lagging strand synthesis.
- DNA polymerase ΙΙ has 3′ to 5′ exonuclease activity and participated in DNA repair with 5′ to 3′ polymerase activity.
- DNA polymerase ΙΙΙ is the primary enzyme involved in the DNA replication of E.coli . It has 3′ to 5′ exonuclease activity and 5′ to 3′ polymerase activity.
- In eukaryotic cells, there are five DNA polymerases: DNA Polymerase α, β, γ, δ and ε
- DNA polymerase α is a repair polymerase, with 3′ to 5′ exonucleases activities and 5′ to 3′ polymerase activities.
- DNA Polymerase β is a repair polymerase.
- DNA Polymerase γ shows polymerase activity 5′ to 3′ and exonucleases activity 3′ to 5′, it is involved in Mitochondrial DNA replication
- DNA Polymerase δ shows 3′ to 5′ exonuclease activity and 5′ to 3′ polymerase activity. This enzyme is involved in lagging strand synthesis.
- DNA Polymerase ε shows 3′ to 5′ and 5′ to 3′ exonucleases activities. This enzyme not only repairs but also synthesizes the leading strand efficiently in a 5′ to 3′ direction. It is the prime enzyme involved in DNA replication.

- DNA ligase is a specific type of enzyme that facilitates the joining of DNA strands together by catalyzing the formation of a phosphodiester bond.
- This enzyme joins the 3′ hydroxyl group of one nucleotide with the 5′ phosphate end of another nucleotide at an expense of ATP.
- DNA helicase
- DNA helicase is a motor protein that moves directionally along a nucleic acid phosphodiester backbone, separating two nucleotides of DNA molecule.
- They separate double-stranded DNA molecules into single strands allowing each strand to be copied.
- During DNA replication, this DNA helicase unwinds DNA at the origin, a site where the replication is to be initiated.
- DNA helicase continues to unwind the double helix of DNA and thus forms a structure called replication fork, named after the forked appearance of two strands of DNA when unzipped apart.
- It is an energy-driven process as it involves the breaking of Hydrogen bonds between annealed nucleotide bases.
- DNA primase
- Primase is an enzyme that is capable to synthesize short stretches of RNA sequences known as a primer.
- Primers are an integral part of DNA replication. These primers serve as an initiating site for the addition of nucleotides by DNA polymerase.
- DNA polymerase can only add nucleotide at pre-existing 3′ Hydroxyl group which is thus provided by the primers.
- As we can see that primers are short stretches of RNA, but replication is of DNA, so therefore after elongation of the chains of nucleotides, these primers are replaced by DNA.
- DNA topoisomerase
- DNA topoisomerase is a class of enzymes that release helical tension during transcription and replication by creating transient nicks within the phosphate backbone on one or both strands of the DNA.
- This tension is aroused when the DNA molecule unwinds due to helicase activity and forms a replication fork. The progress of the replication fork generates supercoils, making it hard for other machinery involved to access the DNA molecule.
- Class Ι DNA topoisomerase makes a single-stranded break to relax the helix and progress the process.
- Class ΙΙ DNA topoisomerase break both the strands of DNA helix, this class of topoisomerases is also very important during the cell cycle for the condensation of chromosomes.
- Single strand binding proteins
- The single-strand binding (SSB) protein are DNA binding proteins, that binds to single-stranded DNA to facilitate DNA replication.
- SSB proteins prevent the hardening of strands during DNA replication. It also protects strands from nuclease degradation and prevents the rewinding of DNA.
- These proteins destabilize helical duplexes so that DNA polymerase can hold onto the DNA during DNA replication, recombination, and repair.
- It also removes unwanted secondary structures on strands for easy access of the strands to the machinery involved in DNA replication.
- Thus, SSB proteins stabilize the single-stranded DNA structure that is important for genomic progression.
So, in summary here are the list of 7 enzymes and proteins used in DNA Replication:
Steps in DNA Replication
Step 1: formation of replication fork.
- Before DNA can replicate, this double-stranded molecule must unwind into two single strands to initiate the replication process.
- DNA unwinds when the complementary base pairing between the double-stranded is broken, and the site to initiate this unwinding is denoted by specific regions (Adenine and Thymine rich).
- These specific coding regions are referred to as Origin of Replication (Ori) and thus the replication process begins.
- These origins are targeted by initiator proteins, which go on to recruit more proteins that can help the replication process by forming a replication fork around the Ori.
- Within this replication protein complex is an enzyme DNA helicase, which starts to unwind the DNA from its Ori and exposes two strands resembling a Y-like structure referred to as replication fork.
- The activity of helicase causes topological stress to the un-winded strand forming supercoiled DNA, this stress is relieved by Topoisomerase by negative supercoiling.
- The replication fork is bidirectional; one strand is oriented to 5′ to 3′ direction (leading strand) and the other strand is oriented to 3′ to 5′ direction (lagging strand) but the addition of nucleotide progress only in 5′ to 3′ direction.
- The formation of a replication fork exposing two single-stranded strands marks the beginning of Initiation.

Step 2: Initiation
- One strand runs from 5′ to 3′ direction towards the replication fork and is referred to as leading strand and the other strand runs from 3′ to 5′ away from the replication fork and is referred to as lagging strands.
- To this exposed single-stranded DNA, SSB proteins are adhered to prevent recoiling of DNA and to stabilize it.
- After which another enzyme DNA primase comes into action to synthesize a short stretch of RNA primer, which provides a free 3′ hydroxyl group for DNA polymerase can now add nucleotides and extend the new chain of nucleotides.

Step 3: Elongation
- Now that primer is added to unzipped two single-stranded DNA, these strands now act as a template for synthesizing new DNAs.
- The enzyme DNA polymerase synthesizes new nucleotide to match the template and add on to the free 3′ hydroxyl group provided by the primer in each single-stranded DNA.
- The leading strand runs from 5′ to 3′ so the addition of nucleotides by DNA polymerase happens from 5′ to 3′ direction. As the replication fork progresses the addition of nucleotide is continuous thus only requiring the primer once.
- However, lagging strands is antiparallel and run from the 5′ to 3′ direction, the continuous addition of nucleotides is not possible as the replication fork progresses, DNA polymerase cannot add complementary nucleotides to the 5′ end. Therefore, multiple primers are required.
- Due to this phenomenon, the DNA nucleotides synthesis from lagging strands occurs in fragments. These fragments are termed Okazaki fragments.
- Hence, the leading strand using only one primer synthesizes nucleotides continuously, while the lagging strand uses multiple primers and thus synthesizes nucleotides discontinuously.
Step 4: Termination
- RNA primers of both leading and lagging strands are cleaved out or degraded by exonucleases activity of DNA polymerase, and the nicks or gaps so formed are filled with DNA and sealed by the enzyme DNA ligase.
- DNA polymerase also shows proofreading activity and check, remove and replace any errors.
- Interestingly, in eukaryotic organisms having linear DNA, when RNA primer at 5′ end of daughter strand is removed, there is not a preceding 3′ OH such that DNA polymerase can use it to replace with DNA.
- So, at the 5′ end of daughter strands, there is a gap (missing DNA). This missing DNA can cause a loss of information contained in that region. This gap must be filled before the next round of replication.
- For solving this end replication problem, researchers have found that linear ends of DNA called telomere are used which contain specific G: C rich repeats. These sequences are known as telomere sequences.
- These telomere sequences do not code anything but are essential to fill in the gap in the daughter strand and maintain the integrity of DNA.
- Eventually, the replication forks terminate at terminating recognizing sequences (ter).
- The ter sequences are of around 23 base pairs which facilitate as the binding sites for TUS protein.
- This ter- TUS complex arrest replication fork and terminate.
So, in summary, these are the 4 steps of DNA Replication:
- Formation of Replication Fork
- Termination
Okazaki Fragments
- The two DNA strands run in opposite or antiparallel directions, and therefore to continuously synthesize the two new strands at the replication fork requires that one strand is synthesized in the 5’to3′ direction while the other is synthesized in the opposite direction, 3’to 5′.
- However, DNA polymerase can only catalyze the polymerization of the dNTPs only in the 5’to 3’direction.
- This means that the other opposite new strand is synthesized differently. But how?
- By the joining of discontinuous small pieces of DNA that are synthesized backward from the direction of movements of the replication fork. These small pieces or fragments of the new DNA strand are known as the Okasaki Fragments.
- The Okasaki fragments are then joined by the action of DNA ligase, which forms an intact new DNA strand known as the lagging strand.
- The lagging phase is not synthesized by the primer that initiates the synthesis of the leading strand.
- Instead, a short fragment of RNA serves as a primer (RNA primer) for the initiation of replication of the lagging strand.
- RNA primers are formed during the synthesis of RNA which is initiated de novo, and an enzyme known as primase synthesizes these short fragments of RNA, which are 3-10 nucleotides long and complementary to the lagging strand template at the replication fork.
- The Okazaki fragments are then synthesized by the extension of the RNA primers by DNA polymerase.
- However, the newly synthesized lagging strand is that it contains an RNA-DNA joint, defining the critical role of RNA in DNA replication.

Replication Fork Formation and its function
- The replication fork is the site of active DNA synthesis, where the DNA helix unwinds and single strands of the DNA replicates.
- Several sites of origin represent the replication forks.
- The replication fork is formed during DNA strand unwinding by the helicase enzyme which exposes the origin of replication. A short RNA primer is synthesized by primase and elongation done by DNA polymerase.
- The replication fork moves in the direction of the new strand synthesis. The new DNA strands are synthesized in two orientations, i.e. 5′ to 3′ direction which is the leading strand, and the 3′ to 5′ orientation which is the lagging strand.
- The two sides of the new DNA strand (leading and lagging strand) are replicated in two opposite directions from the replication fork.
- Therefore the replication fork is bi-directional.
Leading Strand
- The leading strand is the new DNA strand that is continuously synthesized by the DNA polymerase enzyme.
- It is the simplest strand that is synthesized during replication.
- The synthesis starts after the DNA strand has unzipped and separated. This generates a short piece of RNA known as a primer , by the DNA primase enzyme.
- The primer binds to the 5′ end (start) of the strand, thus initiating the synthesize of the new strand (leading strand).
- The synthesis of the leading strand is a continuous process.
The Lagging Strand
- This is the template strand (3′ to 5′) that is synthesized in a discontinuous manner by RNA primers.
- During the synthesis of the leading strand, it exposes small, short strands, or templates that are then used for the synthesis of the Okasaki fragments.
- The Okasaki fragments synthesize the lagging strand by the activity of DNA polymerase which adds the pieces of DNA (the Okasaki fragments) to the strand between the primers.
- The formation of the lagging strand is a discontinuous process because the newly formed strand (lagging strand) is the fragmentation of short DNA strands.
Applications of DNA Replication
- DNA replication makes the transfer of genetic information from one generation to another possible.
- It is an important phenomenon happening inside our cells, that allows the body to maintain homeostasis and integrity of the body.
- With the available information about DNA replication, scientific communities today have a proper idea of genome sequencing which has now been applied in different expertise ranging from clinical diagnosis to possible treatment of genetic diseases.
- DNA replication has made sequencing of whole human genome sequencing possible.
- Cloning of genes has also been possible by DNA replication.
- Enzymes involved in DNA replication have now been greatly studied due to their wider applications. The recent breakthrough Cas9/ CRISPR technology where nucleases are used to cleave the desired portion of DNA and replace it with required nucleotides is the prime example of how we can use these enzymes and make potential advancements in them thus broadening and exploring their uses.
- Polymerase Chain Reaction uses DNA polymerases to repeatedly replicate DNA in-vitro and has numerous applications in diagnosis, sequencing, and recombinant DNA technology.
- The formation of complementary DNA (cDNA) can also be considered as an example of a wider application of the enzymes involved in DNA replication.
- There are various applications of DNA replication, we can even consider that if there is any technique involving genes, some way or the other DNA replication is applied.
DNA Replication Stress
During DNA replication, the process and the DNA genome undergoes various stress arising from the mechanism. these stresses an result in stalled replication and stalled replication fork formation. Several events contribute to these stresses, including;
- Unusual DNA structure
- Mismatched ribonucleotides
- Tensions arising from concurrent mechanisms of replication and transcription
- Inadequate availability of important replication factors
- Fragile sites on the replicating DNA strand
- Overexpression or constitutive activation of oncogenes
- Inaccessible chromatins
Kinase regulatory proteins such as ATM ( ATM serine/threonine kinase ) and ATP are proteins that assist in alleviating replication stress. These proteins get recruited and activated by DNA damages .
Stalled replication forks may collapse if the regulatory proteins do not stabilize, and if and when this happens, initiation of repairing mechanisms to reassembling of the replication fork takes place. this helps to amend damages the damaged ends of DNA.
Similarities between Prokaryotic and Eukaryotic DNA Replication
- The unwinding mechanism of DNA before replication is initiated is the same for both Prokaryotes and eukaryotes.
- In both organisms, the DNA polymerase enzyme coordinated the synthesis of new DNA strands.
- Additionally, both organisms use the semi-conservative replication pattern, making the leading and lagging strands in different directions. Okasaki fragments make the lagging strand.
- Lastly, both organisms initiate DNA replication using a short RNA primer.

Eukaryotic vs. Prokaryotic DNA Replication (11 Major Differences)
| 1. | Occurs in eukaryotic cells. | Occurs in a prokaryotic cell. |
| 2. | This process takes place in the cell’s nucleus. | This process takes place in the cell’s cytoplasm. |
| 3. | There are multiple sites for the origin of replication per DNA molecule. | There is a single site for the origin of replication per DNA molecule. |
| 4. | Initiation of DNA replication is carried out by multi-subunit proteins, origin recognition complex. | Initiation of DNA replication is carried out by protein DnaA and DnaB. |
| 5. | Multiple replication forks are formed in a DNA molecule. | Only two replication forks are formed in a DNA molecule. |
| 6. | Okazaki fragments are short of around 100-200 nucleotides in length | Okazaki fragments are large, around 1000-2000 nucleotides in length. |
| 7. | It is a slow process with around 100 nucleotides added per second. | It is a fast process with around 2000 nucleotides added per second. |
| 8. | DNA is linear and double-stranded. | DNA is circular and double-stranded. |
| 9. | DNA polymerase involved in eukaryotic DNA replication is DNA polymerases ε, α, and δ. | DNA polymerase involved in prokaryotic DNA replication is DNA polymerase Ι, and ΙΙΙ. |
| 10. | Eukaryotic cells have telomeres at the end of DNA thus they are replicated. | Prokaryotic cells have circular DNA thus they are not replicated. |
| 11. | (Telomerase) is needed. | DNA gyrase (Telomerase) is not needed. |
- Weiguo Cao, “DNA Ligases: Structure, Function, and Mechanism”, Current Organic Chemistry 2002; 6(9). https://doi.org/10.2174/1385272023373950
- https://www.nature.com/scitable/definition/helicase-307/
- https://proteinswebteam.github.io/interpro-blog/potm/2006_1/Page2.htm
- https://www.yourgenome.org/facts/what-is-dna-replication
- https://www.khanacademy.org/science/ap-biology/gene-expression-and-regulation/replication/a/molecular-mechanism-of-dna-replication
- https://teachmephysiology.com/biochemistry/cell-growth-death/dna-replication/
- https://courses.lumenlearning.com/wm-biology1/chapter/reading-major-enzymes/
- https://geneticeducation.co.in/single-stranded-binding-protein-ssb-structure-and-function/
- https://www.thoughtco.com/dna-replication-3981005
- https://byjus.com/biology/difference-between-prokaryotic-and-eukaryotic-replication/
- https://www.vedantu.com/biology/difference-between-prokaryotic-and-eukaryotic-dna-replication
- https://www.majordifferences.com/2013/03/difference-between-prokaryotic-and.html
About Author

Rajat Thapa
2 thoughts on “DNA Replication: Enzymes, Mechanism, Steps, Applications”
hello i got a doubt about leading and lagging strand directions. 5` to 3` should be leading strand and 3` to 5` should be a lagging strand. because the polymerase activity goes in 5` to 3` direction so the strand is continuous without any breaks so it is called leading strand and the strand which is in opposite direction to the direction of polymerase is disturbed with breaks hence it is called lagging strand. but you reversed it so please check it and please correct it.
Hello, Yes, you are correct. There has been slight mistakes on the note. We have corrected the note and updated it. Thank you so much for your finding.
Leave a Comment Cancel reply
Save my name, email, and website in this browser for the next time I comment.
This site uses Akismet to reduce spam. Learn how your comment data is processed .

An official website of the United States government
The .gov means it’s official. Federal government websites often end in .gov or .mil. Before sharing sensitive information, make sure you’re on a federal government site.
The site is secure. The https:// ensures that you are connecting to the official website and that any information you provide is encrypted and transmitted securely.
- Publications
- Account settings
Preview improvements coming to the PMC website in October 2024. Learn More or Try it out now .
- Advanced Search
- Journal List
- Portland Press Open Access
Mitochondrial DNA replication in mammalian cells: overview of the pathway
Maria falkenberg.
Department of Medical Biochemistry and Cell Biology, University of Gothenburg, P.O. Box 440, 405 30 Gothenburg, Sweden
Mammalian mitochondria contain multiple copies of a circular, double-stranded DNA genome and a dedicated DNA replication machinery is required for its maintenance. Many disease-causing mutations affect mitochondrial replication factors and a detailed understanding of the replication process may help to explain the pathogenic mechanisms underlying a number of mitochondrial diseases. We here give a brief overview of DNA replication in mammalian mitochondria, describing our current understanding of this process and some unanswered questions remaining.
Introduction
Mitochondrial DNA (mtDNA) is a double-stranded molecule of 16.6 kb ( Figure 1 , lower panel). The two strands of mtDNA differ in their base composition, with one being rich in guanines, making it possible to separate a heavy (H) and a light (L) strand by density centrifugation in alkaline CsCl 2 gradients [ 1 ]. The mtDNA contains one longer noncoding region (NCR) also referred to as the control region. In the NCR, there are promoters for polycistronic transcription, one for each mtDNA strand; the light strand promoter (LSP) and the heavy strand promoter (HSP). The NCR also harbors the origin for H-strand DNA replication (O H ). A second origin for L-strand DNA replication (O L ) is located outside the NCR, within a tRNA cluster approximately 11,000 bp downstream of O H .

The genome encodes for 13 mRNA (green), 22 tRNA (violet), and 2 rRNA (pale blue) molecules. There is also a major noncoding region (NCR), which is shown enlarged at the top. The major NCR contains the heavy strand promoter (HSP), the light strand promoter (LSP), three conserved sequence boxes (CSB1-3, orange), the H-strand origin of replication (O H ), and the termination-associated sequence (TAS, yellow). The triple-stranded displacement-loop (D-loop) structure is formed by premature termination of nascent H-strand DNA synthesis at TAS. The short H-strand replication product formed in this manner is termed 7S DNA. A minor NCR, located approximately 11,000 bp downstream of O H , contains the L-strand origin of replication (O L ).
mtDNA replication factors
Mammalian mtDNA is replicated by proteins distinct from those used for nuclear DNA replication and many are related to replication factors identified in bacteriophages [ 2 ]. DNA polymerase γ (POLγ) is the replicative polymerase in mitochondria. In human cells, POLγ is a heterotrimer with one catalytic subunit (POLγA) and two accessory subunits (POLγB) [ 3–5 ]. Mouse knockouts for POLγA and POLγB have revealed that both factors are essential for embryonic development [ 6 , 7 ]. At least four additional polymerases (PrimPol, DNA polymerase β, DNA polymerase θ, and DNA polymerase ζ) have been reported to play a role mitochondria [ 8–11 ]. These polymerases are not essential for mtDNA maintenance and none of them can substitute for POLγ. Most likely they are involved in mtDNA repair, but the exact function of these additional polymerases in mtDNA maintenance needs to be further elucidated (reviewed in [ 12 ]).
POLγA belongs to the family A DNA polymerases and contains a 3′–5′ exonuclease domain that acts to proofread the newly synthesized DNA strand [ 3 ]. POLγ is a highly accurate DNA polymerase with a frequency of misincorporation lower than 1 × 10 −6 [ 13 ]. The accessory POLγB subunit enhances interactions with the DNA template and increases both the catalytic activity and the processivity of POLγA [ 14–16 ]. POLγ cannot use double-stranded DNA as a template and a DNA helicase is therefore required at the mitochondrial replication fork [ 17 ]. The DNA helicase TWINKLE is homologous to the T7 phage gene 4 protein [ 18 ] and during mtDNA replication, TWINKLE travels in front of POLγ, unwinding the double-stranded DNA template. TWINKLE forms a hexamer and requires a fork structure (a single-stranded 5′-DNA loading site and a short 3′-tail) to load and initiate unwinding [ 18–20 ]. Mitochondrial single-stranded DNA-binding protein (mtSSB) binds to the formed ssDNA, protects it against nucleases, and prevents secondary structure formation [ 21 , 22 ]. mtSSB enhances mtDNA synthesis by stimulating TWINKLE’s helicase activity as well as increasing the processivity of POLγ [ 17 , 19 , 23 ].
The mode of mtDNA replication
A model for mtDNA replication was presented already in 1972 by Vinograd and co-workers ( Figure 2 ) [ 24 ]. According their strand displacement model, DNA synthesis is continuous on both the H- and L-strand [ 25 ]. There is a dedicated origin for each strand, O H and O L . First, replication is initiated at O H and DNA synthesis then proceeds to produce a new H-strand. During the initial phase, there is no simultaneous L-strand synthesis and mtSSB covers the displaced, parental H-strand [ 26 ]. By binding to single-stranded DNA, mtSSB prevents the mitochondrial RNA polymerase (POLRMT) from initiating random RNA synthesis on the displaced strand [ 27 ]. When the replication fork has progressed about two-thirds of the genome, it passes the second origin of replication, O L . When exposed in its single-stranded conformation, the parental H-strand at O L folds into a stem–loop structure [ 28 ]. The stem efficiently blocks mtSSB from binding and a short stretch of single-stranded DNA in the loop region therefore remains accessible, allowing POLRMT to initiate RNA synthesis [ 26 , 29 ]. POLRMT is not processive on a single-stranded DNA templates [ 27 ]. Already after about 25 nt, it is replaced by POLγ and L-strand DNA synthesis is initiated [ 30 ]. From this point, H- and L-strand synthesis proceeds continuously until the two strands have reached full circle. Replication of the two strands is linked, since H-strand synthesis is required for initiation of L-strand synthesis. The structure and the sequence requirement for mammalian O L has been studied both in vivo and in vitro , demonstrating that a functional human O L must include a stable double-stranded stem region with pyrimidine-rich template strand and a single-stranded loop of at least 10 nt [ 31 ].

Mitochondrial DNA replication is initiated at O H and proceeds unidirectionally to produce the full-length nascent H-strand. mtSSB binds and protects the exposed, parental H-strand. When the replisome passes O L , a stem–loop structure is formed that blocks mtSSB binding, presenting a single-stranded loop-region from which POLRMT can initiate primer synthesis. The transition to L-strand DNA synthesis takes place after about 25 nt, when POLγ replaces POLRMT at the 3′-end of the primer. Synthesis of the two strands proceeds in a continuous manner until two full, double-stranded DNA molecules have been formed.
It should be noted that some aspects of the strand-displacement model have been questioned. For instance, studies have suggested that processed RNA molecules hybridize to the single-stranded H-strand and function as a provisional lagging strand, which is replaced by DNA during later stages of mtDNA replication [ 32 ]. This so-called RITOLS model implicates that processed transcripts are successively hybridized to the paternal H-strand as the replication fork advances, but the enzymatic machinery required for this process has not been identified [ 33 ]. Arguing against the RITOLS model, single-stranded DNA binding proteins are used to stabilize single-stranded DNA intermediates during DNA replication in all three major branches of life. In mitochondria, there are at least 500 mtSSB tetramers available per mtDNA molecule. Since each tetramer binds 59 nt, the levels of mtSSB are sufficient to cover the entire parental H-strand during mtDNA synthesis [ 26 , 34 ]. In addition, strand-specific chromatin immunoprecipitation has revealed that mtSSB exclusively covers the parental H-strand during mtDNA replication in vivo . The occupancy profile displays a distinct pattern, with the highest levels of mtSSB close to OriH, followed by a gradual decline toward OriL. The pattern is thus as would be predicted if mtSSB functions to stabilize the single-stranded, paternal H-strand during strand-displacement DNA replication [ 26 ]. Yet another problem for the RITOLS model is the presence of RNASEH1 in mitochondria. This enzyme efficiently removes RNA–DNA hybrids, an activity that is difficult to reconcile with processed RNA molecules stably binding to long stretches of single-stranded DNA during mtDNA replication [ 35 ].
Finally, there have been reports suggesting that under certain conditions, strand-coupled replication may function as a backup replication mode in mammalian mitochondria [ 36 , 37 ]. The molecular mechanisms underlying this type of replication have not been elucidated.
Curiously, not all replication events initiated at O H continue to full circle. Instead, 95% are terminated already after about 650 nt at the termination associated sequences (TAS) [ 38 , 39 ]. The short DNA fragment formed in this way, 7S DNA, remains bound to the parental L-strand, while the parental H-strand is displaced ( Figure 1 , top panel). As a result, a triple-stranded displacement loop structure, a D-loop, is formed. The functional importance of the D-loop structure is unclear and how replication is terminated at TAS is also not known [ 40 , 41 ]. It appears however that termination at TAS is a regulated event, providing a switch between abortive and genome length mtDNA replication [ 42 ]. In support of this notion, in vivo occupation analysis revealed that POLγ under normal conditions stalls at the 3′-end of the D-loop, whereas TWINKLE occupancy is low in this region. When mtDNA is depleted, the situation changes and TWINKLE occupancy increases and at the same time 7S DNA levels are decreased. These data have been interpreted as evidence for TWINKLE reloading in response to increased demand for mtDNA replication [ 42 ]. Binding of the helicase to the 3′-end of 7S DNA would allow the stalled POLγ to continue replication of 7S DNA to full circle. The model receives support from mouse genetic experiments, demonstrating that TWINKLE is important for mtDNA copy number control. Increased or decreased levels of TWINKLE correlate nicely with mtDNA levels [ 43–46 ]. It is thus possible that mtDNA replication is regulated at the level of pretermination rather than initiation. The switch may fine-tune the mtDNA copy number in response to cellular demands.
Interestingly, two closely related 15 nt and evolutionary conserved palindromic sequence motifs (ATGN 9 CAT) are located on each side of the D-loop region. One motif is located just upstream of the 5′-end of the 7S DNA, where it forms a part of conserved sequence box 1, CSB1. The second motif, core-TAS, is located within the TAS region, just downstream of the 3′-end of 7S DNA ( Figure 1 , top panel) [ 42 ]. The physiological role of these motifs remains unclear, but sequence-specific DNA binding proteins often recognize and bind palindromic sequences. In support of this notion, there are published in organello footprints located to the TAS region [ 47 ], but despite substantial efforts in different laboratories, a TAS-binding protein has so far not been identified. It is possible that the proteins binding to CSB1, core-TAS, and other regions within TAS are difficult to purify by traditional methods. Perhaps the missing protein is membrane bound and difficult to retain in solution during chromatography. Alternatively, binding could be a regulated event, requiring precise redox conditions or nucleotide concentrations. Finally, it cannot be excluded that secondary structures in mtDNA may play a role, e.g. stem–loops or G-quadruplexes, which could also contribute to the observed in vivo DNA footprints.
Initiation of mtDNA replication at O H
We know that POLRMT forms the primers necessary to initiate H-strand synthesis O H [ 48–51 ]. Transcripts initiated at LSP provide RNA 3′-ends from which POLγ can initiate DNA synthesis. In human mitochondria, there are multiple transitions points (RNA-to-DNA transitions) located downstream of LSP, clustering around two conserved sequence motifs, CSB3 and CSB2 ( Figure 1 , top panel) [ 52–54 ]. These conserved sequence elements are guanine-rich and during transcription, a G-quadruplex structure can form between nascent RNA and the nontemplate DNA strand at CSB2. In this manner, the nascent transcript is anchored to mtDNA, forming an R-loop structure [ 30 , 55 ]. The G-quadruplex structure also causes premature transcription termination at sites roughly corresponding to RNA to DNA transition sites mapped in the CSB2-region [ 56 ]. Based on these observations, it was hypothesized that sequence-dependent transcription termination may be responsible for primer formation at O H [ 54–56 ]. The transcription elongation factor TEFM, strongly reduces transcription termination and R-loop formation at CSB2, leading to the suggestion that active TEFM may influence the ratio between primer formation and full-length, productive transcription [ 57 , 58 ]. Arguing against this idea, knockdown of TEFM in cells only has very limited effects on mtDNA copy number and mitochondrial replication intermediates [ 59 ]. In addition, there are no direct experimental evidence demonstrating that R-loop-forming, prematurely terminated transcripts can be directly used by POLγ to initiate DNA synthesis. Further experiments are clearly needed to define the precise role of R-loops and TEFM in replication initiation.
The mechanisms of DNA replication initiation at O H may resemble those previously described for initiation of DNA replication in the E. coli plasmid ColE1. In the plasmid, a transcript denoted RNAII associates with the template strand, forming an R-loop that is used to prime DNA synthesis [ 60 , 61 ]. Furthermore, the ColE1 origin of replication is situated downstream of a guanine-rich stretch that is essential for both replication initiation and R-loop formation [ 61 , 62 ]. In ColE1, the R-loop is cleaved by RNase H, before it is used to prime DNA synthesis. If the mitochondrial RNASEH1 plays a similar role in mammalian cells remains to be determined [ 63 , 64 ].
Termination of mtDNA replication
When POLγ has completed synthesis, the newly formed DNA strands are ligated by DNA ligase III [ 65 , 66 ]. To allow for efficient ligation, the 5′- and 3′-ends of the nascent DNA ends must be juxtaposed, which means that the RNA primers used to initiate mtDNA synthesis must first be removed [ 67 ]. A likely candidate for primer removal is RNASEH1, inasmuch as RNA primers are retained in the mitochondrial origin regions in mouse embryonic fibroblasts lacking Rnaseh1 and there is a loss of mtDNA in Rnaseh1 knockout mice [ 35 , 68 ].
After completing a full circle-replication, POLγ encounters the 5′-end of the nascent full-length mtDNA strand it has just produced. At this point, POLγ initiates successive cycles of polymerization and 3′–5′ exonuclease degradation at the nick [ 67 , 69 ]. This process, idling, is required for proper ligation. POLγ lacking exonuclease activity is unable to idle and instead continues DNA synthesis into the dsDNA region past the 5′-end, thereby creating a flap-structure that cannot be ligated. Failure to create ligatable DNA ends may explain why mice with exonuclease-deficient POLγ display strand-specific nicks at O H [ 67 , 70 ].
Interestingly, there is a major 5′-end of nascent DNA located approximately 100 bp further downstream of the identified RNA-to-DNA transitions sites. Historically, this site (position 191 in human mtDNA) has been seen as a part of O H , but how this 5′-end is generated is not clear [ 25 ]. Although initially identified as a start site for mtDNA replication, the free 5′-end at position 191 may be generated in other ways. For instance, the nascent H-strand may undergo considerable 5′-end processing during primer removal, removing not only the RNA primer, but also ∼100 nt of downstream DNA [ 42 ]. In this way, the site for RNA-to-DNA transition would be separated from the site of nascent H-strand ligation at the end of replication. A possible candidate for this effect is the mitochondrial genome maintenance exonuclease 1 (MGME1), a mitochondrial RecB-type exonuclease belonging to the PD-(D/E)XK nuclease superfamily [ 71 , 72 ]. In vitro analysis revealed that MGME1 cuts both ssDNA and DNA flap substrates. Human cells lacking active MGME1 display impaired ligation at O H and the formation of linear deleted mtDNA molecules spanning O H and O L [ 72 ]. In addition, there are increased levels of 7S DNA. The 5′-ends of these 7S DNA products are located further upstream (i.e. closer to CSB2) than what is observed in normal cells, suggesting that MGME1 is involved in processing the 5′-end of the nascent H-strand. Further studies of MGME1 and how it works together with RNASEH1 to process nascent replication products will be important.
Separation mtDNA
During DNA replication, the parental molecule remains intact, which poses a steric problem for the moving replication machinery. Topoisomerases belonging to the type 1 family can relieve torsional strain formed in this way, by allowing one of the strands to pass through the other. In mammalian mitochondria, TOP1MT a type IB enzyme can act as a DNA “swivel”, working together with the mitochondrial replisome [ 73 ]. Knockout of the Top1mt gene in mouse generates viable offspring that shows altered mtDNA supercoiling [ 74 , 75 ].
In other systems, replication of intact, circular DNA generates daughter molecules linked together as catenanes , i.e. mechanically interlocked, but not yet completely finished DNA circles. Therefore, replication of circular genomes requires decatenation to generate complete daughter molecules separation ( Figure 3 ). The existence of catenanes in mitochondria was reported already in 1967 by Vinograd and co-workers, who identified mtDNA molecules linked together by X-type brances, which they suggested were formed during completion of mtDNA replication [ 76 ]. Recently, it was demonstrated that these X-type structures are hemicatenanes, i.e. double-stranded DNA molecules linked together via a single-stranded linkage [ 77 ]. A mitochondrial isoform of Topoisomerase 3α (Top3α) is required to resolve the hemicatenane structure ( Figure 3 ), inasmuch as loss of Top3α causes decrease in mtDNA and the formation of large, catenated mtDNA networks. Patient mutations that decrease Top3α activity cause symptoms similar to those caused by mutations in other mitochondrial replication factors, including muscle-restricted mtDNA deletions and chronic progressive external ophthalmoplegia [ 77 ]. Interestingly, the hemicatenanes holding these mtDNA networks together are located to the O H -region, suggesting that these structures are formed during the completion of mtDNA replication. Even if the exact mechanisms remain unclear, previous theoretical work that has postulated ways by which hemicatenanes can be formed during replication of circular DNA molecules [ 78 ]. Further work is required to understand how mtDNA replication is terminated and hemicatenanes are formed.

After mtDNA replication, the new daughter molecules are mechanically linked via a hemicatenane structure, which requires Top3α to be resolved.
Even if Top3α is required for separation of newly replicated mtDNA, additional proteins are probably also needed. There is a nuclear isoform of Top3α that functions together with three other proteins; the helicase BLM and the OB-fold proteins RMI1 and RMI2. Together, these proteins form the BTR complex, which acts to dissolve double Holliday junctions, and Top3α requires the other subunits to exert full topoisomerase activity [ 79 ]. However, since neither BLM, RMI1, or RMI2 have mitochondrial isoforms, other proteins may partner with Top3α in mitochondria to regulate and/or stimulate its activity [ 77 ].
Nucleoid replication
mtDNA is not a naked molecule, but packaged into large nucleoprotein complexes, nucleoids [ 80 ], which can be visualized by various fluorescent microscopy approaches [ 81 ]. Studies have revealed that nucleoids have an average size of ∼100 nm in diameter [ 82 , 83 ] and in most cases there is a single mtDNA molecule per nucleoid [ 82 ]. The major structural protein component of the nucleoid is TFAM, which is present at a ratio of 1 subunit per 16–17 bp of mtDNA. TFAM is a member of the high mobility group (HMG) box domain family and it binds DNA without sequence specificity [ 84 ]. TFAM is also an essential component of the mitochondrial transcription machinery [ 85 ]. During transcription initiation, the protein binds upstream of the transcription start site and induces a sharp bend into DNA [ 86–88 ]. Nucleoid-like particles can be reconstituted by simply mixing TFAM and mtDNA, implying that TFAM on its own can fully compact mtDNA [ 89–91 ]. TFAM has two DNA binding sites, and appears to compact mtDNA by cross-strand binding and loop formation. In addition, TFAM binds DNA in a cooperative manner, forming protein-patches on mtDNA [ 90–92 ].
That TFAM acts as an epigenetic regulator of mtDNA replication is a tantalizing possibility. Super-resolution microscopy has revealed different forms of nucleoids [ 91 ]. Perhaps, the more compact nucleoids represent a mtDNA storage form, whereas the larger forms are involved in active replication and/or transcription. Nucleoids involved in active DNA replication have been localized to contact points between the endoplasmic reticulum (ER) and mitochondria. At these sites, mitochondrial division takes place, leading to the idea that contacts between the endoplasmic reticulum and mitochondria can coordinate mtDNA synthesis with division to ensure even distribution of newly replicated nucleoids within the mitochondrial network [ 93 ].
In vitro , small changes in the TFAM to DNA ratio can have dramatic consequences. At physiological ratios, there are large variations in mtDNA compaction, fully compacted nucleoids and naked DNA can be observed simultaneously. Under these conditions, a small increase in TFAM concentrations can dramatically increase the number of full compacted mtDNA molecules. [ 89 , 90 ]. This model may explain why TFAM levels in vivo remain roughly proportional to mtDNA levels, and suggests that relatively small changes in TFAM concentrations can have strong effects on both gene expression and mtDNA replication. In support of this notion, longer patches of TFAM prevents DNA unwinding and as a consequence, the mtDNA replication and transcription machineries cannot progress [ 90 ]. TFAM may therefore function as an epigenetic regulator, which controls the number of mtDNA molecules available for active transcription and/or mtDNA replication.
Concluding remarks
A detailed understanding of mtDNA replication is not only important from a basic science point of view, but may also explain the formation of deletions and point mutations associated with human disease and aging. A detailed knowledge of these process may pave the way for development of new therapeutic strategies that can be of use in mitochondrial medicine.
- Mammalian mtDNA is replicated by proteins distinct from those used for nuclear DNA replication.
- According to the strand displacement model, replication is initiated from two distinct origins, OH and OL.
- Transcripts initiated at LSP provide the primer from which POLγ can initiate DNA synthesis at OH.
- O L forms a stem–loop structure and POLRMT initiates primer synthesis from the single-stranded loop region.
- The role of the mitochondrial D-loop is not understood.
- RNASEH1 and MGME1 play important roles in primer removal, but the details of this process are not fully understood.
- Top3α is required to resolve hemicatenane structures formed between new mtDNA molecules at the end of replication.
- mtDNA is not a naked molecule, but packaged into nucleoprotein complexes, nucleoids.
- Mitochondrial division is linked to active mtDNA synthesis.
Acknowledgments
I am grateful to Dr Jay P. Uhler who prepared the illustrations.
Abbreviations
| HSP | heavy strand promoter |
| LSP | light strand promoter |
| MGME1 | mitochondrial genome maintenance exonuclease 1 |
| mtSSB | mitochondrial single-stranded DNA-binding protein |
| NCR | noncoding region |
| TAS | termination-associated sequence |
Competing Interests
The author declares that there are no competing interests associated with the manuscript.
This work was supported by Swedish Research Council (2013-3621); Swedish Cancer Foundation (CAN2016/816); European Research Council (DELMIT); the IngaBritt and Arne Lundberg Foundation; and the Knut and Alice Wallenberg Foundation.
The Process of Semi-Conservative Replication ( AQA A Level Biology )
Revision note.

Biology Lead
The Process of Semi-Conservative Replication
- DNA replication occurs in preparation for mitosis , when a parent cell divides to produce two genetically identical daughter cells – as each daughter cell contains the same number of chromosomes as the parent cell, the number of DNA molecules in the parent cell must be doubled before mitosis takes place
- DNA replication occurs during the S phase of the cell cycle (which occurs during interphase , when a cell is not dividing )
- The enzyme helicase unwinds the DNA double helix by breaking the hydrogen bonds between the base pairs on the two antiparallel polynucleotide DNA strands to form two single polynucleotide DNA strands
- Each of these single polynucleotide DNA strands acts as a template for the formation of a new strand made from free nucleotides that are attracted to the exposed DNA bases by base pairing
- The new nucleotides are then joined together by DNA polymerase which catalyses condensation reactions to form a new strand
- The original strand and the new strand joined together through hydrogen bonding between base pairs to form the new DNA molecule
- This method of replicating DNA is known as semi-conservative replication because half of the original DNA molecule is kept ( conserved ) in each of the two new DNA molecules

Semi-conservative replication of DNA
DNA Polymerase
- These nucleotides are known as nucleoside triphosphates or ‘activated nucleotides’
- The extra phosphates activate the nucleotides, enabling them to take part in DNA replication
- The bases of the free nucleoside triphosphates align with their complementary bases on each of the template DNA strands
- The enzyme DNA polymerase synthesises new DNA strands from the two template strands
- It does this by catalysing condensation reactions between the deoxyribose sugar and phosphate groups of adjacent nucleotides within the new strands, creating the sugar-phosphate backbone of the new DNA strands
- DNA polymerase cleaves (breaks off) the two extra phosphates and uses the energy released to create the phosphodiester bonds (between adjacent nucleotides)
- Hydrogen bonds then form between the complementary base pairs of the template and new DNA strands

Nucleotides are bonded together by DNA polymerase to create the new complementary DNA strands
Leading & lagging strands
- DNA polymerase can only build the new strand in one direction (5’ to 3’ direction)
- As DNA is ‘unzipped’ from the 3’ towards the 5’ end, DNA polymerase will attach to the 3’ end of the original strand and move towards the replication fork (the point at which the DNA molecule is splitting into two template strands)
- This means the DNA polymerase enzyme can synthesise the leading strand continuously
- This template strand that the DNA polymerase attaches to is known as the leading strand
- The other template strand created during DNA replication is known as the lagging strand
- On this strand, DNA polymerase moves away from the replication fork (from the 5’ end to the 3’ end)
- This means the DNA polymerase enzyme can only synthesise the lagging DNA strand in short segments (called Okazaki fragments)
- A second enzyme known as DNA ligase is needed to join these lagging strand segments together to form a continuous complementary DNA strand
- DNA ligase does this by catalysing the formation of phosphodiester bonds between the segments to create a continuous sugar-phosphate backbone

The synthesis of the complementary strands occurs slightly differently on the leading and lagging template strands of the original DNA molecule that is being replicated
You've read 0 of your 0 free revision notes
Get unlimited access.
to absolutely everything:
- Downloadable PDFs
- Unlimited Revision Notes
- Topic Questions
- Past Papers
- Model Answers
- Videos (Maths and Science)
Join the 100,000 + Students that ❤️ Save My Exams
the (exam) results speak for themselves:
Did this page help you?
Author: Lára
Lára graduated from Oxford University in Biological Sciences and has now been a science tutor working in the UK for several years. Lára has a particular interest in the area of infectious disease and epidemiology, and enjoys creating original educational materials that develop confidence and facilitate learning.

Dna Replication Essay
Since we discovered that DNA is in the nucleus in every single cell, we’re curious about how exactly DNA can be replicated in a way that can keep our identity, including our characteristics. This could be described after learning about DNA and its very individual characteristics, along with transcription and translation, which are the two steps of DNA replication. These steps can determine our characteristics, as well as our personalities. DNA is mostly made of adenine, thymine, guanine and cytosine. These all make hydrogen bonds, and that’s only if it’s connected to the correct base. An example of this would be when thymine connects to adenine and guanine connects to cytosine. Though, since this is mRNA being created, adenine would connect …show more content…
The DNA helicase latches on to the DNA molecule, unzipping the double helix, letting enzymes break the hydrogen bonds that connect the base pairs. Also, complementary nucleotides that are floating around and about in the nucleus form hydrogen bonds according to their pairs: thymine to adenine and guanine to cytosine. Due to the hydrogen bonds being more breakable, the DNA is much easier to “unzip” for replication. In the cytoplasm you can also find tRNA. tRNA contains a 3 nucleic code on one side and on the other side, there’s a special protein on the other. In the cytoplasm, mRNA attracts ribosomes that have a similar 3 letter code of tRNA. The amino acids from tRNA then bond with the mRNA, which then creates a protein chain when a start codon or Methionine is reached. This chain will eventually stop once the stop codon is reached. This will then create a completed protein. In conclusion, even through replication, we are still able to keep our characteristics due to the stationary and unchanging method of replication, which is where we keep the same genetic coding. With the steps of DNA replication, this determines our characteristics, along with our personalities. The more we continue the studying of genetics , we may one day be able to cure disorders before the person is even born or
JordanF DNA RNA Experiment 1 Essay
In this experiment, you will model the effects of mutations on the genetic code. Some mutations cause no structural or functional change to proteins while others can have devastating affects on an organism.
Unit 8 Dna Research Paper
Each human being has something called DNA. DNA is described as genetics and an extremely long macromolecule that is the main component of chromosomes and is the material that transfers genetic characteristics in all life forms. DNA constructs of two nucleotide strands coiled around each other in a ladder like arrangement with the sidepieces composed of alternating phosphate and deoxyribose units and the rungs composed of the purine and pyrimidine bases adenine, guanine, cytosine, and thymine. Each chromosome consist of one continuous thread-like molecule of DNA coiled tightly around proteins and contains a portion of the 6,400,000,000 basepairs that make up your DNA.
Plasmid Lab Report
In this investigation pUC19 plasmids were used as the vector due to its small size of 2686bp, high uptake efficiency by the host and fast replication time. Important features of this plasmid include the origin of replication and multiple cloning sites (MCS). The origin of replication allows the plasmid to replicate inside the host bacterium. The MCS is located within the lacZ gene and contains unique sites for the Xbal & EcoRI restirction enzymes to cut and produce sticky ends for the CIH-1 gene to bind to. Furthermore, the pUC19 plasmid also contains an ampiccilin resistance gene so only transforemed E.coli are able to remain viable when spread on the agar plates that also has the addition of ampiccilin. The lacZ gene encodes the β-galactosidase enzyme which aids in indentifying the recombinant E.coli from the non recombinant cells (Coventry University 2016).
Essay about Your Inner Fish
The DNA contains the information needed to make up our body and even our hands.
Essay On DNA Discoveries
Discoveries in DNA, cell biology, evolution, biotechnology have been among the major achievements in biology over the past 200 years with accelerated discoveries and insights over the last 50 years. Consider the progress we have made in these areas of human knowledge. Present at least three of the discoveries you find to be most important and describe their significance to society, health, and the culture of modern life.
Manipulation And Analysis Of Dna Using Standard Molecular Biology Essay
Analysis of DNA from practicals 1 and 2 using the technique of agarose gel electrophoresis and analysis of transfomed E. coli from practical 2 (part B)
Chromoplast Essay
I've discovered a subroute to uncharted internet on the outer rim of IQ4D9 Chromoplast, but I've venture beyond caution and I am not sure if I can make it back.
DNA and Crime Investigation Essay
- 13 Works Cited
DNA is a long curved structure, made up of pairs of four specific bases: adenine, guanine, cytosine, and thymine, is the repository of a code from which all of our cells are made. The code is made up of base pairs which look like the
Epigenetic Essay
Epigenetics is the study of meiotically or mitotically heritable changes in gene function that do not result from changes in DNA sequence. On a molecular level, epigenetic phenomena are mediated by reversible marks such as DNA methylation, histone modifications, noncoding RNAs, and transcription factors. Previous research has shown that suppressive changes in histone modifications and decreases in DNA methylation occur with age. Additionally, there are cognitive, specifically in learning, memory, and processing speed, deficits associated with age in many animals. Cognitive research has localized the areas of the brain where these deficits originate, such as the medial temporal lobe, hippocampus, and prefrontal cortex, and shown that they are
Semi-Conservative Dna Replication Essay
DNA replication is described as semi-conservative. It is semi-conservative because the replication of one helix results in two daughter helices each of which contains one of the original parental helical strands. Furthermore, it is semi-conservative because the two new daughter DNA molecules are “half old” and “half new”; this means that half the original DNA molecule is saved, or conserved in the daughter DNA molecules.
Cellular Reproduction Essay examples
- 5 Works Cited
Cellular Reproduction Cellular Reproduction is the process by which all living things produce new organisms similar or identical to themselves. This is essential in that if a species were not able to reproduce, that species would quickly become extinct. Always, reproduction consists of a basic pattern: the conversion by a parent organism of raw materials into offspring or cells that will later develop into offspring. (Encarta, 2) In almost all animal organisms, reproduction occurs during or after the period of maximum growth. (Fichter, 16).
DNA Essay example
DNA is a term that has been used in science as well as in many parts of daily
The Process of DNA Replication Essay
The process of DNA replication plays a crucial role in providing genetic continuity from one generation to the next. Knowledge of the structure of DNA began with the discovery of nucleic acids in 1869. In 1952, an accurate model of the DNA molecule was presented, thanks to the work of Rosalind Franklin, James Watson, and Francis Crick. To reproduce, a cell must copy and transmit its genetic information (DNA) to all of its progeny. To do so, DNA replicates following the process of semi-conservative replication. Two strands of DNA are obtained from one, having produced two daughter molecules that are identical to one another and to the parent molecule. This essay reviews the three stages
Annotated Bibliography On Dna Fingerprinting
Due to the DNA’s specificity, samples can be utilised for identification. DNA is a nucleic acid composed of deoxyribose sugar bound to a phosphate group and one of four nitrogenous bases (adenine, guanine, cytosine and thymine). Each section of these three components are referred to as nucleotides, which are joined to the phosphate or sugar of another nucleotide by strong covalent bonds to form a backbone. The nitrogenous bases are joined to complimentary bases of another nucleotide (adenine with thymine, guanine with cytosine) to create a double stranded molecule (Figure 2). To complete the double helical structure, the molecule coils to compact it’s contents. DNA molecules can contain up to two million base pairs, with a human genome containing approximately 3 million base pairs. The random assortment of nitrogenous bases as well as the numerous mutations within certain DNA sequences, results in genetically diverese DNA molecules and genomes between individials.
Genetic Engineering Ethics Essay
All living organisms, from amoebas to humans, have a molecular code called DNA in their cells, which instruct the activities that keep the organism alive. DNA is made up of long, twisted strands of four molecular “letters” (A, T, G, and C), which pair up according to their complementary base pairs, and their order determines how proteins — the vital molecules that perform all the major tasks in our cells — are made. (Refer to Diagram 1 to help sum up the concept.)
Related Topics
- Messenger RNA
Essay On Replication Of DNA

Show More The Replication of Deoxyribonucleic Acid (DNA) and Ribonucleic Acid (RNA) DNA replication is when a cell divides and every new cell has a copy of the original cell’s genetic information. This allows it to synthesize the proteins to build cellular parts and metabolize. Replication of DNA happens during the interphase of a cell cycle. What makes the replication possible is the double-stranded structure of the DNA. During the phase of copying, hydrogen bonds between compatible base pairs in each DNA molecule break. Then the double helix disentangles and pulls apart, revealing the nitrogenous bases. After, DNA polymerase brings new nucleotides, and they form compatible pairs with the exposed bases. The other enzymes unify the …show more content… Making proteins takes various steps and is an enzyme-catalyzed process. Cells are able to synthesize proteins because it is given a specific sequence of nucleotide bases in the DNA of genes and a distinct sequence of amino acid in a protein molecule. The building block sequence is called the genetic code. Expressed in a DNA molecule by a specific sequence of three nucleotides are the twenty types of amino acids in an organic protein. The sequences are G, G, T in one of the types of amino acid: G, C, A in a different one: and T, T, A in another one. The other functions of the remaining nucleotide sequences follow instructions for beginning or ending the synthesis of a protein …show more content… RNA is how genetic information gets to the cytoplasm because it is replicated into its molecules that are able to exit the nucleus. RNA is also a lot shorter than DNA and is single-stranded. The process of synthesizing RNA is called transcription. Messenger RNA is what carries a gene’s message out of the nucleus and other types help build proteins. RNA is different from DNA in many ways. For one, RNA is single-stranded and the nucleotides have sugar ribose instead of deoxyribose. Also while adenine, cytosine and guanine nucleotides are both in DNA and RNA, thymine is only in DNA. Instead of thymine, RNA molecules have uracil nucleotides. The enzyme RNA polymerase synthesis mRNA following the rules of compatible base pairing. For instance, DNA sequence A, T, G, C, G indicates the complementary mRNA bases U, A, C, G, C. Fixed DNA sequences outside genes signal the two strands of DNA that holds the information to build protein. RNA polymerase does the same by acknowledging sequences in the DNA that point to where the gene begins and stops. When the RNA polymerase gets to the end of the gene, newly formed mRNA is released and the process of transcription is
Related Documents
Prokaryote dna synthesis lab report.
They bind to the single stranded DNA created by DnaA protein and move toward the double stranded DNA, turning it into single strand by forcing the strands apart. DnaB helicase is the primary helicase in action in E.Coli. The last part of the prepriming complex is single stranded DNA-binding proteins (SSB). Their job is to create the single stranded template required for the actions of polymerases and to protect the DNA from degradation by nucleases. SSB proteins bind to the single stranded DNA made by the helicases and keep them…
Unit 4 Dna Research Paper
Nucleotide: a nucleic acid monomer, consisting of five carbon sugar covalently bonded to nitrogenous base and phosphate group. DNA “backbone” : chain nucleotide made of sugar and phosphate group that are joined together by covalent bond and are resistant to cleavage Antiparallel: the 2 strands of DNA double helix that run in opposite directions of each other Reactive chemical group at the 5’ end of DNA: phosphate group Reactive chemical group at the 3’ end of DNA : hydroxyl group The four DNA nucleobases thymine (T), adenine (A), Cytosine (C) and guanine (G) , Complementary base pairing adenine and thymine pair (A-T) and guanine and cytosine pair (G-C) Melting temperature: temperature needed to break 50% of the hydrogen bonds Chromatin:…
3.05 Dna Research Paper
RNA polymerase attaches itself to a template of DNA and then go into base pairing, synthesizes mRNA or messenger RNA. This is called transcription, as the DNA code being transcribed into mRNA code. RNA replaces Thymine for Uracil during base pairing. 4. mRNA leaves the nucleus and enters the cytoplasm this goo like part of the cell where ribosomes can be found.…
My Protein Synthesis Analogy: A Softball Team
My protein synthesis analogy is a softball team. My analogy is about the softball team playing defense (in the field) not offense (up to bat). The nucleus is the dugout because the coach is in it and the players exit and enter it. The DNA is the coach because he makes all the plays and decides the lineup, or everyone’s position in the field. The mRNA is the catcher, who receives the signal from the coach and sends it to the pitcher and the other fielders.…
Ultraviolet Radiation Lab Report
Mutations of Penicillium notatum When Introduced to Ultraviolet Radiation in Different Environments Introduction DNA is composed of two strands composed of polynucleotides arranged in a double helix formation composed of four nucleotide subunits: adenine (A), thymine (T), guanine (G), and cytosine (C). Each base must form a hydrogen bond with its respective compatible base, therefore adenine always bonds with thymine and guanine always bonds with cytosine. DNA is used to transfer genetic information to be able to duplicate a cell completely and successfully(6). Mutations occur when the replication of DNA strands result in misplacement of the bases A, T, G, and C. Ultraviolet (UV) radiation is important to the human absorption…
Pros And Cons Of Gene Control
mRNA is translated from a five posion to a three position direction. The beginning end of this translated polypeptide is called the N- terminus, while the "three" end of the polypeptide is the C- terminus. The C terminus is where the stop codon is located and where translation processes end for that mRNA template. The main four phases of translation are pre- initiation, initiation, elongation, and termination. A basic transcription process starts out with a start codon where translation begins by ribosome initiation.…
Social Factors Influencing Gene Expression
DNA gives cells the potential for specific behavior, but this potential will only be realized if the gene is expressed. A gene is expressed if the DNA is transcribed into RNA and then converted into a protein. These proteins can have many different effects on the cell, such as metabolism or neurotransmission. We are now able to tell which specific genes are expressed at a particular time. Gene expression is uncommon, however, with no transcription and only the potential for a behavior as a result.…
Eukaryotic Vs Nucleic Protein Essay
The role of nucleic acids are to store, express, and transmit genetic information. A nucleotide is an organic molecule having three components: one or more phosphate groups, a five carbon sugar, and a single or double ring of carbon and nitrogen atoms. Two types of nucleic acids are DNA and RNA. RNA. The structure of DNA is a double helix formed by base pairs attached to a sugar-phosphate backbone.…
Extracting Dna From Peas Essay
A. Purpose: The purpose of this particular experiment is to see what DNA looks like on a macroscopic scale by extracting DNA from peas. According to the Exploring Creation With Biology 2nd Edition, DNA is short for deoxyribonucleic acid, which is necessary to meet the four crieteria for life. DNA preforms many functions throughout an organism, but its main purpose lies in telling the cell which proteins to make (Wile, Durnell).…
Dna Research Paper
DNA is a molecule of nucleotides, such as adenine, thymine, cytosine, and guanine. They are shown by their first letter: A- Adenine T- Thymine C- Cytosine G- Guanine The backbone that holds the nucleotides are called phosphate and deoxyribose.…
Universality Of Dna Research Paper
It is beyond a doubt that the founding fathers could ever conceive an American society like the one we are living in today. The discovery of the structure of DNA marks a significant landmark in medical history. This has open the doors to a new realm that deepen our understanding of biological systems and promises a future that once was an abstract idea in science fiction novels. A challenge that my generation is facing is answering whether genetic modifications are ethical. Despite the ongoing debates, it is remarkable that this type of science is even possible, partially because of the universality of DNA.…
Dna Profiling Research Paper
Each strand contains a linear arrangement of building blocks named nucleotides and bases. The four types of bases are adenine, thymine, cytosine and guanine which are each represented by the letters A, T, C, and G. The two strands are tied together by the attraction between the four bases. Adenine is only attracted to thymine therefore forming a A-T pair and cytosine is only attracted guanine forming a C-G pair. These two pairs of bases form a bridge across the two strands making the double helix…
DNA In Criminal Investigation
The Importance of DNA in Criminal Investigation How is DNA used in the Criminal Justice System? To better understand how DNA is used and how important it has become for our Justice System we first need to understand what DNA is and how unique it makes every single living thing. In this report I will explain what DNA is, and how it has changed the way the Criminal Justice System is able to match a suspect to a crime. What is DNA?…
Essay On Dna Profiling
The DNA (also known as Deoxyribonucleic acid) in cells is formed of two long strands that wrap around each other. There are four different types of bases in DNA, A (adenine), C (cytosine), G (guanine), T (thymine). These bases join together, A with T and U with G, to form a structure that looks like the twisted steps of a…
Unit 18 Genetics: Questions And Answers
The double helix structure of DNA was first discovered by Francis Crick and James Watson in 1869. 1 mRNA carries genetic information from the DNA to the ribosome and helps choose what amino acid should be produced. mRNA is single stranded and it binds to template as free nucleotides…
Related Topics
Ready to get started.
- Create Flashcards
- Mobile apps
- Cookie Settings
- BiologyDiscussion.com
- Follow Us On:
- Google Plus
- Publish Now
Essay on DNA: Meaning, Features and Forms | Genetics

ADVERTISEMENTS:
In this article we will discuss about:- 1. Meaning of DNA 2. Features of DNA 3. Molecular Structure 4. Components 5. Forms.
- Essay on the Forms of DNA
Essay # 1. Meaning of DNA:
A nucleic acid that carries the genetic information in the cell and is capable of self-replication and RNA synthesis is referred to as DNA. In other words, DNA refers to the molecules inside cells that carry genetic information and pass it from one generation to the next. The scientific name for DNA is deoxyribonucleic acid.
Essay # 2. Features of DNA:
The main features of DNA are given below:
i. Location:
In eukaryotes, DNA is found both in nucleus and cytoplasm. In the nucleus it is a major component of chromosome, whereas in cytoplasm it is found in mitochondria and chloroplasts. In prokaryotes, it is found in the cytoplasm.
ii. Structure:
Mostly the DNA structure is double stranded in both eukaryotes and prokaryotes. However, in some viruses DNA is single stranded. DNA is a double stranded molecule held together by weak bonds between base pairs of nucleotides. The four nucleotides in DNA contain the bases: adenine (A), guanine (G), cytosine (C), and thymine (T).
iii. Shape:
In eukaryotes, the DNA is of linear shape. In prokaryotes and mitochondria; the DNA is circular.
iv. Replication:
The DNA is capable of self-replication. This is the only chemical which has self-replicating capacity. The DNA replicates in semi-conservative manner. In eukaryotes, DNA replicates during the S-Phase of the cell cycle.
There are different forms of DNA such as A, B, C, D and Z DNA. The DNA may be linear or circular. It may be double stranded or single stranded. It may be right handed or left handed. The DNA may be repetitive or unique. It may be nuclear or cytoplasmic.
vi. Functions:
DNA plays important role in various ways. It is used in transcription i.e. synthesis of mRNA which in turn is used in protein synthesis. It carries genetic information from one generation to the next generation. DNA stores and transmits the genetic information in cells.
It forms the basis for genetic code. The genes are made of DNA and are responsible for passing on traits from generation to generation. DNA contains the genetic instructions for the development and functioning of living organisms. Thus it is the substance of heredity.
Essay # 3. Molecular Structure of DNA :
The double helical structure of DNA was identified by Watson and Crick in 1953. This brilliant research work resulted in significant breakthrough in understanding the gene function. This structure has been verified in many different ways and is universally accepted. James Watson and Francis Crick were awarded Nobel prize in 1958 for this significant contribution in the field of molecular biology.
The important features of their model of DNA are as follows:
1. Two helical polynucleotide chains are coiled around a common axis, the chains run in opposite directions.
2. The purine and pyrimidine bases are on the inside of the helix whereas the phosphate and deoxyribose units are situated on the outside. Also the planes of the base residues are perpendicular to the helix axis. While the planes of the sugar residues are almost at right angles to those of the bases.

3. The diameter of the helix is 2 nm. Adjacent bases are separated by 0.34 nm along the helix axis. Hence the helix repeats itself every 10 residues on each chain at intervals of 3.4 nm.
4. The two chains are held together by hydrogen bonds formed between pairs of bases. Pairing is highly specific. Adenine pairs with thymine, guanine always pairs with cytosine. A = T, G = C.
5. The sequence of bases along the polynucleotide chain is not restricted. The precise sequence of bases carries the genetic information.
6. The sugar-phosphate backbones of the two DNA strands wind around the helix axis like the railing of a spiral staircase.
7. The bases of the individual nucleotides are on the inside of the helix, stacked on top of each other like the steps of a spiral staircase.
Essay # 4. Components of DNA :
DNA molecule is a polymer which is composed of several thousand pairs of nucleotide monomers. Union of several nucleotides together leads to the formation of polynucleotide chain. The monomer units of DNA are nucleotides, and the polymer is known as a “polynucleotide.” Each nucleotide consists of a 5-carbon sugar (deoxyribose), a nitrogen containing base attached to the sugar, and a phosphate group.
There are three components of DNA, viz:
(1) Nitrogenous bases,
(2) Deoxyribose sugar, and
(3) Phosphate group.
These are briefly discussed below.
i. Nitrogenous Bases :
Nucleotides are also known as nitrogenous bases or DNA bases. Nitrogenous base are of two types, viz. pyrimidines and purines.
Pyrimidines:
Main features of pyrimidines are given below:
(i) These are single ring structures,
(ii) These are of two types namely cytosine and thymine,
(iii) They occupy less space in DNA structure,
(iv) Pyrimidine is linked with deoxyribose sugar at position 3.
Main features or purines are given below:
(i) They are double ring compounds.
(ii) They are of two types, viz. adenine and guanine.
(iii) They occupy more space in DNA structure.
(iv) Deoxyribose sugar is linked at position 9 of purine.
Thus, in DNA there are four different types of nitrogenous bases, viz. adenine (A), guanine (G), cytosine (C) and thymine (T). In RNA, the pyrimidine base thymine is replace by uracil.
Base Pairing:
The purine and pyrimidine bases always pair in a definite fashion. Adenine will always pair with thymine and guanine with cytosine. Adenine and thymine are joined by double hydrogen bonds while guanine and cytosine are joined by triple hydrogen bonds. However, these bonds are weak which help in separation of DNA strands during replication.
ii. Deoxyribose Sugar :
This is a pentose sugar having five carbon atoms. The four carbon atoms are inside the ring and the fifth one is with CH 2 group. This has three OH groups on 1, 3 and 5 carbon positions. Hydrogen atoms are attached to carbon atoms one to four. In RNA, the sugar ribose is similar to deoxyribose except that it has OH group on carbon atom 2 instead of H group.
iii. Phosphate :
The phosphate molecule is arranged in an alternate manner to deoxyribose molecule. Thus there is deoxyribose on both sides of phosphate. The phosphate is joined with carbon atom 3 of deoxyribose at one side and with carbon atom 5 of deoxyribose on the other side.
Nucleosides and Nucleotides :
A combination of deoxyribose sugar and nitrogenous base is known as nucleoside and a combination of nucleoside and phosphate is called nucleotide.
Nucleoside = Deoxyribose Sugar + Nitrogenous base
Nucleotide = Deoxyribose + Nitrogenous base + Phosphate
Thus, a nucleotide is a nucleoside with one or more phosphate groups covalently attached to it. Nucleosides differ from nucleotides in that they lack phosphate groups. The four different nucleosides of DNA are deoxyadenosine (dA), deoxyguanosine (dG), deoxycytosine (dC), and deoxythymidine (dT).
DNA Backbone :
The DNA backbone is a polymer with an alternating sugar-phosphate sequence. The deoxyribose sugars are joined at both the 3′-hydroxyl and 5′-hydroxyl groups to phosphate groups in ester links, also known as “phosphodiester” bonds.
Essay # 5. Forms of DNA :
Depending upon the nucleotide base per turn of the helix, pitch of the helix, tilt of the base pair and humidity of the sample, the DNA can be observed in four different forms namely, A, B, C and D. The comparison of A, B and Z forms of DNA is presented in Table 15.1.
i. B-form :
This is the same form of DNA proposed by Watson and Crick.
Main features of B form of DNA are given below:
1. This is the most common form of DNA.
2. It is observed when humidity is 92% and salt concentration is high.
3. The coiling is in the right direction.
4. The number of base is 10 per turn of helix.
5. The pitch is 3.4 nm.
6. The sugar phosphate linkage is normal.
7. The helix is narrower and more elongated than A form.
8. The major groove is wide which is easily accessible to proteins.
9. The minor groove is narrow.
10. The conformation is favored at high water concentrations.
11. The base pairing is nearly perpendicular to helix axis.
12. The sugar puckering is C2′-endo.
ii. A-form :
1. This form is observed when the humidity of the sample is 75%.
2. The coiling is in the right direction.
3. The number of bases is 10.7 per turn of helix.
4. The pitch is 2.8 nm.
5. The sugar phosphate linkage is normal.
6. The major groove is deep and narrow which is not easily accessible to proteins.

7. The minor groove is wide and shallow which is accessible to proteins, but information content is lower than major groove.
8. The helix is shorter and wider than B form.
9. The conformation is favored at low water concentrations.
10. The base pairs are tilted to helix axis.
11. The sugar puckering is C3′-endo.
iii. Z-form :
1. The helix has left-handed coiling pattern.
2. The number of bases is 12 per turn of helix.
3. The pitch is 4.5 nm.
4. The sugar phosphate linkage is zigzag.
5. The major “groove” is not really a groove.
6. The minor groove is narrow.
7. The helix is narrower and more elongated than A or B form.
8. The base pairing is nearly perpendicular to helix axis.
9. The conformation is favored by high salt concentrations.
10. The sugar puckering is C: C2 endo, G : C2 exo.
Related Articles:
- Structural Features of DNA | Genetics
- Watson-Crick Model of DNA| Genetics
Essay , Biology , Genetics , Molecular Genetics , Nucleic Acid , DNA
- Anybody can ask a question
- Anybody can answer
- The best answers are voted up and rise to the top
Forum Categories
- Animal Kingdom
- Biodiversity
- Biological Classification
- Biology An Introduction 11
- Biology An Introduction
- Biology in Human Welfare 175
- Biomolecules
- Biotechnology 43
- Body Fluids and Circulation
- Breathing and Exchange of Gases
- Cell- Structure and Function
- Chemical Coordination
- Digestion and Absorption
- Diversity in the Living World 125
- Environmental Issues
- Excretory System
- Flowering Plants
- Food Production
- Genetics and Evolution 110
- Human Health and Diseases
- Human Physiology 242
- Human Reproduction
- Immune System
- Living World
- Locomotion and Movement
- Microbes in Human Welfare
- Mineral Nutrition
- Molecualr Basis of Inheritance
- Neural Coordination
- Organisms and Population
- Photosynthesis
- Plant Growth and Development
- Plant Kingdom
- Plant Physiology 261
- Principles and Processes
- Principles of Inheritance and Variation
- Reproduction 245
- Reproduction in Animals
- Reproduction in Flowering Plants
- Reproduction in Organisms
- Reproductive Health
- Respiration
- Structural Organisation in Animals
- Transport in Plants
- Trending 14
Privacy Overview
| Cookie | Duration | Description |
|---|---|---|
| cookielawinfo-checkbox-analytics | 11 months | This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics". |
| cookielawinfo-checkbox-functional | 11 months | The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional". |
| cookielawinfo-checkbox-necessary | 11 months | This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary". |
| cookielawinfo-checkbox-others | 11 months | This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other. |
| cookielawinfo-checkbox-performance | 11 months | This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance". |
| viewed_cookie_policy | 11 months | The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data. |
An official website of the United States government
The .gov means it’s official. Federal government websites often end in .gov or .mil. Before sharing sensitive information, make sure you’re on a federal government site.
The site is secure. The https:// ensures that you are connecting to the official website and that any information you provide is encrypted and transmitted securely.
- Publications
- Account settings
- My Bibliography
- Collections
- Citation manager
Save citation to file
Email citation, add to collections.
- Create a new collection
- Add to an existing collection
Add to My Bibliography
Your saved search, create a file for external citation management software, your rss feed.
- Search in PubMed
- Search in NLM Catalog
- Add to Search
Mitochondrial DNA replication in mammalian cells: overview of the pathway
Affiliation.
- 1 Department of Medical Biochemistry and Cell Biology, University of Gothenburg, P.O. Box 440, 405 30 Gothenburg, Sweden [email protected].
- PMID: 29880722
- PMCID: PMC6056714
- DOI: 10.1042/EBC20170100
Mammalian mitochondria contain multiple copies of a circular, double-stranded DNA genome and a dedicated DNA replication machinery is required for its maintenance. Many disease-causing mutations affect mitochondrial replication factors and a detailed understanding of the replication process may help to explain the pathogenic mechanisms underlying a number of mitochondrial diseases. We here give a brief overview of DNA replication in mammalian mitochondria, describing our current understanding of this process and some unanswered questions remaining.
Keywords: DNA helicase; DNA polymerase; DNA replication; mitochondrion.
© 2018 The Author(s).
PubMed Disclaimer
Conflict of interest statement
The author declares that there are no competing interests associated with the manuscript.
Figure 1. Map of human mtDNA
The genome encodes for 13 mRNA (green), 22 tRNA…
Figure 2. Replication of the human mitochondrial…
Figure 2. Replication of the human mitochondrial genome
Mitochondrial DNA replication is initiated at O…
Figure 3. Separation and segregation of the…
Figure 3. Separation and segregation of the human mitochondrial genome
After mtDNA replication, the new…
Similar articles
- Mammalian mitochondrial DNA replication and mechanisms of deletion formation. Falkenberg M, Gustafsson CM. Falkenberg M, et al. Crit Rev Biochem Mol Biol. 2020 Dec;55(6):509-524. doi: 10.1080/10409238.2020.1818684. Epub 2020 Sep 24. Crit Rev Biochem Mol Biol. 2020. PMID: 32972254 Review.
- An overview of mammalian mitochondrial DNA replication mechanisms. Yasukawa T, Kang D. Yasukawa T, et al. J Biochem. 2018 Sep 1;164(3):183-193. doi: 10.1093/jb/mvy058. J Biochem. 2018. PMID: 29931097 Free PMC article. Review.
- Mitochondrial DNA replication: clinical syndromes. Almannai M, El-Hattab AW, Scaglia F. Almannai M, et al. Essays Biochem. 2018 Jul 20;62(3):297-308. doi: 10.1042/EBC20170101. Print 2018 Jul 20. Essays Biochem. 2018. PMID: 29950321 Review.
- Primer removal during mammalian mitochondrial DNA replication. Uhler JP, Falkenberg M. Uhler JP, et al. DNA Repair (Amst). 2015 Oct;34:28-38. doi: 10.1016/j.dnarep.2015.07.003. Epub 2015 Aug 12. DNA Repair (Amst). 2015. PMID: 26303841 Review.
- Conserved features of yeast and mammalian mitochondrial DNA replication. Schmitt ME, Clayton DA. Schmitt ME, et al. Curr Opin Genet Dev. 1993 Oct;3(5):769-74. doi: 10.1016/s0959-437x(05)80097-8. Curr Opin Genet Dev. 1993. PMID: 8274861 Review.
- Mitochondrial DNA: Inherent Complexities Relevant to Genetic Analyses. Ferreira T, Rodriguez S. Ferreira T, et al. Genes (Basel). 2024 May 12;15(5):617. doi: 10.3390/genes15050617. Genes (Basel). 2024. PMID: 38790246 Free PMC article. Review.
- TOP3A coupling with replication forks and repair of TOP3A cleavage complexes. Saha LK, Pommier Y. Saha LK, et al. Cell Cycle. 2024 Jan;23(2):115-130. doi: 10.1080/15384101.2024.2314440. Epub 2024 Feb 11. Cell Cycle. 2024. PMID: 38341866 Review.
- mtDNA extramitochondrial replication mediates mitochondrial defect effects. Shan Z, Li S, Gao Y, Jian C, Ti X, Zuo H, Wang Y, Zhao G, Wang Y, Zhang Q. Shan Z, et al. iScience. 2024 Jan 19;27(2):108970. doi: 10.1016/j.isci.2024.108970. eCollection 2024 Feb 16. iScience. 2024. PMID: 38322987 Free PMC article.
- CRISPR/Cas9-mediated base editors and their prospects for mitochondrial genome engineering. Eghbalsaied S, Lawler C, Petersen B, Hajiyev RA, Bischoff SR, Frankenberg S. Eghbalsaied S, et al. Gene Ther. 2024 May;31(5-6):209-223. doi: 10.1038/s41434-023-00434-w. Epub 2024 Jan 4. Gene Ther. 2024. PMID: 38177342 Review.
- Light-strand bias and enriched zones of embedded ribonucleotides are associated with DNA replication and transcription in the human-mitochondrial genome. Xu P, Yang T, Kundnani DL, Sun M, Marsili S, Gombolay AL, Jeon Y, Newnam G, Balachander S, Bazzani V, Baccarani U, Park VS, Tao S, Lori A, Schinazi RF, Kim B, Pursell ZF, Tell G, Vascotto C, Storici F. Xu P, et al. Nucleic Acids Res. 2024 Feb 9;52(3):1207-1225. doi: 10.1093/nar/gkad1204. Nucleic Acids Res. 2024. PMID: 38117983 Free PMC article.
- Berk A.J. and Clayton D.A. (1974) Mechanism of mitochondrial DNA replication in mouse L-cells: asynchronous replication of strands, segregation of circular daughter molecules, aspects of topology and turnover of an initiation sequence. J. Mol. Biol. 86, 801–824 10.1016/0022-2836(74)90355-6 - DOI - PubMed
- Shutt T.E. and Gray M.W. (2006) Bacteriophage origins of mitochondrial replication and transcription proteins. Trends Genet. 22, 90–95 10.1016/j.tig.2005.11.007 - DOI - PubMed
- Gray H. and Wong T.W. (1992) Purification and identification of subunit structure of the human mitochondrial DNA polymerase. J. Biol. Chem. 267, 5835–5841 - PubMed
- Yakubovskaya E., Chen Z., Carrodeguas J.A., Kisker C. and Bogenhagen D.F. (2006) Functional human mitochondrial DNA polymerase gamma forms a heterotrimer. J. Biol. Chem. 281, 374–382 10.1074/jbc.M509730200 - DOI - PubMed
- Fan L., Kim S., Farr C.L., Schaefer K.T., Randolph K.M., Tainer J.A. et al. (2006) A novel processive mechanism for DNA synthesis revealed by structure, modeling and mutagenesis of the accessory subunit of human mitochondrial DNA polymerase. J. Mol. Biol. 358, 1229–1243 10.1016/j.jmb.2006.02.073 - DOI - PMC - PubMed
Publication types
- Search in MeSH
Related information
Linkout - more resources, full text sources.
- Europe PubMed Central
- PubMed Central
- Silverchair Information Systems
Other Literature Sources
- scite Smart Citations
- Citation Manager
NCBI Literature Resources
MeSH PMC Bookshelf Disclaimer
The PubMed wordmark and PubMed logo are registered trademarks of the U.S. Department of Health and Human Services (HHS). Unauthorized use of these marks is strictly prohibited.
Information
- Author Services
Initiatives
You are accessing a machine-readable page. In order to be human-readable, please install an RSS reader.
All articles published by MDPI are made immediately available worldwide under an open access license. No special permission is required to reuse all or part of the article published by MDPI, including figures and tables. For articles published under an open access Creative Common CC BY license, any part of the article may be reused without permission provided that the original article is clearly cited. For more information, please refer to https://www.mdpi.com/openaccess .
Feature papers represent the most advanced research with significant potential for high impact in the field. A Feature Paper should be a substantial original Article that involves several techniques or approaches, provides an outlook for future research directions and describes possible research applications.
Feature papers are submitted upon individual invitation or recommendation by the scientific editors and must receive positive feedback from the reviewers.
Editor’s Choice articles are based on recommendations by the scientific editors of MDPI journals from around the world. Editors select a small number of articles recently published in the journal that they believe will be particularly interesting to readers, or important in the respective research area. The aim is to provide a snapshot of some of the most exciting work published in the various research areas of the journal.
Original Submission Date Received: .
- Active Journals
- Find a Journal
- Proceedings Series
- For Authors
- For Reviewers
- For Editors
- For Librarians
- For Publishers
- For Societies
- For Conference Organizers
- Open Access Policy
- Institutional Open Access Program
- Special Issues Guidelines
- Editorial Process
- Research and Publication Ethics
- Article Processing Charges
- Testimonials
- Preprints.org
- SciProfiles
- Encyclopedia
Article Menu

- Subscribe SciFeed
- Recommended Articles
- Google Scholar
- on Google Scholar
- Table of Contents
Find support for a specific problem in the support section of our website.
Please let us know what you think of our products and services.
Visit our dedicated information section to learn more about MDPI.
JSmol Viewer
The function of h2a histone variants and their roles in diseases.

1. Introduction
2. the functions of h2a histone variants, 2.1. gene transcription, 2.2. dna damage repair, 3. the roles of histone h2a variants in diseases, 3.1. cancer.
| Histone Variants | Types of Cancer | Potential Mechanisms |
|---|---|---|
| H2A.Z | Lung cancer | Increases the sensitivity of lung cancer cells to radiotherapy [ ]. |
| Breast cancer | Activates the expression of cyclin A1, thus promoting breast cancer development [ ]. | |
| Malignant melanoma | H2A.Z2 enhances tumor sensitivity to drugs by gene transcriptional regulation for E2F1 in malignant melanoma [ ]. | |
| Uterine leiomyoma | Deficient H2A.Z disposition in uterine leiomyoma cells with SRCAP complex mutations suggests a cancer inhibition role [ ]. | |
| Hepatocellular carcinoma | H2A.Z1 promotes tumorigenesis, mainly through cell cycle signaling and the DNA damage pathway [ ], and H2A.Z acetylation promotes downstream pro-oncogene transcription in liver cancer [ ]. | |
| Bladder cancer | Promotes pro-oncogene expression in bladder cancer [ ]. | |
| H2A.X | Gastrointestinal cancer | Inhibits EMT and promotes autophagy in colon cancer [ ]. |
| Breast cancer | Increases Twist1 and Slug transcription factors, regulates EMT, and facilitates tumor cell migration and invasion after H2A.X deletion in breast cancer [ ]. | |
| Prostate cancer | Inhibits the proliferation of prostate cancer cells [ ]. | |
| Lung cancer | H2A.X deletion causes DNA breaks and cell cycle arrest in lung cancer [ ]. | |
| Head and neck carcinoma | A marker of DNA damage repair in head and neck carcinoma [ ]. | |
| Leukemia | Patients diagnosed with cancer usually occur in the absence of H2A.X in leukemia [ ]. | |
| macroH2A | Malignant melanoma | Activates CDK8 to promote the development of malignant melanoma [ ]. |
| Anal carcinoma | MacroH2A2 promotes the progression of anal carcinoma [ ]. | |
| Glioblastoma | MacroH2A2 antagonizes tumor self-renewal and inhibits glioblastoma growth [ ]. | |
| Solitary dormant disseminated cancer | nhibit cell cycle and pro-tumor-related signaling pathways in solitary dormant disseminated cancer [ ]. | |
| Breast cancer | IMacroH2A1.1 acts as a suppressor of EMT in breast cells [ ]. | |
| Colon cancer | Knockdown of macroH2A1.1 promotes tumor cell growth and proliferation in colon cancer [ ]. | |
| Hematologic malignancies | Lacking macroH2A1.1 induces the development of hematologic malignancies [ ]. | |
| Prostate cancers | MacroH2A1.2 is a tumor suppressor and inhibits osteoclast formation in prostate cancers [ ]. | |
| H2A.B | Hodgkin’s lymphoma | Interacts with RNA polymerase II, increases ribosome biosynthesis in tumor cells, and promotes tumor development [ ]. |
3.2. Embryonic Development Abnormalities
3.3. other diseases, 4. conclusions.
| Histone H2A Variants | Distribution | Isoforms | Role in Gene Transcription | Role in DNA Damage Repair | Pathophysiological Processes Involved | The Roles in Disease |
|---|---|---|---|---|---|---|
| H2A.Z | Global | H2A.Z1 H2A.Z2 H2A.Z2.2 | Gene transcription activation or inhibition [ , ]. The mechanism is associated with the stability of nucleosomes [ ], enhancer activity [ ], RNA polymerase II pausing [ , ], and PTMs of H2A.Z nucleosomes [ , , ]. | Promotes DNA repair [ , , ]. Removing from nucleosomes recruiting repair factors to the break region and promoting DNA damage repair [ , ]. | Tumorigenesis [ , , ] Embryonic development disorders [ , , ] Neurological diseases [ , ] Heart diseases [ ] | Promotes tumorigenesis [ , , ]. Inhibits tumorigenesis in uterine leiomyoma cells with SRCAP complex mutations [ ]. H2A.Z knockout mouse embryos die [ ]. Regulates neurogenesis [ , ], affects learning and memory [ ], and mediates the progression of schizophrenia [ ]. Cardiac hypertrophy [ ] and regulation of cardiac growth [ ]. |
| H2A.X | Global | Transcription related [ ]. The phosphorylation H2A.X axis mediates TGFB1-associated gene transcription activation, aggravating pulmonary fibrosis [ ]. | Accelerates DNA damage repair [ , ] γ-H2A.X amplifies the signal and functions as a platform for assembling the DNA damage repair machinery [ , ]. | Tumorigenesis [ , , ] Embryonic development disorders [ ] Neurological diseases [ ] Heart diseases [ , ] Metabolic diseases [ ] | Inhibits tumorigenesis [ , , ]. H2A.X knockout mice exhibit reduced fertility and a decreased number of lymphocytes, resulting in immune deficiencies [ ]. Depletion of H2A.X causes neurological disorders [ , ]. Aberrant expression in heart diseases [ , ]. Mediating mitochondrial function [ ] and oxidative stress processes [ ]. | |
| macroH2A | Global | macroH2A1.1 macroH2A1.2 macroH2A2 | Mostly represses gene transcription [ ]. The mechanism is associated with RNA polymerase II initiation [ ], chromatin remodeling [ ], histone acetylation [ ], transcription factors activity [ ], and chromatin condensation [ ]. | Promotes DNA damage repair. Required for transcriptional repression near breaks following DNA damage [ , , , ] MacroH2A1.2 recruits DNA damage repair mediators [ ]. MacroH2A1.1 impedes the activity of PARP1 [ , ]. | Tumorigenesis [ , , ] Embryonic development disorder [ , ] Neurological diseases [ ] Metabolic diseases [ , ] | Promotes tumorigenesis or inhibits tumorigenesis [ , ]. MacroH2A-deficient mice’s growth and development are restricted [ ]. The absence of macroH2A1.2 in mice leads to the manifestation of ASD [ ]. Promotes adipogenesis [ ]. Reduces lipid accumulation in hepatocytes [ ]. |
| H2A.B | Mainly in the testes and brain | Promotes gene transcription [ , ]. H2A.B nucleosomes are poorly stable, resulting in easy dissociation from chromatin, the formation of open chromatin structures, and gene transcription activation [ , ]. | Causes DNA damage [ ] H2A.B overexpression in Hela cells induces DNA damage and subsequent apoptosis by activating the NF-κβ pathway [ ]. | Tumorigenesis [ ] Embryonic development disorders [ ] Metabolic diseases [ ] | Promotes tumor development [ ]. The viability of embryos from H2A.B knockout male mice mated with female mice is reduced [ ]. Aberrant expression in diabetic oocytes [ ]. |
Author Contributions
Data availability statement, conflicts of interest.
- Luger, K.; Mäder, A.W.; Richmond, R.K.; Sargent, D.F.; Richmond, T.J. Crystal structure of the nucleosome core particle at 2.8 a resolution. Nature 1997 , 389 , 251–260. [ Google Scholar ] [ CrossRef ]
- Talbert, P.B.; Henikoff, S. Histone variants at a glance. J. Cell Sci. 2021 , 134 , jcs244749. [ Google Scholar ] [ CrossRef ]
- Talbert, P.B.; Henikoff, S. Histone variants on the move: Substrates for chromatin dynamics. Nat. Rev. Mol. Cell Biol. 2017 , 18 , 115–126. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Billon, P.; Côté, J. Precise deposition of histone H2A.Z in chromatin for genome expression and maintenance. Biochim. Biophys. Acta (BBA)—Gene Regul. Mech. 2012 , 1819 , 290–302. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Hammond, C.M.; Strømme, C.B.; Huang, H.; Patel, D.J.; Groth, A. Histone chaperone networks shaping chromatin function. Nat. Rev. Mol. Cell Biol. 2017 , 18 , 141–158. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Sokolova, V.; Sarkar, S.; Tan, D. Histone variants and chromatin structure, update of advances. Comp. Struct. Biotechnol. J. 2023 , 21 , 299–311. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Talbert, P.B.; Ahmad, K.; Almouzni, G.; Ausió, J.; Berger, F.; Bhalla, P.L.; Bonner, W.M.; Cande, W.Z.; Chadwick, B.P.; Chan, S.W.; et al. A unified phylogeny-based nomenclature for histone variants. Epigenetics Chromatin 2012 , 5 , 7. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Kurumizaka, H.; Kujirai, T.; Takizawa, Y. Contributions of histone variants in nucleosome structure and function. J. Mol. Biol. 2021 , 433 , 166678. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Martire, S.; Banaszynski, L.A. The roles of histone variants in fine-tuning chromatin organization and function. Nat. Rev. Mol. Cell Biol. 2020 , 21 , 522–541. [ Google Scholar ] [ CrossRef ]
- Feng, J.X.; Riddle, N.C. Epigenetics and genome stability. Mamm. Genome 2020 , 31 , 181–195.11. [ Google Scholar ] [ CrossRef ]
- Dunjić, M.; Jonas, F.; Yaakov, G.; More, R.; Mayshar, Y.; Rais, Y.; Orenbuch, A.H.; Cheng, S.; Barkai, N.; Stelzer, Y. Histone exchange sensors reveal variant specific dynamics in mouse embryonic stem cells. Nat. Commun. 2023 , 14 , 3791. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Torres-Arciga, K.; Flores-León, M.; Ruiz-Pérez, S.; Trujillo-Pineda, M.; González-Barrios, R.; Herrera, L.A. Histones and their chaperones: Adaptive remodelers of an ever-changing chromatinic landscape. Front. Genet. 2022 , 13 , 1057846. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Pardal, A.J.; Fernandes-Duarte, F.; Bowman, A.J. The histone chaperoning pathway: From ribosome to nucleosome. Essays Biochem. 2019 , 63 , 29–43. [ Google Scholar ]
- Burgess, R.J.; Zhang, Z. Histone chaperones in nucleosome assembly and human disease. Nat. Struct. Mol. Biol. 2013 , 20 , 14–22. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Oberdoerffer, P.; Miller, K.M. Histone H2A variants: Diversifying chromatin to ensure genome integrity. Semin. Cell Dev. Biol. 2023 , 135 , 59–72. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Herchenrother, A.; Wunderlich, T.M.; Lan, J.; Hake, S.B. Spotlight on histone H2A variants: From B to X to Z. Semin. Cell Dev. Biol. 2023 , 135 , 3–12. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Ausió, J.; Abbott, D.W. The many tales of a tail: Carboxyl-terminal tail heterogeneity specializes histone H2A variants for defined chromatin function. Biochemistry 2002 , 41 , 5945–5949. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Bönisch, C.; Hake, S.B. Histone H2A variants in nucleosomes and chromatin: More or less stable? Nucleic Acids Res. 2012 , 40 , 10719–10741. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Peng, J.; Yuan, C.; Hua, X.; Zhang, Z. Molecular mechanism of histone variant H2A.B on stability and assembly of nucleosome and chromatin structures. Epigenet. Chromatin 2020 , 13 , 28. [ Google Scholar ] [ CrossRef ]
- Zhou, M.; Dai, L.; Li, C.; Shi, L.; Huang, Y.; Guo, Z.; Wu, F.; Zhu, P.; Zhou, Z. Structural basis of nucleosome dynamics modulation by histone variants H2A.B and H2A.Z.2.2. EMBO J. 2021 , 40 , e105907. [ Google Scholar ] [ CrossRef ]
- Giaimo, B.D.; Ferrante, F.; Herchenröther, A.; Hake, S.B.; Borggrefe, T. The histone variant H2A.Z in gene regulation. Epigenet. Chromatin 2019 , 12 , 37. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Sales-Gil, R.; Kommer, D.C.; de Castro, I.J.; Amin, H.A.; Vinciotti, V.; Sisu, C.; Vagnarelli, P. Non-redundant functions of H2A.Z.1 and H2A.Z.2 in chromosome segregation and cell cycle progression. EMBO Rep. 2021 , 22 , e52061. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Bönisch, C.; Schneider, K.; Pünzeler, S.; Wiedemann, S.M.; Bielmeier, C.; Bocola, M.; Eberl, H.C.; Kuegel, W.; Neumann, J.; Kremmer, E.; et al. H2A.Z.2.2 is an alternatively spliced histone H2A.Z variant that causes severe nucleosome destabilization. Nucleic Acids Res. 2012 , 40 , 5951–5964. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Greenberg, R.S.; Long, H.K.; Swigut, T.; Wysocka, J. Single amino acid change underlies distinct roles of H2A.Z subtypes in human syndrome. Cell 2019 , 178 , 1421–1436. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Colino-Sanguino, Y.; Clark, S.J.; Valdes-Mora, F. The H2A.Z-nucleosome code in mammals: Emerging functions. Trends Genet. 2022 , 38 , 516. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Hardy, S.; Jacques, P.E.; Gévry, N.; Forest, A.; Fortin, M.E.; Laflamme, L.; Gaudreau, L.; Robert, F. The euchromatic and heterochromatic landscapes are shaped by antagonizing effects of transcription on H2A.Z deposition. PLoS Genet. 2009 , 5 , e1000687. [ Google Scholar ] [ CrossRef ]
- Moreno-Andrés, D.; Yokoyama, H.; Scheufen, A.; Holzer, G.; Lue, H.; Schellhaus, A.K.; Weberruss, M.; Takagi, M.; Antonin, W. Vps72/yl1-mediated H2A.Z deposition is required for nuclear reassembly after mitosis. Cells 2020 , 9 , 1702. [ Google Scholar ] [ CrossRef ]
- Obri, A.; Ouararhni, K.; Papin, C.; Diebold, M.L.; Padmanabhan, K.; Marek, M.; Stoll, I.; Roy, L.; Reilly, P.T.; Mak, T.W.; et al. Anp32e is a histone chaperone that removes H2A.Z from chromatin. Nature 2014 , 505 , 648–653. [ Google Scholar ] [ CrossRef ]
- Rudnizky, S.; Bavly, A.; Malik, O.; Pnueli, L.; Melamed, P.; Kaplan, A. H2A.Z controls the stability and mobility of nucleosomes to regulate expression of the LH genes. Nat. Commun. 2016 , 7 , 12958. [ Google Scholar ] [ CrossRef ]
- Li, S.; Wei, T.; Panchenko, A.R. Histone variant H2A.Z modulates nucleosome dynamics to promote DNA accessibility. Nat. Commun. 2023 , 14 , 769. [ Google Scholar ] [ CrossRef ]
- Day, D.S.; Zhang, B.; Stevens, S.M.; Ferrari, F.; Larschan, E.N.; Park, P.J.; Pu, W.T. Comprehensive analysis of promoter-proximal RNA polymerase II pausing across mammalian cell types. Genome Biol. 2016 , 17 , 120. [ Google Scholar ] [ CrossRef ]
- Cole, L.; Kurscheid, S.; Nekrasov, M.; Domaschenz, R.; Vera, D.L.; Dennis, J.H.; Tremethick, D.J. Multiple roles of H2A.Z in regulating promoter chromatin architecture in human cells. Nat. Commun. 2021 , 12 , 2524. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Domaschenz, R.; Kurscheid, S.; Nekrasov, M.; Han, S.; Tremethick, D.J. The histone variant H2A.Z is a master regulator of the epithelial-mesenchymal transition. Cell Rep. 2017 , 21 , 943–952. [ Google Scholar ] [ CrossRef ]
- Lewis, T.S.; Sokolova, V.; Jung, H.; Ng, H.; Tan, D. Structural basis of chromatin regulation by histone variant H2A.Z. Nucleic Acids Res. 2021 , 49 , 11379–11391. [ Google Scholar ] [ CrossRef ]
- Suto, R.K.; Clarkson, M.J.; Tremethick, D.J.; Luger, K. Crystal structure of a nucleosome core particle containing the variant histone H2A.Z. Nat. Struct. Biol. 2000 , 7 , 1121–1124. [ Google Scholar ]
- Shin, H.; He, M.; Yang, Z.; Jeon, Y.H.; Pfleger, J.; Sayed, D.; Abdellatif, M. Transcriptional regulation mediated by H2A.Z via Anp32e-dependent inhibition of protein phosphatase 2A. Biochim. Biophys. Acta-Gene Regul. Mech. 2018 , 1861 , 481–496. [ Google Scholar ] [ CrossRef ]
- Tsai, C.H.; Chen, Y.J.; Yu, C.J.; Tzeng, S.R.; Wu, I.C.; Kuo, W.H.; Lin, M.C.; Chan, N.L.; Wu, K.J.; Teng, S.C. SMYD3-mediated H2A.Z.1 methylation promotes cell cycle and cancer proliferation. Cancer Res. 2016 , 76 , 6043–6053. [ Google Scholar ] [ CrossRef ]
- Li, X.; Mei, Q.; Yu, Q.; Wang, M.; He, F.; Xiao, D.; Liu, H.; Ge, F.; Yu, X.; Li, S. The TORC1 activates Rpd3l complex to deacetylate INO80 and H2A.Z and repress autophagy. Sci. Adv. 2023 , 9 , e8312. [ Google Scholar ] [ CrossRef ]
- Soboleva, T.A.; Parker, B.J.; Nekrasov, M.; Hart-Smith, G.; Tay, Y.J.; Tng, W.; Wilkins, M.; Ryan, D.; Tremethick, D.J. A new link between transcriptional initiation and pre-mRNA splicing: The RNA binding histone variant H2A.B. PLoS Genet. 2017 , 13 , e1006633. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Okuwaki, M.; Kato, K.; Shimahara, H.; Tate, S.; Nagata, K. Assembly and disassembly of nucleosome core particles containing histone variants by human nucleosome assembly protein I. Mol. Cell. Biol. 2005 , 25 , 10639–10651. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Jiang, X.; Soboleva, T.A.; Tremethick, D.J. Short histone H2A variants: Small in stature but not in function. Cells 2020 , 9 , 867. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Soboleva, T.A.; Nekrasov, M.; Pahwa, A.; Williams, R.; Huttley, G.A.; Tremethick, D.J. A unique H2A histone variant occupies the transcriptional start site of active genes. Nat. Struct. Mol. Biol. 2011 , 19 , 25–30. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Kohestani, H.; Wereszczynski, J. Effects of H2A.B incorporation on nucleosome structures and dynamics. Biophys. J. 2021 , 120 , 1498–1509. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Anuar, N.D.; Kurscheid, S.; Field, M.; Zhang, L.; Rebar, E.; Gregory, P.; Buchou, T.; Bowles, J.; Koopman, P.; Tremethick, D.J.; et al. Gene editing of the multi-copy H2A.B gene and its importance for fertility. Genome Biol. 2019 , 20 , 23. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Baralle, F.E.; Giudice, J. Alternative splicing as a regulator of development and tissue identity. Nat. Rev. Mol. Cell Biol. 2017 , 18 , 437–451. [ Google Scholar ] [ CrossRef ]
- Hirano, R.; Arimura, Y.; Kujirai, T.; Shibata, M.; Okuda, A.; Morishima, K.; Inoue, R.; Sugiyama, M.; Kurumizaka, H. Histone variant H2A.B-H2B dimers are spontaneously exchanged with canonical H2A-H2B in the nucleosome. Commun. Biol. 2021 , 4 , 191. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Arimura, Y.; Kimura, H.; Oda, T.; Sato, K.; Osakabe, A.; Tachiwana, H.; Sato, Y.; Kinugasa, Y.; Ikura, T.; Sugiyama, M.; et al. Structural basis of a nucleosome containing histone H2A.B/H2A.Bbd that transiently associates with reorganized chromatin. Sci. Rep. 2013 , 3 , 3510. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Goshima, T.; Shimada, M.; Sharif, J.; Matsuo, H.; Misaki, T.; Johmura, Y.; Murata, K.; Koseki, H.; Nakanishi, M. Mammal-specific H2A variant, H2A.Bbd, is involved in apoptotic induction via activation of NF-κB signaling pathway. J. Biol. Chem. 2014 , 289 , 11656–11666. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Rivera-Casas, C.; Gonzalez-Romero, R.; Cheema, M.S.; Ausió, J.; Eirín-López, J.M. The characterization of macroH2A beyond vertebrates supports an ancestral origin and conserved role for histone variants in chromatin. Epigenetics 2016 , 11 , 415–425. [ Google Scholar ] [ CrossRef ]
- Sun, Z.; Bernstein, E. Histone variant macroH2A: From chromatin deposition to molecular function. Essays Biochem. 2019 , 63 , 59–74. [ Google Scholar ]
- Mehrotra, P.V.; Ahel, D.; Ryan, D.P.; Weston, R.; Wiechens, N.; Kraehenbuehl, R.; Owen-Hughes, T.; Ahel, I. DNA repair factor APLF is a histone chaperone. Mol. Cell 2011 , 41 , 46–55. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Mandemaker, I.K.; Fessler, E.; Corujo, D.; Kotthoff, C.; Wegerer, A.; Rouillon, C.; Buschbeck, M.; Jae, L.T.; Mattiroli, F.; Ladurner, A.G. The histone chaperone Anp32B regulates chromatin incorporation of the atypical human histone variant macroH2A. Cell Rep. 2023 , 42 , 113300. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Doyen, C.M.; An, W.; Angelov, D.; Bondarenko, V.; Mietton, F.; Studitsky, V.M.; Hamiche, A.; Roeder, R.G.; Bouvet, P.; Dimitrov, S. Mechanism of polymerase II transcription repression by the histone variant macroH2A. Mol. Cell. Biol. 2006 , 26 , 1156–1164. [ Google Scholar ] [ CrossRef ]
- Chakravarthy, S.; Patel, A.; Bowman, G.D. The basic linker of macroH2A stabilizes DNA at the entry/exit site of the nucleosome. Nucleic Acids Res. 2012 , 40 , 8285–8295.55. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Douet, J.; Corujo, D.; Malinverni, R.; Renauld, J.; Sansoni, V.; Marjanović, M.P.; Cantari’O, N.; Valero, V.; Mongelard, F.; Bouvet, P.; et al. MacroH2A histone variants maintain nuclear organization and heterochromatin architecture. J. Cell Sci. 2017 , 130 , 1570–1582. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Kim, J.M.; Heo, K.; Choi, J.; Kim, K.; An, W. The histone variant macroH2A regulates Ca(2+) influx through TRPC3 and TRPC6 channels. Oncogenesis 2013 , 2 , e77. [ Google Scholar ] [ CrossRef ]
- Chang, E.Y.; Ferreira, H.; Somers, J.; Nusinow, D.A.; Owen-Hughes, T.; Narlikar, G.J. MacroH2A allows ATP-dependent chromatin remodeling by SWI/SNF and ACF complexes but specifically reduces recruitment of SWI/SNF. Biochemistry 2008 , 47 , 13726–13732. [ Google Scholar ] [ CrossRef ]
- Lavigne, M.D.; Vatsellas, G.; Polyzos, A.; Mantouvalou, E.; Sianidis, G.; Maraziotis, I.; Agelopoulos, M.; Thanos, D. Composite macroH2A/NRF-1 nucleosomes suppress noise and generate robustness in gene expression. Cell Rep. 2015 , 11 , 1090–1101. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Recoules, L.; Heurteau, A.; Raynal, F.; Karasu, N.; Moutahir, F.; Bejjani, F.; Jariel-Encontre, I.; Cuvier, O.; Sexton, T.; Lavigne, A.C.; et al. The histone variant macroH2A1.1 regulates RNA polymerase II-paused genes within defined chromatin interaction landscapes. J. Cell Sci. 2022 , 135 , jcs259456. [ Google Scholar ] [ CrossRef ]
- Xu, Y.; Ayrapetov, M.K.; Xu, C.; Gursoy-Yuzugullu, O.; Hu, Y.; Price, B.D. Histone H2A.Z controls a critical chromatin re-modeling step required for DNA double-strand break repair. Mol. Cell 2012 , 48 , 723–733. [ Google Scholar ] [ CrossRef ]
- Gursoy-Yuzugullu, O.; Ayrapetov, M.K.; Price, B.D. Histone chaperone Anp32e removes H2A.Z from DNA double-strand breaks and promotes nucleosome reorganization and DNA repair. Proc. Natl. Acad. Sci. USA 2015 , 112 , 7507–7512. [ Google Scholar ] [ CrossRef ]
- Bao, Y. Chromatin response to DNA double-strand break damage. Epigenomics 2011 , 3 , 307–321. [ Google Scholar ] [ CrossRef ]
- Alatwi, H.E.; Downs, J.A. Removal of H2A.Z by INO80 promotes homologous recombination. EMBO Rep. 2015 , 16 , 986–994. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Rona, G.; Roberti, D.; Yin, Y.; Pagan, J.K.; Homer, H.; Sassani, E.; Zeke, A.; Busino, L.; Rothenberg, E.; Pagano, M. PARP1-dependent recruitment of the FBXL10-RNF68-RNF2 ubiquitin ligase to sites of DNA damage controls H2A.Z loading. eLife 2018 , 7 , e38771. [ Google Scholar ] [ CrossRef ]
- Ui, A.; Chiba, N.; Yasui, A. Relationship among DNA double-strand break (DSB), DSB repair, and transcription prevents genome instability and cancer. Cancer Sci. 2020 , 111 , 1443–1451. [ Google Scholar ] [ CrossRef ]
- Milano, L.; Gautam, A.; Caldecott, K.W. DNA damage and transcription stress. Mol. Cell 2024 , 84 , 70–79. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Henikoff, S.; Smith, M.M. Histone variants and epigenetics. Cold Spring Harb. Perspect. Biol. 2015 , 7 , a19364. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Seo, J.; Kim, S.C.; Lee, H.S.; Kim, J.K.; Shon, H.J.; Salleh, N.L.; Desai, K.V.; Lee, J.H.; Kang, E.S.; Kim, J.S.; et al. Genome-wide profiles of H2AX and γ-H2AX differentiate endogenous and exogenous DNA damage hotspots in human cells. Nucleic Acids Res. 2012 , 40 , 5965–5974. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Piquet, S.; Le Parc, F.; Bai, S.K.; Chevallier, O.; Adam, S.; Polo, S.E. The histone chaperone FACT coordinates H2A.X-dependent signaling and repair of DNA damage. Mol. Cell 2018 , 72 , 888–901. [ Google Scholar ] [ CrossRef ]
- Heo, K.; Kim, H.; Choi, S.H.; Choi, J.; Kim, K.; Gu, J.; Lieber, M.R.; Yang, A.S.; An, W. FACT-mediated exchange of histone variant H2Ax regulated by phosphorylation of H2AX and ADP-ribosylation of SPT16. Mol. Cell 2008 , 30 , 86–97. [ Google Scholar ] [ CrossRef ]
- Li, M.; Fang, Y. Histone variants: The artists of eukaryotic chromatin. Sci. China Life Sci. 2015 , 58 , 232–239. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Xiao, A.; Li, H.; Shechter, D.; Ahn, S.H.; Fabrizio, L.A.; Erdjument-Bromage, H.; Ishibe-Murakami, S.; Wang, B.; Tempst, P.; Hofmann, K.; et al. WSTF regulates the H2A.X DNA damage response via a novel tyrosine kinase activity. Nature 2009 , 457 , 57–62. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Schwertman, P.; Bekker-Jensen, S.; Mailand, N. Regulation of DNA double-strand break repair by ubiquitin and ubiquitin-like modifiers. Nat. Rev. Mol. Cell Biol. 2016 , 17 , 379–394. [ Google Scholar ] [ CrossRef ]
- Qiu, L.; Xu, W.; Lu, X.; Chen, F.; Chen, Y.; Tian, Y.; Zhu, Q.; Liu, X.; Wang, Y.; Pei, X.H.; et al. The HDAC6-RNF168 axis regulates H2A/H2A.X ubiquitination to enable double-strand break repair. Nucleic Acids Res. 2023 , 51 , 9166–9182. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Pan, M.R.; Peng, G.; Hung, W.C.; Lin, S.Y. Monoubiquitination of H2AX protein regulates DNA damage response signaling. J. Biol. Chem. 2011 , 286 , 28599–28607. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Mattiroli, F.; Vissers, J.H.; van Dijk, W.J.; Ikpa, P.; Citterio, E.; Vermeulen, W.; Marteijn, J.A.; Sixma, T.K. RNF168 ubiquitinates k13-15 on H2A/H2AX to drive DNA damage signaling. Cell 2012 , 150 , 1182–1195. [ Google Scholar ] [ CrossRef ]
- Sharma, D.; De Falco, L.; Padavattan, S.; Rao, C.; Geifman-Shochat, S.; Liu, C.F.; Davey, C.A. PARP1 exhibits enhanced association and catalytic efficiency with gammaH2A.X-nucleosome. Nat. Commun. 2019 , 10 , 5751. [ Google Scholar ] [ CrossRef ]
- Novo, N.; Romero-Tamayo, S.; Marcuello, C.; Boneta, S.; Blasco-Machin, I.; Velázquez-Campoy, A.; Villanueva, R.; Moreno-Loshuertos, R.; Lostao, A.; Medina, M.; et al. Beyond a platform protein for the degradosome assembly: The apoptosis-inducing factor as an efficient nuclease involved in chromatinolysis. Proc. Natl. Acad. Sci. USA Nexus 2023 , 2 , c312. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Artus, C.; Boujrad, H.; Bouharrour, A.; Brunelle, M.N.; Hoos, S.; Yuste, V.J.; Lenormand, P.; Rousselle, J.C.; Namane, A.; England, P.; et al. AIF promotes chromatinolysis and caspase-independent programmed necrosis by interacting with histone H2Ax. EMBO J. 2010 , 29 , 1585–1599. [ Google Scholar ] [ CrossRef ]
- Bano, D.; Prehn, J. Apoptosis-inducing factor (AIF) in physiology and disease: The tale of a repented natural born killer. EBioMedicine 2018 , 30 , 29–37. [ Google Scholar ] [ CrossRef ]
- Dobersch, S.; Rubio, K.; Singh, I.; Günther, S.; Graumann, J.; Cordero, J.; Castillo-Negrete, R.; Huynh, M.B.; Mehta, A.; Braubach, P.; et al. Positioning of nucleosomes containing γ-H2AX precedes active DNA demethylation and transcription initiation. Nat. Commun. 2021 , 12 , 1072. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Orlando, L.; Tanasijevic, B.; Nakanishi, M.; Reid, J.C.; García-Rodríguez, J.L.; Chauhan, K.D.; Porras, D.P.; Aslostovar, L.; Lu, J.D.; Shapovalova, Z.; et al. Phosphorylation state of the histone variant H2A.X controls human stem and progenitor cell fate decisions. Cell Rep. 2021 , 34 , 108818. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Kozlowski, M.; Corujo, D.; Hothorn, M.; Guberovic, I.; Mandemaker, I.K.; Blessing, C.; Sporn, J.; Gutierrez-Triana, A.; Smith, R.; Portmann, T.; et al. MacroH2A histone variants limit chromatin plasticity through two distinct mechanisms. EMBO Rep. 2018 , 19 , e44445. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Khurana, S.; Kruhlak, M.J.; Kim, J.; Tran, A.D.; Liu, J.; Nyswaner, K.; Shi, L.; Jailwala, P.; Sung, M.H.; Hakim, O.; et al. A macrohistone variant links dynamic chromatin compaction to BRCA1-dependent genome maintenance. Cell Rep. 2014 , 8 , 1049–1062. [ Google Scholar ] [ CrossRef ]
- Kim, D.; Challa, S.; Jones, A.; Kraus, W.L. PARPs and ADP-ribosylation in RNA biology: From RNA expression and processing to protein translation and proteostasis. Genes. Dev. 2020 , 34 , 302–320. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Ruiz, P.D.; Hamilton, G.A.; Park, J.W.; Gamble, M.J. MacroH2A1 regulation of poly(ADP-ribose) synthesis and stability prevents necrosis and promotes DNA repair. Mol. Cell. Biol. 2019 , 40 , e00230-19. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Chen, H.; Ruiz, P.D.; Novikov, L.; Casill, A.D.; Park, J.W.; Gamble, M.J. MacroH2A1.1 and PARP-1 cooperate to regulate transcription by promoting CBP-mediated H2B acetylation. Nat. Struct. Mol. Biol. 2014 , 21 , 981–989. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Sanchez, A.; Buck-Koehntop, B.A.; Miller, K.M. Joining the party: PARP regulation of during DNA repair (and transcription?). Bioessays 2022 , 44 , e2200015. [ Google Scholar ] [ CrossRef ]
- Kim, J.; Shin, Y.; Lee, S.; Kim, M.; Punj, V.; Lu, J.F.; Shin, H.; Kim, K.; Ulmer, T.S.; Koh, J.; et al. Regulation of breast cancer-induced osteoclastogenesis by macroH2A1.2 involving EZH2-mediated H3K27me3. Cell Rep. 2018 , 24 , 224–237. [ Google Scholar ] [ CrossRef ]
- Kumbhar, R.; Sanchez, A.; Perren, J.; Gong, F.; Corujo, D.; Medina, F.; Devanathan, S.K.; Xhemalce, B.; Matouschek, A.; Buschbeck, M.; et al. Poly(ADP-ribose) binding and macroH2A mediate recruitment and functions of KDM5A at DNA lesions. J. Cell Biol. 2021 , 220 , e202006149. [ Google Scholar ] [ CrossRef ]
- Na, Y.J.; Kim, B.R.; Kim, J.L.; Kang, S.; Jeong, Y.A.; Park, S.H.; Jo, M.J.; Kim, J.Y.; Kim, H.J.; Oh, S.C.; et al. Deficiency of 15-LOX-1 induces radioresistance through downregulation of macroH2A2 in colorectal cancer. Cancers 2019 , 11 , 1776. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Karras, G.I.; Kustatscher, G.; Buhecha, H.R.; Allen, M.D.; Pugieux, C.; Sait, F.; Bycroft, M.; Ladurner, A.G. The macro domain is an ADP-ribose binding module. EMBO J. 2005 , 24 , 1911–1920. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Corujo, D.; Buschbeck, M. Post-translational modifications of H2A histone variants and their role in cancer. Cancers 2018 , 10 , 59. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Monteiro, F.L.; Baptista, T.; Amado, F.; Vitorino, R.; Jerónimo, C.; Helguero, L.A. Expression and functionality of histone H2A variants in cancer. Oncotarget 2014 , 5 , 3428–3443. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Dijkwel, Y.; Tremethick, D.J. The role of the histone variant H2A.Z in metazoan development. J. Dev. Biol. 2022 , 10 , 28. [ Google Scholar ] [ CrossRef ]
- Li, Z.; Gadue, P.; Chen, K.; Jiao, Y.; Tuteja, G.; Schug, J.; Li, W.; Kaestner, K.H. FOXA2 and H2A.Z mediate nucleosome depletion during embryonic stem cell differentiation. Cell 2012 , 151 , 1608–1616. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Shen, T.; Ji, F.; Wang, Y.; Lei, X.; Zhang, D.; Jiao, J. Brain-specific deletion of histone variant H2A.Z results in cortical neurogenesis defects and neurodevelopmental disorder. Nucleic Acids Res. 2018 , 46 , 2290–2307. [ Google Scholar ] [ CrossRef ]
- Rao, V.K.; Swarnaseetha, A.; Tham, G.H.; Lin, W.Q.; Han, B.B.; Benoukraf, T.; Xu, G.L.; Ong, C.T. Phosphorylation of TET3 by CDK5 is critical for robust activation of BRN2 during neuronal differentiation. Nucleic Acids Res. 2020 , 48 , 1225–1238. [ Google Scholar ] [ CrossRef ]
- Karthik, N.; Taneja, R. Histone variants in skeletal myogenesis. Epigenetics 2021 , 16 , 243–262. [ Google Scholar ] [ CrossRef ]
- Saul, D.; Kosinsky, R.L. Epigenetics of aging and aging-associated diseases. Int. J. Mol. Sci. 2021 , 22 , 401. [ Google Scholar ] [ CrossRef ]
- Stefanelli, G.; Azam, A.B.; Walters, B.J.; Brimble, M.A.; Gettens, C.P.; Bouchard-Cannon, P.; Cheng, H.M.; Davidoff, A.M.; Narkaj, K.; Day, J.J.; et al. Learning and age-related changes in genome-wide H2A.Z binding in the mouse hippocampus. Cell Rep. 2018 , 22 , 1124–1131. [ Google Scholar ] [ CrossRef ]
- Pazienza, V.; Borghesan, M.; Mazza, T.; Sheedfar, F.; Panebianco, C.; Williams, R.; Mazzoccoli, G.; Andriulli, A.; Nakanishi, T.; Vinciguerra, M. Sirt1-metabolite binding histone macroH2A1.1 protects hepatocytes against lipid accumulation. Aging 2014 , 6 , 35–47. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Wan, D.; Liu, C.; Sun, Y.; Wang, W.; Huang, K.; Zheng, L. MacroH2A1.1 cooperates with EZH2 to promote adipogenesis by regulating WNT signaling. J. Mol. Cell Biol. 2017 , 9 , 325–337. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Pazienza, V.; Panebianco, C.; Rappa, F.; Memoli, D.; Borghesan, M.; Cannito, S.; Oji, A.; Mazza, G.; Tamburrino, D.; Fusai, G.; et al. Histone macroH2A1.2 promotes metabolic health and leanness by inhibiting adipogenesis. Epigenet. Chromatin 2016 , 9 , 45. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Shi, Y.; Fan, W.; Xu, M.; Lin, X.; Zhao, W.; Yang, Z. Critical role of Znhit1 for postnatal heart function and vacuolar cardiomyopathy. JCI Insight 2022 , 7 , e148752. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Eleftheriadou, O.; Boguslavskyi, A.; Longman, M.R.; Cowan, J.; Francois, A.; Heads, R.J.; Wadzinski, B.E.; Ryan, A.; Shattock, M.J.; Snabaitis, A.K. Expression and regulation of type 2a protein phosphatases and alpha4 signalling in cardiac health and hypertrophy. Basic Res. Cardiol. 2017 , 112 , 37. [ Google Scholar ] [ CrossRef ]
- Yoon, S.R.; Song, J.; Lee, J.H.; Kim, O.Y. Phosphorylation of histone H2A.X in peripheral blood mononuclear cells may be a useful marker for monitoring cardiometabolic risk in nondiabetic individuals. Dis. Markers 2017 , 2017 , 1–9. [ Google Scholar ] [ CrossRef ]
- Bray, F.; Laversanne, M.; Sung, H.; Ferlay, J.; Siegel, R.L.; Soerjomataram, I.; Jemal, A. Global cancer statistics 2022: Global estimates of incidence and mortality worldwide for 36 cancers in 185 countries. CA-Cancer J. Clin. 2024 , 74 , 229–263. [ Google Scholar ] [ CrossRef ]
- Balon, K.; Sheriff, A.; Jacków, J.; Baczmański, A. Targeting cancer with CRISPR/cas9-based therapy. Int. J. Mol. Sci. 2022 , 23 , 573. [ Google Scholar ] [ CrossRef ]
- Yuan, Y.; Cao, W.; Zhou, H.; Qian, H.; Wang, H. H2A.Z acetylation by lincznf337-as1 via kat5 implicated in the transcriptional misregulation in cancer signaling pathway in hepatocellular carcinoma. Cell Death Dis. 2021 , 12 , 609. [ Google Scholar ] [ CrossRef ]
- Li, X.; Zhu, R.; Yuan, Y.; Cai, Z.; Liang, S.; Bian, J.; Xu, G. Double-stranded RNA-specific adenosine deaminase-knockdown inhibits the proliferation and induces apoptosis of DU145 and PC3 cells by promoting the phosphorylation of H2A.X variant histone. Oncol. Lett. 2021 , 22 , 764. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Jiang, X.; Wen, J.; Paver, E.; Wu, Y.H.; Sun, G.; Bullman, A.; Dahlstrom, J.E.; Tremethick, D.J.; Soboleva, T.A. H2A.B is cancer/testis factor involved in the activation of ribosome biogenesis in Hodgkin lymphoma. EMBO Rep. 2021 , 22 , e52462. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Chew, G.L.; Bleakley, M.; Bradley, R.K.; Malik, H.S.; Henikoff, S.; Molaro, A.; Sarthy, J. Short H2A histone variants are expressed in cancer. Nat. Commun. 2021 , 12 , 490. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Lone, I.N.; Sengez, B.; Hamiche, A.; Dimitrov, S.; Alotaibi, H. The role of histone variants in the epithelial-to-mesenchymal transition. Cells 2020 , 9 , 2499. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Babaei, G.; Aziz, S.G.; Jaghi, N. Emt, cancer stem cells and autophagy; The three main axes of metastasis. Biomed. Pharmacother. 2021 , 133 , 110909. [ Google Scholar ] [ CrossRef ]
- Saitoh, M. Involvement of partial EMT in cancer progression. J. Biochem. 2018 , 164 , 257–264. [ Google Scholar ] [ CrossRef ]
- Zheng, Y.; Han, X.; Wang, T. Role of H2A.Z.1 in epithelial-mesenchymal transition and radiation resistance of lung adenocarcinoma in vitro. Biochem. Biophys. Res. Commun. 2022 , 611 , 118–125. [ Google Scholar ] [ CrossRef ]
- Berta, D.G.; Kuisma, H.; Välimäki, N.; Räisänen, M.; Jäntti, M.; Pasanen, A.; Karhu, A.; Kaukomaa, J.; Taira, A.; Cajuso, T.; et al. Deficient H2A.Z deposition is associated with genesis of uterine leiomyoma. Nature 2021 , 596 , 398–403. [ Google Scholar ] [ CrossRef ]
- Vardabasso, C.; Gaspar-Maia, A.; Hasson, D.; Pünzeler, S.; Valle-Garcia, D.; Straub, T.; Keilhauer, E.C.; Strub, T.; Dong, J.; Panda, T.; et al. Histone variant H2A.Z.2 mediates proliferation and drug sensitivity of malignant melanoma. Mol. Cell 2015 , 59 , 75–88. [ Google Scholar ] [ CrossRef ]
- Kim, K.; Punj, V.; Choi, J.; Heo, K.; Kim, J.M.; Laird, P.W.; An, W. Gene dysregulation by histone variant H2A.Z in bladder cancer. Epigenetics Chromatin 2013 , 6 , 34. [ Google Scholar ] [ CrossRef ]
- Tang, S.; Huang, X.; Wang, X.; Zhou, X.; Huang, H.; Qin, L.; Tao, H.; Wang, Q.; Tao, Y. Vital and distinct roles of H2A.Z isoforms in hepatocellular carcinoma. OncoTargets Ther. 2020 , 13 , 4319–4337. [ Google Scholar ] [ CrossRef ]
- Dong, M.; Chen, J.; Deng, Y.; Zhang, D.; Dong, L.; Sun, D. H2AFZ is a prognostic biomarker correlated to TP53 mutation and immune infiltration in hepatocellular carcinoma. Front. Oncol. 2021 , 11 , 701736. [ Google Scholar ] [ CrossRef ]
- Weyemi, U.; Redon, C.E.; Choudhuri, R.; Aziz, T.; Maeda, D.; Boufraqech, M.; Parekh, P.R.; Sethi, T.K.; Kasoji, M.; Abrams, N.; et al. The histone variant H2A.X is a regulator of the epithelial–mesenchymal transition. Nat. Commun. 2016 , 7 , 10711. [ Google Scholar ] [ CrossRef ]
- Ge, Y.; Liu, B.; Cui, J.; Li, S. Livin regulates H2A.X y142 phosphorylation and promotes autophagy in colon cancer cells via a novel kinase activity. Front. Oncol. 2019 , 9 , 1233. [ Google Scholar ] [ CrossRef ]
- Weyemi, U.; Redon, C.E.; Sethi, T.K.; Burrell, A.S.; Jailwala, P.; Kasoji, M.; Abrams, N.; Merchant, A.; Bonner, W.M. Twist1 and slug mediate H2AX-regulated epithelial-mesenchymal transition in breast cells. Cell Cycle 2016 , 15 , 2398–2404. [ Google Scholar ] [ CrossRef ]
- Guo, Z.F.; Kong, F.L. Akt regulates rsk2 to alter phosphorylation level of H2A.X in breast cancer. Oncol. Lett. 2021 , 21 , 187. [ Google Scholar ] [ CrossRef ]
- Ribeiro, I.P.; Caramelo, F.; Esteves, L.; Menoita, J.; Marques, F.; Barroso, L.; Miguéis, J.; Melo, J.B.; Carreira, I.M. Genomic predictive model for recurrence and metastasis development in head and neck squamous cell carcinoma patients. Sci. Rep. 2017 , 7 , 13897. [ Google Scholar ] [ CrossRef ]
- Knittel, G.; Liedgens, P.; Reinhardt, H.C. Targeting ATM-deficient CLL through interference with DNA repair pathways. Front. Genet. 2015 , 6 , 207. [ Google Scholar ] [ CrossRef ]
- Lord, C.J.; Ashworth, A. The DNA damage response and cancer therapy. Nature 2012 , 481 , 287–294. [ Google Scholar ] [ CrossRef ]
- Yin, H.; Jiang, Z.; Wang, S.; Zhang, P. Actinomycin D-activated RNase l promotes H2A.X/H2B-mediated DNA damage and apoptosis in lung cancer cells. Front. Oncol. 2019 , 9 , 1086. [ Google Scholar ] [ CrossRef ]
- Miyake, K.; Takano, N.; Kazama, H.; Kikuchi, H.; Hiramoto, M.; Tsukahara, K.; Miyazawa, K. Ricolinostat enhances adavosertib-induced mitotic catastrophe in TP53-mutated head and neck squamous cell carcinoma cells. Int. J. Oncol. 2022 , 60 , 54. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Zhao, L.; Chang, D.W.; Gong, Y.; Eng, C.; Wu, X. Measurement of DNA damage in peripheral blood by the γ-H2Ax assay as predictor of colorectal cancer risk. DNA Repair. 2017 , 53 , 24–30. [ Google Scholar ] [ CrossRef ]
- Fernández, M.I.; Gong, Y.; Ye, Y.; Lin, J.; Chang, D.W.; Kamat, A.M.; Wu, X. gamma-H2AX level in peripheral blood lymphocytes as a risk predictor for bladder cancer. Carcinogenesis 2013 , 34 , 2543–2547. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Kapoor, A.; Goldberg, M.S.; Cumberland, L.K.; Ratnakumar, K.; Segura, M.F.; Emanuel, P.O.; Menendez, S.; Vardabasso, C.; Leroy, G.; Vidal, C.I.; et al. The histone variant macroH2A suppresses melanoma progression through regulation of cdk8. Nature 2010 , 468 , 1105–1109. [ Google Scholar ] [ CrossRef ]
- Hu, W.; Miyai, K.; Sporn, J.C.; Luo, L.; Wang, J.Y.J.; Cosman, B.; Ramamoorthy, S. Loss of histone variant macroH2A2 expression associates with progression of anal neoplasm. J. Clin. Pathol. 2016 , 69 , 627–631. [ Google Scholar ] [ CrossRef ]
- Nikolic, A.; Maule, F.; Bobyn, A.; Ellestad, K.; Paik, S.; Marhon, S.A.; Mehdipour, P.; Lun, X.; Chen, H.M.; Mallard, C.; et al. MacroH2A2 antagonizes epigenetic programs of stemness in glioblastoma. Nat. Commun. 2023 , 14 , 3062. [ Google Scholar ] [ CrossRef ]
- Sun, D.; Singh, D.K.; Carcamo, S.; Filipescu, D.; Khalil, B.; Huang, X.; Miles, B.A.; Westra, W.; Sproll, K.C.; Hasson, D.; et al. MacroH2A impedes metastatic growth by enforcing a discrete dormancy program in disseminated cancer cells. Sci. Adv. 2022 , 8 , o876. [ Google Scholar ] [ CrossRef ]
- Dardenne, E.; Pierredon, S.; Driouch, K.; Gratadou, L.; Lacroix-Triki, M.; Espinoza, M.P.; Zonta, E.; Germann, S.; Mortada, H.; Villemin, J.P.; et al. Splicing switch of an epigenetic regulator by RNA helicases promotes tumor-cell invasiveness. Nat. Struct. Mol. Biol. 2012 , 19 , 1139–1146. [ Google Scholar ] [ CrossRef ]
- Sporn, J.C.; Jung, B. Differential regulation and predictive potential of macroH2A1 isoforms in colon cancer. Am. J. Pathol. 2012 , 180 , 2516–2526. [ Google Scholar ] [ CrossRef ]
- Hodge, D.Q.; Cui, J.; Gamble, M.J.; Guo, W. Histone variant macroH2A1 plays an isoform-specific role in suppressing epithelial-mesenchymal transition. Sci. Rep. 2018 , 8 , 841. [ Google Scholar ] [ CrossRef ]
- Kim, J.; Shin, Y.; Lee, S.; Kim, M.Y.; Punj, V.; Shin, H.; Kim, K.; Koh, J.; Jeong, D.; An, W. MacroH2A1.2 inhibits prostate cancer-induced osteoclastogenesis through cooperation with hp1α and h1.2. Oncogene 2018 , 37 , 5749–5765. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Giallongo, C.; Dulcamare, I.; Giallongo, S.; Duminuco, A.; Pieragostino, D.; Cufaro, M.C.; Amorini, A.M.; Lazzarino, G.; Romano, A.; Parrinello, N.; et al. MacroH2A1.1 as a crossroad between epigenetics, inflammation and metabolism of mesenchymal stromal cells in myelodysplastic syndromes. Cell Death Dis. 2023 , 14 , 686. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Novikov, L.; Park, J.W.; Chen, H.; Klerman, H.; Jalloh, A.S.; Gamble, M.J. QKI-mediated alternative splicing of the histone variant macroH2A1 regulates cancer cell proliferation. Mol. Cell. Biol. 2011 , 31 , 4244–4255. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Vieira-Silva, T.S.; Monteiro-Reis, S.; Barros-Silva, D.; Ramalho-Carvalho, J.; Graça, I.; Carneiro, I.; Martins, A.T.; Oliveira, J.; Antunes, L.; Hurtado-Bagès, S.; et al. Histone variant macroH2A1 is downregulated in prostate cancer and influences malignant cell phenotype. Cancer Cell Int. 2019 , 19 , 112. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Bereshchenko, O.; Lo Re, O.; Nikulenkov, F.; Flamini, S.; Kotaskova, J.; Mazza, T.; Le Pannérer, M.; Buschbeck, M.; Giallongo, C.; Palumbo, G.; et al. Deficiency and haploinsufficiency of histone macroH2A1.1 in mice recapitulate hematopoietic defects of human myelodysplastic syndrome. Clin. Epigenetics 2019 , 11 , 121. [ Google Scholar ] [ CrossRef ]
- Kang, L.; Cao, G.; Jing, W.; Liu, J.; Liu, M. Global, regional, and national incidence and mortality of congenital birth defects from 1990 to 2019. Eur. J. Pediatr. 2023 , 182 , 1781–1792. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Banaszynski, L.A.; Allis, C.D.; Lewis, P.W. Histone variants in metazoan development. Dev. Cell 2010 , 19 , 662–674. [ Google Scholar ] [ CrossRef ]
- Faast, R.; Thonglairoam, V.; Schulz, T.C.; Beall, J.; Wells, J.R.; Taylor, H.; Matthaei, K.; Rathjen, P.D.; Tremethick, D.J.; Lyons, I. Histone variant H2A.Z is required for early mammalian development. Curr. Biol. 2001 , 11 , 1183–1187. [ Google Scholar ] [ CrossRef ]
- Celeste, A.; Petersen, S.; Romanienko, P.J.; Fernandez-Capetillo, O.; Chen, H.T.; Sedelnikova, O.A.; Reina-San-Martin, B.; Coppola, V.; Meffre, E.; Difilippantonio, M.J.; et al. Genomic instability in mice lacking histone H2AX. Science 2002 , 296 , 922–927. [ Google Scholar ] [ CrossRef ]
- Pehrson, J.R.; Changolkar, L.N.; Costanzi, C.; Leu, N.A. Mice without macroH2A histone variants. Mol. Cell. Biol. 2014 , 34 , 4523–4533. [ Google Scholar ] [ CrossRef ]
- Law, C.; Cheung, P. Expression of non-acetylatable H2A.Z in myoblast cells blocks myoblast differentiation through disruption of myod expression. J. Biol. Chem. 2015 , 290 , 13234–13249. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Raja, D.A.; Subramaniam, Y.; Aggarwal, A.; Gotherwal, V.; Babu, A.; Tanwar, J.; Motiani, R.K.; Sivasubbu, S.; Gokhale, R.S.; Natarajan, V.T. Histone variant dictates fate biasing of neural crest cells to melanocyte lineage. Development 2020 , 147 , dev182576. [ Google Scholar ] [ CrossRef ]
- Zhao, B.; Chen, Y.; Jiang, N.; Yang, L.; Sun, S.; Zhang, Y.; Wen, Z.; Ray, L.; Liu, H.; Hou, G.; et al. Znhit1 controls intestinal stem cell maintenance by regulating H2A.Z incorporation. Nat. Commun. 2019 , 10 , 1071. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Hu, G.; Cui, K.; Northrup, D.; Liu, C.; Wang, C.; Tang, Q.; Ge, K.; Levens, D.; Crane-Robinson, C.; Zhao, K. H2A.Z facilitates access of active and repressive complexes to chromatin in embryonic stem cell self-renewal and differentiation. Cell Stem Cell 2013 , 12 , 180–192. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Jukam, D.; Shariati, S.; Skotheim, J.M. Zygotic genome activation in vertebrates. Dev. Cell 2017 , 42 , 316–332. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Deng, M.; Chen, B.; Liu, Z.; Cai, Y.; Wan, Y.; Zhou, J.; Wang, F. Exchanges of histone methylation and variants during mouse zygotic genome activation. Zygote 2020 , 28 , 51–58. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Ibarra-Morales, D.; Rauer, M.; Quarato, P.; Rabbani, L.; Zenk, F.; Schulte-Sasse, M.; Cardamone, F.; Gomez-Auli, A.; Cecere, G.; Iovino, N. Histone variant H2A.Z regulates zygotic genome activation. Nat. Commun. 2021 , 12 , 7002. [ Google Scholar ] [ CrossRef ]
- Yamada, S.; Kugou, K.; Ding, D.Q.; Fujita, Y.; Hiraoka, Y.; Murakami, H.; Ohta, K.; Yamada, T. The conserved histone variant H2A.Z illuminates meiotic recombination initiation. Curr. Genet. 2018 , 64 , 1015–1019. [ Google Scholar ] [ CrossRef ]
- Zhuo, M.L.P.W. Anp32e, a higher eukaryotic histone chaperone directs preferential recognition for H2A.Z. Cell Res. 2014 , 24 , 389–399. [ Google Scholar ]
- Pei, D.; Shu, X.; Gassama-Diagne, A.; Thiery, J.P. Mesenchymal-epithelial transition in development and reprogramming. Nat. Cell Biol. 2019 , 21 , 44–53. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Kafer, G.R.; Lehnert, S.A.; Pantaleon, M.; Kaye, P.L.; Moser, R.J. Expression of genes coding for histone variants and histone-associated proteins in pluripotent stem cells and mouse preimplantation embryos. Gene Expr. Patterns 2010 , 10 , 299–305. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Zha, S.; Sekiguchi, J.; Brush, J.W.; Bassing, C.H.; Alt, F.W. Complementary functions of atm and H2AX in development and suppression of genomic instability. Proc. Natl. Acad. Sci. USA 2008 , 105 , 9302–9306. [ Google Scholar ] [ CrossRef ]
- Turinetto, V.; Orlando, L.; Sanchez-Ripoll, Y.; Kumpfmueller, B.; Storm, M.P.; Porcedda, P.; Minieri, V.; Saviozzi, S.; Accomasso, L.; Cibrario, R.E.; et al. High basal γH2AX levels sustain self-renewal of mouse embryonic and induced pluripotent stem cells. Stem Cells 2012 , 30 , 1414–1423. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Eleuteri, B.; Aranda, S.; ERNFors, P. NORC recruitment by H2A.X deposition at rRNA gene promoter limits embryonic stem cell proliferation. Cell Rep. 2018 , 23 , 1853–1866. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Wu, T.; Liu, Y.; Wen, D.; Tseng, Z.; Tahmasian, M.; Zhong, M.; RafII, S.; Stadtfeld, M.; Hochedlinger, K.; Xiao, A. Histone variant H2A.X deposition pattern serves as a functional epigenetic mark for distinguishing the developmental potentials of iPSCs. Cell Stem Cell 2014 , 15 , 281–294. [ Google Scholar ] [ CrossRef ]
- Creppe, C.; Janich, P.; Cantariño, N.; Noguera, M.; Valero, V.; Musulén, E.; Douet, J.; Posavec, M.; Martín-Caballero, J.; Sumoy, L.; et al. MacroH2A1 regulates the balance between self-renewal and differentiation commitment in embryonic and adult stem cells. Mol. Cell. Biol. 2012 , 32 , 1442–1452. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Pasque, V.; Radzisheuskaya, A.; Gillich, A.; Halley-Stott, R.P.; Panamarova, M.; Zernicka-Goetz, M.; Surani, M.A.; Silva, J.C. Histone variant macroH2A marks embryonic differentiation in vivo and acts as an epigenetic barrier to induced pluripotency. J. Cell Sci. 2012 , 125 , 6094–6104. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Barrero, M.J.; Sese, B.; Martí, M.; Izpisua, B.J. Macro histone variants are critical for the differentiation of human pluripotent cells. J. Biol. Chem. 2013 , 288 , 16110–16116. [ Google Scholar ] [ CrossRef ]
- Gonzalez-Munoz, E.; Arboleda-Estudillo, Y.; Chanumolu, S.K.; Otu, H.H.; Cibelli, J.B. Zebrafish macroH2A variants have distinct embryo localization and function. Sci. Rep. 2019 , 9 , 8632. [ Google Scholar ] [ CrossRef ]
- Costanzi, C.; Stein, P.; Worrad, D.M.; Schultz, R.M.; Pehrson, J.R. Histone macroH2A1 is concentrated in the inactive X chromosome of female preimplantation mouse embryos. Development 2000 , 127 , 2283–2289. [ Google Scholar ] [ CrossRef ]
- Chen, Y.; Chen, Q.; Mceachin, R.C.; Cavalcoli, J.D.; Yu, X. H2A.B facilitates transcription elongation at methylated CPG loci. Genome Res. 2014 , 24 , 570–579. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Molaro, A.; Wood, A.J.; Janssens, D.; Kindelay, S.M.; Eickbush, M.T.; Wu, S.; Singh, P.; Muller, C.H.; Henikoff, S.; Malik, H.S. Biparental contributions of the H2A.B histone variant control embryonic development in mice. PLoS. Biol. 2020 , 18 , e3001001. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Steinmetz, J.D.; Seeher, K.M.; Schiess, N.; Nichols, E.; Cao, B.; Servili, C.; Cavallera, V.; Cousin, E.; Hagins, H.; Moberg, M.E.; et al. Global, regional, and national burden of disorders affecting the nervous system, 1990–2021: A systematic analysis for the global burden of disease study 2021. Lancet Neurol. 2024 , 23 , 344–381. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Zovkic, I.B.; Paulukaitis, B.S.; Day, J.J.; Etikala, D.M.; Sweatt, J.D. Histone H2A.Z subunit exchange controls consolidation of recent and remote memory. Nature 2014 , 515 , 582–586. [ Google Scholar ] [ CrossRef ]
- Stefanelli, G.; Makowski, C.E.; Brimble, M.A.; Hall, M.; Reda, A.; Creighton, S.D.; Leonetti, A.M.; Mclean, T.; Zakaria, J.M.; Baumbach, J.; et al. The histone chaperone Anp32e regulates memory formation, transcription, and dendritic morphology by regulating steady-state H2A.Z binding in neurons. Cell Rep. 2021 , 36 , 109551. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Farrelly, L.A.; Zheng, S.; Schrode, N.; Topol, A.; Bhanu, N.V.; Bastle, R.M.; Ramakrishnan, A.; Chan, J.C.; Cetin, B.; Flaherty, E.; et al. Chromatin profiling in human neurons reveals aberrant roles for histone acetylation and bet family proteins in schizophrenia. Nat. Commun. 2022 , 13 , 2195. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Weyemi, U.; Paul, B.D.; Bhattacharya, D.; Malla, A.P.; Boufraqech, M.; Harraz, M.M.; Bonner, W.M.; Snyder, S.H. Histone H2AX promotes neuronal health by controlling mitochondrial homeostasis. Proc. Natl. Acad. Sci. USA 2019 , 116 , 7471–7476. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Weyemi, U.; Paul, B.D.; Snowman, A.M.; Jailwala, P.; Nussenzweig, A.; Bonner, W.M.; Snyder, S.H. Histone H2AX deficiency causes neurobehavioral deficits and impaired redox homeostasis. Nat. Commun. 2018 , 9 , 1526. [ Google Scholar ] [ CrossRef ]
- Ma, H.; Su, L.; Xia, W.; Wang, W.; Tan, G.; Jiao, J. MacroH2A1.2 deficiency leads to neural stem cell differentiation defects and autism-like behaviors. EMBO Rep. 2021 , 22 , e52150. [ Google Scholar ] [ CrossRef ]
- Berger, N.A.; Besson, V.C.; Boulares, A.H.; Bürkle, A.; Chiarugi, A.; Clark, R.S.; Curtin, N.J.; Cuzzocrea, S.; Dawson, T.M.; Dawson, V.L.; et al. Opportunities for the repurposing of PARP inhibitors for the therapy of non-oncological diseases. Br. J. Pharmacol. 2018 , 175 , 192–222. [ Google Scholar ] [ CrossRef ]
- Jiang, G.; Zhang, G.; An, T.; He, Z.; Kang, L.; Yang, X.; Gu, Y.; Zhang, D.; Wang, Y.; Gao, S. Effect of type I diabetes on the proteome of mouse oocytes. Cell Physiol. Biochem. 2016 , 39 , 2320–2330. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Ishibashi, T.; Dryhurst, D.; Rose, K.L.; Shabanowitz, J.; Hunt, D.F.; Ausió, J. Acetylation of vertebrate H2A.Z and its effect on the structure of the nucleosome. Biochemistry 2009 , 48 , 5007–5017. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Millar, C.B.; Xu, F.; Zhang, K.; Grunstein, M. Acetylation of H2AZ lys 14 is associated with genome-wide gene activity in yeast . Genes. Dev. 2006 , 20 , 711–722. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Perche, P.Y.; Vourc’H, C.; Konecny, L.; Souchier, C.; Robert-Nicoud, M.; Dimitrov, S.; Khochbin, S. Higher concentrations of histone macroH2A in the Barr body are correlated with higher nucleosome density. Curr. Biol. 2000 , 10 , 1531–1534. [ Google Scholar ] [ CrossRef ] [ PubMed ]
Click here to enlarge figure
| The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
Share and Cite
Yin, X.; Zeng, D.; Liao, Y.; Tang, C.; Li, Y. The Function of H2A Histone Variants and Their Roles in Diseases. Biomolecules 2024 , 14 , 993. https://doi.org/10.3390/biom14080993
Yin X, Zeng D, Liao Y, Tang C, Li Y. The Function of H2A Histone Variants and Their Roles in Diseases. Biomolecules . 2024; 14(8):993. https://doi.org/10.3390/biom14080993
Yin, Xuemin, Dong Zeng, Yingjun Liao, Chengyuan Tang, and Ying Li. 2024. "The Function of H2A Histone Variants and Their Roles in Diseases" Biomolecules 14, no. 8: 993. https://doi.org/10.3390/biom14080993
Article Metrics
Article access statistics, further information, mdpi initiatives, follow mdpi.
Subscribe to receive issue release notifications and newsletters from MDPI journals
COMMENTS
ADVERTISEMENTS: In this essay we will discuss about:- 1. Definition of DNA Replication 2. Mechanism of DNA Replication 3. Evidences for Semi-Conservative DNA Replication 4. Models for Replication of Prokaryotic DNA. Essay # Definition of DNA Replication: DNA replicates by "unzipping" along the two strands, breaking the hydrogen bonds which link the pairs of nucleotides. […]
Dispersive replication. In the dispersive model, DNA replication results in two DNA molecules that are mixtures, or "hybrids," of parental and daughter DNA. In this model, each individual strand is a patchwork of original and new DNA. Most biologists at the time would likely have put their money on the semi-conservative model.
The basic idea. DNA replication is semiconservative, meaning that each strand in the DNA double helix acts as a template for the synthesis of a new, complementary strand. This process takes us from one starting molecule to two "daughter" molecules, with each newly formed double helix containing one new and one old strand.
Conclusion. DNA replication is a highly regulated molecular process where a single molecule of DNA is duplicated to result in two identical DNA molecules. As a semiconservative process, the double helix is broken down into two strands, where each strand serves as the template for the newly synthesized strand by matching complementary bases. ...
DNA replication has been extremely well-studied in prokaryotes, primarily because of the small size of the genome and large number of variants available. Escherichia coli has 4.6 million base pairs in a single circular chromosome, and all of it gets replicated in approximately 42 minutes, starting from a single origin of replication and ...
which replication generates a double helix in which both strands are newly synthesized. Ergo, DNA replication is semi-conservative. DNA is synthesized by the repetitive addition of nucleotides to the 3' end of the growing polynucleotide chain DNA is synthesized by an iterative process in which nucleotides are added
The replication complex is the group of proteins that help synthesize the new DNA strands. A replication unit is any chunk of DNA that is capable of being replicated — e.g. a plasmid with an origin of replication (ORI) is a replication unit. Alternatively, this can also mean a region of DNA that is replicated together.
The described outcomes of the experiment also lead to a vast range of conclusions concerning the nature and outcomes of DNA replications in different species. By defining DNA replication as semiconservative, the researchers made it evident that every double helix axis in the DNA structure built with the help of DNA polymerases leads to the ...
The number of DNA polymerases in eukaryotes is much more than prokaryotes: 14 are known, of which five are known to have major roles during replication and have been well studied. They are known as pol α, pol β, pol γ, pol δ, and pol ε. The essential steps of replication are the same as in prokaryotes.
Formation of Replication Fork Step 2: Initiation. One strand runs from 5′ to 3′ direction towards the replication fork and is referred to as leading strand and the other strand runs from 3′ to 5′ away from the replication fork and is referred to as lagging strands.; To this exposed single-stranded DNA, SSB proteins are adhered to prevent recoiling of DNA and to stabilize it.
Essays Biochem. 2018 Jul 20; 62(3): 287-296. ... During DNA replication, the parental molecule remains intact, which poses a steric problem for the moving replication machinery. Topoisomerases belonging to the type 1 family can relieve torsional strain formed in this way, by allowing one of the strands to pass through the other. ...
The process of DNA replication plays a crucial role in providing genetic continuity from one generation to the next. Knowledge of the structure of DNA began with the discovery of nucleic acids in 1869. In 1952, an accurate model of the DNA molecule was presented, thanks to the work of Rosalind Franklin, James Watson, and Francis Crick.
Leading & lagging strands. DNA polymerase can only build the new strand in one direction (5' to 3' direction); As DNA is 'unzipped' from the 3' towards the 5' end, DNA polymerase will attach to the 3' end of the original strand and move towards the replication fork (the point at which the DNA molecule is splitting into two template strands) ...
Working with Molecular Genetics Chapter 6, DNA Replication_2, Control analogy. Imagine that 20 students are writing essays using word processors set to use black letters. They are all at different stages of completing their papers, and they are not revising or editing their essays - just writing them from start to finish.
Dna Replication Essay. Satisfactory Essays. 443 Words. 2 Pages. Open Document. Since we discovered that DNA is in the nucleus in every single cell, we're curious about how exactly DNA can be replicated in a way that can keep our identity, including our characteristics. This could be described after learning about DNA and its very individual ...
Show More. The Replication of Deoxyribonucleic Acid (DNA) and Ribonucleic Acid (RNA) DNA replication is when a cell divides and every new cell has a copy of the original cell's genetic information. This allows it to synthesize the proteins to build cellular parts and metabolize. Replication of DNA happens during the interphase of a cell cycle.
A nucleic acid that carries the genetic information in the cell and is capable of self-replication and RNA synthesis is referred to as DNA. In other words, DNA refers to the molecules inside cells that carry genetic information and pass it from one generation to the next. The scientific name for DNA is deoxyribonucleic acid. Essay # 2. Features ...
Abstract. Nucleic acids, deoxyribonucleic acid (DNA) and ribonucleic acid (RNA), carry genetic information which is read in cells to make the RNA and proteins by which living things function. The well-known structure of the DNA double helix allows this information to be copied and passed on to the next generation. In this article we summarise the structure and function of nucleic acids. The ...
Abstract. Mammalian mitochondria contain multiple copies of a circular, double-stranded DNA genome and a dedicated DNA replication machinery is required for its maintenance. Many disease-causing mutations affect mitochondrial replication factors and a detailed understanding of the replication process may help to explain the pathogenic ...
Dna Replication Essay. Since we discovered that DNA is in the nucleus in every single cell, we're curious about how exactly DNA can be replicated in a way that can keep our identity, including our characteristics. ... In conclusion, even through replication, we are still able to keep our characteristics due to the stationary and unchanging ...
Epigenetic regulation, which is characterized by reversible and heritable genetic alterations without changing DNA sequences, has recently been increasingly studied in diseases. Histone variant regulation is an essential component of epigenetic regulation. The substitution of canonical histones by histone variants profoundly alters the local chromatin structure and modulates DNA accessibility ...