

Top 22 JP Morgan Data Scientist Interview Questions + Guide in 2024
Back to Jpmorgan Chase & Co.
Introduction
JP Morgan Chase & Co. is a leading global financial services firm and one of the largest banking institutions in the US. As an organization, JP Morgan is becoming increasingly reliant on data-driven business decisions, and sophisticated data management capabilities for top clients. They require data scientists across their teams in functions such as Cybersecurity, Investment Banking, and Commercial Banking for risk analysis, fraud investigation, market research, and many more challenging functions.
If you are planning to interview for a Data Scientist position at JP Morgan, or are curious about the process, this interview guide is for you.
Read on to find out how you can boost your chances when you land that JP Morgan data scientist interview.
JP Morgan Data Scientist Interview Process
JP Morgan Chase’s interview process is rigorous, reflecting their commitment to hiring individuals who are not only technically adept but also aligned with the company’s values and long-term objectives. The process usually consists of four interview rounds but may differ based on the team and seniority of the position.
1. Application
You can apply for jobs through their website, recruiters, or trusted online platforms. You can consider asking for an employee referral as well when you apply. Make sure to quantify the success of key projects as well as your leadership skills, as these are qualities that they look for in promising candidates. JP Morgan advises that brevity is important during your application.
2. HireVue Interview
This round is often conducted over the HireVue platform. You will be asked to record a series of video responses and respond to coding challenges. The purpose of this round is to assess your candidature virtually to ensure you are a good fit for the in-person rounds later.
3 . In-person Interview(s)
If it’s a good fit, you will be invited onsite to meet your team and have a panel interview. These rounds typically involve a mix of technical, behavioral, and case study questions.
Interview tips from JP Morgan’s careers page: “Stay up to date on the news, both general and firm-specific, so you can speak from a place of knowledge and confidence. Be ready to share specific examples of your previous experience that reflect transferrable skills to the opportunity you are applying for. Prepare questions for our team, so you can learn more about the opportunity and our firm.”
Frequently Asked JP Morgan Data Scientist Interview Questions
You will be expected to be technically sound in SQL, Python, machine learning algorithms, and analytical solutions, and apply these technical skills to real-life scenarios the company faces, such as risk management, fraud detection, investment strategies, operational improvements, etc.
It is a good idea to stay updated about the company through its website and LinkedIn page, and follow firm-specific and data science-related news to stay abreast of the business problems you may encounter.
For a more in-depth discussion, look through our list below as we’ve hand-picked popular questions that have actually been asked in JP Morgan’s Data Science interview.
1. Describe a challenging data science project you handled. How did you manage the complexities, and what was the outcome?
You’ll face a lot of complex decision-making at JP Morgan, so you need to showcase your experience in handling such situations.
How to Answer
Focus on a project you feel comfortable discussing in depth. Detail your approach, strategies, and impact. Be authentic and make sure to demonstrate that you worked collaboratively with your team as well as stakeholders.
“In my previous firm, I led a project to optimize investment strategies using machine learning. The challenge was integrating disparate data sources while ensuring model accuracy. My approach involved collaborating with cross-functional teams to refine data integration and iteratively improving the model based on stakeholder feedback. The outcome was a 15% improvement in prediction accuracy, significantly aiding our decision-making.”
2. Why do you want to join JP Morgan?
Interviewers will want to know why you specifically chose the Data Scientist role at JP Morgan. They want to establish if you’re passionate about the company’s culture and values or if your interest is temporary.
Your answer should cover why you chose the company and role and why you’re a good match for both. Frame your response positively. Additionally, focus on how your selection would benefit both parties.
“J.P. Morgan promises the opportunity to work on complex financial challenges. This aligns with my passion for tackling intricate financial problems and my background in financial analysis and data-driven decision-making. My skills, coupled with my enthusiasm for innovation in finance, make me a good fit. The firm’s commitment to employee development and its inclusive culture also resonate with my professional values and aspirations.”
3. Tell us about a time when you had to explain complex data science concepts to non-technical stakeholders. How did you ensure they understood?
As you will be expected to participate in cross-functional teams and projects, the ability to communicate complex ideas effectively is non-negotiable.
Highlight your communication skills through a specific instance from a past project. Use the STAR method of storytelling - discuss the S pecific situation you were challenged with, the T ask you decided on, the A ction you took, and the R esult of your efforts.
“I was tasked with explaining the outcomes of a predictive model to our marketing team, in a past project. I used analogies related to their daily work to illustrate how the model functions and its relevance to their campaigns, avoiding any unnecessary technical jargon. I followed up with a Q&A session to address any doubts. This extra effort went a long way in promoting team dynamics and ensuring that the marketing team felt included in the technical conversations.”
4. How do you prioritize multiple deadlines?
You may need to work across teams, projects, and even geographies in a global organization like JP Morgan Chase. Time management and organization are essential skills to succeed.
Emphasize your ability to differentiate between urgent and important tasks. Mention any tools or frameworks you use for time management. It’s also important to showcase your ability to adjust priorities.
“In a previous role, I often juggled multiple projects with tight deadlines. I prioritized tasks based on their impact and deadlines using a combination of the Eisenhower Matrix and Agile methodologies. I regularly reassessed priorities to accommodate any changes and communicated proactively with stakeholders about progress and any potential delays.”
5. Can you provide an example of a time when you had to make a quick decision based on incomplete data?
Real-world data is seldom perfect, and there will be occasions when your team or manager asks for your input when a quick decision is paramount. The interviewer wants to test your domain knowledge and critical thinking skills.
Provide an example where you had to make a timely decision with partial data. It’s important to convey the rationale behind your decision. You should also demonstrate that you are willing to seek help from experts when needed - this shows that you are a team player.
“We faced a tight deadline in my old firm, to launch a marketing campaign with incomplete customer data. I looked at existing trends to extrapolate missing information and consulted with domain experts. Based on this, we made an informed decision to proceed with a targeted approach, which ultimately resulted in a successful campaign with higher-than-expected engagement rates.”
6. Given a list of tuples featuring names and grades on a test, write a function to normalize the values of the grades to a linear scale between 0 and 1.
You will need to demonstrate basic data manipulation problem skills in Python, as such operations are necessary for the day-to-day coding requirements for a Data Scientist in JPMC.
Briefly outline your approach, which should involve finding the minimum and maximum grades and then applying a formula to normalize each grade.
“My approach would be to extract the grades from the list of tuples, find the minimum and maximum grades, and then normalize each grade using the formula: (grade - min_grade) / (max_grade - min_grade).”
7. You have access to two tables: transactions , which includes fields like transaction_id , customer_id , amount , and transaction_date , and customers , which includes customer_id , age , and income . Write an SQL query to identify the top 10% of customers by transaction volume in the last quarter and provide insights into their age and income distribution.
In a JP Morgan Data Scientist interview, a question like this will evaluate your ability to extract meaningful insights from financial data using SQL window functions.
Explain your SQL logic systematically. Discuss your insights and how they would aid business strategies.
“I’d join the transactions table with the customers table on the customer_id column. Then, I’d filter the transactions to include those from the last quarter. Using a window function like RANK() or NTILE(), I’d identify the top 10% of customers based on transaction volume. Finally, I’d analyze the age and income distribution by looking for patterns that could inform targeted marketing or product development.”
8. You are given a deck of 500 cards numbered from 1 to 500. If the cards are shuffled randomly and you are asked to pick three, one at a time, what’s the probability of each subsequent card being larger than the previously drawn one?
Probability, permutations and combinations, and logical thinking are mathematical skills essential to analyzing financial data at JPMC.
Emphasize the importance of considering all possible combinations of three cards and then the favorable outcomes. Inform the interviewer what mathematical approach (Binomial distribution) you are going to follow.
“The total number of ways to draw three cards from 500 is $^{500}C_3$. Each specific set of three cards can only be arranged in one way to meet the condition (ascending order). So, the probability is the number of sets of three cards, which is $^{500}C_3$ divided by the total number of ways to draw three cards.”
9. Explain how an XGBoost model differs from a Random Forest model.
You need to know about advanced machine learning techniques to solve complex problems such as credit risk in JPMC.
How to Answer Focus on the key differences, and provide examples of potential applications in financial modeling.
“XGBoost is a gradient boosting algorithm that builds trees one at a time, where each new tree helps to correct errors made by previously trained trees. It uses gradient descent to minimize loss when adding new models. Random Forest, on the other hand, creates a ‘forest’ of decision trees trained on random subsets of data and averages their predictions. This parallel approach in Random Forest is different from the sequential tree-building in XGBoost. Also, XGBoost includes regularization, which helps in reducing overfitting.”
10. Write a function to calculate the total profit gained from investing in an index fund from the start to the end date.
You will be expected to know how to code functions related to investment scenarios on the fly, so do ensure to practice such problems in Python.
You need to calculate the total profit from transactions in an index fund, considering the discrete nature of share purchases and daily price changes. Mention the importance of accounting for the daily valuation of the fund and the timing of transactions.
“I’d first track the total number of shares owned, updating it based on daily deposits and withdrawals. I’d calculate the share purchases based on the available funds and daily index price. For each day, I’d adjust the value of the holdings based on the index’s daily price change. This approach mirrors real-world scenarios at J.P. Morgan.”
11. In analyzing financial transaction data at JPMC, how would you differentiate and handle outliers that are erroneous versus those that represent significant but valid market events?
Addressing how to handle outliers in transaction data demonstrates your analytical skills as well as domain expertise in financial data.
Emphasize the importance of understanding the context of the data. Differentiate between outliers by investigating their source: erroneous outliers often stem from data entry errors or technical glitches, while valid outliers could be due to significant market events like a merger or regulatory change. Stress the importance of using statistical methods to identify outliers, coupled with domain knowledge to interpret them.
“I would use statistical methods like z-scores or IQR to identify outliers. Then, I’d investigate each outlier’s context. For example, if an outlier coincides with a major market event, like a central bank announcement, it’s likely a valid data point reflecting market reaction. However, if the outlier deviates significantly from market trends without a corresponding event, it might be erroneous. In such cases, I would consult with market experts or cross-reference with other data sources.”
12. Let’s say that you are working on analyzing salary data. You are tasked by your manager with computing the average salary of a Data Scientist using a recency-weighted average. Write the function to compute the average Data Scientist salary given a mapped linear recency weighting on the data.
Recency-weighted averages are an important statistical method to analyze trends where market rates fluctuate significantly.
Explain the concept and its relevance in data analysis. In your function, outline how you would assign greater weight to more recent salaries.
“I would write a function that takes a list of salaries from the past ‘n’ years. The function will assign a linearly increasing weight to each year’s salary, with the most recent year having the highest weight. This approach ensures that recent trends in Data Scientist salaries have a more significant impact on the computed average, reflecting the current market conditions more accurately.”
13. How would you estimate the valuation of the JP Morgan Chase mobile app?
This is a relevant situational exercise in applying finance and business analysis principles.
Start with the app’s direct financial impact, like revenue generation through transactions or cost savings. Then, consider the app’s strategic value, like customer retention, data collection, and brand enhancement. Use industry benchmarks and comparable analyses if possible.
“I would first analyze its direct financial contributions, such as fees from mobile transactions or savings from reduced branch operations. Next, I’d assess the strategic value, like how the app improves customer engagement and retention, which can be quantified by looking at customer lifetime value. Additionally, I’d consider the value of data generated by the app for personalized marketing or risk assessment.”
14. Let’s say we’re comparing two machine learning algorithms. In which case would you use a bagging algorithm versus a boosting algorithm? Give an example of the tradeoffs between the two.
This tests your understanding of advanced machine learning techniques and their application in financial contexts, especially with complex datasets and in credit risk prediction.
Highlight the key differences and provide relevant examples where you would employ each method.
“Bagging, like in a Random Forest, is robust against overfitting and works well with complex datasets. However, it might not perform as well when the underlying model is overly simple. Boosting, exemplified by algorithms like XGBoost, often achieves higher accuracy but can be prone to overfitting, especially with noisy data. It’s also typically more computationally intensive.”
15. How would you address and rectify biases in a financial dataset?
Addressing biases in a financial dataset demonstrates your ability to ensure data integrity in relevant business scenarios.
Discuss the statistical techniques you would employ to detect anomalies and the need for thorough data cleaning. Mention the significance of using diverse datasets to train models and regularly updating them with new data to reduce bias over time.
“In a financial context, biases in datasets can lead to inaccurate models and unfair outcomes. To address this, I’d first conduct an exploratory data analysis to identify potential anomalies. For example, if we’re analyzing loan approval data, we need to ensure it doesn’t inherently favor certain demographic groups. I’d use techniques like stratified sampling to ensure representative data and employ algorithms that are less susceptible to biases.”
16. Let’s say you are tasked with building a decision tree model to predict if a borrower will pay back a personal loan. How would you evaluate whether using a decision tree is the correct model? Let’s say you move forward with the decision tree model. How would you evaluate the performance of the model before deployment and after?
Evaluating and implementing a decision tree model for loan repayment prediction is a typical case study that emulates strategic challenges that JP Morgan is trying to solve.
Explain that decision trees are great for their simplicity and interpretability, which is crucial in banking for regulatory compliance and explainability. However, they can be prone to overfitting. Assess whether the dataset has features well-suited for a decision tree and if the model’s simplicity aligns with the complexity of the problem.
“For evaluation, I’d focus on metrics like recall to minimize false negatives, as incorrectly predicting a default could be costly. Pre-deployment, I’d use a portion of the data to test the model, and post-deployment, I’d regularly compare the model’s predictions with actual loan outcomes, adjusting as necessary to ensure accuracy and fairness.”
17. What are the benefits of feature scaling in a logistic regression model?
This is asked to assess your understanding of data preprocessing and its impact on model accuracy and performance, crucial for data-driven financial decision-making.
Focus on how feature scaling aids in faster convergence during training, ensures uniformity in feature influence, and enhances the interpretability of model coefficients. Talk about the practical implications of these benefits.
“Feature scaling standardizes the range of independent variables, leading to faster convergence during optimization. For example, in a credit scoring model at JP Morgan, if income is in thousands and age is in years, without scaling, income would disproportionately influence the model. By scaling, we ensure each feature contributes proportionally.”
18. We are looking into creating a new partner card (think Starbucks-Chase credit card or Whole Foods-Chase credit card). You have access to all of our customer spending data. How would you determine what our next partner card should be?
This tests how you’d leverage analytics for strategic business decisions.
Discuss using customer spending data to identify trends and preferences. Elucidate the importance of clustering or segmentation techniques to understand customer behavior.
“I’d first analyze customer spending patterns by segmenting them based on spending categories, like groceries, dining, travel, etc. For example, if there’s a significant portion of customers with high spending in the hospitality sector, a hotel chain could be a suitable partner. Additionally, I’d look into the customer demographics and geographical data to ensure the chosen partner aligns with our customer base’s preferences and location.”
19. How would you explain Linear Regression to a non-technical person?
Data Scientists participate in cross-functional teams and projects at JP Morgan, so you need to have excellent communication skills as well as robust technical understanding.
Focus on explaining Linear Regression as a way to understand relationships between variables.
“Imagine you’re looking at the relationship between the amount of time you spend studying and your exam scores. Linear Regression is essentially drawing a straight line through a set of points on a graph where each point represents a different amount of study time and the corresponding exam score. This line helps us predict, for example, what score you might expect if you studied for a certain number of hours.”
20. JP Morgan has begun a new email campaign. You are given tables detailing users’ visits to the site and timestamps of when emails were sent to users. How would you measure the success of this campaign?
Answering this well demonstrates your ability to apply Data Science to marketing effectiveness.
Focus on establishing a clear connection between email sent times and user site visits. Highlight the importance of A/B testing and control groups to isolate the effect of the emails.
“I’d first link the timestamps of emails sent with users’ subsequent site visits. A significant increase in visits shortly after emails are sent, compared to typical visit rates, would indicate a positive impact. I’d also recommend an A/B test, where one group receives the emails and another similar group doesn’t. Comparing these groups’ behaviors provides a clearer picture of the campaign’s effectiveness.”
21. Write a function called find_bigrams that takes a sentence or paragraph of strings and returns a list of all its bigrams in order.
This question might be asked in a JP Morgan Data Scientist interview to assess a candidate’s ability to manipulate and process text data, which is essential for tasks like sentiment analysis, customer feedback analysis, and natural language processing in financial documents.
To parse them out of a string, we need to split the input string first. We would use the Python function .split() to create a list with each word as an input. Create another empty list that will eventually be filled with tuples.
Then, once we’ve identified each word, we need to loop through k-1 times (if k is the number of words in a sentence) and append the current word and subsequent word to make a tuple. This tuple gets added to a list that we eventually return.
“Bigrams are pairs of consecutive words in a string, which are useful in natural language processing. To find bigrams, I would start by splitting the string into words using Python’s .split() method and converting them to lowercase for consistency. Then, I would iterate through the list, forming bigrams by pairing each word with the next and storing these pairs as tuples in a list. Finally, I would return this list of bigrams. This approach demonstrates my understanding of both the concept and the practical implementation.”
22. You are given a string that represents some floating-point number. Write a function, digit_accumulator, that returns the sum of every digit in the string.
This question might be asked in a JP Morgan Data Scientist interview to evaluate your problem-solving skills, attention to detail, and programming proficiency. It tests your ability to handle numerical data within a string, which is important for data cleaning and preprocessing tasks.
Start by iterating through each character in the string. For each character, check if it is a digit. If it is, convert it to an integer and add it to a running total. This approach allows you to ignore non-digit characters such as the decimal point and accumulate the sum of all digits efficiently.
“To solve the problem of summing every digit in a string representing a floating-point number, I would iterate through each character in the string and check if it is a digit by seeing if it is in ‘0123456789’. If it is, I would convert it to an integer and add it to an accumulator variable. This method ensures that non-digit characters are ignored, and the final value of the accumulator will be the sum of all the digits in the string.”
How to Prepare for a Data Scientist Interview at JP Morgan
Here are some tips to help you excel in your interview:
Study the Company and Role
Understand the basics of banking, investment, risk management, and the financial products JP Morgan deals with. Follow current trends in the finance industry and how Data Science is applied.
You can also read Interview Query members’ experiences on our discussion board for insider tips and first-hand information. Visit JP Morgan’s page on their hiring process for detailed information.
Understand the Fundamentals
Brush up on core Data Science topics like statistics, Machine Learning algorithms, data preprocessing, and model evaluation. Be comfortable with Python or R, SQL, and the Python libraries that are commonly used for Machine Learning and statistical modeling, like pandas, scikit-learn, and TensorFlow.
For further practice, refer to our popular guide on quantitative interview questions , or practice some cool fintech projects in machine learning to bolster your resume.
If you need further guidance, we also have a tailored Data Science Learning Path covering core topics and practical applications.
Prepare Behavioral Interview Answers
Soft skills such as collaboration and adaptability are paramount to succeeding in any job, especially Data Science roles where you’ll need to coordinate with teams from non-technical backgrounds as well as stakeholders from different geographies.
To test your current preparedness for the interview process, try a mock interview to improve your communication skills.
What is the average salary for a Data Science role at JP Morgan?
Average Base Salary
Average Total Compensation
View the full Data Scientist at Jpmorgan Chase & Co. salary guide
The average base salary for a Data Scientist at JP Morgan is US$128,435 , making the remuneration competitive for prospective applicants.
For more insights into the salary range of Data Scientists at various companies, check out our comprehensive Data Scientist Salary Guide .
Where can I read more discussion posts on the JP Morgan Data Science role here in Interview Query?
Here is our discussion board where Interview Query members talk about their JP Morgan interview experience. You can also use the search bar to look up the general Data Science interview experience to gain insights into other companies’ interview patterns.
Are there job postings for JP Morgan Data Science roles on Interview Query?
We have jobs listed for Data Science roles in JP Morgan, which you can apply for directly through our job portal . You can also have a look at similar roles that are relevant to your career goals and skill set.
In conclusion, succeeding in a JP Morgan Data Science interview requires not only a strong foundation in coding and algorithms but also the ability to apply them to real-world financial problems, and the skill to communicate your findings to business stakeholders.
If you’re considering opportunities at other companies, check out our Company Interview Guides . We cover a range of similar companies, so if you are looking for Data Science positions in financial or banking firms, you can check our guides for Citi , Morgan Stanley , Wells Fargo , and more.
For other data-related roles at JP Morgan, consider exploring our Business Analyst , Machine Learning Engineer , Product Analyst , and similar guides in our main JP Morgan Chase interview guide .
With diligent preparation and a solid interview strategy, you can confidently approach the interview and showcase your potential as a valuable employee to JP Morgan Chase. Check out more of our content here at Interview Query, and we hope you’ll land your dream role very soon!
Please update your browser.
- Careers Brand
- JPMC Careers
- Careers in United States
- English Master
- Careers Home
- Student & Graduate Careers
- Jobs, Student Programs & Internships
AI & Data Science
Help us harness the power of data, analytics and insights.
Delivering excellence at the intersection of data science, research and industry expertise, our AI and Data Science teams go beyond where any bank has gone before. We develop technology and create solutions to help to solve some of the world's most interesting financial problems, while improving our customer and client experiences every day. Whether you’re working with artificial intelligence, big data, machine learning, blockchain technology or robotics, our entrepreneurial team environment challenges you to push the limits of your expertise in the pursuit of impactful and commercial real-world applications.
Program information
Learn More About Our AI & Data Science Internship Opportunities
What you'll do
Who we're looking for
What we offer
You'll apply the latest Data Science techniques to our unique data assets while collaborating directly with traders and salespeople to drive the data-led transformation of our businesses.
Depending on your area of interest, AI & Data Science Interns will be placed on one of the following teams:
- Machine Learning Centre of Excellence : Join a world-class machine learning team that continually advances state-of-the-art methods to solve a wide range of real-world financial problems by leveraging JPMorgan Chase’s vast datasets. With this unparalleled access to data, a remit that spans all of the firm’s lines of business, and history of setting the standard for deep learning and RL based solutions in NLP, time series, speech analytics and more, the team is transforming how the financial industry operates.
- AI Research : Explore cutting-edge research in the fields of AI and Machine Learning, as well as related fields like Cryptography, to develop solutions that are most impactful to J.P. Morgan’s clients and businesses. The team works closely with the QR and Data Analytics teams across the firm, and partners with leading academic and research institutions around the world on areas of mutual interest.
- Applied AI & Machine Learning : Combine machine learning techniques with unique data assets to optimize business decisions. Develop tools to leverage machine learning and deep learning models to solve problems in areas like Speech Recognition, Natural Language Processing and Time Series predictions.
- Asset Management : Provide quantitative solutions to asset allocation and portfolio construction.
Valued qualities
For our internship roles we’re looking for those enrolled in an undergraduate or graduate degree program in math, sciences, engineering, computer science or other quantitative fields.
We are seeking colleagues with excellent analytical, quantitative and problem solving skills and demonstrated research ability. We value strong communication skills and the ability to present findings to a non-technical audience. We do not require you to have prior experience in financial markets.
• Knowledge of machine learning / data science theory, techniques and tools
• Programming experience with one or more of Python, Matlab, C++, Java, C#
• Excellent analytical quantitative and problem solving skills and demonstrated research ability
•Strong communication skills and the ability to present findings to a non-technical audience
Your professional growth and development will be supported throughout the internship program via project work related to your academic and professional interests, mentorship, engaging speaker series with senior leaders and more.
Through research and hands-on work experience, you'll develop solutions and technology that help to solve the world's most interesting financial problems, and improve and protect our customer and client experiences every day. You'll be supported by your teammates, tutors and mentors throughout the internship experience.
Career Progression
The specialized knowledge and skills gained through the program will prepare you for a successful career at the firm. Top performing candidates may receive a full-time offer.
What we do
How we hire

You're now leaving J.P. Morgan
J.P. Morgan’s website and/or mobile terms, privacy and security policies don’t apply to the site or app you're about to visit. Please review its terms, privacy and security policies to see how they apply to you. J.P. Morgan isn’t responsible for (and doesn’t provide) any products, services or content at this third-party site or app, except for products and services that explicitly carry the J.P. Morgan name.
JPMorgan Chase: Digital transformation, AI and data strategy sets up generative AI

View full PDF

JPMorgan Chase will deliver more than $1.5 billion in business value from artificial intelligence and machine learning efforts in 2023 as it leverages its 500 petabytes of data across 300 use cases in production.
"We've always been a data driven company," said Larry Feinsmith, Managing Director and Head of Technology Strategy, Innovation, & Partnerships at JPMorgan Chase. Feinsmith, speaking with Databricks CEO Ali Ghodsi during a keynote at the company’s Data + AI Summit, said JPMorgan Chase has been continually investing in data, AI, business intelligence tools and dashboards.
Indeed, JPMorgan Chase said it will spend $15.3 billion on technology investments in 2023. JPMorgan Chase's technology budget has grown at a 7% compound annual growth rate over the last four years.
Feinsmith said the bank's AI/ML strategy is one of the big reasons JPMorgan Chase migrated to the public cloud. "If you look at our size and scale, the only way to deploy at scale is to do it through platforms," said Feinsmith. "Everyone has an opinion on data platforms, but you can efficiently move the data once and manage. Once you start moving data around it's highly inefficient and breaks the lineage."
JPMorgan Chase, a customer of Databricks, Snowflake and MongoDB, has multiple platforms, according to Feinsmith. It has an internal platform, JADE (JPMorgan Chase Advanced Data Ecosystem) for moving and managing data and one called Infinite AI for data scientists. "Equally as important as the data is the capabilities that surround that data," said Feinsmith, adding that data discovery, data lineage, governance, compliance and model lifecycle are critical.

According to Feinsmith, JPMorgan Chase's AI efforts start with a business focus with data scientists and AI/ML experts embedded into each business.
Feinsmith said JPMorgan Chase is leveraging streaming data and said he was a fan of Databricks' Lakehouse architecture and new AI features because it's easier to move and process data in one environment instead of two architectures, a data warehouse for business intelligence and a data lake for AI. JPMorgan deploys a central but federated data strategy and interoperability between data platforms is important. "Data has to be interoperable," Feinsmith told Ghodsi. "Not all of our data will wind up in Databricks. Interoperability is very important."
That comment rhymes with what other enterprise technology buyers have said. Despite a lot of talk about consolidating vendors--mostly from vendors looking to gain share--enterprise buyers want to keep options open. How JPMorgan Chase has approached its tech stack is instructive.
The digital transformation behind the AI
At JPMorgan Chase's Investor Day in May, Lori Beer, Global CIO at the bank, gave an overview of the bank's technology strategy. In 2022, JP Morgan launched a plan to deliver leading technology at scale with its team of 57,000 employees.
"Products and platforms need a strong foundation to be successful, and ours are underpinned by our mission to modernize our technology and practices," explained Beer. "We are already delivering product features 20% faster than last year, and we continue to modernize our applications, leverage software as a service and retire legacy applications."
JPMorgan Chase is moving to a multi-vendor public cloud approach while optimizing its owned data centers. The company is also embedding data and insights throughout the organization, said Beer. Those efforts will pave the way for large language models (LLMs) and other advances in the future.
"We have driven $300 million in efficiency through modern engineering practices and labor productivity, and we have developed a framework that enables us to identify further opportunities in the future. Our infrastructure modernization efforts have yielded an additional $200 million in productivity, driven by improved utilization and vendor rationalization," said Beer.

Here's a look at the key pillars of JP Morgan Chase's digital transformation.
Applications. Beer said the bank has decommissioned more than 2,500 legacy applications since 2017 and is focusing on modernizing software to deliver products faster. The bank has more than 560 SaaS applications, up 14% from 2022. By using industry-leading SaaS applications, Beer said it will be easier to scale new products to more than 290,000 employees.
Infrastructure modernization. Beer said:
"To date, we have moved about 60% of our in-scope applications to new data centers, which are 30% more efficient, and this translates to 16,000 fewer hardware assets. We are also migrating applications to utilize the benefit of public and private cloud. 38% of our infrastructure is now in the cloud, which is up 8 percentage points year-over-year. In total, 56% of our infrastructure spend is modern. Over the next three years, we have line of sight to have nearly 80% on modern infrastructure. Of the remainder, half are mainframes, which are highly efficient and already run in our new data centers."
JPMorgan Chase has been able to maintain infrastructure expenses flat even though compute and storage volumes have increased 50% since 2019, said Beer. One example is Chase.com is now being served through AWS and has an average of 15 releases a week.
Engineering. Beer said JPMorgan is equipping its 43,000 engineers with modern tools to boost productivity. JPMorgan Chase has adopted a framework to speed up the move from backlog to production via agile development practices.
Data and AI. Beer said:
"We have made tremendous progress building what we believe is a competitive advantage for JPMorgan Chase. We have over 900 data scientists, 600 machine learning engineers and about 1,000 people involved in data management. We also have a 200-person top notch AI research team looking at the hardest problems in the new frontiers of finance."
Specifically, Beer said AI is helping JPMorgan Chase deliver more personalized products and experiences to customers with $220 million in benefits in the last year. At JPMorganChase's Commercial Bank, AI provided growth signals and product suggestions for bankers. That move provided $100 million in benefits, said Beer.

The data mesh
To capitalize on AI, JPMorgan Chase created a data mesh architecture that is designed to ensure data is shareable across the enterprise in a secure and compliant way. The bank outlined its data mesh architecture at a 2021 Data Mesh Learning meetup .
JPMorgan said its data approach is to define data products that are curated by people who understand the data and management requirements. Data products are defined as groups of data from systems that support the business. These data groups are stored in its product specific data lake. Each data lake is separated by its own cloud-based storage layer. JPMorgan Chase catalogs the data in each lake using technologies like AWS S3 and AWS Glue.
Data is then consumed by applications that are separated from each other and the data lakes. JPMorgan Chase said it makes the data lake visible to data users to query it.
At a high level, JPMorgan Chase said its approach will empower data product owners to manage and use data for decisions, share data without copying it and provide visibility into data sharing and lineage.
In a slide, this architecture looks like this.

According to JPMorgan Chase, its architecture keeps data storage bills down and ensures accuracy. Since data doesn't physically leave the data lake, JPMorgan Chase said it's easier to enforce decisions product owners make about their data and ensure proper access controls.
How JPMorgan Chase will address generative AI
Given JPMorgan Chase's data strategy and architecture, the bank can more easily leverage new technologies like generative AI. Feinsmith at the Databricks conference said JPMorgan Chase was optimistic about generative AI but said it's very early in the game.
"There's a lot of optimism and a lot of excitement about generative AI. Businesses all know about it and generative AI will make us more productive," said Feinsmith. "But we won't roll out generative AI until we can do it in a responsible way. We won't roll it out until it's done in an entirely responsible manner. It's going to take time."
In the meantime, JPMorgan Chase's Feinsmith said the bank is working through the generative AI risks. The promise for JPMorgan Chase is obvious: Take 500 petabytes of data, train it, make it valuable and then add value to open-source models.
Beer outlined the JPMorgan Chase approach during the bank's Investor Day in May.
"We couldn't discuss AI without mentioning GPT and large language models. We recognize the power and opportunity of these tools and are committed to exploring all the ways they can deliver value for the firm. We are actively configuring our environment and capabilities to enable them. In fact, we have a number of use cases leveraging GPT4 and other open-source models currently under testing and evaluation.”
With Databricks, MongoDB and Snowflake all adding generative AI and large language model (LLMs) capabilities to the data stack, enterprises will have the tools when ready.
JPMorgan Chase has named Teresa Heitsenrether its chief data and analytics officer, a central role overseeing the adoption of AI across the bank. Heitsenrether oversees data use, governance and controls with the aim of harnessing AI technologies to effectively and responsibly develop new products, improve productivity and enhance risk management.
Heitsenrether is a 35-year veteran at JP Morgan Chase and previously was Global Head of Securities Services from 2015 to 2023.
Beer said explained JPMorgan Chase’s approach to responsible AI:
“We take the responsible use of AI very seriously, and we have an interdisciplinary team, including ethicists, data scientists, engineers, AI researchers and risk and control professionals helping us assess the risk and build appropriate controls to prevent unintended misuse, comply with regulation, and promote trust with our customers and communities. We know the industry is making remarkably fast progress, but we have a strong view that successful AI is responsible AI."
Business Research Themes
Memberships.
- About our Research
- Research Index
- Research by Role
- Research by Theme
- Custom Research
- Speaking Engagements
- Technology Acquisition
| Thank you for Signing Up |

You are using an outdated browser. Please upgrade your browser to improve your experience.

UPDATED 12:09 EDT / JULY 10 2021

A new era of data: a deep look at how JPMorgan Chase runs a data mesh on the AWS cloud

BREAKING ANALYSIS by Dave Vellante
A new era of data is upon us.
The technology industry generally and the data business specifically are in a state of transition. Even our language reflects that. For example, we rarely use the phrase “big data” anymore. Rather we talk about digital transformation or data-driven companies.
Many have finally come to the realization that data is not the new oil — because unlike oil, the same data can be used over and over for different purposes. But our language is still confusing. We say things like “data is our most valuable asset,” but in the same sentence we talk about democratizing access and sharing data. When was the last time you wanted to share your financial assets with your co-workers, partners and customers?
In this Breaking Analysis we want to share our assessment of the state of the data business. We’ll do so by looking at the data mesh concept and how a division of a leading financial institution, JPMorgan Chase, is practically applying these relatively new ideas to transform its data architecture for the next decade.
What is a data mesh?
As we’ve previously reported , data mesh is a concept and set of principles introduced in 2018 by Zhamak Dehghani, director of technology at ThoughtWorks Inc. She created this movement because her clients, some of the leading firms in the world, had invested heavily in predominantly monolithic data architectures that failed to deliver desired results.

Her work went deep into understanding why her clients’ investments were not delivering desired results. Her main conclusion was the prevailing method of trying to force our data into a single monolithic architecture is an approach that is fundamentally limiting.
One of the profound ideas of data mesh is the notion that data architectures should be organized around business lines with domain context. That the highly technical and hyperspecialized roles of a centralized cross-functional team are a key blocker to achieving our data aspirations.
This is the first of four high-level principles of data mesh, specifically:
- That the business domain should own the data end-to-end, rather than have to go through a centralized technical team;
- A self-service platform is fundamental to a successful architectural approach where data is discoverable and shareable across an organization and ecosystem;
- Product thinking is central to the idea of data mesh – in other words, data products will power the next era of data success;
- Data products must be built with governance and compliance that is automated and federated.
No. 3 is one of the most significant and difficult to understand. Most discussion around data value in the past decade have centered around using data to create actionable insights: Data informs humans so they can make better decisions. We see this as a necessary but insufficient condition for successful data transformations in the 2020s. In other words, if the end game is better insights we see that as an important but evolutionary extension of reporting. Rather, we believe that building data products that can be monetized – either to cut costs directly or, more importantly, generate new revenue, as the more interesting (and now attainable) target goal.
There’s lots more to the data mesh concept and there are tons of resources on the Web to learn more, including an entire community that has formed around data mesh. But this should give you a basic idea.
Data mesh is tools-agnostic
One other notable point is that in observing Zhamak’s work, she has deliberately avoided discussions around specific tooling, which has frustrated some folks. Understandably, because we all like to have references that tie to products and companies. This has been a two-edged sword in that on the one hand, it’s good, because data mesh is designed to be successful independent of the tools that are chosen. On the other hand, it has led some folks to take liberties with the term data mesh and claim “mission accomplished” when their solution may be more marketing than reality.
JPMorgan Chase and a data mesh journey
We were really interested to see just this past week, a team from JPMC held a meetup to discuss what it called “Data Lake Strategy via Data Mesh Architecture.” We saw the name of the session and thought, “That’s a weird title.” And we wondered if they are just taking their legacy data lakes and claiming they’re now transformed into a data mesh?

But in listening to the presentation the answer is a definitive “No – not at all.” A gentleman named Scott Hirleman organized the session that comprised the three JPMC speakers shown above: James Reid, a divisional chief information officer, technologist and architect Arup Nanda and information architect Sarita Bakst.
This was the most detailed and practical discussion we’ve seen to data about implementing a data mesh. And this is JPMC. We know it was an early Hadoop adopter, an extremely tech-savvy company, and it has invested probably billions in the past decade on data across this massive company. And rather than dwell on the downsides of its big data past, we were pleased to see how it’s evolving its approach and embracing new thinking around data mesh.
In this post, we’re going to share some of the slides they used and comment on how it dovetails into the concept of data mesh as we understand it, and dig a bit into some of the tooling that is being used by JPMorgan, specifically around the Amazon Web Services cloud.
It’s all about business value
JPMC is in the money business and in that world, it’s all about the bottom line.
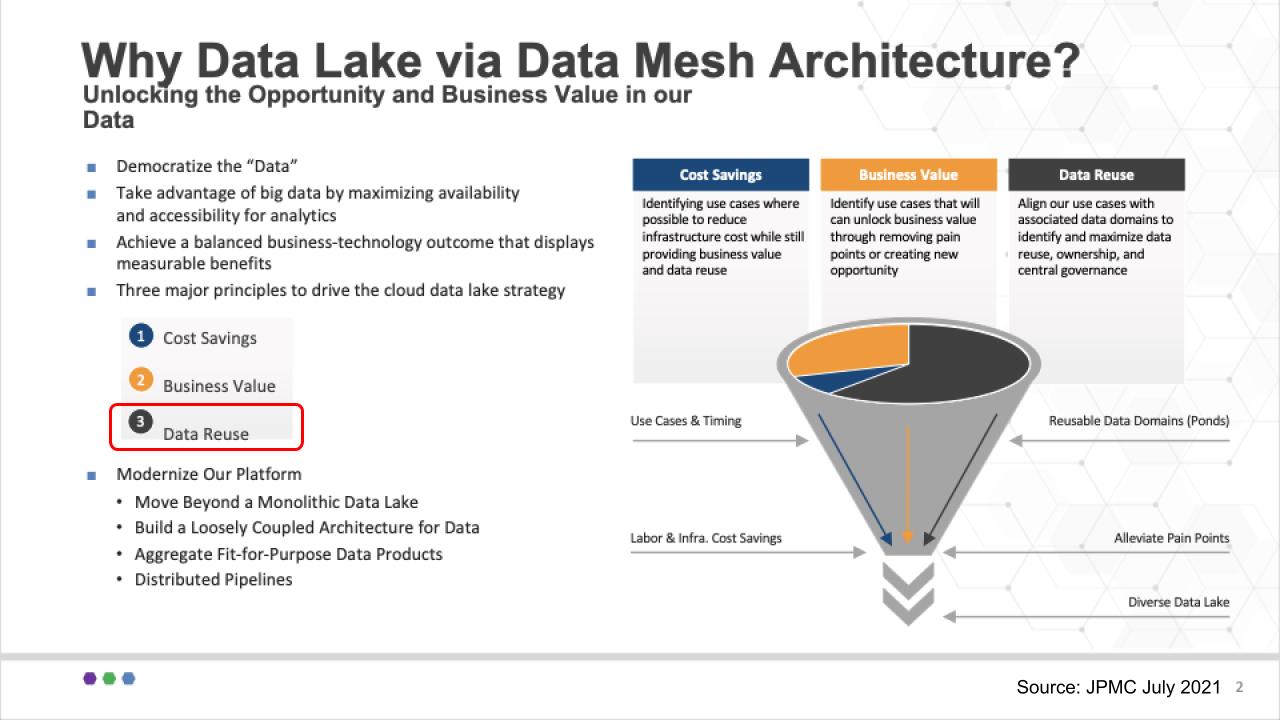
James Reid, the CIO, showed the slide above and talked about the team’s overall goals, which centered on a cloud-first strategy to modernize the JPMC platform. He focused on three factors of value: No. 1: Cutting costs – always, of course. No. 2: Unlocking new opportunities or accelerating time to value. And we really like No. 3, which we’ve highlighted in red: Data re-use as a fundamental value ingredient. And his commentary here was all about aligning with the domains, maximizing data reuse and making sure there’s appropriate governance.
Don’t get caught up in the term data lake – we think that’s just how JP Morgan communicates internally. It’s invested in the data lake concept – and it likes water analogies at JPMC. They use the term data puddles for example, which are single-project data marts and data ponds which comprise multiple puddles that can can feed into data lakes.
As we’ll see, JPMC doesn’t try to force a single version of the truth by putting everything into a monolithic data lake. Rather, it enables the business lines to create and own their own data lakes that comprise fit-for-purpose data products. And it uses a catalog of metadata to track lineage and provenance so that when it reports to regulators, it can trust that the data it’s communicating are current, accurate and consistent with previous disclosures.
Cloud-first platform that recognizes hybrid
JPMC is leaning into public cloud and adopting agile methods and microservices architectures, and it sees cloud as a fundamental enabler. But it recognizes that on-premises data must be part of the data mesh equation.
Below is a slide that starts to get into some of the generic tech in play:
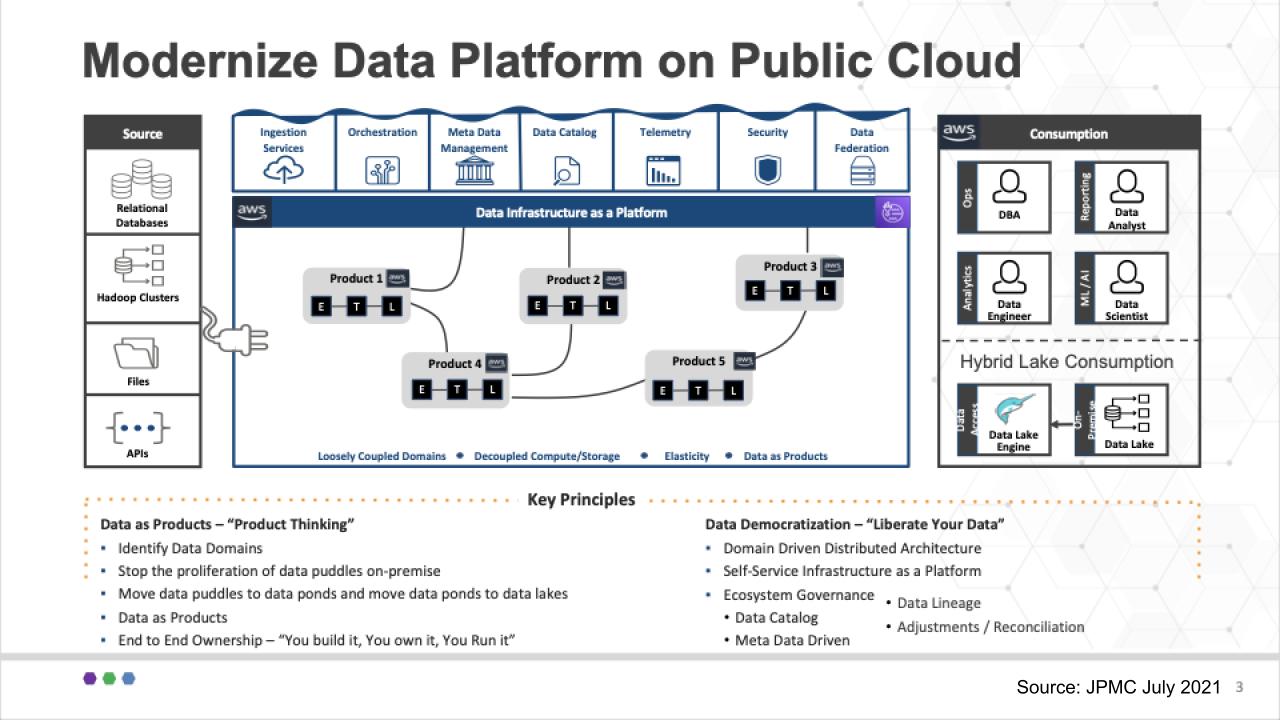
We’d like to make a couple of points here that tie back to Zhamak Deghani’s original concept.
The first is that unlike many data architectures, this diagram puts data as products right in the fat middle of the chart. The data products live in business domains and are at the heart of the architecture. The databases, Hadoop clusters, files and APIs on the left hand side serve the data product builders.
The specialized roles on the right-hand side – the DBAs, data engineers, data scientists and data analysts serve the data product builders. Because the data products are owned by the business they inherently have context. This is nuanced but an important difference from most technical data teams that are part of a pipeline process but lack business and domain knowledge.
And you can see at the bottom of the slide, the key principles include domain thinking and end-to-end ownership of the data products – build, own, run/manage.
At the same time, the goal is to democratize data with self-service as a platform.
One of the biggest points of contention on data mesh is governance and as Sarita Bakst said on the meetup “metadata is your friend.” She said, “This sounds kinda geeky” – but we agree, it’s vital to have a metadata catalog to understand where data resides, the data lineage and overall change management.
So to us, this passed the data mesh stink test pretty well.
Data as products: Don’t try to boil the ocean
The presenters from JPMC said one of the most difficult things for them was getting their heads around data products. They spent a lot of time getting this concept working. Below is one of the slides they used to describe their data products as it related to their specific segment of the financial industry:
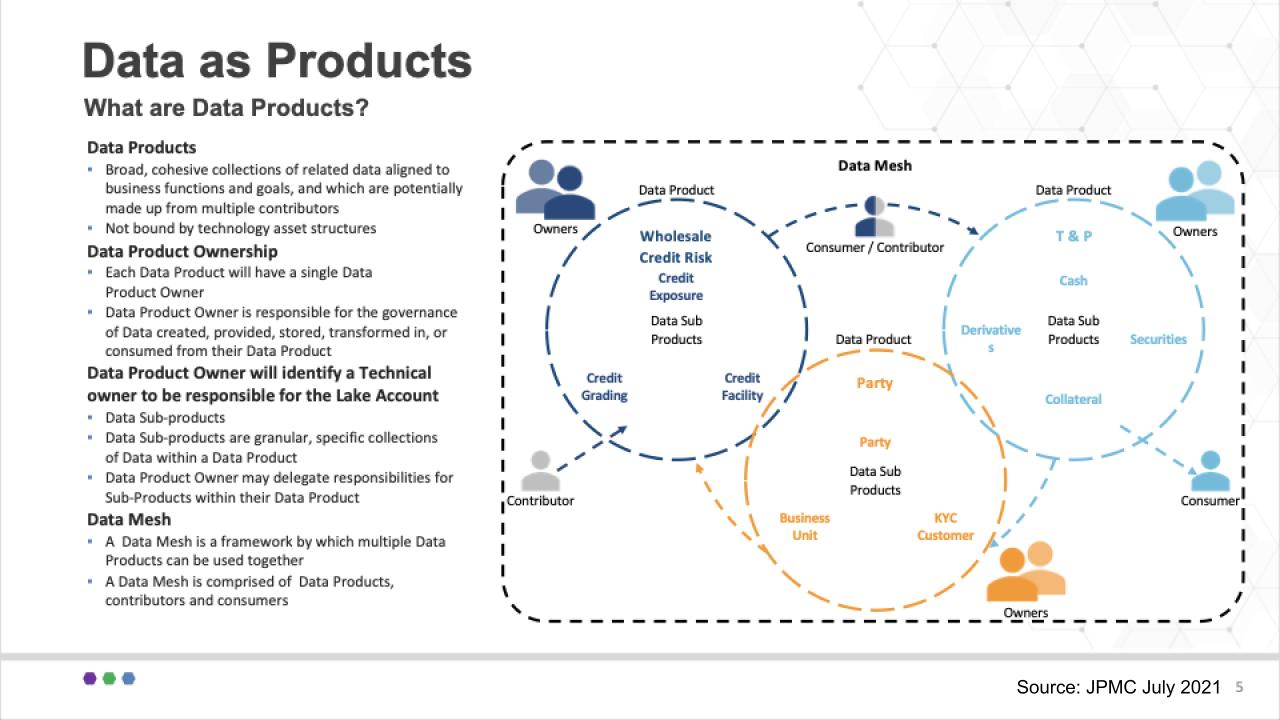
The team stressed that a common language and taxonomy is very important in this regard. It said, for example, it took a lot of discussion and debate to define what is a transaction. But you can see at a high level, three product groups around Wholesale Credit Risk, Party, and Trade and Position Data as Products. And each of these can have subproducts (e.g. KYC under Party). So a key for JPMC was to start at a high level and iterate to get more granular over time.
Lots of decisions had to be made around who owns the products and subproducts. The product owners had to defend why that product should exist, what boundaries should be put in place and what data sets do and don’t belong in the product — and which subproducts should be part of these circles. No doubt those conversations were engaging and perhaps sometimes heated as business line owners carved out their respective turf.
The team didn’t say this specifically, but tying back to data mesh, each of these products, whether in a data lake, data hub, data pond, data warehouse or data puddle, is a node in the global data mesh.
Supporting this notion, Sarita Bakst said this should not be infrastructure-bound; logically, any of these data products, whether on-prem or in the cloud, can connect via the data mesh.
So again we felt like this really stayed true to the data mesh concept.
Key technical considerations
This chart below shows a diagram of how JPMorgan thinks about the problem from a technology point of view:
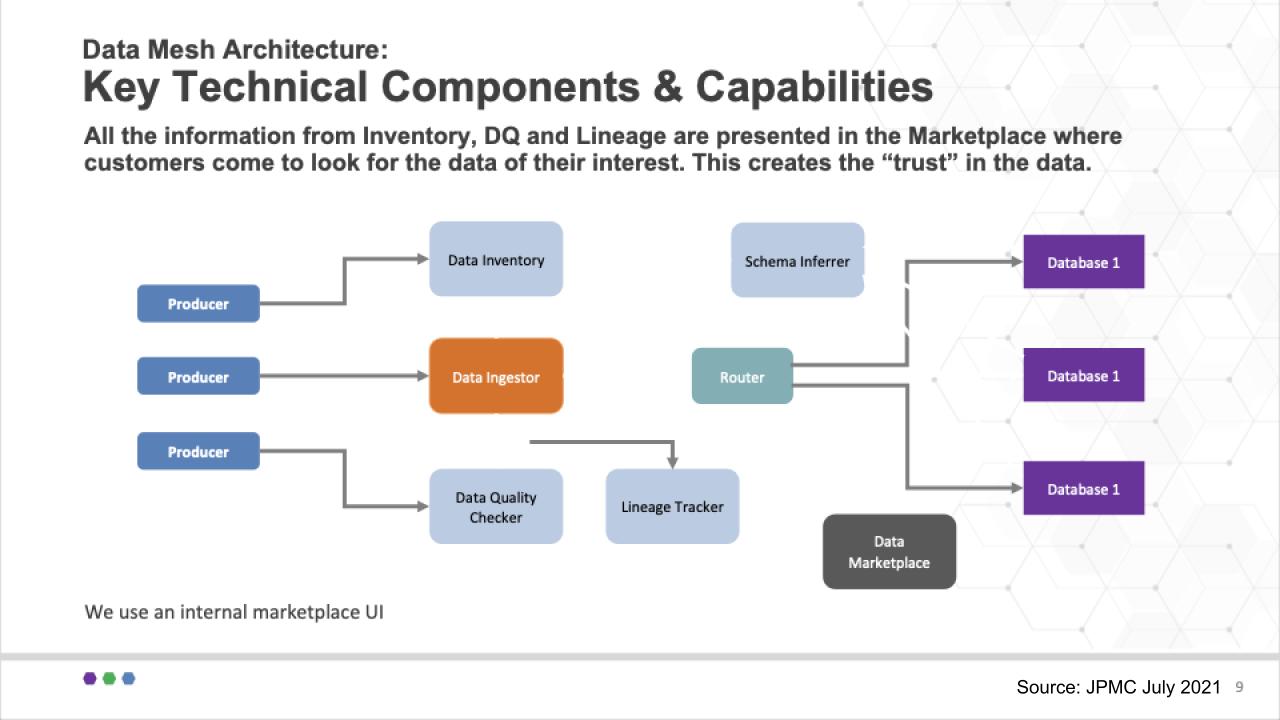
Some of the challenges JPMC had to consider was how to write to various data stores, can you/how can you move data from one data store to another? How can data be transformed? Where is data located? Can the data be trusted, how can it be easily accessed, who has the right to access the data? These are problems that technology can solve.
To address these issues, Arup Nanda explained that the heart of the slide above is the Data Ingestor (versus ETL or extract/transform/load). All data producers/contributors send data to the Ingestor. The Ingestor then registers the data so it’s in the data catalog, it does a data quality check and it tracks the lineage. Then data is sent to the router, which persists the data based on the best destination as informed by the registration.
This is designed to be flexible. In other words, the data store for a data product is not pre-determined and fixed. Rather it’s decided at the point of inventory and that allows changes to be easily made in one place. The router simply reads that optimal location and sends it to the appropriate data store.
The Schema Inferrer is used when there is no clear schema on write. In this case the data product is not allowed to be consumed until the schema is inferred and settled. The data in this case goes to a raw area and the Inferrer determines the proper schema and then updates the inventory system so that the data can be routed to the proper location and accurately tracked.
That’s a high-level snapshot of some of the technical workflow and how the sausage factory works in this use case. Very interesting and worth technical practitioners watching at least the technical section of this 83-minute video , which starts around 19 minutes in.
How JPMC leverages the AWS cloud for data mesh
Now let’s look at the specific implementation on AWS and dig into some of the tooling.
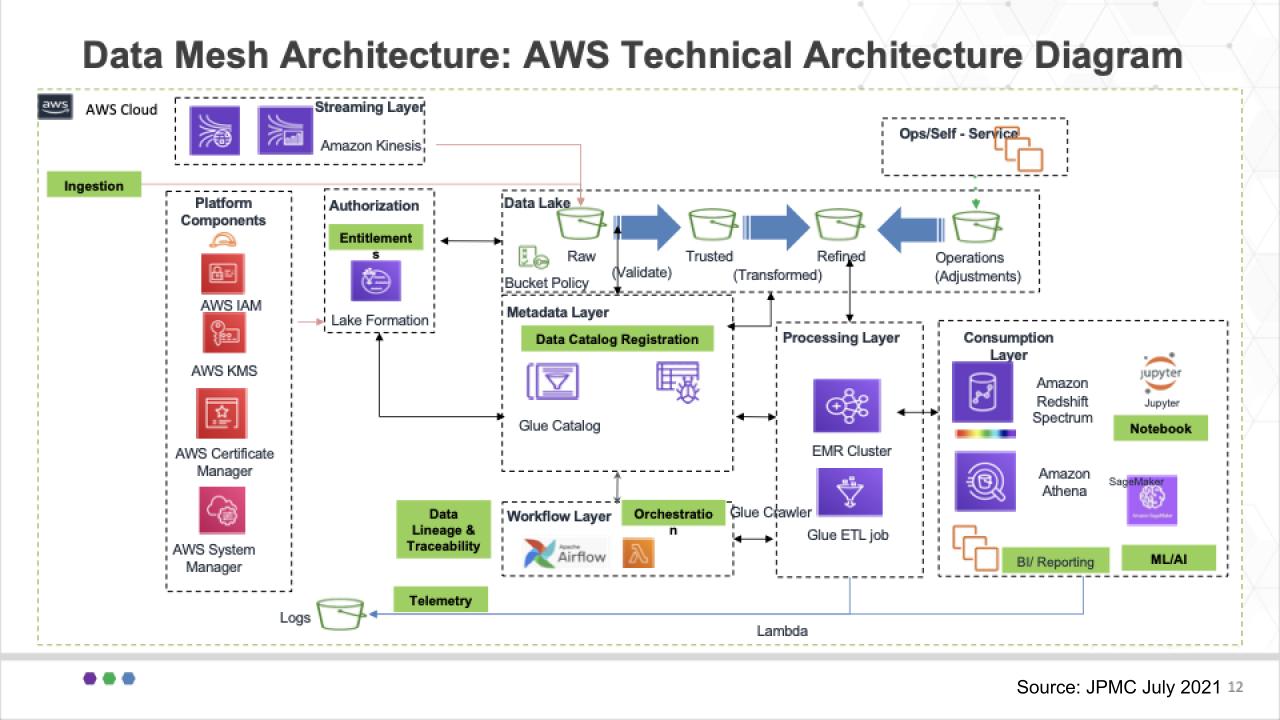
As described in some detail by Arup Nanda, the diagram above shows the reference architecture used by this group at JPMorgan. It shows all the various AWS services and components that support their data mesh approach.
Start with the Authorization block right underneath Kinesis. The Lake Formation is the single point of entitlement for data product owners and has a number of buckets associated with it – including the raw area we just talked about, a trusted bucket, a refined bucket and a bucket for any operational adjustments that are required.
Beneath those buckets you can see the Data Catalog Registration block. This is where the Glue Catalog resides and it reviews the data characteristics to determine in which bucket the router puts the data. If, for example, there is no schema, the data goes into the Raw bucket and so forth, based on policy.
And you can see the many AWS services in use here, identity, the EMR cluster from the legacy Hadoop work done over the years, Redshift Spectrum and Athena. JPMC uses Athena for single threaded workloads and Redshift Spectrum for nested types that can be queried independently of each other.
Now remember, very importantly, in this use case, there is not a single lake formation, rather multiple lines of business will be authorized to create their own lakes and that creates a challenge. In other words, how can that be done in a flexible manner to accommodate the business owners?
Note: Here’s an AWS-centric blog on how they recommend implementing data mesh
Enter data mesh
JPMC applied the notion of federated lake formation accounts to support its multiple lines of business. Each line of business can create as many data producer and consumer accounts as they desire and roll them up to their master line of business lake formation account shown in the center of each block. And they cross connect these data products in a federated model as shown below.
These all roll up into a master Glue Catalog as shown in the middle of the diagram so that any authorized user can find out where a specific data element is located. This superset catalog comprises multiple sources and syncs up across the data mesh.
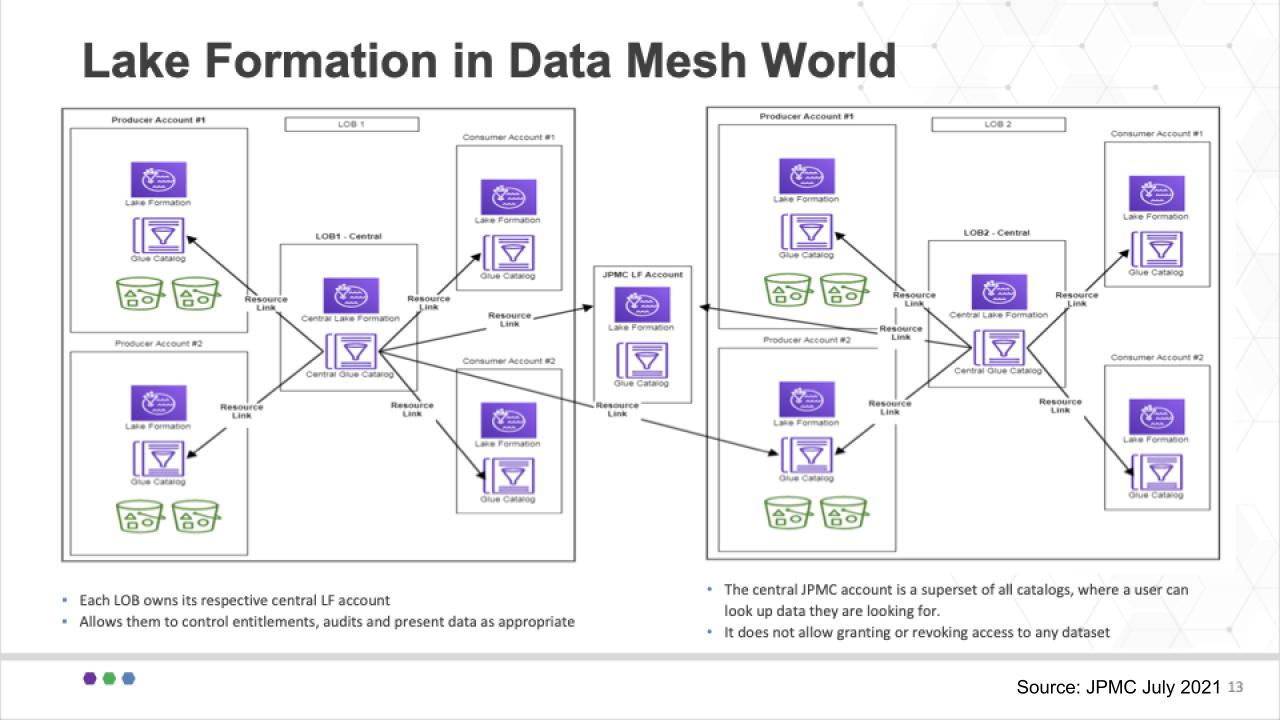
So again this to us was a well thought out and practical application of data mesh. Yes it includes some notion of centralized management but much of that responsibility has been passed down to the lines of business. It does roll up to a single master catalog and that is a metadata management effort and seems compulsory to ensure federated and automated governance.
Importantly, at JPMC, the office of the chief data officer is responsible for ensuring governance and compliance throughout the federation.
Which vendors play in data mesh?
Let’s take a look at some of the suspects in this world of data mesh and bring in the ETR data .
Now, of course, ETR doesn’t have a data mesh category – and there’s no such thing as a data mesh vendor; you build a data mesh, you don’t buy it. So what we did is used the ETR data set to filter certain sectors to identify some of the companies that might contribute to the data mesh to see how they’re performing.
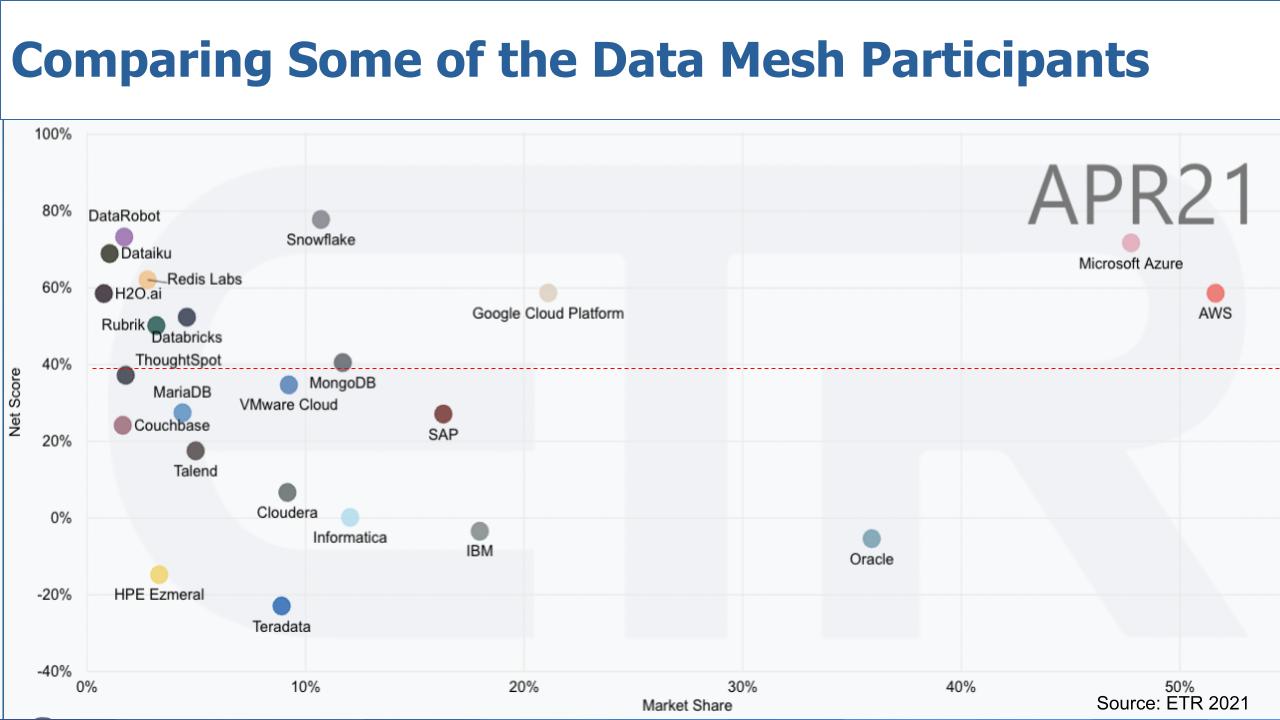
The chart above depicts a popular view we often like to share. It’s a two-dimensional graphic with Net Score or spending momentum on the vertical axis and Market Share or pervasiveness within the data set on the horizontal axis. And we’ve filtered the data on sectors such as analytics, data warehouse, etc, that reflected participation in data mesh.
Let’s make a few observations.
As is often the case, Microsoft Azure and AWS are almost literally off the charts with high spending velocity and a large presence in the market. Oracle Corp. also stands out because much of the world’s data lives inside Oracle databases – it doesn’t have the spending momentum, but the company remains prominent. You can see Google Cloud doesn’t have nearly the presence, but its momentum is elevated.
Remember, that red dotted line at 40% indicates our subjective view of what we consider a highly elevated spending momentum level.
A quick aside on Snowflake
Snowflake Inc. has consistently shown to be the gold standard in Net Score and continues to maintain highly elevated spending velocity in the Enterprise Technology Research data set. In many ways Snowflake with its data marketplace, data cloud vision and data-sharing approach fits nicely into the data mesh concept. Snowflake has used the term data mesh in its marketing, but in our view it lacks clarity and we feel like it’s still trying to figure out how to communicate what that really is.
We don’t see Snowflake as a monolithic architecture, but it’s marketing sometimes uses terms that allow one to infer legacy thinking. Our sense is this is actually customer-driven. What we mean is Snowflake customers are so used to monolithic architectural approaches and because Snowflake is so simple to use, it “paves the cowpath” and applies Snowflake to its legacy organizational structures and ways of thinking.
In reality, the value of Snowflake, in the context of data mesh, is the ability quickly and easily to spin up (and down) virtual data stores and share data across the Snowflake data cloud with federated governance. Snowflake’s vision is to abstract the underlying complexity of the physical cloud location (that is, AWS, GCP or Azure) and enable sharing across the globe, within its governed data cloud. Ideally it minimizes the need to make copies to share data (notwithstanding sometimes copies are necessary for latency considerations).
The bottom line is we actually think Snowflake fits nicely into the data mesh concept and is well-positioned for the future.
Other vendors of note
Databricks Inc. is also interesting because the firm has momentum and we expect further elevated levels on the vertical axis as it readies for IPO. The firm has a strong product and very good managed service. Initially, everyone thought Databricks would try to be the Red Hat of big data and build a service around Spark.
Rather, what it has done is build a managed service, with strong artificial intelligence and data science chops, and is taking the data lake to new levels. It is one to watch for sure and on a collision course with Snowflake in our view. We need to do more research but have always believed Databricks fits well into a federated data mesh approach.
We included a number of other database companies for obvious reasons – such as Redis Labs Inc., MongoDB Inc., MariaDB Inc., Couchbase and Teradata Corp. There’s also SAP SE; it’s not all HANA for SAP, but it’s a prominent player in the market, as is IBM.
Cloudera Inc., which includes Hortonworks Inc. and Hewlett Packard Enterprise Co.’s Ezmeral, which comprises the MapR business that HPE acquired. These include some of the early Hadoop deployments that are evolving. And of course Talend SA and Informatica Corp. are two data integration companies worth noting.
And we also included some of the AI/machine learning specialists and data science players in the mix like DataRobot, which just did a monster $250M round, Dataiku, H2O.ai and ThoughtSpot, which is a specialist using AI to democratize data and fits very well into the data mesh concept, in our view.
And we put VMware Inc. cloud in there for reference because it really is the predominant on-prem infrastructure platform.
JPMC: a practical example of data mesh in action
First, thanks to the team at JPMorgan for sharing this data. We really want to encourage practitioners and technologists to go watch the YouTube video of that meetup. And thanks to Zhamak Deghani and the entire data mesh community for the outstanding work they do challenging established conventions. The JPM presentation gives you real credibility and takes data mesh well beyond concept and demonstrates how it can be done.

This is not a perfect world. You have to start somewhere and there will be some failures. The key is to recognize that shoving everything into a monolithic data architecture won’t support massive scale and cloudlike agility. It’s a fine approach for smaller firms, but if you’re building a global platform and a data business it’s time to rethink your data architecture and, importantly, your organization.
Much of this is enabled by cloud – but cloud-first doesn’t mean you’ll leave your on-prem data behind. On the contrary, you must include nonpublic cloud data in your data mesh vision as JPMC has done.
Getting some quick wins is crucial so you can gain credibility within the organization and continue to grow.
One of the takeaways from the JPMorgan team is there is a place for dogma – like organizing around data products and domains. On the other hand, you have to remain flexible because technologies will come and they will go.
If you’re going to embrace the metaphor of puddles, ponds and lakes, we suggest you expand the scope to include data oceans – something we have talked about extensively on theCUBE. Data oceans – it’s huge! Watch this fun clip with analyst Ray Wang and John Furrier on the topic.
And think about this: Just as we are evolving our language, we should be evolving our metrics. Much of the last decade of big data was around making the technology work. Getting it up and running and managing massive amounts of data. And there were many KPIs built around standing up infrastructure and ingesting data at high velocity.
This decade is not just about enabling better insights. It’s more than that. Data mesh points us to a new era of data value, and that requires new metrics around monetizing data products. For instance, how long does it take to go from data product idea to monetization? And what is the time to quality? Automation, AI and very importantly, organizational restructuring of our data teams will heavily contribute to success in the coming years.
So go learn, lean in and create your data future.
Ways to keep in touch
Remember we publish each week on Wikibon and SiliconANGLE . These episodes are all available as podcasts wherever you listen .
Email [email protected] , DM @dvellante on Twitter and comment on our LinkedIn posts .
Also, check out this ETR Tutorial we created , which explains the spending methodology in more detail. Note: ETR is a separate company from Wikibon and SiliconANGLE . If you would like to cite or republish any of the company’s data, or inquire about its services, please contact ETR at [email protected].
Here’s the full video analysis:
Image: Alex
A message from john furrier, co-founder of siliconangle:, your vote of support is important to us and it helps us keep the content free., one click below supports our mission to provide free, deep, and relevant content. , join our community on youtube, join the community that includes more than 15,000 #cubealumni experts, including amazon.com ceo andy jassy, dell technologies founder and ceo michael dell, intel ceo pat gelsinger, and many more luminaries and experts..
Like Free Content? Subscribe to follow.
LATEST STORIES

A close look at JPMorgan's aggressive cloud migration

Why Databricks vs. Snowflake is not a zero-sum game

X’s new AI training opt-out setting draws regulatory scrutiny

Cyber insurance provider Cowbell reels in $60M to grow its product portfolio

New AI models flood the market even as AI takes fire from regulators, actors and researchers

US grand jury indicts North Korean hacker for role in Andariel cyberattacks
CLOUD - BY PAUL GILLIN . 2 DAYS AGO
BIG DATA - BY GUEST AUTHOR . 2 DAYS AGO
AI - BY MARIA DEUTSCHER . 2 DAYS AGO
SECURITY - BY MARIA DEUTSCHER . 2 DAYS AGO
AI - BY ROBERT HOF . 3 DAYS AGO
SECURITY - BY MARIA DEUTSCHER . 3 DAYS AGO
More From Forbes
Jpmorgan’s cio has championed a data platform that turbocharges ai.
- Share to Facebook
- Share to Twitter
- Share to Linkedin
JPMorgan Chase headquarters in central Manhattan.
JPMorgan Chase sees artificial intelligence (AI) as critical to its future success. And the mega-bank has a big advantage over many of its smaller rivals: the massive amount of data it gathers from sources such as the 50% of U.S. households with which it has some form of relationship and the $6 trillion worth of payment flows it handles daily.
But until recently, identifying and pulling in relevant data to train AI models was taking up around 60% of the time of the bank’s growing army of data scientists. That was an inefficient use of an expensive and relatively scarce resource. Now a new data platform the bank has developed, called OmniAI, is helping it to get relevant data into its models much faster.
Speaking about the project during a presentation at the AI Summit in New York City this week, Beer said the platform, which has been up-and-running for a couple of months, helps workers identify and ingest “minimum viable data” to build models faster. The platform was developed by a team led by Apoorv Saxena, a former Google executive the bank poached in August 2018 to become its new head of AI and machine-learning services.
The initial focus is on providing data relevant to a dozen high-priority use cases of AI that the bank has identified. They include things like tailoring consumer-banking services for individual customers and driving internal efficiencies in areas like travel-and-entertainment expense management. According to Beer, the use of AI-driven technology has already helped JPMorgan Chase save $150 million in expenses.
The platform doesn’t just let data scientists get their hands on raw material for their models quickly; it also automatically verifies that data are being used in accordance with regulations covering areas like customer privacy—again saving time and effort. JPMorgan Chase pulls in data from around 7,500 external sources as well as leveraging its own information.
Apple iPhone 16, iPhone 16 Pro Release Date Proposed In New Report
Daniel cormier calls out ufc for protecting its ‘golden goose’, today’s nyt mini crossword clues and answers for saturday, august 10.
Beer also spoke about the bank’s efforts to guard against things like bias in the AI models it builds. Last year, it hired Manuela Veloso, a prominent AI expert at Carnegie Mellon University, to head AI research, and she has been helping it think through the ways in which it is deploying AI. “Manuela challenges us all the time,” said Beer.
The new platform is part of an ambitious push by JPMorgan Chase to infuse AI into many different areas of its operations, from efforts to develop deeper insights into customers’ needs to defending itself against cyberattacks. Beer said she thinks AI will also help the financial industry in general to address some significant socioeconomic issues, such as helping more people get access to financial services and build retirement savings.

- Editorial Standards
- Reprints & Permissions
- Performance & Yields
- Ultra-Short
- Short Duration
- Empower Share Class
- Academy Securities
- Cash Segmentation
- Separately Managed Accounts
- Managed Reserves Strategy
- Capitalizing on Prime Money Market Funds
Liquidity Insights
- Liquidity Insights Overview
- Case Studies
- Leveraging the Power of Cash Segmentation
- Cash Investment Policy Statement
Market Insights
- Market Insights Overview
- Eye on the Market
- Guide to the Markets
- Market Updates
Portfolio Insights
- Portfolio Insights Overview
- Fixed Income
- Long-Term Capital Market Assumptions
- Sustainable investing
- Strategic Investment Advisory Group
MORGAN MONEY
- Global Liquidity Investment Academy
- Account Management & Trading
- Announcements
- Navigating market volatility
- 2024 US Money Market Fund Reform
- Diversity, Equity & Inclusion
- Spectrum: Our Investment Platform
- Sustainable and social investing
- Our Leadership Team
- LinkedIn Twitter Facebook

Case studies
Working with clients to solve short-term fixed income needs
FEATURED CASE STUDIES

Meituan-Dianping: A unicorn’s path to achieve world-class treasury
All case studies, vertex pharmaceuticals.
Vertex Pharmaceuticals transforms its investment processes with Morgan Money.
Kulicke & Soffa
Kulicke & Soffa meets strong risk management standard with MORGAN MONEY’s cash optimizer.
Nigeria LNG
Harnessing the Power of Technology. Nigeria LNG transforms Money Market Fund investments with MORGAN MONEY.
Micro Focus
Short-term AAA-rated money market funds provide short-term investment opportunities for divestment proceeds.
Liquidity and security over yield deliver investment benefits to NIO
Active Super (previously known as Local Government Super)
Prioritizing cash management at scale, Active Super (previously known as Local Government Super), an Australian superannuation fund, found “operational alpha”.
Meituan-Dianping
Meituan-Dianping, a growing unicorn, had a major challenge to accurately forecast its cash flow beyond three months.
NTUC Income
Singapore-based insurance provider NTUC Income had always handled its investments entirely through its internal portfolio management team.
Recruit Holdings
As the business has grown globally, liquidity and cash positions outside of Japan have expanded, creating foreign exchange (FX) exposure.
The challenge: to assess the optimal level of liquidity required to ensure John Lewis Partnership has continued financial sustainability.
Explore more
Cash investment policy statement
How to write an investment policy statement for your organization.
Leveraging the power of cash segmentation
The most effective strategy incorporates a clear investment policy, well-defined goals and parameters for liquidity, quality and return.
Invest with ease, operational efficiency and effective controls via our state-of-the-art trading and analytics platform.
- Data Science Tutorials
6 Intriguing Applications of Data Science in Banking – [JP Morgan Case Study]
Free Machine Learning courses with 130+ real-time projects Start Now!!
Companies need data to develop insights and make data-driven decisions. In order to provide better services to its customers and devise strategies for various banking operations, data science is a mandatory requirement.
Furthermore, banks need data to grow their business and draw more customers. We will go through some of the important areas where banking industries use data science to improve their products. We will see the major role of data science in banking sectors.
Then we will understand the use case of JP Morgan Chase applying data science in banking sector.

Data Science in Banking
Here are 6 interesting data science applications for banking which will guide you how data science is transforming banking industry.
1. Risk Modeling
Risk Modeling a high priority for the banking industry. It helps them to formulate new strategies for assessing their performance. Credit Risk Modeling is one of its most important aspects. Credit Risk Modeling allows banks to analyze how their loan will be repaid.
In credit risks, there is a chance of the borrower not being able to repay the loan. There are many factors in credit risk that makes it a complex task for the banks.
With Risk Modeling, banks are able to analyze the default rate and develop strategies to reinforce their lending schemes. With the help of Big Data and Data Science, banking industries are able to analyze and classify defaulters before sanctioning loan in a high-risk scenario.
Risk Modeling also applies to the overall functioning of the bank where analytical tools used to quantify the performance of the banks and also keep a track of their performance.
2. Fraud Detection
With the advancements in machine learning , it has become easier for companies to detect frauds and irregularities in transactional patterns. Fraud detection involves monitoring and analysis of the user activity to find any usual or malicious pattern.
With the increase in dependency on the internet and e-commerce for transactions, the number of frauds has increased significantly.

Using data science, industries can leverage the power of machine learning and predictive analytics to create clustering tools that will help to recognize various trends and patterns in the fraud-detection ecosystem.
There are various algorithms like K-means clustering, SVM that is helpful in building the platform for recognizing patterns of unusual activities and transactions. The process of Fraud Detection involves –
- Obtaining the data samples for training the model.
- Training our model on the given datasets. The process of training involves the implementation of several machine learning algorithms for feature selection and further classification.
- Testing and Deploying our model.
For instance, two algorithms like K-means clustering and SVM can be used for data-preprocessing and classification. K-means can be used for feature selection and SVMs are then applied to the data for its classification into a fraudulent class or otherwise.
3. Customer Lifetime Value
Customers are an essential part of the banking industries. They ensure a steady stream of revenues. Formally speaking, a Customer Lifetime Value offers a discounted value of the future revenues that are contributed by the customer. Banks are often required to predict future revenues based on past ones.
Also, banks want to know the retention of customers and if they will help to generate revenues in the future as well. Banks want their customers to be satisfied and nurture them for the current as well as future prospects.
Businesses like banking sectors are required to predict their customer lifetime value. Data Science in banking plays an essential role in this part.
With predictive analytics, banks can classify potential customers and assign them with significant future value in order to invest company resources on them. While the classification algorithms help the banks to acquire potential customers, retaining them is another challenging task.
With the growth in the competition, banks require a comprehensive view of the customers to channel their resources in an optimized manner.
There are various tools that are used in data preprocessing, cleaning and prediction. There are various tools such as Classification and Regression Trees (CART), Generalized Linear Models (GLM), etc.
This allows the banks to monitor their customers and contribute towards the growth and profitability of the company.
4. Customer Segmentation
In customer segmentation, banks group their customers based on their behavior and common characteristics in order to address them appropriately.
In this scenario, machine learning techniques like classification and clustering play a major role in determining potential customers as well as segmenting customers based on their common behaviours.
One popular clustering technique is K-means, that is widely used for clustering similar data points.
It is an unsupervised learning algorithm, meaning that the data on which it is applied does not have any labels and does not possess an input-output mapping. Some of the various ways in which customer segmentation helps the banking institutions are –
- Identification of customers based on their profitability.
- Segmenting customers based on their usage of banking services.
- Strengthening relationships with their customers.
- Providing appropriate schemes and services that appeal to specific customers.
- Analyzing customer segments to implement and improve services.
5. Recommendation Engines
Providing customized experiences to clients is one of the major roles that a bank plays. Based on customer transactions and personal information to suggest offers and extended services.
Banks also estimate what products the customer may be interested in buying after analyzing historical purchases. With this, banks will be able to recommend the product of the companies that have tied up with them.
It also recommends customer centric or product-centric offering based on their preferences. Banks can also recommend offers that are highly appealing to customers. There are two types of recommendation engines that are used by the banks –
- User-Based Collaborative Filtering
- Item-Based Collaborative Filtering
6. Real-Time Predictive Analytics
Predictive Analytics is the process of using computational techniques to predict future events. Machine Learning is the main toolbox of predictive analytics. Machine Learning is an ideal tool for improving the analytical strategy of the banks.
With the rapid increase in data, there is an abundance of use cases and the exigency of analyzing data is at its peak.
There are two types of major analytics techniques –
- Real-time analytics
- Predictive analytics
Real-time analytics allows customers to understand problems that impede businesses. Predictive Analytics , on the other hand, allow the customers to select the right technique to solve the problems.
There are areas like financial management of banking sectors that allow the industries to manage the finances and devise new strategies.
Explore How Data Science is Transforming the Education Sector
Data Science in Banking Case Study
How jp morgan chase uses data science.
JP Morgan Chase is one of the premier banks of the world today . It is one of the largest consumers of data with a staggering 150 petabytes of data holding about 3.5 billion users under its wing.
With such a surplus amount of data, JP Morgan makes use of the Big Data Analytics system that processes unstructured and structured data. It makes extensive use of the popular open-source platform – Hadoop.
Started your Hadoop Training? Learn Big Data and Hadoop with industry veterans
Mobile phones and internet services generate conventional structured data. This type of data is easy to handle.
However, more unconventional data like emails, customer conversations, reviews cannot process with traditional SQL tools. For this reason, Hadoop is an ideal platform for accommodating both types of data.

Some of the areas where JP Morgan Chase is using Hadoop for analyzing data are –
Fraud Detection
With an active tracking of phone calls and emails, JP Morgan Chase is monitoring for unusuality and searching for irregularities in the transactions.
Adding Value for Clients
JP Morgan Chase has been making the best use of the internet platform and digitization. It offers its customers deep insights about their businesses.
JP Morgan uses Big Data to analyze and process customer queries, provides them with cash forecasting, incrementing their turnover and benchmarking their performance against other competitors
You must read about – Latest Big Data Trends
Effective Cash Management
Cash Management is an important concern of customers. Clients want their cash to be effectively managed and be benefitted with capital protection. JP Morgan makes use of predictive analytics to forecast cash flows and provide deep insights about various existing loopholes.
Providing Insights about Trends in Credit Market
“CreditMap” is an application that provides intuitive information to the customers of JP Morgan. It makes use of Datawatch platform to provide the customers with real-time analytics.
Improving Public Economy
JP Morgan Chase is helping the US government by making tools for policy-making using Big Data. It is combining the transactions of 30 million American customers with the economic statistics of the United States.
It will use big data tools to analyze all the public information and help the policymakers to prevent financial disasters.
In the end, we conclude that data science in banking plays a major role. Banks all over the world analyze data to provide better experiences to their customers. There are several key areas like Fraud Detection, Risk Modeling, Customer Lifetime Value, Real-Time Predictive Analytics etc.
Furthermore, we understood how premier banking institutions like JP Morgan Chase are using data science to improve their client experience.
Hope you gathered a good experience of reading this blog. Share your valuable feedback through comments, it means a lot for us.
Did you like this article? If Yes, please give DataFlair 5 Stars on Google

Tags: Data Science Applications in Banking Data science case study Data Science in Banking
- Pingbacks 0
Thank you for sharing the wonderful information.
Leave a Reply Cancel reply
Your email address will not be published. Required fields are marked *
- Data Science – Introduction
- Data Science – Pros and Cons
- Data Science – Purpose
- Data Science – Why Learn?
- Data Science – Is it Difficult to Learn?
- Data Science – Top Skills
- Data Science – Prerequisites
- Data Science – General Skills
- Data Science – Tech & Non-Tech Skill
- Data Science – Process and Tasks
- Data Science – Top Algorithms
- Data Science – Top Programming Languages
- Data Science – Role of SQL
- Data Science – Master SQL
- Data Science – Best Tools
- Data Science – Why Hire Data Scientist
- Data Science – Maths and Statistics
- Data Science – Apache Spark
- Data Science for Business
- Data Science in Agriculture
- Data Science for Weather Prediction
- Data Science – Tools for Small Business
- Data Science – Real-Life Analogies
- Data Science – Applications
- Data Science – Applications in Banking
- Data Science – Applications in Education
- Data Science – Applications in Finance
- Data Science – Applications in Healthcare
- Data Science – Applications in Movies
- Data Science – Use Cases
- Data Science – Use Cases in Retail
- Data Science – Predictive Modeling
- Data Science – K-means Clustering
- Data Science – Bayes’ Theorem
- Data Science – Future
- Data Science – Top Trends
- Data Science – Books
- R for Data Science
- Machine Learning for Data Science
- Hadoop for Data Science
- SAS for Data Science
- R vs Python for Data Science
- R vs Python vs SAS for Data Science
- Data Science – NLP
- Transfer Learning for Deep Learning with CNN
- Data Science Vs Big Data
- Data Science Vs Artificial Intelligence
- Data Science Vs Machine Learning
- Data Science Vs Business Intelligence
- Data Scientist Vs Data Analyst
- Data Scientist Vs Business Analyst
- Data Scientist Vs Data Engineer vs Data Analyst
- Data Science and Data Mining
- Infographic – Data Science Vs Data Analytics
- Data Science in Digital Marketing
- Data Science Case Studies
- Case Study – Data Science at Netflix
- Case Study – Data Science at Flipkart
- Case Study – Data Science at Twitter
- Case Study – Data Science at Facebook
- Data Science – Portfolio
- Data Science – Top Jobs
- Data Science – Salary & Job trends
- Data Science – Get Your First Job
- Data Science – Scope in India
- Data Science – Demand Predictions for 2020
- Data Science – Certifications
- Steps to Become a Data Scientist
- Become Data Scientist without a Degree
- Why Data Science is in Demand?
- How to Make Career in Data Science
- Jobs in Data Science
- Infographic – How to Become Data Scientist
- Data Science – Projects
- Data Science – Project Ideas
- 70+ Project Ideas & Datasets
- Data Science Project – Sentiment Analysis
- Data Science Project – Uber Data Analysis
- Data Science Project – Credit Card Fraud Detection
- Data Science Project – Movie Recommendation System
- Data Science Project – Customer Segmentation
- Data Science – Interview Preparation
- Data Science Interview Que.Part 1
- Data Science Interview Que.Part 2

JP Morgan interview (41 real questions, process, and prep)

Today we’re going to show you what to expect during JP Morgan interviews, and what you should do to prepare .
The information in this guide is based on an analysis of over 100 JP Morgan interview reports (from real candidates for analyst roles), which were recorded between 2016-2021.
And here’s one of the first things you’ll want to know:
JP Morgan heavily emphasizes “behavioral” questions (as do Goldman Sachs and Morgan Stanley ). So, if you want to prioritize your preparation, then you’ll want to pay close attention to the questions section below.
Let’s get started.
- Process and timeline
- Behavioral questions
- Business sense questions
- Technical questions
- How to prepare
1. Interview process and timeline
Want to get more interviews click here for a 1-to-1 resume review with an ex-investment banker from jp morgan, goldman sachs,etc.
Here we’ll cover what you can expect at each stage of JP Morgan's application process. In this article, we’ll focus primarily on investment banking (IBD) roles, but the below process likely has some overlap with the steps for other roles.
The interview process at JP Morgan typically takes around 4 weeks to complete, but it can often take 2 months or even longer, so be prepared for an extensive process.
Let’s begin with an overview of each step you’ll encounter, then we’ll dig deeper into each one.
1.1 What interviews to expect
Whether applying for a full-time position or an internship program, JP Morgan candidates will typically go through 4 steps:
- Application and resume
- Pymetrics test (~30min)
- HireVue interview (~20min )
- Final-round interviews / Super day
1.1.1 Application and resume
There are three main ways that the JP Morgan interview process will begin:
- You’ll apply on their website
- You’ll apply through an event or career fair
- A recruiter will reach out to you
Regardless of which of these starts your application journey, you’ll want to be ready with a polished resume that is targeted to JP Morgan.
If you'd like expert feedback on your resume, you can get help from our team of ex-investment bankers , who will cover what achievements to focus on (or ignore), how to fine tune your bullet points, and more.
It’s also important to spend some time learning about the specific division within JP Morgan where you intend to apply. If you don’t have a clear perspective on the division where you want to work within the company, then this can be a red flag for recruiters.
You should also understand the teams that exist within your target division. This will demonstrate that you’re highly motivated and familiar with how the firm operates.
If you really want to get your foot in the door, another way to set yourself apart is by attending career fairs or events hosted by JP Morgan. Try to make genuine connections with people from the company. Then, when you go to apply, specifically name drop the people you’ve met in your cover letter. You could even write in a quote you heard from them, or mention what you learned from them about the company.
1.1.2 Pymetrics test
If your application meets JP Morgan’s basic requirements, you’ll receive an email to complete an online " Pymetrics " test (note: if you’re an experienced hire, expect to be invited to some video-call interviews without having to go through Pymetrics or HireVue).
The Pymetrics test aims to measure your “cognitive, social, and behavioral attributes.” It does this by giving you 12 “games” to play, each taking a couple of minutes to complete. You’ll be assessed on 90 different character traits , and afterwards you’ll receive a report on what your natural strengths and talents are.
As soon as you’ve completed the Pymetrics test, regardless of your performance, you’ll receive an email inviting you to the next stage: the HireVue interview.
Be aware that once you take the Pymetrics test, you can’t take it again for another year. If you apply to another company and they also use Pymetrics, they’ll be given your score from the test you’ve already taken.
1.1.3 HireVue video interview
Soon after you’ve taken the Pymetrics test, you’ll receive an email inviting you to a HireVue video interview. We've actually written a detailed guide on this topic, so feel free to check out our JPM Hirevue interview guide . We'll also provide a summary of Hirevue below:
HireVue is a digital tool that allows you to record your responses to a series of interview questions, without having an interviewer on the other side of the camera. You’ll be asked 3-5 questions during the interview. For each question, you’ll have a few moments to prepare your answer, and then you’ll have a time limit of 2-3 minutes to give your answer on camera.
You’ll only be allowed one opportunity to re-record each answer, so we’d recommend preparing answers to common questions in advance. You can get started with the example questions listed later in this article. You can also take unlimited practice questions within HireVue before starting your actual interview, which we strongly encourage you to do.
Most JP Morgan candidates say they faced the following types of questions in the Hirevue:
- One question about their motivations (e.g “Why JP Morgan?” or “Why investment banking?”)
- One behavioral question (e.g “Provide an example of when you sought out relevant information and used it to develop a plan of action”)
- One question about current economic affairs (e.g "What business deal in the news has interested you recently?”).
We'll go deeper into the questions you'll face in section 2.
1.1.4 Final-round interviews / Super Day
If you do well enough in the Pymetrics test and HireVue interview, you’ll be invited to a final round of interviews.
For entry level positions at the firm (internships and graduate hires) this may take the form of a “Super Day” (or Assessment Centre in the UK). This is where a large number of candidates spend the day interviewing at a JP Morgan office or a conference center, although due to COVID-19 this is now normally done on Zoom. Each interview should last around 30 minutes, and you'll face at least two interviewers in each.
If you’re a more experienced hire, you probably won’t be invited to a Super Day. Instead, your final-round interview will consist of at least 3 back-to-back interviews with JP Morgan team members of varying seniority. Each interview should last around 30 minutes.
Now that you know what to expect from the interview process, let's take a look at the kind of questions you'll need to answer.
2. Question types
During the interview process at JP Morgan, you’ll face the following question types:
- Behavioral
- Business sense
However, some of these questions are asked more frequently than others. Here’s a summary of the data:

As you can see, behavioral questions are by far the most common, so we’ll cover that category next.
Below, we’ve curated a list of practice questions for each question type.
Note: The questions below were originally posted on Glassdoor , but we have improved the grammar or phrasing in some places to make them easier to understand.
2.1 Behavioral questions [69% of questions]
Behavioral questions focus on your motivation for applying to the position, your resume, and scenario based questions (e.g. “Tell me about a time…”).
Below is a list of behavioral interview questions that have been asked in JP Morgan investment banking interviews in the last few years. These are excellent questions to practice with because many of the same questions tend to come up repeatedly.
You’ll want to pay special attention to the first three questions (bolded below), because they are extremely common. You should definitely have an answer prepared for each of them before your interview. For a complete list of practice questions, including sample answers and an answer framework, take a look at our guide to JP Morgan behavioral interview questions .
Example behavioral questions at JP Morgan
Why do you want to work in investment banking?
Why JP Morgan?
Tell me about yourself
Walk me through your resume
What's your career plan within five years?
Why are you a good fit for this position?
What’s one of your biggest weaknesses?
What is the biggest challenge you have faced, and how has that made you a better person?
Tell me about a recent achievement
Tell me about a time you worked in a team
What would your co-workers say about you?
Provide an example on when you sought out relevant information and used it to develop a plan of action
Tell me about a time when you encountered a difficult client and describe how you handled the situation
Tell me about a time during which you had a positive impact on a project, and how did you measure your success?
Name a time you had to make a quick decision, then describe your thought process and what the final decision was
Make a sales pitch for something you're interested in
2.2 Business sense [19% of questions]
The second type of questions you can expect to encounter during your JP Morgan interviews are business sense questions.
These questions cover a few different areas, but generally, these questions will be focused on assessing your industry knowledge and critical thinking skills.
To make it easier to organize your practice time, we’ve grouped the below questions into a few subcategories. You should be prepared to answer questions from each subcategory. And you can also learn more about this type of question in our separate business sense questions guide .
Example business sense questions asked at JP Morgan
- Tell us about a recent news story and why it sparked your attention
What is going on in the current market right now that has interested you and why?
What is the biggest challenge facing the financial market in the next 5 years?
What current issues will affect the sustainability of investments in future
How will the bond market react to the interest rate drop?
- What's your view on the European debt crises?
- What do you know about public finance?
- What deals has our group done that you liked and why?
- Tell me about a recent deal you've been paying attention to
3. Industry
What makes JP Morgan different from other banks and the financial industry as a whole?
What's the biggest threat to J.P. Morgan?
4. Investing
How would you compare X company with Y company (e.g. GE and GM)?
What interests you about IPO's?
- How many coins would fit in this room?
- How many cigarettes are sold in the US each year?
2.3 Technical questions [12% of questions]
Technical questions help your interviewers evaluate whether you have the knowledge and skills to perform on-the-job tasks.
These technical questions can be split into two main categories:
Valuation questions at JP Morgan focus on your ability to calculate the value of a business and your familiarity with DCFs, whereas accounting questions focus on your knowledge of financial statements and accounting principles. Valuation questions tend to be asked more frequently, but you should prepare for both.
Below is a list of example questions from each category for you to practice with. The questions in bold are extremely common, so you should have a strong answer prepared for them.
You can learn more about common technical questions in our technical questions guide , and you can also find helpful summaries in our investment banking interview cheat sheet .
Example technical questions asked at JP Morgan
1. Valuation
- Walk me through a DCF
- What are the ways to work out a company's value?
- Talk to me about some leverage ratios you may use to value the risk on the company's balance sheet
- Value Airbnb using DCF, LBO, and Comps
- When would you not use a DCF to evaluate a company?
- How would a DCF change for a company in the biotechnology space?
- How do interest rate changes transmit to corporate balance sheets?
- Walk me through a depreciation expense, in year 0 and then in year 1, of a $100,000 purchase of a building
- A shoemaker in New York makes shoes for his clients. Give me your scenario of his balance sheet this season. Now link his balance sheet, income statement, and cash flows together.
3. How to prepare
Before you spend weeks (or months) preparing for JP Morgan interviews, you should pause for a moment to learn about the company’s culture.
This is important for two reasons.
First, it will help you to clarify whether JP Morgan is actually the right fit for you. JP Morgan is prestigious, so it can be tempting to apply without thinking more deeply. But, it's important to remember that the prestige of a job (by itself) won't make you happy in your day-to-day work. It's the type of work and the people you work with that will.
Second, having a clear understanding of JP Morgan’s culture will give you an edge in your interviews, because it will help you frame your skills and experiences to align with what the company values. In addition, you will almost definitely be asked about your specific motivations for applying to JP Morgan.
If you know any current or former JP Morgan employees, see if you can chat with them about the company’s culture for a few minutes. In addition, we would recommend checking out the following resources:
- Who we are (By JP Morgan)
- JP Morgan weekly brief (By JP Morgan)
- JP Morgan strategy teardown (by CB Insights)
Looking for more tips on how to set yourself apart in an investment banking interview? Take a look at our list of 15 essential IB interview tips .
3.2 Practice by yourself
As we mentioned above, you’ll face 3 main types of questions in your JP Morgan interviews: behavioral, technical, and business sense questions.
And you’re going to want to do specific preparation for each question type.
3.2.1 For behavioral questions
For behavioral questions, we recommend that you use a repeatable method for delivering your answers. You may have heard of the STAR method before, but we recommend a slightly different approach, which is explained in this guide .
Once you’ve learned a method for structuring your answers, we recommend that you practice answering all of the example questions we provided above, especially the first four questions in the list.
It’s best to rehearse the answers to these questions out loud, so that you’ll get comfortable giving good, concise answers. It may feel weird to practice answering questions out loud without an interviewer across from you. But trust us, this will dramatically improve how you communicate your answers.
In addition, it’s helpful to prepare a few “stories” that highlight your past experiences and accomplishments, so that you have examples to use for unexpected interview questions. For example, if you have a good example of a time you handled a team conflict, rehearse this story, and you could potentially use it for a variety of different questions during your interviews.
3.2.2 For business sense questions
For business sense questions, there are a few different areas you’ll need to cover.
First, it’s important for you to be up to speed on current events related to JP Morgan, the investment banking industry, and the broader economy.
To help you stay current, we recommend developing a habit of reading the Investment Banking section of the Financial Times, which will give you the main news from the industry as well as frequent stories specifically on JP Morgan. For broader economic news, you can use your favorite news publication. If you don’t have one, consider giving The Economist a try.
To take this a step further, it’s a good exercise to “quiz” yourself on these current events by reframing them in the form of a question. For example, if you read a story about an M&A deal, ask yourself something like: “Is this really a good deal? Why?” We’d recommend that you analyze and develop an opinion on at least a couple of recent deals, because it’s likely to be useful during your interviews.
Finally, JP Morgan very occasionally also asks “estimation” questions, which test your math and critical thinking skills. This would be something like “how many golf balls would fit in a one gallon milk jug?” To prepare for this type of question, we recommend learning the approach covered in this market sizing guide .
And of course, practicing the above example questions (out loud) will go a long way in preparing you for your interviews.
3.2.3 For technical questions
For technical questions, we recommend that you start by brushing up on the key valuation and accounting concepts used in investment banking.
For valuation, we recommend reading Street of Wall’s valuation overview guide .
And for accounting concepts, we recommend using this free guide as a quick refresher. Then, you can study accounting topics more deeply with this free course .
Once you’ve refreshed your memory on the fundamental concepts, then go ahead and practice with the technical questions we’ve provided above. Again, we’d recommend that you practice answering questions out loud, because this more closely replicates the conditions of a real interview.
3.3 Practice with peers
Practicing by yourself is a critical step, but it will only take you so far.
One of the main challenges of interviewing at JP Morgan is communicating your answers in a way that is clear and leaves a strong impression.
As a result, we recommend that you also do some mock interviews. This is much closer to the real interview experience. Plus, the feedback you get from an interview partner could help you avoid mistakes that you wouldn’t notice on your own.
You can practice with a friend or family member to start. This will help you polish your “stories” and catch communication mistakes. However, if your interview partner isn’t familiar with investment banking interviews, then practicing with an ex-interviewer will give you an extra edge.
3.4 Practice with ex-interviewers
I f you know someone who runs interviews at JP Morgan or another investment bank, then that’s amazing! They would be a great person to give you interview feedback.
But most of us don’t, and it can be REALLY tough to make a new connection with an investment banker. And even if you do have a good connection already, it might also be difficult to practice multiple hours with that person unless you know them extremely well.
Here's the good news. We want to help you make these connections. That’s why we've launched a coaching platform where you can find ex-interviewers at JP Morgan to practice with. Learn more and start scheduling sessions today .
Related articles:

Get the Reddit app
All about studying and students of computer science.
JP Morgan AI/Data Science Summer Analyst 2023
For those of you that applied, what was your experience/Timeline?
How long after OA did you have to prepare for next interview.
Did you get ghosted after OA?
Any other info is greatly appreciated!
By continuing, you agree to our User Agreement and acknowledge that you understand the Privacy Policy .
Enter the 6-digit code from your authenticator app
You’ve set up two-factor authentication for this account.
Enter a 6-digit backup code
Create your username and password.
Reddit is anonymous, so your username is what you’ll go by here. Choose wisely—because once you get a name, you can’t change it.
Reset your password
Enter your email address or username and we’ll send you a link to reset your password
Check your inbox
An email with a link to reset your password was sent to the email address associated with your account
Choose a Reddit account to continue

J.P Morgan – COiN – a Case Study of AI in Finance
Back to front: the vision.
AI in Finance takes center stage as organizations understand that success hinges on embracing thought leaders who embody the organization’s vision, values, and responsibilities. This commitment manifests in cost reduction, operational efficiency enhancement, and improved customer experiences. In 2016, JP Morgan Chase recognized the potential of AI to unlock new capabilities for the firm, its clients, and its customers. To explore and implement diverse AI use cases across the organization, they established a Center of Excellence within Intelligent Solutions . This begs the question: What necessitated this imperative, and what were the driving factors?
Building Solutions: COiN (Contract Intelligence)
AI in Finance has revolutionized JP Morgan’s operations, reducing the time spent on tasks like interpreting business credit agreements from 360,000 hours annually to mere seconds. Through its AI-driven Contract Intelligence platform , known as COiN, the bank has automated the document review process for a specific category of contracts. COiN utilizes unassisted AI, minimizing human involvement post-deployment. Powered by a private cloud network, the AI system employs image recognition to compare and identify different clauses. In its initial implementation, COiN extracted approximately 150 relevant attributes from annual business credit agreements within seconds, eliminating the need for 360,000 manual review hours. The algorithm identifies patterns based on terms or locations in the contracts, resulting in significant time and cost savings while improving efficiency and reducing errors. Let’s delve into the successful strategies behind COiN’s implementation.
At the Core: The Strategy Takeaways
At the core of the achievement of COiN has been interest in innovation, and building a solid center group that gets innovation.
Recruiting the Best
JP Morgan has attracted top AI talent worldwide, including Manuela Veloso and Tucker Balch, to lead their AI research . They prioritize collaboration with existing data analysis and research teams while fostering partnerships with universities and research institutions. Their goal is to combine human qualities with new processes to ensure unbiased outputs. When hiring, they seek individuals passionate about automation, ethics, values, and visionary thinking. The company’s significant investment in technology, with a budget of 9% of projected revenue in 2017, double the industry average, reinforces their commitment to research and development. They also invest in partnerships with startups and allocate resources to upskilling programs for future workforce needs. The success of COiN stems from JP Morgan’s exceptional AI team and continuous innovation investment, driving their application of cutting-edge technology. Let’s explore future challenges and opportunities.
The Dilemma and the Road Ahead
JP Morgan is actively exploring advanced applications of COiN, aiming to provide better predictive capabilities and potentially disrupt law firms in the future. As technology progresses, COiN’s algorithms can deliver more accurate initial impressions. The bank recognizes the need for workforce adaptation, with an estimated 30% of the U.S. job market and 375 million workers globally requiring job transitions and upskilling by 2030. JP Morgan has invested significantly in local education and job training programs to support individuals in securing stable employment. To remain a leader in the industry, the company embraces innovation and explores diverse solutions. Learning from the success of tech giants like JP Morgan can inspire other organizations to improve their own business strategies. Discover how JP Morgan’s approach can benefit your business.
How Your Business, Clients, and Customers can Benefit?
The whole association should be focused on streamlining new innovation to stay serious on the lookout. Here’s a depiction of some new patterns and utilizations of AI in financial that you can profit depending on the JP Morgan case.
Preview of Technology Trends in Banking
The ascent of AI and ML in the monetary business is changing the business scene. Expanding on the example of overcoming adversity of JP Morgan, it would bode well to relook at your hierarchical vision towards innovation and find a way to execute the more current innovation into your organization measures.
Influence AI in Your Digital Transformation Journey with Imaginovation Prepare to AI-power your business! We AI and Data Science organization with an encounter of creating strong AI answers for organizations, all things considered. If you’re keen on utilizing current advancements in your computerized change venture, at that point connect with us.
Advantages of machine learning in financial forecasting.

Using AI to robotize the monetary estimating measure presents a few remarkable advantages for senior money heads and their groups. The key advantages are summed up below.
1. Capacity to Produce More Accurate Forecasts, Faster
As mentioned earlier, the use of AI in finance enables automated data collection and reconciliation, freeing financial forecasting from manual efforts. AI tools can handle large datasets and identify business drivers, significantly reducing forecasting errors. These algorithms learn from data over time, improving accuracy and expediting the forecasting process. The integration of AI in finance empowers organizations to make informed predictions and optimize financial performance. By leveraging AI technology, businesses can enhance their forecasting capabilities, identify key drivers, and make data-driven decisions. Embracing AI in finance enables organizations to streamline forecasting processes, enhance accuracy, and unlock valuable insights for better financial planning. With AI-driven forecasting, businesses can stay ahead of market trends, mitigate risks, and achieve their financial goals.
2. Hedge between best and worst case scenario
With accounting page-driven gauging measures, there are cutoff points to the number of information sources and how much information can be processed and burned-through inside anticipating models. AI devices can significantly upgrade the volume and sorts of information that can be utilized on the grounds that the apparatuses can hold more information and process it quicker than people. Through this way we can have the better chance to hedge between the best and worst case scenario.
3. Empowering Value-Adding Activities
Traditional forecasting methods require analysts to spend time on data collection instead of value-added analysis and collaboration. AI solutions can generate baseline forecasts, freeing analysts from mundane tasks and enabling deeper understanding of operational drivers. By incorporating AI, analysts bring valuable insights into the forecasting process and enhance their partnership with the business. This empowers analysts to support informed decision-making and drive growth through strategic analysis.
The Emergence of AI in Finance and Accounting
Certain businesses are generally helpless to the effects of AI. The most referred to report from NPR predicts that:
- Bookkeepers have a 97.6 percent possibility of seeing their positions computerized.
- Accountants and examiners have a 93.5 percent possibility of seeing their positions mechanized.
- Financial examiners have a 23.3 percent possibility of seeing their positions mechanized.
To summarize, occupations that are comprised of repeatable, precise errands have higher danger of being mechanized than those that require judgment, examination, and relationship building abilities. Thus, in the event that your present place of employment regularly expects you to show those attributes, at that point you need not concern. For Finance and Accounting, AI and robotization are viewed as suitable answers for successfully managing consistency and danger challenges across different areas. To stay serious, organizations are moving from work exchange and seaward unrest to mechanization insurgency. Man-made intelligence speaks to an occasion to decrease the weight on money experts, especially around conventional monetary exercises, for example, exchange handling, review and consistency. These exercises in their present structure keep money from being more essential colleagues.
Maximizing Efficiency and Insight: The Role of AI in Finance
- Enhancing Financial Decision-Making with AI Technology
- Leveraging AI for Smarter Financial Operations
- The Transformative Impact of AI on Finance
In what way Might We Help You Improve Your Customer Service with an Advanced Platform?
- Build ai platform for your team
- Quick financial projections according to your double entries
- Analysis Charts and plots
- Resources to carry on this project
- Superior Data Science builds reinforcement learning agent
Through our platform, you will be able to get the forecasted financial statements including income statements, balance sheets, and cash flow statements. On these forecasts, you can have the opportunity to decide and take action. the best and worst-case scenario. Through the forecasted data organizations can take actions to create value for their investors.

Request for a Call
Collaborate with the best in the industry. Let’s talk and get your project moving.
Contact Us For Questions

Thank You for Subscribing
Chatbot Dialogflow CX Instructions

- Asia Pacific
- Latin America
- Middle East & Africa
- North America
- Australia & New Zealand
Mainland China
- Hong Kong SAR, China
- Philippines
- Taiwan, China
- Channel Islands
- Netherlands
- Switzerland
- United Kingdom
- Saudi Arabia
- South Africa
- United Arab Emirates
- United States
From startups to legacy brands, you're making your mark. We're here to help.
- Innovation Economy Fueling the success of early-stage startups, venture-backed and high-growth companies.
- Midsize Businesses Keep your company growing with custom banking solutions for middle market businesses and specialized industries.
- Large Corporations Innovative banking solutions tailored to corporations and specialized industries.
- Commercial Real Estate Capitalize on opportunities and prepare for challenges throughout the real estate cycle.
- Community Impact Banking When our communities succeed, we all succeed. Local businesses, organizations and community institutions need capital, expertise and connections to thrive.
- International Banking Power your business' global growth and operations at every stage.
- Client Stories
Prepare for future growth with customized loan services, succession planning and capital for business equipment.
- Asset Based Lending Enhance your liquidity and gain the flexibility to capitalize on growth opportunities.
- Equipment Financing Maximize working capital with flexible equipment and technology financing.
- Trade & Working Capital Experience our market-leading supply chain finance solutions that help buyers and suppliers meet their working capital, risk mitigation and cash flow objectives.
- Syndicated Financing Leverage customized loan syndication services from a dedicated resource.
- Employee Stock Ownership Plans Plan for your business’s future—and your employees’ futures too—with objective advice and financing.
Institutional Investing
Serving the world's largest corporate clients and institutional investors, we support the entire investment cycle with market-leading research, analytics, execution and investor services.
- Institutional Investors We put our long-tenured investment teams on the line to earn the trust of institutional investors.
- Markets Direct access to market leading liquidity harnessed through world-class research, tools, data and analytics.
- Prime Services Helping hedge funds, asset managers and institutional investors meet the demands of a rapidly evolving market.
- Global Research Leveraging cutting-edge technology and innovative tools to bring clients industry-leading analysis and investment advice.
- Securities Services Helping institutional investors, traditional and alternative asset and fund managers, broker dealers and equity issuers meet the demands of changing markets.
- Financial Professionals
- Liquidity Investors
Providing investment banking solutions, including mergers and acquisitions, capital raising and risk management, for a broad range of corporations, institutions and governments.
- Center for Carbon Transition J.P. Morgan’s center of excellence that provides clients the data and firmwide expertise needed to navigate the challenges of transitioning to a low-carbon future.
- Corporate Finance Advisory Corporate Finance Advisory (“CFA”) is a global, multi-disciplinary solutions team specializing in structured M&A and capital markets. Learn more.
- Development Finance Institution Financing opportunities with anticipated development impact in emerging economies.
- Sustainable Solutions Offering ESG-related advisory and coordinating the firm's EMEA coverage of clients in emerging green economy sectors.
- Mergers and Acquisitions Bespoke M&A solutions on a global scale.
- Capital Markets Holistic coverage across capital markets.
- Capital Connect
- In Context Newsletter from J.P. Morgan
- Director Advisory Services
Accept Payments
Explore blockchain, client service, process payments, manage funds, safeguard information, banking-as-a-service, send payments.
- Partner Network
A uniquely elevated private banking experience shaped around you.
- Banking We have extensive personal and business banking resources that are fine-tuned to your specific needs.
- Investing We deliver tailored investing guidance and access to unique investment opportunities from world-class specialists.
- Lending We take a strategic approach to lending, working with you to craft the fight financing solutions matched to your goals.
- Planning No matter where you are in your life, or how complex your needs might be, we’re ready to provide a tailored approach to helping your reach your goals.
Whether you want to invest on your own or work with an advisor to design a personalized investment strategy, we have opportunities for every investor.
- Invest on your own Unlimited $0 commission-free online stock, ETF and options trades with access to powerful tools to research, trade and manage your investments.
- Work with our advisors When you work with our advisors, you'll get a personalized financial strategy and investment portfolio built around your unique goals-backed by our industry-leading expertise.
- Expertise for Substantial Wealth Our Wealth Advisors & Wealth Partners leverage their experience and robust firm resources to deliver highly-personalized, comprehensive solutions across Banking, Lending, Investing, and Wealth Planning.
- Why Wealth Management?
- Retirement Calculators
- Market Commentary
Who We Serve
INDUSTRIES WE SERVE
Explore a variety of insights.
- Global Research
- Newsletters
Insights by Topic
Explore a variety of insights organized by different topics.
Insights by Type
Explore a variety of insights organized by different types of content and media.
- All Insights
We aim to be the most respected financial services firm in the world, serving corporations and individuals in more than 100 countries.
Artificial Intelligence Research
The goal of our AI Research program is to explore and advance cutting-edge research in the fields of AI and Machine Learning, as well as related fields like Cryptography, to develop solutions that are most impactful to the firm’s clients and businesses.

Research Publications
See some of the latest research we publish each year and present at a range of conferences, journals, and workshops.

AI Research Awards Program
Our global firm is committed to building partnerships and relationships with the best-in-class universities, students and researchers through its Faculty Research Awards and PhD Fellowships.

Careers in AI Research
Conducting AI research in financial services offers unique and exciting opportunities for impact. As a member of this highly visible team, you will have the opportunity to realize significant impact not only within the firm but also to the broader AI community.
Initiatives
Learn more about some of our unique initiatives including our financial synthetic datasets, our explainable ai center of excellence, our algocrypt center of excellence, and learn from global ai experts..
Synthetic Data
Explainable AI Center of Excellence
AlgoCRYPT Center of Excellence
AIgoCRYPT Center of Excellence (CoE) to lead cutting-edge research in cryptography and secure distributed (AI) computation
Distinguished Lecture Series on AI
You're now leaving J.P. Morgan
J.P. Morgan’s website and/or mobile terms, privacy and security policies don’t apply to the site or app you're about to visit. Please review its terms, privacy and security policies to see how they apply to you. J.P. Morgan isn’t responsible for (and doesn’t provide) any products, services or content at this third-party site or app, except for products and services that explicitly carry the J.P. Morgan name.
- Open access
- Published: 07 August 2024
Impact of neonatal sepsis on neurocognitive outcomes: a systematic review and meta-analysis
- Wei Jie Ong ORCID: orcid.org/0000-0001-8244-2977 1 na1 ,
- Jun Jie Benjamin Seng ORCID: orcid.org/0000-0002-3039-3816 1 , 2 , 3 na1 ,
- Beijun Yap 1 ,
- George He 4 ,
- Nooriyah Aliasgar Moochhala 4 ,
- Chen Lin Ng 1 ,
- Rehena Ganguly ORCID: orcid.org/0000-0001-9347-5571 5 ,
- Jan Hau Lee ORCID: orcid.org/0000-0002-8430-4217 6 &
- Shu-Ling Chong ORCID: orcid.org/0000-0003-4647-0019 7
BMC Pediatrics volume 24 , Article number: 505 ( 2024 ) Cite this article
150 Accesses
1 Altmetric
Metrics details
Introduction
Sepsis is associated with neurocognitive impairment among preterm neonates but less is known about term neonates with sepsis. This systematic review and meta-analysis aims to provide an update of neurocognitive outcomes including cognitive delay, visual impairment, auditory impairment, and cerebral palsy, among neonates with sepsis.
We performed a systematic review of PubMed, Embase, CENTRAL and Web of Science for eligible studies published between January 2011 and March 2023. We included case–control, cohort studies and cross-sectional studies. Case reports and articles not in English language were excluded. Using the adjusted estimates, we performed random effects model meta-analysis to evaluate the risk of developing neurocognitive impairment among neonates with sepsis.
Of 7,909 studies, 24 studies ( n = 121,645) were included. Majority of studies were conducted in the United States ( n = 7, 29.2%), and all studies were performed among neonates. 17 (70.8%) studies provided follow-up till 30 months. Sepsis was associated with increased risk of cognitive delay [adjusted odds ratio, aOR 1.14 (95% CI: 1.01—1.28)], visual impairment [aOR 2.57 (95%CI: 1.14- 5.82)], hearing impairment [aOR 1.70 (95% CI: 1.02–2.81)] and cerebral palsy [aOR 2.48 (95% CI: 1.03–5.99)].
Neonates surviving sepsis are at a higher risk of poorer neurodevelopment. Current evidence is limited by significant heterogeneity across studies, lack of data related to long-term neurodevelopmental outcomes and term infants.
Peer Review reports
Sepsis is a major cause of mortality and morbidity among neonates [ 1 , 2 , 3 , 4 ]. Young infants especially neonates, defined by age < 28 days old, have a relatively immature immune system and are susceptible to sepsis [ 5 , 6 ]. Annually, there are an estimated 1.3 to 3.9 million cases of infantile sepsis worldwide and up to 700,000 deaths [ 7 ]. Low-income and middle-income countries bear a disproportionate burden of neonatal sepsis cases and deaths [ 7 , 8 ]. While advances in medical care over the past decade have reduced mortality, neonates who survive sepsis are at risk of developing neurocognitive complications, which affect the quality of life for these children and their caregivers [ 9 ].
Previous reviews evaluating neurocognitive outcomes in neonates with infections or sepsis have focused on specific types of pathogens (e.g., Group B streptococcus or nosocomial infections [ 10 ]), or are limited to specific populations such as very low birth weight or very preterm neonates [ 11 ], and there remains paucity of data regarding neurocognitive outcomes among term and post-term neonates. There remains a gap for an updated comprehensive review which is not limited by type of pathogen or gestation. In this systematic review, we aim to provide a comprehensive update to the current literature on the association between sepsis and the following adverse neurocognitive outcomes (1) mental and psychomotor delay (cognitive delay (CD)), (2) visual impairment, (3) auditory impairment and (4) cerebral palsy (CP) among neonates [ 11 ].
We performed a systematic review using the Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) 2020 guidelines [ 12 ]. This study protocol was registered with Open Science Framework ( https://doi.org/10.17605/OSF.IO/B54SE ).
Eligibility criteria
We identified studies which evaluated neurocognitive outcomes in neonates less than 90 days old (regardless of gestational age) with sepsis. While the neonatal period is traditionally defined to be either the first 28 days postnatally for term and post-term infants, or 27 days after the expected date of delivery for preterm infants [ 13 ], serious late onset infections in the young infant population can present beyond the neonatal period [ 14 ], hence we defined the upper age limit as 90 days old to obtain a more complete picture of the burden of young infantile sepsis [ 15 ]. Post-term neonates was defined as a neonate delivered at > = 42 weeks of gestational age in this study [ 16 ]. We included studies that either follow international sepsis definitions such as Surviving Sepsis Campaign guidelines definitions [ 17 ], or if they fulfilled clinical, microbiological and/or biochemical criteria for sepsis as defined by study authors. The primary outcome of interest was impaired neurocognitive outcome defined by the following domains of neurodevelopmental impairment (NDI) [ 11 ]: (1) CD, (2) visual impairment, (3) auditory impairment and (4) CP. We selected these domains because they were highlighted as key neurocognitive sequelae after intrauterine insults in a landmark review by Mwaniki et al. [ 18 ]. The authors’ definitions of these outcomes and their assessment tools were captured, including the use of common validated instruments (e.g., a common scale used for CD is the Bayley Scales of Infant Development (BSID) [ 19 ] while a common instrument used for CP was the Gross Motor Function Classification System (GMFCS) [ 20 ]. Specifically for BSID, its two summative indices score – Mental Development Index (MDI) and Psychomotor Development Index (PDI) were collected. The MDI assesses both the non-verbal cognitive and language skills, while PDI assess the combination of fine and gross motor skills. The cut-off points for mild, moderate and severe delay for MDI and PDI were < 85 or < 80, < 70 and < 55 respectively [ 21 ]. There were no restrictions on duration of follow-up or time of assessment of neurocognitive outcomes to allow capturing of both short- and long-term neurocognitive outcomes.
Case–control, cohort studies and cross-sectional studies published between January 2011 and March 2023 were included. Because the definition and management of sepsis has evolved over the years [ 22 ], we chose to include studies published from 2011 onwards. Case reports, animal studies, laboratory studies and publications that were not in English language were excluded. Hand-searching of previous systematic reviews were performed to ensure all relevant articles were included. To avoid small study effects, we also excluded studies with a sample size of less than 50 [ 23 ].
Information sources and search strategy
Four databases (PubMed, Cochrane Central, Embase and Web of Science) were used to identify eligible studies. The search strategy was developed in consultation with a research librarian. The first search was conducted on 4 December 2021 and an updated search was conducted on 3 April 2023. The detailed search strategy can be found in Supplementary Tables 1A and B.
Study selection process
Covidence systematic review software (Veritas Health Innovation, Melbourne, Australia) [ 24 ] was utilized during this review. Five reviewers (WJO, BJY, NM, CLN and GH) independently conducted the database search and screened the title and abstracts for relevance. Following training on inclusion and exclusion eligibility, 4 reviewers (WJO, NM, CLN and GH) subsequently assessed the full text of shortlisted articles for eligibility. All full texts were independently assessed by at least 2 reviewers. Any conflict related to study eligibility were resolved in discussion with the senior author (S-LC). We recorded the reason(s) for exclusion of each non-eligible article.
Data collection process and data items
Four reviewers (WJO, NM, CLN and GH) independently carried out the data extraction using a standardized data collection form, and any conflict was resolved by discussion, or with input from the senior author (S-LC). A pilot search was performed for the first 200 citations to evaluate concordance among reviewers and showed good concordance among reviewers of 94%. For studies with missing data required for data collection or meta-analyses, we contacted the corresponding authors of articles to seek related information. If there was no reply from the authors, the data were labelled as missing.
Study risk of bias assessment
Three reviewers (BJY, GH and WJO) independently carried out the assessment of risk of bias using the Newcastle–Ottawa Scale (NOS) for all observational studies [ 25 ]. Studies were graded based on three domains namely, selection, comparability and outcomes. Studies were assigned as low, moderate and high risk of bias if they were rated 0–2 points, 3–5 points and 6–9 points respectively. Any conflict was resolved by discussion or with input from the senior author (S-LC).
Statistical analysis
All outcomes (i.e. CD, visual impairment, auditory impairment and CP) were analysed as categorical data. Analyses were done for each NDI domain separately. To ensure comparability across scales, results from different studies were only pooled if the same measurement tools were used to assess the outcomes and hence sub-group analyses were based on different scales and/or different definitions of neurocognitive outcomes used by authors. Both unadjusted and adjusted odds ratios (aOR) and/or relative risk (RR) for each NDI domain were recorded. Where source data were present, we calculated the unadjusted OR if the authors did not report one, together with the 95% confidence interval (CI). For adjusted odds ratio, these were extracted from individual studies and variables used for adjustment were determined at the individual study level.
Meta-analysis was conducted for all outcomes that were reported by at least 2 independent studies or cohorts. Studies were included in the meta-analysis only if they reported outcomes for individual NDI domains within 30 months from sepsis occurrence. For each domain, all selected studies were pooled using DerSimonian-Laird random effects model due to expected heterogeneity. Studies were pooled based on adjusted and unadjusted analyses. Case–control and cohort studies were pooled separately. The pooled results were expressed as unadjusted odds ratio (OR) or adjusted odds ratio (aOR) with corresponding 95% confidence interval (95% CI). If there was more than 1 study that utilized the same population, we only analysed data from the most recent publication or from the larger sample size, to avoid double counting. Standard error (SE) from studies with multiple arms with same control group were adjusted using SE = √(K/2), where K refers to number of treatment arms including control [ 26 ]. Heterogeneity across studies was evaluated using the I^2 statistic, for which ≥ 50% is indicative of significant heterogeneity. With regards to publication bias, this was performed using Egger’s test and funnel plots only if the number of studies pooled were 10 or more for each outcome.
For neurocognitive related outcomes, subgroup analyses were performed based on the severity of the NDI domain outcomes and distinct, non-overlapping populations of septic infants (such as late onset vs early onset sepsis, culture positive sepsis vs clinically diagnosed sepsis, term and post term patients).
All analyses were done using ‘meta’ library from R software (version 4.2.2) [ 27 ]. The statistical significance threshold was a two tailed P- value < 0.05.
Certainty of evidence
The certainty of evidence for outcomes in this review was performed during the GRADE criteria [ 28 ] which is centred on the study design, risk of bias, inconsistency, indirectness, imprecision, and other considerations.
Study selection
From 7,909 studies identified, a total of 24 articles were included (Fig. 1 ) [ 29 , 30 , 31 , 32 , 33 , 34 , 35 , 36 , 37 , 38 , 39 , 40 , 41 , 42 , 43 , 44 , 45 , 46 , 47 , 48 , 49 , 50 , 51 , 52 ]. A total of 101,657 and 19,988 preterm and term infants were included in this review.

PRISMA flowchart of the study selection process for search
Study characteristics
There were 2 case–control studies and 22 cohort studies, with a total of 121,645 infants (Table 1 ). Studies were conducted in 16 different countries (Fig. 2 ), with the most studies conducted in the United States of America (USA) (7 studies, n = 92,358 patients) [ 30 , 33 , 37 , 41 , 42 , 47 , 52 ]. There were no studies that were conducted solely on term infants. 5 studies reported data specifically on ELBW infants (27,078 infants) and 6 studies on VLBW infants (3,322 infants). All studies were performed among neonates.

World map depicting distribution of studies that evaluate neurocognitive outcomes in infantile and neonatal sepsis
Risk of bias
Overall, all 24 studies were classified as low risk (Supplementary Table 2). 5 papers scored high risk for outcome bias for having greater than 10% of initial population being lost to follow-up [ 29 , 32 , 40 , 41 , 42 ].
Outcome measures reported by domain
As the number of studies pooled for each outcome was less than 10, publication bias was not analysed in the meta-analyses.
Cognitive delay (CD)
Among 24 studies that assessed for CD, 16 studies reported either the incidence of CD among young infants with sepsis compared to those without, and/or the odds ratio (adjusted and/or unadjusted) comparing the two populations [ 29 , 31 , 32 , 33 , 34 , 35 , 36 , 37 , 38 , 40 , 41 , 42 , 45 , 46 , 48 , 49 ]. The scales used, authors’ definition of CD, incidence of CD among those with sepsis and those without are described in Table 2 . The most common tools used for assessment of CD were the Bayley Scales of Infant Development (BSID) ( n = 13) and Denver Development Screening Test II ( n = 2).
Infantile sepsis was associated with increased risk of overall CD delays [aOR 1.14 (95%CI: 1.01, 1.28)], overall PDI delay (aOR 1.73 (95%CI: 1.16, 2.58)) and moderate PDI delay [aOR 1.85 (95%CI: 1.01, 3.36)]. Conversely, infantile sepsis was not associated with increased risk for severe PDI delay nor overall MDI delay [aOR 1.30 (95%CI: 0.99, 1.71)] or its subgroups. There were no significant differences in outcomes between different subgroups of infections as well as culture-proven or clinically defined sepsis for either MDI or PDI (Table 8 , Fig. 3 A and B).

A Forest plot on adjusted odds ratios for neurocognitive outcomes related to MDI, PDI, visual impairment, hearing impairment and cerebral palsy. B Forest plot on unadjusted odds ratios for neurocognitive outcomes related to MDI, PDI, visual impairment, hearing impairment and cerebral palsy. Legend: MDI: Mental Developmental Index; PDI: Psychomotor Developmental Index. Foot note: Mild MDI or PDI: < 85 or < 80; Moderate MDI or PDI < 70; Severe MDI or PDI < 55
Visual impairment
Seven studies reported data on visual impairment (Table 3 ) [ 31 , 33 , 41 , 42 , 47 , 49 ]. The most common definition of visual impairment utilized was “visual acuity of < 20/200” ( n = 4, 66.7%).
In the meta-analysis, infantile sepsis was associated with significantly increased risk of visual impairment [aOR 2.57 (95%CI: 1.14, 5.82)] but there were no statistically significant differences in visual impairment between subgroups of early or late onset sepsis, and blood culture negative conditions as compared to the non-septic population (Table 8 , Fig. 3 A and B).
Hearing impairment
Seven studies reported data on hearing impairment (Table 4 ) [ 31 , 33 , 41 , 42 , 47 , 49 ]. Two studies defined hearing impairment as permanent hearing loss affecting communication with or without amplification [ 42 , 47 ]. Other definitions included “sensorineural hearing loss requiring amplification” ( n = 1), “bilateral hearing impairment with no functional hearing (with or without amplification)” ( n = 1), “clinical hearing loss” ( n = 1).
In the meta-analysis, sepsis was associated with increased risk of hearing impairment [aOR 1.70 (95% CI: 1.02–2.81)]. However, in the subgroup analyses, there were no differences in risk of hearing impairment between patients with late onset sepsis as compared to the non-septic population (Table 8 , Fig. 3 A and B).
Cerebral palsy
Nine studies [ 29 , 32 , 33 , 41 , 42 , 47 , 48 , 49 , 50 ] reported data on CP (Table 5 ), of which 5 studies [ 41 , 42 , 45 , 49 , 50 ] used the GMFCS scale. In the meta-analysis, infantile sepsis was associated with significantly increased risk of CP [aOR 2.48 (95%CI: 1.03; 5.99)]. There was no difference in rates of CP among patients with proven or suspected sepsis, as compared with infants with no sepsis (Table 8 , Fig. 3 A and B).
Differences in neurocognitive outcomes between neonates with culture-proven or clinically diagnosed sepsis as well as early or late onset sepsis
Tables 6 and 7 showed data related to differences in neurocognitive outcomes between neonates with culture-proven or clinically diagnosed sepsis as well as early or late onset sepsis. Meta-analyses were not be performed due to significant heterogeneity in definitions of sepsis, time of assessment of outcomes.
Differences in neurocognitive outcomes between term and post-term neonates
There were no studies which evaluated neurocognitive outcomes between term and post-term neonates and infants.
We found that the certainty of evidence to be very low to low for the four main neurocognitive outcomes selected. (Supplementary File 3).
In this review involving more than 121,000 infants, we provide an update to the literature regarding young infant sepsis and neurocognitive impairment. Current collective evidence demonstrate that young infant sepsis was associated with increased risk of developing neurocognitive impairment in all domains of CD, visual impairment, auditory impairment and cerebral palsy.
Cognitive delay
In this review, higher rates of cognitive delay were noted among infants with sepsis [ 29 , 31 , 33 , 34 , 35 , 36 , 37 , 38 , 40 , 41 , 42 , 45 , 46 , 48 , 49 , 52 ]. We found that infants with sepsis reported lower PDI scores (Table 8 ), which measures mainly neuromotor development. On the other hand, young infant sepsis was not associated with lower MDI scores (Table 8 ), which assesses cognitive and language development. The pathophysiological mechanism of young infant sepsis and its preferential impact on PDI remains unclear. Postulated mechanisms include development of white matter lesions which may arise from the susceptibility of oligodendrocyte precursors to inflammatory processes such as hypoxia and ischemia [ 53 ]. Future studies should look into evaluating the causes of the above findings. A majority of included studies focused on early CD outcomes while no studies evaluated long-term outcomes into adulthood. CD is known to involve complex genetic and experiential interactions [ 54 ] and may evolve overtime with brain maturation. Delays in speech and language, intellectual delay and borderline intellectual functioning are shown to be associated with poorer academic or employment outcomes in adulthood [ 55 , 56 ], and early assessment of CD may not fully reveal the extent of delays. The only study with follow-up to the adolescent phase showed a progressive increase in NDI rate as the participants aged, which provides evidence of incremental long-term negative outcomes associated with infantile sepsis [ 44 ]. Moving forward, studies with longer follow-up may allow for further examination of the long-term effects of neonatal sepsis on CD.
There were different versions of the BSID instrument (BSID-II and BSID-III) [ 19 , 57 , 58 ]. BSID-II lacked subscales in PDI and MDI scores, leading to the development of BSID-III with the segregation of PDI into fine and gross motor scales and MDI into cognitive, receptive language, and expressive language scales [ 59 ]. Although we pooled results of both BSID-II and BSID-III in our study, we recognize that comparisons between BSID-II and BSID-III are technically challenging due to differences in standardised scores [ 59 , 60 ]. In addition, the BSID-IV was created in 2019 which has fewer items, However, none of our studies utilized this instrument. Future studies should consider this instrument, as well as standardising the timepoints for assessment of CD.
Young infant sepsis was associated with increased risk of developing visual impairment. This was similar to results noted by a previous systematic review published in 2014 [ 61 ] and 2019 [ 62 ] which showed that neonatal sepsis was associated with twofold risk of developing retinopathy of prematurity in preterm infants. Specifically, meningitis was associated with a greater risk of visual impairment compared to just sepsis alone [ 47 ]. The mechanism of visual impairment has not been fully described although various theories have been suggested, including sepsis mediated vascular endothelial damage, increased body oxidative stress response as well as involvement of inflammatory cytokines and mediators [ 63 , 64 ].
Our meta-analysis showed an increased risk of hearing impairment for young infants with young infants with sepsis. This is consistent with a previous report that found an association between neonatal meningitis and sensorineural hearing loss [ 65 ]. One potential confounder which we were unable to account for may have been the use of ototoxic antimicrobial agents such as aminoglycosides. Additional confounders include very low birth weight, patient’s clinical states (e.g. hyperbilirubinemia requiring exchange transfusion) and use of mechanical ventilation or extracorporeal membrane support. To allow for meaningful comparisons of results across different study populations, it is imperative that a standardised definition of hearing impairment post neonatal sepsis be established for future studies.
Our meta-analysis found an association between neonatal sepsis and an increased risk of developing CP. This is also consistent with previous systematic reviews which had found a significant association of sepsis and CP in VLBW and early preterm infants [ 11 ]. One study found that infants born at full term and who experienced neonatal infections were at a higher risk of developing a spastic triplegia or quadriplegia phenotype of CP [ 66 ]. The pathophysiology and mechanism of injury to white matter resulting in increased motor dysfunction remains unclear and more research is required in this area.
Limitations and recommendations for future research
The main limitation of this review lies in the heterogeneity in the definitions of sepsis, exposures and assessment of outcomes across studies. This is likely attributed to the varying definition of sepsis used in different countries as well as lack of gold standard definitions or instruments for assessment of each component of NDI. A recent review of RCTs [ 67 ] also reported similar limitations where 128 different varying definitions of neonatal sepsis were used in literature. Notably, there is a critical need for developing international standardized guidelines for defining neonatal sepsis as well as assessment of NDI such as hearing and visual impairment. Another important limitation relates to the inability to assess quality of neonatal care delivered as well as temporal changes in medical practices which could have affected neurocognitive outcomes for neonates with sepsis. Improving quality of neonatal care has been shown to significantly reduce mortality risk among neonates with sepsis, especially in resource-poor countries [ 68 ]. We performed a comprehensive search strategy (PubMed, Embase, Web of Science and CENTRAL) coupled with hand searching of references within included systematic reviews, but did not evaluate grey literature. Future studies should include additional literature databases and grey literature. Another area of research gap lies in the paucity of data related to differences in neurocognitive outcomes between term and post-term neonates with sepsis and future research is required to bridge this area of research gap. Likewise, there are few studies which evaluated differences in neurocognitive outcomes between early or late onset sepsis and outcomes assessed were significantly heterogenous which limits meaningful meta-analyses. Similarly, there was significant heterogeneity in study outcomes, causative organisms and severity of disease.
We found a lack of long-term outcomes and recommend that future prospective cohorts include a longer follow-up duration as part of the study design. This is important given the implication of NDI on development into adulthood. Most data were reported for preterm infants with low birth weight, and there was a paucity of data for term infants in our literature review. Since prematurity itself is a significant cause of NDI [ 69 ], future studies should consider how gestational age and/or birth weight can be adequately adjusted for in the analysis.
Apart from the domains of NDI we chose to focus on in this review, there are other cognitive domains classified by the Diagnostic and Statistical Manual of Mental Disorders, Fifth Edition (DSM-V) [ 70 ] and/or recommended by the Common Data Elements (CDE) workgroup [ 71 ]. Future studies may wish to look into the implications of sepsis on other neuro-cognitive domains related to executive function, complex attention and societal cognition which are studied for other types of acquired brain injury [ 71 , 72 ].
Our systematic review and meta-analysis found that neonates surviving sepsis are at a higher risk of poorer neurodevelopment. However, the evidence is limited by significant heterogeneity and selection bias due to differing definitions used for NDI and for sepsis. There is also a lack of long-term follow-up data, as well as data specific for term and post-term infants. Future prospective studies should be conducted with long-term follow-up to assess the impact of neurodevelopmental impairment among all populations of neonates with sepsis.
Availability of data and materials
All data generated or analyzed in the study are found in the tables and supplementary materials.
Liu L, Johnson HL, Cousens S, Perin J, Scott S, Lawn JE, et al. Global, regional, and national causes of child mortality: an updated systematic analysis for 2010 with time trends since 2000. Lancet. 2012;379:2151–61.
Article PubMed Google Scholar
WHO. Newborns: improving survival and well-being. Geneve: World Health Organisation; 2020.
Chiesa C, Panero A, Osborn JF, Simonetti AF, Pacifico L. Diagnosis of neonatal sepsis: a clinical and laboratory challenge. Clin Chem. 2004;50:279–87.
Article CAS PubMed Google Scholar
Ramaswamy VV, Abiramalatha T, Bandyopadhyay T, Shaik NB, Bandiya P, Nanda D, et al. ELBW and ELGAN outcomes in developing nations-Systematic review and meta-analysis. PLoS ONE. 2021;16:e0255352.
Article CAS PubMed PubMed Central Google Scholar
Zhang X, Zhivaki D, Lo-Man R. Unique aspects of the perinatal immune system. Nat Rev Immunol. 2017;17:495–507.
Prabhudas M, Adkins B, Gans H, King C, Levy O, Ramilo O, et al. Challenges in infant immunity: Implications for responses to infection and vaccines. Nat Immunol. 2011;12:189–94.
World Health Organization. Global report on the epidemiology and burden of sepsis. 2020. Available from: https://www.who.int/publications/i/item/9789240010789 .
Milton R, Gillespie D, Dyer C, Taiyari K, Carvalho MJ, Thomson K, et al. Neonatal sepsis and mortality in low-income and middle-income countries from a facility-based birth cohort: an international multisite prospective observational study. Lancet Glob Health. 2022May 1;10(5):e661-72. https://doi.org/10.1016/S2214-109X(22)00043-2 .
Li Y, Ji M, Yang J. Current understanding of long-term cognitive impairment after sepsis. Front Immunol. 2022;13:855006.
Haller S, Deindl P, Cassini A, Suetens C, Zingg W, Abu Sin M, et al. Neurological sequelae of healthcare-associated sepsis in very-low-birthweight infants: Umbrella review and evidence-based outcome tree. Euro Surveill. 2016;21:30143.
Alshaikh B, Yusuf K, Sauve R. Neurodevelopmental outcomes of very low birth weight infants with neonatal sepsis: Systematic review and meta-analysis. J Perinatol. 2013;33:558–64.
Page MJ, McKenzie JE, Bossuyt PM, Boutron I, Hoffmann TC, Mulrow CD, Shamseer L, Tetzlaff JM, Akl EA, Brennan SE, Chou R, Glanville J, Grimshaw JM, Hróbjartsson A, Lalu MM, Li T, Loder EW, Mayo-Wilson E, McDonald S, McGuinness LA, Stewart LA, Thomas J, Tricco AC, Welch VA, Whiting P, Moher D. The PRISMA 2020 statement: an updated guideline for reporting systematic reviews. BMJ. 2021;372:n71. https://doi.org/10.1136/bmj.n71 .
U.S. Department of Health and Human Services F and D, Administration C for DE and R (CDER), (CBER) C for BE and R. General Clinical Pharmacology Considerations for Neonatal Studies for Drugs and Biological Products Guidance for Industry. 2019. Available from: https://www.fda.gov/media/129532/download . [cited 2022 Aug 9].
Bizzarro MJ, Shabanova V, Baltimore RS, Dembry LM, Ehrenkranz RA, Gallagher PG. Neonatal sepsis 2004–2013: the rise and fall of coagulase-negative staphylococci. J Pediatr. 2015;166:1193–9.
Article PubMed PubMed Central Google Scholar
Goddard B, Chang J, Sarkar IN. Using self organizing maps to compare sepsis patients from the neonatal and adult intensive care unit. AMIA Jt Summits Transl Sci Proc. 2019;2019:127–35.
PubMed PubMed Central Google Scholar
Galal M, Symonds I, Murray H, Petraglia F, Smith R. Postterm pregnancy. Facts Views Vis Obgyn. 2012;4(3):175–87. Available from: https://www.ncbi.nlm.nih.gov/pubmed/24753906 .
Evans L, Rhodes A, Alhazzani W, Antonelli M, Coopersmith CM, French C, et al. Surviving sepsis campaign: international guidelines for management of sepsis and septic shock 2021. Intensive Care Med. 2021;47:1181–247.
Mwaniki MK, Atieno M, Lawn JE, Newton CRJC. Long-term neurodevelopmental outcomes after intrauterine and neonatal insults: a systematic review. Lancet. 2012;379:445–52.
Bayley N. Bayley scales of infant and toddler development, Third edition: screening test manual. San Antonio, Texas: Pearson Clinical Assessment PsychCorp; 2006.
Google Scholar
Palisano R, Rosenbaum P, Walter S, Russell D, Wood E, Galuppi B. Development and reliability of a system to classify gross motor function in children with cerebral palsy. Dev Med Child Neurol. 1997;39:214–23.
Spencer-Smith MM, Spittle AJ, Lee KJ, Doyle LW, Anderson PJ. Bayley-III cognitive and language scales in preterm children. Pediatrics. 2015;135(5):e1258-65.
Survival Sepsis Campaign. https://www.sccm.org/SurvivingSepsisCampaign/About-SSC/History . History of Surviving Sepsis Campaign | SCCM.
Tan B, Wong JJM, Sultana R, Koh JCJW, Jit M, Mok YH, et al. Global Case-Fatality Rates in Pediatric Severe Sepsis and Septic Shock: A Systematic Review and Meta-analysis. JAMA Pediatr. 2019;173:352–62.
Covidence systematic review software. Melbourne, Australia: Veritas Health Innovation; Available from: www.covidence.org .
GA Wells, B Shea, D O’Connell, J Peterson, V Welch, M Losos PT. The Newcastle-Ottawa Scale (NOS) for assessing the quality of nonrandomised studies in meta-analyses. Available from: https://www.ohri.ca/programs/clinical_epidemiology/oxford.asp . [cited 2022 Aug 9].
Rücker G, Cates CJ, Schwarzer G. Methods for including information from multi-arm trials in pairwise meta-analysis. Res Synth Methods. 2017;8:392–403.
R Core Team. R core team (2021). R: A language and environment for statistical computing. R Foundation for Statistical Computing, Vienna, Austria. http://www.R-project.org . 2021.
Schünemann H, Oxman JBGGA. GRADE Handbook. עלון הנוטע. 2013;66(1997).
Schlapbach LJ, Aebischer M, Adams M, Natalucci G, Bonhoeffer J, Latzin P, et al. Impact of sepsis on neurodevelopmental outcome in a swiss national cohort of extremely premature infants. Pediatrics. 2011;128:e348-57.
Adams-Chapman I, Bann CM, Das A, Goldberg RN, Stoll BJ, Walsh MC, et al. Neurodevelopmental outcome of extremely low birth weight infants with Candida infection. J Pediatr. 2013;163(4):961-7.e3.
de Haan TR, Beckers L, de Jonge RCJ, Spanjaard L, van Toledo L, Pajkrt D, et al. Neonatal gram negative and candida sepsis survival and neurodevelopmental outcome at the corrected age of 24 months. PLoS One. 2013;8:e59214.
Mitha A, Foix-L’Hélias L, Arnaud C, Marret S, Vieux R, Aujard Y, et al. Neonatal infection and 5-year neurodevelopmental outcome of very preterm infants. Pediatrics. 2013;132:e372-80.
Alshaikh B, Yee W, Lodha A, Henderson E, Yusuf K, Sauve R. Coagulase-negative staphylococcus sepsis in preterm infants and long-term neurodevelopmental outcome. J Perinatol. 2014;34:125–9.
Ferreira RC, Mello RR, Silva KS. Neonatal sepsis as a risk factor for neurodevelopmental changes in preterm infants with very low birth weight. J Pediatr (Rio J). 2014;90:293–9.
Hentges CR, Silveira RC, Procianoy RS, Carvalho CG, Filipouski GR, Fuentefria RN, et al. Association of late-onset neonatal sepsis with late neurodevelopment in the first two years of life of preterm infants with very low birth weight. J Pediatr (Rio J). 2014;90:50–7.
Dangor Z, Lala SG, Cutland CL, Koen A, Jose L, Nakwa F, et al. Burden of invasive group B Streptococcus disease and early neurological sequelae in South African infants. PLoS One. 2015;10:e0123014.
Savioli K, Rouse C, Susi A, Gorman G, Hisle-Gorman E. Suspected or known neonatal sepsis and neurodevelopmental delay by 5 years. J Perinatol. 2018;38:1573–80.
Singh L, Das S, Bhat VB, Plakkal N. Early neurodevelopmental outcome of very low birthweight neonates with culture-positive blood stream infection: a prospective cohort study. Cureus. 2018;10:e3492.
Zonnenberg IA, van Dijk-Lokkart EM, van den Dungen FAM, Vermeulen RJ, van Weissenbruch MM. Eur J Pediatr. 2019;178:673–80.
Nakwa FL, Lala SG, Madhi SA, Dangor Z. Neurodevelopmental impairment at 1 year of age in infants with previous invasive group B streptococcal sepsis and meningitis. Pediatric Infect Dis J. 2020;39:794–8.
Article Google Scholar
Mukhopadhyay S, Puopolo KM, Hansen NI, Lorch SA, Demauro SB, Greenberg RG, et al. Neurodevelopmental outcomes following neonatal late-onset sepsis and blood culture-negative conditions. Arch Dis Child Fetal Neonatal Ed. 2021;106:467–73.
Mukhopadhyay S, Puopolo KM, Hansen NI, Lorch SA, DeMauro SB, Greenberg RG, et al. Impact of early-onset sepsis and antibiotic use on death or survival with neurodevelopmental impairment at 2 years of age among extremely preterm infants. J Pediatr. 2020;221:39-46.e5.
Horváth-Puhó E, Snoek L, van Kassel MN, Gonçalves BP, Chandna J, Procter SR, et al. Prematurity modifies the risk of long-term neurodevelopmental impairments after invasive group B streptococcus infections during infancy in Denmark and the Netherlands. Clin Infect Dis. 2021;74:S44–53.
Article PubMed Central Google Scholar
Horváth-Puhó E, van Kassel MN, Gonçalves BP, de Gier B, Procter SR, Paul P, et al. Mortality, neurodevelopmental impairments, and economic outcomes after invasive group B streptococcal disease in early infancy in Denmark and the Netherlands: a national matched cohort study. Lancet Child Adolesc Health. 2021;5:398–407.
Ortgies T, Rullmann M, Ziegelhöfer D, Bläser A, Thome UH. The role of early-onset-sepsis in the neurodevelopment of very low birth weight infants. BMC Pediatr. 2021;21:289.
Shim SY, Cho SJ, Park EA. Neurodevelopmental outcomes at 18–24 months of corrected age in very low birth weight infants with late-onset sepsis. J Korean Med Sci. 2021;36:e205.
Brumbaugh JE, Bell EF, Do BT, Greenberg RG, Stoll BJ, Demauro SB, et al. Incidence of and neurodevelopmental outcomes after late-onset meningitis among children born extremely preterm. JAMA Netw Open. 2022;5(12):e2245826.
Golin MO, Souza FIS, Paiva L da S, Sarni ROS. The value of clinical examination in preterm newborns after neonatal sepsis: a cross-sectional observational study. Dev Neurorehabil. 2022;25(2):80–6.
Humberg A, Fortmann MI, Spiegler J, Rausch TK, Siller B, Silwedel C, et al. Recurrent late-onset sepsis in extremely low birth weight infants is associated with motor deficits in early school age. Neonatology. 2022;119(6):695–702.
Kartam M, Embaireeg A, Albalool S, Almesafer A, Hammoud M, Al-Hathal M, et al. Late-onset sepsis in preterm neonates is associated with higher risks of cerebellar hemorrhage and lower motor scores at three years of age. Oman Med J. 2022;37(2):e368.
Paul P, Chandna J, Procter SR, Dangor Z, Leahy S, Santhanam S, et al. Neurodevelopmental and growth outcomes after invasive Group B Streptococcus in early infancy: a multi-country matched cohort study in South Africa, Mozambique, India, Kenya, and Argentina. EClinicalMedicine. 2022;47:101358.
Bright HR, Babata K, Allred EN, Erdei C, Kuban KCK, Joseph RM, et al. Neurocognitive outcomes at 10 years of age in extremely preterm newborns with late-onset bacteremia. Journal of Pediatrics. 2017;187:43-49. e1.
Romanelli RMC, Anchieta LM, Mourão MVA, Campos FA, Loyola FC, Mourão PHO, et al. Fatores de risco e letalidade de infecção da corrente sanguínea laboratorialmente confirmada, causada por patógenos não contaminantes da pele em recém-nascidos. J pediatr (Rio J). 2013;89(2):189–96.
Burgaleta M, Johnson W, Waber DP, Colom R, Karama S. Cognitive ability changes and dynamics of cortical thickness development in healthy children and adolescents. Neuroimage. 2014;84:810–9.
Peltopuro M, Ahonen T, Kaartinen J, Seppälä H, Närhi V. Borderline intellectual functioning: a systematic literature review. Intellect Dev Disabil. 2014;52:419–43.
Conti-Ramsden G, Durkin K, Toseeb U, Botting N, Pickles A. Education and employment outcomes of young adults with a history of developmental language disorder. Int J Lang Commun Disord. 2018;53:237–55.
Czeizel AE, Dudas I;, Murphy MM, Fernandez-Ballart JD, Arija V. Bayley scales of infant development-administration manual. Paediatr Perinat Epidemiol. 2019.
Bayley N. Manual for the Bayley Scales of Infant Development (2nd ed.). San Antonio: TX: The Psychological Corporation; 1993.
Bos AF. Bayley-Ii Or Bayley-Iii: what do the scores tell us? Dev Med Child Neurol. 2013;55:978–9.
Johnson S, Marlow N. Developmental screen or developmental testing? Early Hum Dev. 2006;82(3):173–83.
Bakhuizen SE, De Haan TR, Teune MJ, Van Wassenaer-Leemhuis AG, Van Der Heyden JL, Van Der Ham DP, et al. Meta-analysis shows that infants who have suffered neonatal sepsis face an increased risk of mortality and severe complications. Acta Paediatr Int J Paediatr. 2014;103:1211–8.
Cai S, Thompson DK, Yang JYM, Anderson PJ. Short-and long-term neurodevelopmental outcomes of very preterm infants with neonatal sepsis: a systematic review and meta-analysis. Children. 2019;6:131.
Joussen AM, Poulaki V, Le ML, Koizumi K, Esser C, Janicki H, Schraermeyer U, Kociok N, Fauser S, Kirchhof B, Kern TS, Adamis AP. A central role for inflammation in the pathogenesis of diabetic retinopathy. FASEB J. 2004;18(12):1450–2.
Ushio-Fukai M. VEGF signaling through NADPH oxidase-derived ROS. In: Antioxidants and Redox Signaling. 2007.
Sharma A, Leaf JM, Thomas S, Cane C, Stuart C, Tremlett C, et al. Sensorineural hearing loss after neonatal meningitis: a single-centre retrospective study. BMJ Paediatr Open. 2022;6(1):e001601.
Smilga AS, Garfinkle J, Ng P, Andersen J, Buckley D, Fehlings D, et al. Neonatal infection in children with cerebral palsy: a registry-based cohort study. Pediatr Neurol. 2018;80:77–83.
Hayes R, Hartnett J, Semova G, Murray C, Murphy K, Carroll L, et al. Neonatal sepsis definitions from randomised clinical trials. Pediatr Res. 2023;93:1141–8.
Rahman AE, Iqbal A, Hoque DME, Moinuddin M, Zaman SB, Rahman QSU, et al. Managing neonatal and early childhood syndromic sepsis in sub-district hospitals in resource poor settings: Improvement in quality of care through introduction of a package of interventions in rural Bangladesh. PLoS One. 2017;12(1):e0170267.
Singh M, Alsaleem M GCP. StatPearls. Treasure Island (FL): StatPearls Publishing. 2022. Neonatal Sepsis. [Updated 2022 Sep 29]. Available from: https://www-ncbi-nlm-nih-gov.libproxy1.nus.edu.sg/books/NBK531478/ .
American Psychiatric Association. Diagnostic and Statistical Manual of Mental Disorders. Diagnostic and Statistical Manual of Mental Disorders. 2022.
Book Google Scholar
McCauley SR, Wilde EA, Anderson VA, Bedell G, Beers SR, Campbell TF, et al. Recommendations for the Use of Common Outcome measures in pediatric traumatic brain injury research. J Neurotrauma. 2012;29:678–705.
Goh MSL, Looi DSH, Goh JL, Sultana R, Goh SSM, Lee JH, Chong SL. The Impact of Traumatic Brain Injury on Neurocognitive Outcomes in Children: a Systematic Review and Meta-Analysis. J Neurol Neurosurg Psychiatry. 2021:jnnp-2020-325066.
Download references
Acknowledgements
We would like to thank Ms. Wong Suei Nee, senior librarian from the National University of Singapore for helping us with the search strategy. We will also like to thank Dr Ming Ying Gan, Dr Shu Ting Tammie Seethor, Dr Jen Heng Pek, Dr Rachel Greenberg, Dr Christoph Hornik and Dr Bobby Tan, for their inputs in the initial design of this study.
Conflict of interest
No financial or non-financial benefits have been received or will be received from any party related directly or indirectly to the subject of this article.
Author information
Wei Jie Ong and Jun Jie Benjamin Seng are co-first authors.
Authors and Affiliations
MOH Holdings, Singapore, 1 Maritime Square, Singapore, 099253, Singapore
Wei Jie Ong, Jun Jie Benjamin Seng, Beijun Yap & Chen Lin Ng
SingHealth Regional Health System PULSES Centre, Singapore Health Services, Outram Rd, Singapore, 169608, Singapore
Jun Jie Benjamin Seng
SingHealth Duke-NUS Family Medicine Academic Clinical Programme, Singapore, Singapore
Yong Loo Lin School of Medicine, 10 Medical Dr, Yong Loo Lin School of Medicine, Singapore, Singapore
George He & Nooriyah Aliasgar Moochhala
Centre for Quantitative Medicine, Duke-NUS Medical School, Singapore, Singapore
Rehena Ganguly
Children’s Intensive Care Unit, KK Women’s and Children’s Hospital, SingHealth Paediatrics Academic Clinical Programme, 100 Bukit Timah Rd, Singapore, 229899, Singapore
Jan Hau Lee
Department of Emergency Medicine, KK Women’s and Children’s Hospital, SingHealth Paediatrics Academic Clinical Programme, SingHealth Emergency Medicine Academic Clinical Programme, 100 Bukit Timah Rd, Singapore, 229899, Singapore
Shu-Ling Chong
You can also search for this author in PubMed Google Scholar
Contributions
SLC and JHL were the study’s principal investigators and were responsible for the conception and design of the study. WJO, JJBS, BY, GE, NAM and CLN were the co-investigators. WJO, JJBS, BY, GE, NAM and CLN were responsible for the screening and inclusion of articles and data extraction. All authors contributed to the data analyses and interpretation of data. WJO, JJBS, BY, GE, NAM and CLN prepared the initial draft of the manuscript. All authors revised the draft critically for important intellectual content and agreed to the final submission. All authors had access to all study data, revised the draft critically for important intellectual content and agreed to the final submission.
Corresponding author
Correspondence to Jun Jie Benjamin Seng .
Ethics declarations
Ethics approval and consent to participate.
As this was a systematic review with no access to patient data, ethical approval from the institutional review board was exempted.
Consent for publication
Not applicable.
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note.
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Supplementary material 1., rights and permissions.
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/ .
Reprints and permissions
About this article
Cite this article.
Ong, W.J., Seng, J.J.B., Yap, B. et al. Impact of neonatal sepsis on neurocognitive outcomes: a systematic review and meta-analysis. BMC Pediatr 24 , 505 (2024). https://doi.org/10.1186/s12887-024-04977-8
Download citation
Received : 11 May 2024
Accepted : 26 July 2024
Published : 07 August 2024
DOI : https://doi.org/10.1186/s12887-024-04977-8
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Neonatal sepsis
- Infantile sepsis
- Neurocognitive outcomes
- Systematic review
BMC Pediatrics
ISSN: 1471-2431
- Submission enquiries: [email protected]
- General enquiries: [email protected]
IMAGES
COMMENTS
The average base salary for a Data Scientist at Jpmorgan Chase & Co. is $128,435. based on 83 data points. Adjusting the average for more recent salary data points, the average recency weighted base salary is $129,845. The estimated average total compensation is $137,839.
Depending on your area of interest, AI & Data Science Interns will be placed on one of the following teams: Machine Learning Centre of Excellence: Join a world-class machine learning team that continually advances state-of-the-art methods to solve a wide range of real-world financial problems by leveraging JPMorgan Chase's vast datasets.
J.P. Morgan Asset Management is building machine learning and predictive analytics tools for its fundamental portfolio managers. Just don't call them quants.
View full PDF JPMorgan Chase will deliver more than $1.5 billion in business value from artificial intelligence and machine learning efforts in 2023 as it leverages its 500 petabytes of data across 300 use cases in production. "We've always been a data driven company," said Larry Feinsmith, Managing Director and Head of Technology Strategy, Innovation, & Partnerships at JPMorgan Chase.
Machine Learning Center Of Excellence. The Machine Learning Center of Excellence (MLCOE) is a group of specialized Machine Learning scientists who partner with businesses within JPMorgan Chase and their analytics teams. Through our collaborative approach, we build, deploy and share ML solutions using the latest innovations and methods in the ...
And we also included some of the AI/machine learning specialists and data science players in the mix like DataRobot, which just did a monster $250M round, Dataiku, H2O.ai and ThoughtSpot, which is ...
I interviewed at J.P. Morgan (Dublin, Dublin) in Oct 1, 2021. Interview. 1. Coding Challenge with 3 questions on the Virtual Interview environment. 2. Move on to the questions and answers stage with 3 Questions about coding challenges. 3. Move to Questions about past experience, projects, and introduction of yourself.
JPMorgan Chase sees artificial intelligence (AI) as critical to its future success. And the mega-bank has a big advantage over many of its smaller rivals: the massive amount of data it gathers ...
Distribution: J.P. Morgan Funds are distributed by JPMorgan Distribution Services, Inc., which is an affiliate of JPMorgan Chase & Co. Affiliates of JPMorgan Chase & Co. receive fees for providing various services to the funds. JPMorgan Distribution Services, Inc. is a member of FINRA.
43 J.P. Morgan Data Science interview questions and 32 interview reviews. Free interview details posted anonymously by J.P. Morgan interview candidates. ... JPMorgan Chase. ... Online application Initially screening test Chat with hiring manager Case Study Job offer Over all the initial screening was difficult and the case study was quite ...
I interviewed at J.P. Morgan in 10/1/2021. Interview. Absolutely atrocious interview process. Process went as such: 1: After application submission, was invited for a HireVue interview (3-4 questions, 2 easy questions - questions like finding the standard deviation of an array, 2 medium - DSA questions - decode ways) 2: After THREE months, I ...
This material contains forward-looking statements within the meaning of the Private Securities Litigation Reform Act of 1995. These statements relate to, among other things, our goals, commitments, targets, aspirations and objectives, and are based on the current beliefs and expectations of management of JPMorgan Chase & Co. and its affiliates and subsidiaries worldwide (collectively ...
Average interview. Application. I applied online. I interviewed at JPMorgan Chase & Co. Interview. 1. Codevue coding problems 2. Super day which included technical behavioral and case study about 45 minutes each 3. Got a call within 2 weeks informing me that I got the position.
Data Science in Banking Case Study How JP Morgan Chase uses Data Science. JP Morgan Chase is one of the premier banks of the world today. It is one of the largest consumers of data with a staggering 150 petabytes of data holding about 3.5 billion users under its wing.
1.1 What interviews to expect. Whether applying for a full-time position or an internship program, JP Morgan candidates will typically go through 4 steps: Application and resume. Pymetrics test (~30min) HireVue interview (~20min ) Final-round interviews / Super day. 1.1.1 Application and resume.
comments. Best. Add a Comment. thebrownwaters • 10 mo. ago. timeline for AI/Data Science summer associate 2023: applied 8/17, received OA/hirevue 8/17, completed OA/hirevue 8/22, final round interview invite 11/29, final round interview 12/2, still waiting for decision. interview was mostly knowledge checks about machine learning fundamentals ...
Embracing AI in finance enables organizations to streamline forecasting processes, enhance accuracy, and unlock valuable insights for better financial planning. With AI-driven forecasting, businesses can stay ahead of market trends, mitigate risks, and achieve their financial goals. 2.
Artificial Intelligence Research. Artificial Intelligence. Research. The goal of our AI Research program is to explore and advance cutting-edge research in the fields of AI and Machine Learning, as well as related fields like Cryptography, to develop solutions that are most impactful to the firm's clients and businesses. Learn More.
Data on hourly aggregate solar resource availability for CONUS were retrieved from the GitHub repository for Shaner et al. [34]. Data from which this hourly resource availability was calculated were retrieved from the Modern-Era Retrospective analysis for Research and Application, Version-2 (MERRA-2) reanalysis satellite weather data.
Sepsis is a major cause of mortality and morbidity among neonates [1,2,3,4].Young infants especially neonates, defined by age < 28 days old, have a relatively immature immune system and are susceptible to sepsis [5, 6].Annually, there are an estimated 1.3 to 3.9 million cases of infantile sepsis worldwide and up to 700,000 deaths [].Low-income and middle-income countries bear a ...