Copyright © 2024 AudiologyOnline - All Rights Reserved
- Back to Basics: Speech Audiometry

Janet R. Schoepflin, PhD
- Hearing Evaluation - Adults
Editor's Note: This is a transcript of an AudiologyOnline live seminar. Please download supplemental course materials . Speech is the auditory stimulus through which we communicate. The recognition of speech is therefore of great interest to all of us in the fields of speech and hearing. Speech audiometry developed originally out of the work conducted at Bell Labs in the 1920s and 1930s where they were looking into the efficiency of communication systems, and really gained momentum post World War II as returning veterans presented with hearing loss. The methods and materials for testing speech intelligibility were of interest then, and are still of interest today. It is due to this ongoing interest as seen in the questions that students ask during classes, by questions new audiologists raise as they begin their practice, and by the comments and questions we see on various audiology listservs about the most efficient and effective ways to test speech in the clinical setting, that AudiologyOnline proposed this webinar as part of their Back to Basics series. I am delighted to participate. I am presenting a review of the array of speech tests that we use in clinical evaluation with a summary of some of the old and new research that has come about to support the recommended practices. The topics that I will address today are an overview of speech threshold testing, suprathreshold speech recognition testing, the most comfortable listening level testing, uncomfortable listening level, and a brief mention of some new directions that speech testing is taking. In the context of testing speech, I will assume that the environment in which you are testing meets the ANSI permissible noise criteria and that the audiometer transducers that are being used to perform speech testing are all calibrated to the ANSI standards for speech. I will not be talking about those standards, but it's of course important to keep those in mind.
Speech Threshold testing involves several considerations. They include the purposes of the test or the reasons for performing the test, the materials that should be used in testing, and the method or procedure for testing. Purposes of Speech Threshold Testing A number of purposes have been given for speech threshold testing. In the past, speech thresholds were used as a means to cross-check the validity of pure tone thresholds. This purpose lacks some validity because we have other physiologic and electrophysiologic procedures like OAEs and imittance test results to help us in that cross-check. However, the speech threshold measure is a test of hearing. It is not entirely invalid to be performed as a cross-check for pure tone hearing. I think sometimes we are anxious to get rid of things because we feel we have a better handle from other tests, but in this case, it may not be the wisest thing to toss out. Also in past years, speech thresholds were used to determine the level for suprathreshold speech recognition testing. That also lacks validity, because the level at which suprathreshold testing is conducted depends on the reason you are doing the test itself. It is necessary to test speech thresholds if you are going to bill 92557. Aside from that, the current purpose for speech threshold testing is in the evaluation of pediatric and difficult to test patients. Clinical practice surveys tell us that the majority of clinicians do test speech thresholds for all their patients whether it is for billing purposes or not. It is always important that testing is done in the recommended, standardized manner. The accepted measures for speech thresholds are the Speech Recognition Threshold (SRT) and the Speech Detection Threshold (SDT). Those terms are used because they specify the material or stimulus, i.e. speech, as well as the task that the listener is required to do, which is recognition or identification in the case of the SRT, and detection or noticing of presence versus absence of the stimulus in the case of SDT. The terms also specify the criterion for performance which is threshold or generally 50%. The SDT is most commonly performed on those individuals who have been unable to complete an SRT, such as very young children. Because recognition is not required in the speech detection task, it is expected that the SDT will be about 5 to 10 dB better than the SRT, which requires recognition of the material. Materials for Speech Threshold Testing The materials that are used in speech threshold testing are spondees, which are familiar two-syllable words that have a fairly steep psychometric function. Cold running speech or connected discourse is an alternative for speech detection testing since recognition is not required in that task. Whatever material is used, it should be noted on the audiogram. It is important to make notations on the audiogram about the protocols and the materials we are using, although in common practice many of us are lax in doing so. Methods for Speech Threshold Testing The methods consideration in speech threshold testing is how we are going to do the test. This would include whether we use monitored live voice or recorded materials, and whether we familiarize the patient with the materials and the technique that we use to elicit threshold. Monitored live voice and recorded speech can both be used in SRT testing. However, recorded presentation is recommended because recorded materials standardize the test procedure. With live voice presentation, the monitoring of each syllable of each spondee, so that it peaks at 0 on the VU meter can be fairly difficult. The consistency of the presentation is lost then. Using recorded materials is recommended, but it is less important in speech threshold testing than it is in suprathreshold speech testing. As I mentioned with the materials that are used, it is important to note on the audiogram what method of presentation has been used. As far as familiarization goes, we have known for about 50 years, since Tillman and Jerger (1959) identified familiarity as a factor in speech thresholds, that familiarization of the patient with the test words should be included as part of every test. Several clinical practice surveys suggest that familiarization is not often done with the patients. This is not a good practice because familiarization does influence thresholds and should be part of the procedure. The last consideration under methods is regarding the technique that is going to be used. Several different techniques have been proposed for the determination of SRT. Clinical practice surveys suggest the most commonly used method is a bracketing procedure. The typical down 10 dB, up 5 dB is often used with two to four words presented at each level, and the threshold then is defined as the lowest level at which 50% or at least 50% of the words are correctly repeated. This is not the procedure that is recommended by ASHA (1988). The ASHA-recommended procedure is a descending technique where two spondees are presented at each decrement from the starting level. There are other modifications that have been proposed, but they are not widely used.
Suprathreshold speech testing involves considerations as well. They are similar to those that we mentioned for threshold tests, but they are more complicated than the threshold considerations. They include the purposes of the testing, the materials that should be used in testing, whether the test material should be delivered via monitored live voice or recorded materials, the level or levels at which the testing should be conducted, whether a full list, half list, or an abbreviated word list should be used, and whether or not the test should be given in quiet or noise. Purposes of Suprathreshold Testing There are several reasons to conduct suprathreshold tests. They include estimating the communicative ability of the individual at a normal conversational level; determining whether or not a more thorough diagnostic assessment is going to be conducted; hearing aid considerations, and analysis of the error patterns in speech recognition. When the purpose of testing is to estimate communicative ability at a normal conversational level, then the test should be given at a level around 50 to 60 dBHL since that is representative of a normal conversational level at a communicating distance of about 1 meter. While monosyllabic words in quiet do not give a complete picture of communicative ability in daily situations, it is a procedure that people like to use to give some broad sense of overall communicative ability. If the purpose of the testing is for diagnostic assessment, then a psychometric or performance-intensity function should be obtained. If the reason for the testing is for hearing aid considerations, then the test is often given using words or sentences and either in quiet or in a background of noise. Another purpose is the analysis of error patterns in speech recognition and in that situation, a test other than some open set monosyllabic word test would be appropriate. Materials for Suprathreshold Testing The choice of materials for testing depends on the purpose of the test and on the age and abilities of the patients. The issues in materials include the set and the test items themselves.
Closed set vs. Open set. The first consideration is whether a closed set or an open set is appropriate. Closed set tests limit the number of response alternatives to a fairly small set, usually between 4 and 10 depending on the procedure. The number of alternatives influences the guess rate. This is a consideration as well. The Word Intelligibility by Picture Identification or the WIPI test is a commonly used closed set test for children as it requires only the picture pointing response and it has a receptive language vocabulary that is as low as about 5 years. It is very useful in pediatric evaluations as is another closed set test, the Northwestern University Children's Perception of Speech test (NU-CHIPS).
In contrast, the open set protocol provides an unlimited number of stimulus alternatives. Therefore, open set tests are more difficult. The clinical practice surveys available suggest for routine audiometric testing that monosyllabic word lists are the most widely used materials in suprathreshold speech recognition testing for routine evaluations, but sentences in noise are gaining popularity for hearing aid purposes.
CID W-22 vs. NU-6. The most common materials for speech recognition testing are the monosyllabic words, the Central Institute of the Deaf W-22 and the Northwestern University-6 word list. These are the most common open set materials and there has been some discussion among audiologists concerning the differences between those. From a historical perspective, the CID W-22 list came from the original Harvard PAL-PB50 words and the W-22s are a group of the more familiar of those. They were developed into four 50-word lists. They are still commonly used by audiologists today. The NU-6 lists were developed later and instead of looking for phonetic balance, they considered a more phonemic balance. The articulation function for both of those using recorded materials is about the same, 4% per dB. The NU-6 tests are considered somewhat more difficult than the W-22s. Clinical surveys show that both materials are used by practicing audiologists, with usage of the NU-6 lists beginning to surpass usage of W-22s.
Nonsense materials. There are other materials that are available for suprathreshold speech testing. There are other monosyllabic word lists like the Gardner high frequency word list (Gardner, 1971) that could be useful for special applications or special populations. There are also nonsense syllabic tasks which were used in early research in communication. An advantage of the nonsense syllables is that the effects of word familiarity and lexical constraints are reduced as compared to using actual words as test materials. A few that are available are the City University of New York Nonsense Syllable test, the Nonsense Syllable test, and others.
Sentence materials. Sentence materials are gaining popularity, particularly in hearing aid applications. This is because speech that contains contextual cues and is presented in a noise background is expected to have better predictive validity than words in quiet. The two sentence procedures that are popular are the Hearing In Noise Test (HINT) (Nilsson, Soli,& Sullivan, 1994) and the QuickSIN (Killion, Niquette, Gudmundsen, Revit & Banerjee, 2004). Other sentence tests that are available that have particular applications are the Synthetic Sentence Identification test (SSI), the Speech Perception and Noise test (SPIN), and the Connected Speech test.
Monitored Live Voice vs. Recorded. As with speech threshold testing, the use of recorded materials for suprathreshold speech testing standardizes the test administration. The recorded version of the test is actually the test in my opinion. This goes back to a study in 1969 where the findings said the test is not just the written word list, but rather it is a recorded version of those words.
Inter-speaker and intra-speaker variability makes using recorded materials the method of choice in almost all cases for suprathreshold testing. Monitored live voice (MLV) is not recommended. In years gone by, recorded materials were difficult to manipulate, but the ease and flexibility that is afforded us by CDs and digital recordings makes recorded materials the only way to go for testing suprathreshold speech recognition. Another issue to consider is the use of the carrier phrase. Since the carrier phrase is included on recordings and recorded materials are the recommended procedure, that issue is settled. However, I do know that monitored live voice is necessary in certain situations and if monitored live voice is used in testing, then the carrier phrase should precede the test word. In monitored live voice, the carrier phrase is intended to allow the test word to have its own natural inflection and its own natural power. The VU meter should peak at 0 for the carrier phrase and the test word then is delivered at its own natural or normal level for that word in the phrase.
Levels. The level at which testing is done is another consideration. The psychometric or performance-intensity function plots speech performance in percent correct on the Y-axis, as a function of the level of the speech signal on the X-axis. This is important because testing at only one level, which is fairly common, gives us insufficient information about the patient's optimal performance or what we commonly call the PB-max. It also does not allow us to know anything about any possible deterioration in performance if the level is increased. As a reminder, normal hearers show a function that reaches its maximum around 25 to 40 dB SL (re: SRT) and that is the reason why suprathreshold testing is often conducted at that level. For normals, the performance remains at that level, 100% or so, as the level increases. People with conductive hearing loss also show a similar function. Individuals with sensorineural hearing loss, however, show a performance function that reaches its maximum at generally less than 100%. They can either show performance that stays at that level as intensity increases, or they can show a curve that reaches its maximum and then decreases in performance as intensity increases. This is known as roll-over. A single level is not the best way to go as we cannot anticipate which patients may have rollover during testing, unless we test at a level higher than where the maximum score was obtained. I recognize that there are often time constraints in everyday practice, but two levels are recommended so that the performance-intensity function can be observed for an individual patient at least in an abbreviated way.
Recently, Guthrie and Mackersie (2009) published a paper that compared several different presentation levels to ascertain which level would result in maximum word recognition in individuals who had different hearing loss configurations. They looked at a number of presentation levels ranging from 10 dB above the SRT to a level at the UCL (uncomfortable listening level) -5 dB. Their results indicated that individuals with mild to moderate losses and those with more steeply sloping losses reached their best scores at a UCL -5 dB. That was also true for those patients who had moderately-severe to severe losses. The best phoneme recognition scores for their populations were achieved at a level of UCL -5 dB. As a reminder about speech recognition testing, masking is frequently needed because the test is being presented at a level above threshold, in many cases well above the threshold. Masking will always be needed for suprathreshold testing when the presentation level in the test ear is 40 dB or greater above the best bone conduction threshold in the non-test ear if supra-aural phones are used.
Full lists vs. half-lists. Another consideration is whether a full list or a half-list should be administered. Original lists were composed of 50 words and those 50 words were created for phonetic balance and for simplicity in scoring. It made it easy for the test to be scored if 50 words were administered and each word was worth 2%. Because 50-word lists take a long time, people often use half-lists or even shorter lists for the purpose of suprathreshold speech recognition testing. Let's look into this practice a little further.
An early study was done by Thornton and Raffin (1978) using the Binomial Distribution Model. They investigated the critical differences between one score and a retest score that would be necessary for those scores to be considered statistically significant. Their findings showed that with an increasing set size, variability decreased. It would seem that more items are better. More recently Hurley and Sells (2003) conducted a study that looked at developing a test methodology that would identify those patients requiring a full 50 item suprathreshold test and allow abbreviated testing of patients who do not need a full 50 item list. They used Auditec recordings and developed 10-word and 25-word screening tests. They found that the four lists of NU-6 10-word and the 25-word screening tests were able to differentiate listeners who had impaired word recognition who needed a full 50-word list from those with unimpaired word recognition ability who only needed the 10-word or 25-word list. If abbreviated testing is important, then it would seem that this would be the protocol to follow. These screening lists are available in a recorded version and their findings were based on a recorded version. Once again, it is important to use recorded materials whether you are going to use a full list or use an abbreviated list.
Quiet vs. Noise. Another consideration in suprathreshold speech recognition testing is whether to test in quiet or in noise. The effects of sensorineural hearing loss beyond the threshold loss, such as impaired frequency resolution or impaired temporal resolution, makes speech recognition performance in quiet a poor predictor for how those individuals will perform in noise. Speech recognition in noise is being promoted by a number of experts because adding noise improves the sensitivity of the test and the validity of the test. Giving the test at several levels will provide for a better separation between people who have hearing loss and those who have normal hearing. We know that individuals with hearing loss have a lot more difficulty with speech recognition in noise than those with normal hearing, and that those with sensorineural hearing loss often require a much greater signal-to-noise ratio (SNR), 10 to 15 better, than normal hearers.
Monosyllabic words in noise have not been widely used in clinical evaluation. However there are several word lists that are available. One of them is the Words in Noise test or WIN test which presents NU-6 words in a multi-talker babble. The words are presented at several different SNRs with the babble remaining at a constant level. One of the advantages of using these kinds of tests is that they are adaptive. They can be administered in a shorter period of time and they do not run into the same problems that we see with ceiling effects and floor effects. As I mentioned earlier, sentence tests in noise have become increasingly popular in hearing aid applications. Testing speech in noise is one way to look at amplification pre and post fitting. The Hearing in Noise Test and QuickSin, have gained popularity in those applications. The HINT was developed by Nilsson and colleagues in 1994 and later modified. It is scored as the dB to noise ratio that is necessary to get a 50% correct performance on the sentences. The sentences are the BKB (Bamford-Kowal-Bench) sentences. They are presented in sets of 10 and the listener listens and repeats the entire sentence correctly in order to get credit. In the HINT, the speech spectrum noise stays constant and the signal level is varied to obtain that 50% point. The QuickSin is a test that was developed by Killion and colleagues (2004) and uses the IEEE sentences. It has six sentences per list with five key words that are the scoring words in each sentence. All of them are presented in a multi-talker babble. The sentences get presented one at a time in 5 dB decrements from a high positive SNR down to 0 dB SNR. Again the test is scored as the 50% point in terms of dB signal-to-noise ratio. The guide proposed by Killion on the SNR is if an individual has somewhere around a 0 to 3 dB SNR it would be considered normal, 3 to 7 would be a mild SNR loss, 7 to15 dB would be a moderate SNR loss, and greater than 15 dB would be a severe SNR loss.
Scoring. Scoring is another issue in suprathreshold speech recognition testing. It is generally done on a whole word basis. However phoneme scoring is another option. If phoneme scoring is used, it is a way of increasing the set size and you have more items to score without adding to the time of the test. If whole word scoring is used, the words have to be exactly correct. In this situation, being close does not count. The word must be absolutely correct in order to be judged as being correct. Over time, different scoring categorizations have been proposed, although the percentages that are attributed to those categories vary among the different proposals.
The traditional categorizations include excellent, good, fair, poor, and very poor. These categories are defined as:
- Excellent or within normal limits = 90 - 100% on whole word scoring
- Good or slight difficulty = 78 - 88%
- Fair to moderate difficulty = 66 - 76%
- Poor or great difficulty = 54 - 64 %
- Very poor is < 52%
A very useful test routinely administered to those who are being considered for hearing aids is the level at which a listener finds listening most comfortable. The materials that are used for this are usually cold running speech or connected discourse. The listener is asked to rate the level at which listening is found to be most comfortable. Several trials are usually completed because most comfortable listening is typically a range, not a specific level or a single value. People sometimes want sounds a little louder or a little softer, so the range is a more appropriate term for this than most comfortable level. However whatever is obtained, whether it is a most comfortable level or a most comfortable range, should be recorded on the audiogram. Again, the material used should also be noted on the audiogram. As I mentioned earlier the most comfortable level (MCL) is often not the level at which a listener achieves maximum intelligibility. Using MCL in order to determine where the suprathreshold speech recognition measure will be done is not a good reason to use this test. MCL is useful, but not for determining where maximum intelligibility will be. The study I mentioned earlier showed that maximum intelligibility was reached for most people with hearing loss at a UCL -5. MCL is useful however in determining ANL or acceptable noise level.
The uncomfortable listening level (UCL) is also conducted with cold running speech. The instructions for this test can certainly influence the outcome since uncomfortable or uncomfortably loud for some individuals may not really be their UCL, but rather a preference for listening at a softer level. It is important to define for the patient what you mean by uncomfortably loud. The utility of the UCL is in providing an estimate for the dynamic range for speech which is the difference between the UCL and the SRT. In normals, this range is usually 100 dB or more, but it is reduced in ears with sensorineural hearing loss often dramatically. By doing the UCL, you can get an estimate of the individual's dynamic range for speech.
Acceptable Noise Level (ANL) is the amount of background noise that a listener is willing to accept while listening to speech (Nabelek, Tucker, & Letowski, 1991). It is a test of noise tolerance and it has been shown to be related to the successful use of hearing aids and to potential benefit with hearing aids (Nabelek, Freyaldenhoven, Tampas, & Muenchen, 2006). It uses the MCL and a measure known as BNL or background noise level. To conduct the test, a recorded speech passage is presented to the listener in the sound field for the MCL. Again note the use of recorded materials. The noise is then introduced to the listener to a level that will be the highest level that that person is able to accept or "put up with" while they are listening to and following the story in the speech passage. The ANL then becomes the difference between the MCL and the BNL. Individuals that have very low scores on the ANL are considered successful hearing aid users or good candidates for hearing aids. Those that have very high scores are considered unsuccessful users or poor hearing aid candidates. Obviously there are number of other applications for speech in audiologic practice, not the least of which is in the assessment of auditory processing. Many seminars could be conducted on this topic alone. Another application or future direction for speech audiometry is to more realistically assess hearing aid performance in "real world" environments. This is an area where research is currently underway.
Question: Are there any more specific instructions for the UCL measurement? Answer: Instructions are very important. We need to make it clear to a patient exactly what we expect them to do. I personally do not like things loud. If I am asked to indicate what is uncomfortably loud, I am much below what is really my UCL. I think you have to be very direct in instructing your patients in that you are not looking for a little uncomfortable, but where they just do not want to hear it or cannot take it. Question: Can you sum up what the best methods are to test hearing aid performance? I assume this means with speech signals. Answer: I think the use of the HINT or the QuickSin would be the most useful on a behavioral test. We have other ways of looking at performance that are not behavioral. Question: What about dialects? In my area, some of the local dialects have clipped words during speech testing. I am not sure if I should count those as correct or incorrect. Answer: It all depends on your situation. If a patient's production is really reflective of the dialect of that region and they are saying the word as everyone else in that area would say it, then I would say they do have the word correct. If necessary, if you are really unclear, you can always ask the patient to spell the word or write it down. This extra time can be inconvenient, but that is the best way to be sure that they have correctly identified the word. Question: Is there a reference for the bracketing method? Answer: The bracketing method is based on the old modified Hughson-Westlake that many people use for pure tone threshold testing. It is very similar to that traditional down 10 dB, up 5 dB. I am sure there are more references, but the Hughson-Westlake is what bracketing is based on. Question: Once you get an SRT result, if you want to compare it to the thresholds to validate your pure tones, how do you compare it to the audiogram? Answer: If it is a flat hearing loss, then you can compare to the 3-frequency pure tone average (PTA). If there is a high frequency loss, where audibility at perhaps 2000 Hz is greatly reduced, then it is better to use just the average of 500Hz and 1000Hz as your comparison. If it is a steeply sloping loss, then you look for agreement with the best threshold, which would probably be the 500 Hz threshold. The reverse is also true for patients who have rising configurations. Compare the SRT to the best two frequencies of the PTA, if the loss has either a steep slope or a steep rise, or the best frequency in the PTA if it is a really precipitous change in configuration. Question: Where can I find speech lists in Russian or other languages? Answer: Auditec has some material available in languages other than English - it would be best to contact them directly. You can also view their catalog at www.auditec.com Carolyn Smaka: This raises a question I have. If an audiologist is not fluent in a particular language, such as Spanish, is it ok to obtain a word list or recording in that language and conduct speech testing? Janet Schoepflin: I do not think that is a good practice. If you are not fluent in a language, you do not know all the subtleties of that language and the allophonic variations. People want to get an estimation of suprathreshold speech recognition and this would be an attempt to do that. This goes along with dialect. Whether you are using a recording, or doing your best to say these words exactly as there are supposed to be said, and your patient is fluent in a language and they say the word back to you, since you are not familiar with all the variations in the language it is possible that you will score the word incorrectly. You may think it is correct when it is actually incorrect, or you may think it is incorrect when it is correct based on the dialect or variation of that language. Question: In school we were instructed to use the full 50-word list for any word discrimination testing at suprathreshold, but if we are pressed for time, a half word list would be okay. However, my professor warned us that we absolutely must go in order on the word list. Can you clarify this? Answer: I'm not sure why that might have been said. I was trained in the model to use the 50-word list. This was because the phonetic balance that was proposed for those words was based on the 50 words. If you only used 25 words, you were not getting the phonetic balance. I think the more current findings from Hurley and Sells show us that it is possible to use a shorter list developed specifically for this purpose. It should be the recorded version of those words. These lists are available through Auditec. Question: On the NU-6 list, the words 'tough' and 'puff' are next to each other. 'Tough' is often mistaken for 'puff' so then when we reads 'puff', the person looks confused. Is it okay to mix up the order on the word list? Answer: I think in that case it is perfectly fine to move that one word down. Question: When do you recommend conducting speech testing, before or after pure tone testing? Answer: I have always been a person who likes to interact with my patients. My own procedure is to do an SRT first. Frequently for an SRT I do use live voice. I do not use monitored live voice for suprathreshold testing. It gives me a time to interact with the patient. People feel comfortable with speech. It is a communicative act. Then I do pure tone testing. Personally I would not do suprathreshold until I finished pure tone testing. My sequence is often SRT, pure tone, and suprathreshold. If this is not a good protocol for you based on time, then I would conduct pure tone testing, SRT, and then suprathreshold. Question: Some of the spondee words are outdated such as inkwell and whitewash. Is it okay to substitute other words that we know are spondee words, but may not be on the list? Or if we familiarize people, does it matter? Answer: The words that are on the list were put there for their so-called familiarity, but also because they were somewhat homogeneous and equal in intelligibility. I think inkwell, drawbridge and whitewash are outdated. If you follow a protocol where you are using a representative sample of the words and you are familiarizing, I think it is perfectly fine to eliminate those words you do not want to use. You just do not want to end up only using five or six words as it will limit the test set. Question: At what age is it appropriate to expect a child to perform suprathreshold speech recognition testing? Answer: If the child has a receptive language age of around 4 or 5 years, even 3 years maybe, it is possible to use the NU-CHIPS as a measure. It really does depend on language more than anything else, and the fact that the child can sit still for a period of time to do the test. Question: Regarding masking, when you are going 40 dB above the bone conduction threshold in the non-test ear, what frequency are you looking at? Are you comparing speech presented at 40 above a pure tone average of the bone conduction threshold? Answer: The best bone conduction threshold in the non-test ear is what really should be used. Question: When seeing a patient in follow-up after an ENT prescribes a steroid therapy for hydrops, do you recommend using the same word list to compare their suprathreshold speech recognition? Answer: I think it is better to use a different list, personally. Word familiarity as we said can influence even threshold and it certainly can affect suprathreshold performance. I think it is best to use a different word list. Carolyn Smaka: Thanks to everyone for their questions. Dr. Schoepflin has provided her email address with the handout. If your question was not answered or if you have further thoughts after the presentation, please feel free to follow up directly with her via email. Janet Schoepflin: Thank you so much. It was my pleasure and I hope everyone found the presentation worthwhile.
American Speech, Language and Hearing Association. (1988). Determining Threshold Level for Speech [Guidelines]. Available from www.asha.org/policy Gardner, H.(1971). Application of a high-frequency consonant discrimination word list in hearing-aid evaluation. Journal of Speech and Hearing Disorders, 36 , 354-355. Guthrie, L. & Mackersie, C. (2009). A comparison of presentation levels to maximize word recognition scores. Journal of the American Academy of Audiology, 20 (6), 381-90. Hurley, R. & Sells, J. (2003). An abbreviated word recognition protocol based on item difficulty. Ear & Hearing, 24 (2), 111-118. Killion, M., Niquette, P., Gudmundsen, G., Revit, L., & Banerjee, S. (2004). Development of a quick speech-in-noise test for measuring signal-to-noise ratio loss in normal-hearing and hearing-impaired listeners. Journal of the Acoustical Society of America, 116 (4 Pt 1), 2395-405. Nabelek, A., Freyaldenhoven, M., Tampas, J., Burchfield, S., & Muenchen, R. (2006). Acceptable noise level as a predictor of hearing aid use. Journal of the American Academy of Audiology, 17 , 626-639. Nabelek, A., Tucker, F., & Letowski, T. (1991). Toleration of background noises: Relationship with patterns of hearing aid use by elderly persons. Journal of Speech and Hearing Research, 34 , 679-685. Nilsson, M., Soli. S,, & Sullivan, J. (1994). Development of the hearing in noise test for the measurement of speech reception thresholds in quiet and in noise. Journal of the Acoustical Society of America, 95 (2), 1085-99. Thornton, A.. & Raffin, M, (1978). Speech-discrimination scores modeled as a binomial variable. Journal of Speech and Hearing Research, 21 , 507-518. Tillman, T., & Jerger, J. (1959). Some factors affecting the spondee threshold in normal-hearing subjects. Journal of Speech and Hearing Research, 2 , 141-146.

Chair, Communication Sciences and Disorders, Adelphi University
Janet Schoepflin is an Associate Professor and Chair of the Department of Communication Sciences and Disorders at Adelphi University and a member of the faculty of the Long Island AuD Consortium. Her areas of research interest include speech perception in children and adults, particularly those with hearing loss, and the effects of noise on audition and speech recognition performance.
Related Courses
Using gsi for cochlear implant evaluations, course: #39682 level: introductory 1 hour, empowerment and behavioral insights in client decision making, presented in partnership with nal, course: #37124 level: intermediate 1 hour, cognition and audition: supporting evidence, screening options, and clinical research, course: #37381 level: introductory 1 hour, innovative audiologic care delivery, course: #38661 level: intermediate 4 hours, aurical hit applications part 1 - applications for hearing instrument fittings and beyond, course: #28678 level: intermediate 1 hour.
Our site uses cookies to improve your experience. By using our site, you agree to our Privacy Policy .
- Audiometers
- Tympanometers
- Hearing Aid Fitting
- Research Systems
- Research Unit
- ACT Research
- Our History
- Distributors
- Sustainability
- Environmental Sustainability
Training in Speech Audiometry
- Why Perform Functional Hearing Tests?
- Performing aided speech testing to validate pediatric hearing devices
Speech Audiometry: An Introduction
Description, table of contents, what is speech audiometry, why perform speech audiometry.
- Contraindications and considerations
Audiometers that can perform speech audiometry
How to perform speech audiometry, results interpretation, calibration for speech audiometry.
Speech audiometry is an umbrella term used to describe a collection of audiometric tests using speech as the stimulus. You can perform speech audiometry by presenting speech to the subject in both quiet and in the presence of noise (e.g. speech babble or speech noise). The latter is speech-in-noise testing and is beyond the scope of this article.
Speech audiometry is a core test in the audiologist’s test battery because pure tone audiometry (the primary test of hearing sensitivity) is a limited predictor of a person’s ability to recognize speech. Improving an individual’s access to speech sounds is often the main motivation for fitting them with a hearing aid. Therefore, it is important to understand how a person with hearing loss recognizes or discriminates speech before fitting them with amplification, and speech audiometry provides a method of doing this.
A decrease in hearing sensitivity, as measured by pure tone audiometry, results in greater difficulty understanding speech. However, the literature also shows that two individuals of the same age with similar audiograms can have quite different speech recognition scores. Therefore, by performing speech audiometry, an audiologist can determine how well a person can access speech information.
Acquiring this information is key in the diagnostic process. For instance, it can assist in differentiating between different types of hearing loss. You can also use information from speech audiometry in the (re)habilitation process. For example, the results can guide you toward the appropriate amplification technology, such as directional microphones or remote microphone devices. Speech audiometry can also provide the audiologist with a prediction of how well a subject will hear with their new hearing aids. You can use this information to set realistic expectations and help with other aspects of the counseling process.
Below are some more examples of how you can use the results obtained from speech testing.
Identify need for further testing
Based on the results from speech recognition testing, it may be appropriate to perform further testing to get more information on the nature of the hearing loss. An example could be to perform a TEN test to detect a dead region or to perform the Audible Contrast Threshold (ACT™) test .
Inform amplification decisions
You can use the results from speech audiometry to determine whether binaural amplification is the most appropriate fitting approach or if you should consider alternatives such as CROS aids.
You can use the results obtained through speech audiometry to discuss and manage the amplification expectations of patients and their communication partners.
Unexpected asymmetric speech discrimination, significant roll-over , or particularly poor speech discrimination may warrant further investigation by a medical professional.
Non-organic hearing loss
You can use speech testing to cross-check the results from pure tone audiometry for suspected non‑organic hearing loss.
Contraindications and considerations when performing speech audiometry
Before speech audiometry, it is important that you perform pure tone audiometry and otoscopy. Results from these procedures can reveal contraindications to performing speech audiometry.
Otoscopic findings
Speech testing using headphones or inserts is generally contraindicated when the ear canal is occluded with:
- Foreign body
- Or infective otitis externa
In these situations, you can perform bone conduction speech testing or sound field testing.
Audiometric findings
Speech audiometry can be challenging to perform in subjects with severe-to-profound hearing losses as well as asymmetrical hearing losses where the level of stimulation and/or masking noise required is beyond the limits of the audiometer or the patient's uncomfortable loudness levels (ULLs).
Subject variables
Depending on the age or language ability of the subject, complex words may not be suitable. This is particularly true for young children and adults with learning disabilities or other complex presentations such as dementia and reduced cognitive function.
You should also perform speech audiometry in a language which is native to your patient. Speech recognition testing may not be suitable for patients with expressive speech difficulties. However, in these situations, speech detection testing should be possible.
Before we discuss speech audiometry in more detail, let’s briefly consider the instrumentation to deliver the speech stimuli. As speech audiometry plays a significant role in diagnostic audiometry, many audiometers include – or have the option to include – speech testing capabilities.
Table 1 outlines which audiometers from Interacoustics can perform speech audiometry.
| Clinical audiometer | |
| Diagnostic audiometer | |
| Diagnostic audiometer | |
| Equinox 2.0 | PC-based audiometer |
| Portable audiometer | |
| Hearing aid fitting system | |
| Hearing aid fitting system |
Table 1: Audiometers from Interacoustics that can perform speech audiometry.
Because speech audiometry uses speech as the stimulus and languages are different across the globe, the way in which speech audiometry is implemented varies depending on the country where the test is being performed. For the purposes of this article, we will start with addressing how to measure speech in quiet using the international organization of standards ISO 8252-3:2022 as the reference to describe the terminology and processes encompassing speech audiometry. We will describe two tests: speech detection testing and speech recognition testing.
Speech detection testing
In speech detection testing, you ask the subject to identify when they hear speech (not necessarily understand). It is the most basic form of speech testing because understanding is not required. However, it is not commonly performed. In this test, words are normally presented to the ear(s) through headphones (monaural or binaural testing) or through a loudspeaker (binaural testing).
Speech detection threshold (SDT)
Here, the tester will present speech at varying intensity levels and the patient identifies when they can detect speech. The goal is to identify the level at which the patient detects speech in 50% of the trials. This is the speech detection threshold. It is important not to confuse this with the speech discrimination threshold. The speech discrimination threshold looks at a person’s ability to recognize speech and we will explain it later in this article.
The speech detection threshold has been found to correlate well with the pure tone average, which is calculated from pure tone audiometry. Because of this, the main application of speech detection testing in the clinical setting is confirmation of the audiogram.
Speech recognition testing
In speech recognition testing, also known as speech discrimination testing, the subject must not only detect the speech, but also correctly recognize the word or words presented. This is the most popular form of speech testing and provides insights into how a person with hearing loss can discriminate speech in ideal conditions.
Across the globe, the methods of obtaining this information are different and this often leads to confusion about speech recognition testing. Despite there being differences in the way speech recognition testing is performed, there are some core calculations and test parameters which are used globally.
Speech recognition testing: Calculations
There are two main calculations in speech recognition testing.
1. Speech recognition threshold (SRT)
This is the level in dB HL at which the patient recognizes 50% of the test material correctly. This level will differ depending on the test material used. Some references describe the SRT as the speech discrimination threshold or SDT. This can be confusing because the acronym SDT belongs to the speech detection threshold. For this reason, we will not use the term discrimination but instead continue with the term speech recognition threshold.
2. Word recognition score (WRS)
In word recognition testing, you present a list of phonetically balanced words to the subject at a single intensity and ask them to repeat the words they hear. You score if the patient repeats these words correctly or incorrectly. This score, expressed as a percentage of correct words, is calculated by dividing the number of words correctly identified by the total number of words presented.
In some countries, multiple word recognition scores are recorded at various intensities and plotted on a graph. In other countries, a single word recognition score is performed using a level based on the SRT (usually presented 20 to 40 dB louder than the SRT).
Speech recognition testing: Parameters
Before completing a speech recognition test, there are several parameters to consider.
1. Test transducer
You can perform speech recognition testing using air conduction, bone conduction, and speakers in a sound-field setup.
2. Types of words
Speech recognition testing can be performed using a variety of different words or sentences. Some countries use monosyllabic words such as ‘boat’ or ‘cat’ whereas other countries prefer to use spondee words such as ‘baseball’ or ‘cowboy’. These words are then combined with other words to create a phonetically balanced list of words called a word list.
3. Number of words
The number of words in a word list can impact the score. If there are too few words in the list, then there is a risk that not enough data points are acquired to accurately calculate the word recognition score. However, too many words may lead to increased test times and patient fatigue. Word lists often consist of 10 to 25 words.
You can either score words as whole words or by the number of phonemes they contain.
An example of scoring can be illustrated by the word ‘boat’. When scoring using whole words, anything other than the word ‘boat’ would result in an incorrect score.
However, in phoneme scoring, the word ‘boat’ is broken down into its individual phonemes: /b/, /oa/, and /t/. Each phoneme is then scored as a point, meaning that the word boat has a maximum score of 3. An example could be that a patient mishears the word ‘boat’ and reports the word to be ‘float’. With phoneme scoring, 2 points would be awarded for this answer whereas in word scoring, the word float would be marked as incorrect.
5. Delivery of material
Modern audiometers have the functionality of storing word lists digitally onto the hardware of the device so that you can deliver a calibrated speech signal the same way each time you test a patient. This is different from the older methods of testing using live voice or a CD recording of the speech material. Using digitally stored and calibrated speech material in .wav files provides the most reliable and repeatable results as the delivery of the speech is not influenced by the tester.
6. Aided or unaided
You can perform speech recognition testing either aided or unaided. When performing aided measurements, the stimulus is usually played through a loudspeaker and the test is recorded binaurally.
Global examples of how speech recognition testing is performed and reported
Below are examples of how speech recognition testing is performed in the US and the UK. This will show how speech testing varies across the globe.
Speech recognition testing in the US: Speech tables
In the US, the SRT and WRS are usually performed as two separate tests using different word lists for each test. The results are displayed in tables called speech tables.
The SRT is the first speech test which is performed and typically uses spondee words (a word with two equally stressed syllables, such as ‘hotdog’) as the stimulus. During this test, you present spondee words to the patient at different intensities and a bracketing technique establishes the threshold at where the patient correctly identifies 50% of the words.
In the below video, we can see how an SRT is performed using spondee words.
Below, you can see a table showing the results from an SRT test (Figure 1). Here, we can see that the SRT has been measured in each ear. The table shows the intensity at which the SRT was found as well as the transducer, word list, and the level at which masking noise was presented (if applicable). Here we see an unaided SRT of 30 dB HL in both the left and right ears.

Once you have established the intensity of the SRT in dB HL, you can use it to calculate the intensity to present the next list of words to measure the WRS. In WRS testing, it is common to start at an intensity of between 20 dB and 40 dB louder than the speech recognition threshold and to use a different word list from the SRT. The word lists most commonly used in the US for WRS are the NU-6 and CID-W22 word lists.
In word recognition score testing, you present an entire word list to the test subject at a single intensity and score each word based on whether the subject can correctly repeat it or not. The results are reported as a percentage.
The video below demonstrates how to perform the word recognition score.
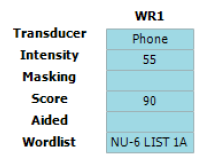
Below is an image of a speech table showing the word recognition score in the left ear using the NU‑6 word list at an intensity of 55 dB HL (Figure 2). Here we can see that the patient in this example scored 90%, indicating good speech recognition at moderate intensities.
Speech recognition testing in the UK: Speech audiogram
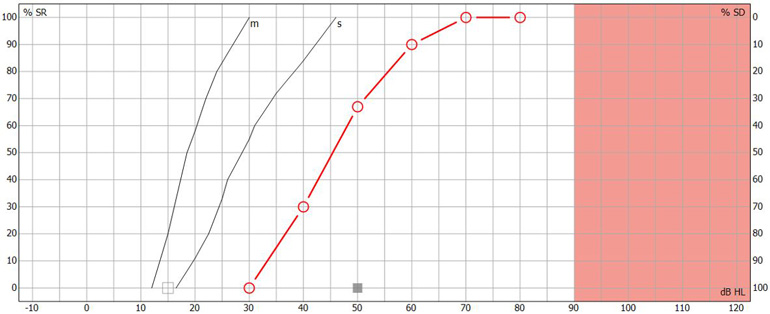
In the UK, speech recognition testing is performed with the goal of obtaining a speech audiogram. A speech audiogram is a graphical representation of how well an individual can discriminate speech across a variety of intensities (Figure 3).
In the UK, the most common method of recording a speech audiogram is to present several different word lists to the subject at varying intensities and calculate multiple word recognition scores. The AB (Arthur Boothroyd) word lists are the most used lists. The initial list is presented around 20 to 30 dB sensation level with subsequent lists performed at quieter intensities before finally increasing the sensation level to determine how well the patient can recognize words at louder intensities.
The speech audiogram is made up of plotting the WRS at each intensity on a graph displaying word recognition score in % as a function of intensity in dB HL. The following video explains how it is performed.
Below is an image of a completed speech audiogram (Figure 4). There are several components.
Point A on the graph shows the intensity in dB HL where the person identified 50% of the speech material correctly. This is the speech recognition threshold or SRT.
Point B on the graph shows the maximum speech recognition score which informs the clinician of the maximum score the subject obtained.
Point C on the graph shows the reference speech recognition curve; this is specific to the test material used (e.g., AB words) and method of presentation (e.g., headphones), and shows a curve which describes the median speech recognition scores at multiple intensities for a group of normal hearing individuals.

Having this displayed on a single graph can provide a quick and easy way to determine and analyze the ability of the person to hear speech and compare their results to a normative group. Lastly, you can use the speech audiogram to identify roll-over. Roll-over occurs when the speech recognition deteriorates at loud intensities and can be a sign of retro-cochlear hearing loss. We will discuss this further in the interpretation section.
Masking in speech recognition testing
Just like in audiometry, cross hearing can also occur in speech audiometry. Therefore, it is important to mask the non-test ear when testing monaurally. Masking is important because word recognition testing is usually performed at supra-threshold levels. Speech encompasses a wide spectrum of frequencies, so the use of narrowband noise as a masking stimulus is not appropriate, and you need to modify the masking noise for speech audiometry. In speech audiometry, speech noise is typically used to mask the non-test ear.
There are several approaches to calculating required masking noise level. An equation by Coles and Priede (1975) suggests one approach which applies to all types of hearing loss (sensorineural, conductive, and mixed):
- Masking level = D S plus max ABG NT minus 40 plus E M
It considers the following factors.
1. Dial setting
D S is the level of dial setting in dB HL for presentation of speech to the test ear.
2. Air-bone gap
Max ABG NT is the maximum air-bone gap between 250 to 4000 Hz in the non‑test ear.
3. Interaural attenuation
Interaural attenuation: The value of 40 comes from the minimum interaural attenuation for masking in audiometry using headphones (for insert earphones, this would be 55 dB).
4. Effective masking
E M is effective masking. Modern audiometers are calibrated in E M , so you don’t need to include this in the calculation. However, if you are using an old audiometer calibrated to an older calibration standard, then you should calculate the E M .
You can calculate it by measuring the difference in the speech dial setting presented to normal listeners at a level that yields a score of 95% in quiet and the noise dial setting presented to the same ear that yields a score less than 10%.
You can use the results from speech audiometry for many purposes. The below section describes these applications.
1. Cross-check against pure tone audiometry results
The cross-check principle in audiology states that no auditory test result should be accepted and used in the diagnosis of hearing loss until you confirm or cross-check it by one or more independent measures (Hall J. W., 3rd, 2016). Speech-in-quiet testing serves this purpose for the pure tone audiogram.
The following scores and their descriptions identify how well the speech detection threshold and the pure tone average correlate (Table 2).
| 6 dB or less | Good |
| 7 to 12 dB | Adequate |
| 13 dB or more | Poor |
Table 2: Correlation between speech detection threshold and pure tone average.
If there is a poor correlation between the speech detection threshold and the pure tone average, it warrants further investigation to determine the underlying cause or to identify if there was a technical error in the recordings of one of the tests.
2. Detect asymmetries between ears
Another core use of speech audiometry in quiet is to determine the symmetry between the two ears and whether it is appropriate to fit binaural amplification. Significant differences between ears can occur when there are two different etiologies causing hearing loss.
An example of this could be a patient with sensorineural hearing loss who then also contracts unilateral Meniere’s disease . In this example, it would be important to understand if there are significant differences in the word recognition scores between the two ears. If there are significant differences, then it may not be appropriate for you to fit binaural amplification, where other forms of amplification such as contralateral routing of sound (CROS) devices may be more appropriate.
3. Identify if further testing is required
The results from speech audiometry in quiet can identify whether further testing is required. This could be highlighted in several ways.
One example could be a severe difference in the SRT and the pure tone average. Another example could be significant asymmetries between the two ears. Lastly, very poor speech recognition scores in quiet might also be a red flag for further testing.
In these examples, the clinician might decide to perform a test to detect the presence of cochlear dead regions such as the TEN test or an ACT test to get more information.
4. Detect retro-cochlear hearing loss
In subjects with retro-cochlear causes of hearing loss, speech recognition can begin to deteriorate as sounds are made louder. This is called ‘roll-over’ and is calculated by the following equation:
- Roll-over index = (maximum score minus minimum score) divided by maximum score
If roll-over is detected at a certain value (the value is dependent on the word list chosen for testing but is commonly larger than 0.4), then it is considered to be a sign of retro-cochlear pathology. This could then have an influence on the fitting strategy for patients exhibiting these results.
It is important to note however that as the cross-check principle states, you should interpret any roll-over with caution and you should perform additional tests such as acoustic reflexes , the reflex decay test, or auditory brainstem response measurements to confirm the presence of a retro-cochlear lesion.
5. Predict success with amplification
The maximum speech recognition score is a useful measure which you can use to predict whether a person will benefit from hearing aids. More recent, and advanced tests such as the ACT test combined with the Acceptable Noise Level (ANL) test offer good alternatives to predicting hearing success with amplification.
Just like in pure tone audiometry, the stimuli which are presented during speech audiometry require annual calibration by a specialized technician ster. Checking of the transducers of the audiometer to determine if the speech stimulus contains any distortions or level abnormalities should also be performed daily. This process replicates the daily checks a clinicians would do for pure tone audiometry. If speech is being presented using a sound field setup, then you can use a sound level meter to check if the material is being presented at the correct level.
The next level of calibration depends on how the speech material is delivered to the audiometer. Speech material can be presented in many ways including live voice, CD, or installed WAV files on the audiometer. Speech being presented as live voice cannot be calibrated but instead requires the clinician to use the VU meter on the audiometer (which indicates the level of the signal being presented) to determine if they are speaking at the correct intensity. Speech material on a CD requires daily checks and is also performed using the VU meter on the audiometer. Here, a speech calibration tone track on the CD is used, and the VU meter is adjusted accordingly to the desired level as determined by the manufacturer of the speech material.
The most reliable way to deliver a speech stimulus is through a WAV file. By presenting through a WAV file, you can skip the daily tone-based calibration as this method allows you to calibrate the speech material as part of the annual calibration process. This saves the clinician time and ensures the stimulus is calibrated to the same standard as the pure tones in their audiometer. To calibrate the WAV file stimulus, the speech material is calibrated against a speech calibration tone. This is stored on the audiometer. Typically, a 1000 Hz speech tone is used for the calibration and the calibration process is the same as for a 1000 Hz pure tone calibration.
Lastly, if the speech is being presented through the sound field, a calibration professional should perform an annual sound field speaker calibration using an external free field microphone aimed directly at the speaker from the position of the patient’s head.
Coles, R. R., & Priede, V. M. (1975). Masking of the non-test ear in speech audiometry . The Journal of laryngology and otology , 89 (3), 217–226.
Graham, J. Baguley, D. (2009). Ballantyne's Deafness, 7th Edition. Whiley Blackwell.
Hall J. W., 3rd (2016). Crosscheck Principle in Pediatric Audiology Today: A 40-Year Perspective . Journal of audiology & otology , 20 (2), 59–67.
Katz, J. (2009). Handbook of Clinical Audiology. Wolters Kluwer.
Killion, M. C., Niquette, P. A., Gudmundsen, G. I., Revit, L. J., & Banerjee, S. (2004). Development of a quick speech-in-noise test for measuring signal-to-noise ratio loss in normal-hearing and hearing-impaired listeners . The Journal of the Acoustical Society of America , 116 (4), 2395–2405.
Stach, B.A (1998). Clinical Audiology: An Introduction, Cengage Learning.

Popular Academy Advancements
What is nhl-to-ehl correction, getting started: assr, what is the ce-chirp® family of stimuli, nhl-to-ehl correction for abr stimuli.
- Find a distributor
- Customer stories
- Made Magazine
- ABR equipment
- OAE devices
- Hearing aid fitting systems
- Balance testing equipment
Certificates
- Privacy policy
- Cookie Policy

An official website of the United States government
The .gov means it’s official. Federal government websites often end in .gov or .mil. Before sharing sensitive information, make sure you’re on a federal government site.
The site is secure. The https:// ensures that you are connecting to the official website and that any information you provide is encrypted and transmitted securely.
- Publications
- Account settings
Preview improvements coming to the PMC website in October 2024. Learn More or Try it out now .
- Advanced Search
- Journal List
- HHS Author Manuscripts
A Comparison of Presentation Levels to Maximize Word Recognition Scores
While testing suprathreshold word recognition at multiple levels is considered best practice, studies on practice patterns do not suggest that this is common practice. Audiologists often test at a presentation level intended to maximize recognition scores, but methods for selecting this level are not well established for a wide range of hearing losses.
To determine the presentation level methods that resulted in maximum suprathreshold phoneme-recognition scores while avoiding loudness discomfort.
Research Design
Performance-intensity functions were obtained for 40 participants with sensorineural hearing loss using the Computer-Assisted Speech Perception Assessment. Participants had either gradually sloping (mild, moderate, moderately severe/severe) or steeply sloping losses. Performance-intensity functions were obtained at presentation levels ranging from 10 dB above the SRT to 5 dB below the UCL (uncomfortable level). In addition, categorical loudness ratings were obtained across a range of intensities using speech stimuli. Scores obtained at UCL – 5 dB (maximum level below loudness discomfort) were compared to four alternative presentation-level methods. The alternative presentation-level methods included sensation level (SL; 2 kHz reference, SRT reference), a fixed-level (95 dB SPL) method, and the most comfortable loudness level (MCL).
For the SL methods, scores used in the analysis were selected separately for the SRT and 2 kHz references based on several criteria. The general goal was to choose levels that represented asymptotic performance while avoiding loudness discomfort. The selection of SLs varied across the range of hearing losses.
Scores obtained using the different presentation-level methods were compared to scores obtained using UCL – 5 dB. For the mild hearing loss group, the mean phoneme scores were similar for all presentation levels. For the moderately severe/severe group, the highest mean score was obtained using UCL - 5 dB. For the moderate and steeply sloping groups, the mean scores obtained using 2 kHz SL were equivalent to UCL - 5 dB, whereas scores obtained using the SRT SL were significantly lower than those obtained using UCL - 5 dB. The mean scores corresponding to MCL and 95 dB SPL were significantly lower than scores for UCL - 5 dB for the moderate and the moderately severe/severe group.
Conclusions
For participants with mild to moderate gradually sloping losses and for those with steeply sloping losses, the UCL – 5 dB and the 2 kHz SL methods resulted in the highest scores without exceeding listeners' UCLs. For participants with moderately severe/severe losses, the UCL - 5 dB method resulted in the highest phoneme recognition scores.
Speech recognition measures are widely recognized as an important component of the audiological test battery. Although there are professional guidelines for administering speech recognition threshold tests ( American Speech-Language-Hearing Association, 1988 ), procedures related to suprathreshold speech recognition testing have never been standardized. It has been argued that the best approach to speech recognition testing is to present stimuli over a range of levels ( Boothroyd, 1968 ; Ullrich and Grimm, 1976 ; Beattie and Warren, 1982 ; Beattie and Raffin, 1985 ; Beattie and Zipp, 1990 ; Boothroyd, 2008 ). This argument is supported by evidence that the level corresponding to maximum word recognition scores varies considerably across individuals. Beattie and Raffin (1985) , for example, reported that levels corresponding to maximum recognition scores can vary from 20 to 60 dB SL.
While these studies provide evidence that testing speech recognition in quiet at multiple levels is the best practice, the use of multiple presentation levels is not common in clinical settings ( Martin and Forbis, 1978 ; Martin and Morris, 1989 ; DeBow and Green, 2000 ). In a study on the practice patterns of Canadian audiologists, 89% of the respondents reported that they did not test at multiple presentation levels ( DeBow and Green, 2000 ). In another study on practice patterns of audiologists, 74% of the respondents reported using a single SL; however, the level used was not specified ( Martin and Morris, 1989 ). Martin and Morris (1989) also reported that “several” respondents reported using more than one level in speech recognition testing, with the most common levels being most comfortable level (MCL) and 90 dB HL.
When a single presentation level is used to assess suprathreshold word recognition abilities during routine diagnostic testing, a common objective is to test at a level that will result in maximum performance. With this objective in mind, a presentation level that results in maximum performance may be considered the “optimal presentation level.” Methods for determining the presentation level for suprathreshold speech testing fall into three broad categories: (1) methods based on SL, a fixed level above a reference threshold; (2) methods based on a fixed sound pressure level (SPL); and (3) methods based on loudness measures (e.g., most comfortable loudness level).
The most popular approach is to set the presentation level at a particular SL above the speech recognition threshold (SRT). Martin and Morris (1989) noted that over half of the 74% of audiologists who used a single presentation level chose a level of 40 dB SL re SRT, while 30% used a level of 30 dB SL re SRT. In a later survey, Martin et al (1998) also noted that 67% of audiologists used a level referenced to the SRT, but a specific SL was not reported. Similar to their 1989 survey, Martin et al (1994) reported that 75% of audiologists tested at a specified SL, typically 40 dB SL. It is important to note, however, that the 40 dB SL presentation level re SRT is likely to reach uncomfortable loudness levels for the majority of people with an average hearing loss greater than 50 dB HL ( Kamm et al, 1978 ).
Kamm and her colleagues suggested using a fixed level of 95 dB SPL (75 dB HL) as an alternative to 40 dB SL ( Kamm et al, 1983 ). For listeners with mild to moderate sensorineural hearing loss, Kamm et al reported that maximum word recognition scores were obtained for only 60% of the participants when the 40 dB SL re SRT method was used, but maximum word recognition scores were obtained for 76% of the participants when a presentation level of 95 dB SPL was used.
As noted earlier, some clinicians also test at both the most comfortable loudness level (MCL) and a higher level approaching the uncomfortable loudness level (UCL). Testing at MCL seems logical given that “comfortable loudness” is a rationale underlying several hearing aid fitting prescriptions. There is little evidence, however, to support the MCL approach for testing word recognition in individuals with hearing loss, if finding the maximum speech recognition score is the goal. While maximum scores are generally obtained at MCL for listeners with normal hearing, higher levels are often needed for individuals with hearing loss ( Ullrich and Grimm, 1976 ; Beattie and Warren, 1982 ; Beattie and Raffin, 1985 ; Beattie and Zipp, 1990 ).
There is inconsistent support for the use of speech UCL as a presentation level. In two studies, Beattie and his colleagues reported that the level corresponding to maximum recognition scores was the same as the UCL for 79–90% of the cases ( Beattie and Warren, 1982 ; Beattie and Zipp, 1990 ). Dirks et al (1981) reported, however, that recognition scores for words presented below the listeners' UCLs were equal to or better than scores presented at UCL.
Most of the work evaluating different methods for obtaining the maximum word recognition score has been conducted using patients with mild to moderate hearing losses. The present study extends the work of previous investigators described above by evaluating a wider range of hearing losses and by examining additional methods for determining the optimal presentation level for suprathreshold speech recognition testing. For the purposes of this study, the “optimal presentation level” was defined as the level that produced the maximum speech recognition score without exceeding the participant's UCL. Listener groups consisted of people with gradually sloping mild, moderate, and moderately severe/severe losses. In addition, a group of individuals with steeply sloping losses was included to examine the impact of hearing loss configuration.
Five different presentation levels were evaluated:
- 1) A fixed level of 95 dB SPL as recommended by Kamm et al. (1983)
- 2) The individually-determined MCL
- 3) 5 dB below the individually-determined UCL
- 4) A sensation level referenced to the SRT
- 5) A sensation level referenced to the 2-kHz threshold
The choice of sensation levels varied with the degree of hearing loss and was determined from several criteria including UCL (described below). A sensation level referenced to 2-kHz was evaluated as an alternative to the sensation level re: SRT due to the importance of 2-kHz for consonant recognition ( French and Steinberg, 1947 ). A sensation level referenced to the 2-kHz threshold rather than the SRT may result in better audibility in the high-frequency regions, particularly for individuals with steeply sloping losses. The UCL-5 dB was evaluated because it should maximize audibility while avoiding the problem of loudness discomfort. To the extent that maximum audibility corresponds to maximum intelligibility, the UCL-5 dB level may serve as the “gold standard” against which the other methods can be compared.
The general approach used in the present study was to measure phoneme recognition over a range of levels. Recognition scores were then extracted for the five different presentation-level methods of interest. Based on the importance of the 2-kHz region for speech intelligibility, it was predicted that the scores obtained using a sensation level referenced to the 2-kHz threshold would result in scores equivalent to those for UCL- 5 dB. Based on previous research, it was also expected that scores for MCL would be lower than for UCL-5 dB for one or more participant groups. Specific predictions were not formulated for the other presentation levels.
Participants
Forty adults with sensorineural hearing loss participated in the study. The mean age of the participants was 71.7 years, with a range of 45–90 years. Participants were categorized according to the degree and configuration of their hearing loss. Thirty participants with gradually sloping hearing loss had less than a 20 dB difference between 1- and 2-kHz thresholds. The participants with gradually sloping loss were further classified based on their three-frequency (0.5, 1, 2-kHz) pure-tone averages (PTA) into mild (PTA of 26–40 dB HL), moderate (PTA of 41–55 dB HL), or moderately-severe/severe (PTA of 56–75 dB HL) hearing loss groups. Ten participants were included in each group.
Ten participants with steeply sloping audiometric configurations were also evaluated. Participants with steeply sloping high-frequency hearing loss had a 20 dB or greater difference between 1 and 2-kHz thresholds, a mean PTA of 48 dB HL, and a mean Fletcher average of 28 dB HL. The Fletcher average is the average of the two lowest pure-tone thresholds at octave frequencies between 0.5 and 2-kHz. This average is often used in lieu of the pure-tone average when there is a greater than 20 dB difference between two adjacent frequencies in the pure-tone average ( Fletcher, 1950 ). Mean pure-tone thresholds for the four participant groups are shown in Figure 1 .

Mean audiograms for the four participant groups. The error bars indicate ± 1 SD.
Air and bone conduction pure-tone thresholds were obtained for both ears using the standard Hughson-Westlake procedure ( Hughson and Westlake, 1944 ). Pure-tone stimuli were delivered through a Grason-Stadler 61 audiometer and were routed to TDH-50 headphones and a B-71 bone oscillator.
For all remaining procedures, participants were tested monaurally. The test ear was chosen randomly. The speech-recognition threshold (SRT) was obtained using the Downs and Minard (1996) procedure. The Downs and Minard procedure is an ascending speech recognition threshold search. Following a familiarization phase, one word was presented at each level and the level was increased in 10 dB steps until one word was repeated correctly. The level was then reduced by 15 dB and two, three or four words were presented at each level. The level was increased in 5 dB steps until the participant repeated two words correctly at a given level. This level was taken as the SRT. This procedure was chosen for its efficiency and high correlation with the pure-tone average ( Downs and Minard, 1996 ). Speech stimuli for the SRT consisted of spondees digitized from the Department of Veterans Affairs Speech Recognition and Identification Materials Compact Disc 2.0 ( Wilson and Strouse, 1998 ). Stimuli were played from a computer using custom-written software and were routed through the speech channel of an audiometer to TDH-50 headphones.
Categorical loudness ratings were completed to determine MCL and UCL. Participants were asked to rate the subjective loudness of brief (½ second) speech stimuli (female talker saying `ah-ah') using a procedure described by Hawkins, Walden, Montgomery, and Prosek (1987) . The loudness of the speech stimuli was rated on a categorical scale ranging from `cannot hear' to `uncomfortably loud'. Loudness categories and numerical anchors were as follows: 1 = `cannot hear', 2= `very soft', 3 = `soft', 4 = `comfortable, but slightly soft', 5 = `comfortable', 6 = `comfortable, but slightly loud', 7 = `loud, but ok', and 8 = `uncomfortably loud'. The initial presentation level was set at 10 dB above the participant's SRT, and the level of the voice was increased in 5 dB steps until the participant rated the level as `uncomfortably loud' (UCL). The participant's rating and the corresponding level were recorded for each presentation. This procedure was then repeated using a varied starting level of ±10 dB from the starting level of the initial estimate. If the level corresponding to `uncomfortably loud' on the second trial differed by more than 5 dB from the first trial, the procedure was repeated a third time. The higher of the two values within 5 dB of each other was taken as the UCL. Values were within 5 dB for all participants by the second or third trial. A rating of `5' was used as MCL. If more than one level was rated as a `5' within an ascending series, the midpoint of the range was used if there were an odd number of levels with the same rating and the highest value was used if there were an even number of levels with the same rating. The final estimate of MCL was taken as the highest of the values that was rated as a `5' across the two to three trials. The levels corresponding to MCL were within 5 dB for all participants by the second or third trial.
Supra-threshold speech recognition testing was completed using the Computer-Assisted Speech Perception Assessment (CASPA) ( Boothroyd, 1999 ; Boothroyd, 2008 ; Mackersie, Boothroyd and Minniear, 2001 ). The CASPA consists of twenty lists of ten monosyllabic consonant-vowel-consonant (CVC) words. Sixteen of the twenty lists were used. The sixteen lists used have been shown to be equivalent in difficulty ( Mackersie, Boothroyd and Minnear, 2001 ). In addition, the order in which the lists were presented was randomly selected for each listener. This software allows for computer-assisted phoneme scoring by having the examiner assign one point to each phoneme repeated correctly in the word for a total of three points per word and 30 phonemes per list. The speech stimuli were routed through the speech channel of the audiometer to the TDH-50 headphones.
Test presentation levels ranged from 10 dB above the SRT to 5 dB below the UCL. A practice list was presented at a level corresponding to 10 dB below the most comfortable loudness level (MCL). Following the practice list, the presentation level was increased in 10 dB steps from MCL to a maximum level of 5 dB below the UCL. The presentation level was then decreased in 10 dB steps in order to complete testing at the levels not used in the ascending run, with the final list presented at a level of 10 dB above the SRT. A step size of 5 dB was used when an increase of 10 dB would have exceeded UCL or when a decrease of 10 dB would have been below the minimum test level. The resulting performance-intensity level function provided phoneme recognition in 5-dB steps. For example, if a participant's SRT was 35 dB HL, MCL was 60 dB HL and the UCL was 90 dB HL, the order of presentation levels would be: 60, 70, 80, and 85 dB HL (ascending) followed by 75, 65, 55, 50, and 45 dB HL (descending). Contralateral masking was used as needed.
Determination of Sensation Levels for Analysis of Recognition Scores
Separate sensation levels were chosen for the 2-kHz and SRT references. It is important to note that for the purposes of this study, the term “ 2-kHz sensation-level reference ” refers to the audiometer dial settings for a speech signal. The true sensation level of the speech signal at 2-kHz would be different because at a given dial setting, there are differences between the speech and pure-tone energy at 2-kHz.
After determining the sensation levels of interest, corresponding recognition scores from the performance/intensity function were used for subsequent analysis. The general goal was to choose the highest sensation level possible within the constraints of three criteria. These criteria were:
- 1) The level was below UCL for all participants
- 2) The choice of sensation level for different degrees of hearing loss resulted in a monotonic relationship between the range of reference thresholds (2-kHz, SRT) and the corresponding increase in dB HL output. That is, as the reference threshold increased, the output value in dB HL (after adding the sensation level) always increased or stayed the same; the output never decreased.
- 3) Whenever possible, the sensation levels chosen represented mean asymptotic performance for each of the reference threshold ranges. For the purposes of this study, mean asymptotic performance was defined as mean scores within 5 percentage points of the individual participant's maximum score. That is, the level chosen should correspond to ceiling-level performance. In some instances it was not possible to evaluate this criterion without exceeding a listener's UCL.
UCL Levels and Hearing Loss
The sensation levels corresponding to uncomfortable loudness levels were determined separately for the SRT and the 2-kHz references. The values in Table 1 indicate the number of participants whose uncomfortable loudness levels were reached or exceeded for SRT sensation levels ranging from 20 to 40 dB (top) and for 2-kHz sensation levels ranging from 10–30 dB.
Number of participants for whom speech levels reached and/or exceeded UCL for the SRT sensation levels (top) and 2-kHz threshold (dial) sensation levels (bottom). The lines indicate the SRT or 2-kHz threshold values above which UCL was reached for at least one participant.
| SRT+20 dB | SRT+25 | SRT+30 | SRT+35 | SRT+40 | ||
|---|---|---|---|---|---|---|
| SRT | n | n =/ > UCL | n =/ > UCL | n =/ > UCL | n =/ > UCL | n =/ > UCL |
| 10 | 1 | 0 | 0 | 0 | 0 | 0 |
| 20 | 3 | 0 | 0 | 0 | 0 | 0 |
| 25 | 3 | 0 | 0 | 0 | 0 | 0 |
| 30 | 4 | 0 | 0 | 0 | 0 | 0 |
| 35 | 5 | 0 | 0 | 0 | 0 | 1 |
| 40 | 5 | 0 | 0 | 0 | 0 | 4 |
| 45 | 4 | 0 | 0 | 0 | 0 | 0 |
| 50 | 4 | 0 | 0 | 0 | 1 | 3 |
| 55 | 5 | 0 | 1 | 1 | 3 | 4 |
| 60 | 1 | 0 | 1 | 1 | 1 | 1 |
| 65 | 2 | 0 | 1 | 1 | 2 | 2 |
| 70 | 2 | 0 | 2 | 2 | 2 | 2 |
| 75 | 1 | 0 | 3 | 1 | 1 | 3 |
| 2k+10 dB | 2k+15 | 2k+20 | 2k+25 | 2k+30 | ||
|---|---|---|---|---|---|---|
| 2-kHz threshold | n | n =/ > UCL | n =/ > UCL | n =/ > UCL | n =/ > UCL | n =/ > UCL |
| 30 | 2 | 0 | 0 | 0 | 0 | 0 |
| 35 | 3 | 0 | 0 | 0 | 0 | 0 |
| 40 | 4 | 0 | 0 | 0 | 0 | 0 |
| 45 | 4 | 0 | 0 | 0 | 0 | 1 |
| 50 | 4 | 0 | 0 | 0 | 1 | 1 |
| 55 | 6 | 0 | 0 | 0 | 1 | 3 |
| 60 | 4 | 0 | 0 | 1 | 2 | 4 |
| 65 | 5 | 0 | 0 | 0 | 3 | 4 |
| 70 | 4 | 0 | 1 | 1 | 2 | 3 |
| 75 | 4 | 0 | 2 | 2 | 4 | 4 |
For an SRT sensation level of 40 dB, UCL was reached for 69% (20/29) of the participants with speech recognition thresholds of 35 dB HL and higher. These results suggest that the conventional 40 dB SL presentation level would exceed the UCL of the majority of participants. The majority of participants with SRTs of 55 dB HL and higher were unable to tolerate speech levels greater than 25 dB SL. For the 2-kHz reference, as the 2-kHz thresholds increased, there was a steady decrease in the sensation levels tolerated by all participants. All participants with 2-kHz thresholds of 55 dB HL or less were able to tolerate sensation levels of up to 20 dB HL.
For the fixed level method of 95 dB SPL, UCL was reached for two participants, one with a gradually sloping loss (PTA = 37 dB HL) and one with a steeply sloping loss (PTA = 38 dB HL). These participants were not included in the subsequent analyses of the phoneme recognition scores.
Determination of Sensation Levels
Four sensation levels were provisionally chosen for both SRT and 2-kHz references to satisfy the first two of the three criteria described earlier (below UCL, monotonic function). To satisfy the third criterion, it was necessary to determine whether the sensation levels chosen would correspond to mean asymptotic performance. Mean scores for the four SRT and 2-kHz threshold ranges are shown in Figure 2 as a function of sensation level. The filled symbols indicate the chosen sensation level for each range. As shown in left panel of Figure 2 , for the 2-kHz reference, the chosen sensation levels for the four 2-kHz threshold ranges did correspond to asymptotic performance. For sensation levels above the chosen values, mean scores either decreased or increased by less than five percentage points. For the SRT reference ( right panel ), scores for the chosen sensation levels were also within five percentage points of the maximum score except for the 45–50 dB HL range (5.8 percentage points below maximum). Although listeners with SRTs between 45–50 dB HL were able to tolerate a sensation level of 30 dB, increasing this criterion would result in a non-monotonic function with increasing hearing loss (see criterion #2). Therefore, a sensation level of 25 dB SL was used for SRTs of 45–50 dB HL. For the highest SRT range, it was not possible to evaluate the sensation level above the chosen value because this level exceeded the uncomfortable loudness level for several participants.

Mean phoneme recognition scores obtained at the different sensation levels for the 2-kHz reference (left) and SRT reference (right). The chosen sensation levels for each hearing loss range are represented by the filled symbols. The error bars represent ± 1 standard error.
Based on these analyses, the sensation levels provisionally selected for the SRT and 2-kHz references satisfy the criteria discussed earlier. The final SRT and 2-kHz references used in the phoneme recognition analyses were as follows:
- SRT < 35 dB HL: 35 dB SL
- SRT 35–40 dB HL: 30 dB SL
- SRT 45–50 dB HL: 25 dB SL
- SRT greater than 50 dB HL: 20 dB SL
- 2-kHz thresholds < 50 dB HL: 25 dB SL
- 2-kHz thresholds 50–55 dB HL: 20 dB SL
- 2-kHz thresholds 60–65 dB HL: 15 dB SL
- 2-kHz thresholds 70–75 dB HL: 10 dB SL
We applied the above criteria to select the phoneme recognition scores obtained at various levels of the performance/intensity function. These scores were used in subsequent analyses for each of the four participant groups (mild, moderate, moderately-severe/severe, steeply sloping).
The means, standard deviations and ranges of levels in dB HL are shown in Table 2 for MCL, UCL-5 dB, SL re: SRT, and SL re: 2-kHz. It can be seen that mean presentation levels increase with increasing hearing loss and vary up to 25 dB within listener groups. For mild, moderate, and moderately-severe/severe losses, the mean level in dB HL corresponding to the sensation levels for the 2-kHz and SRT methods were similar. However, for the majority of participants, there were differences between the 2-kHz and SRT HL levels of up to 15 dB for participants with mild, moderate, and moderately-severe/severe losses. For some groups, these differences may have had a greater impact on recognitions scores than for other groups. For example a difference of 10 dB in presentation levels may not affect phoneme recognition if performance is already at ceiling level. However, a 10 dB difference in presentation level may affect phoneme recognition within the linear portion of the PI function. In the next section, analyses of the recognition scores for the different presentation level are presented in detail.
Means, standard deviations, and ranges for the presentation levels corresponding to MCL, UCL, the 2-kHz sensation level method, and SRT sensation level method. All presentation levels are shown in dB HL. A level of 75 dB HL corresponds to 95 dB SPL.
| MCL | UCL-5 dB | HL for SL re: 2 kHz | HL for SL re: SRT | |
|---|---|---|---|---|
| Mild | 62.0 (6.3) | 83.5 (8.2) | 63.0 (5.9) | 65 (4.7) |
| (range) | (50–70) | (75–100) | (55–70) | (55–70) |
| Moderate | 72.5 (5.4) | 83.0 (6.8) | 73.0 (5.37) | 72.5 (2.6) |
| (range) | (65–80) | (80–100) | (65–80) | (70–75) |
| Moderately-severe | 80.5 (5.5) | 89.5 (7.3) | 80.0 (3.2) | 82.0 (8.2) |
| (range) | (70–85) | (80–105) | (75–85) | (70–95) |
| Steeply sloping | 66.0 (8.4) | 83.5 (8.5) | 75.8 (5.2) | 60.5 (7.2) |
| (range) | (50–75) | (75–105) | (70–85) | (50–70) |
| All | 70.3 | 84.9 (7.9) | 73.0 (8.1) | 70.0 (10.2) |
| (range) | (50–85) | (75–105) | (55–85) | (50–95) |
Phoneme recognition
The five presentation level methods were analyzed to determine if there were significant differences among the mean recognition scores. Mean phoneme recognition scores for the four participant groups are shown in Figure 3 . The mean scores for the mild hearing loss group were similar using the five methods. Differences among the five methods were apparent for the other participant groups.

Mean phoneme recognition scores obtained using the five different methods for the four different participant groups. The asterisks indicate a significant difference based on the post-hoc analyses. The arrows indicate which method is significantly different from UCL – 5 dB. The error bars represent ± 1 standard error.
A two-way repeated-measures analysis of variance (ANOVA) was completed using the different presentation-level methods (95 dB SPL, MCL, UCL-5 dB, SL re: SRT, SL re: 2-kHz) and hearing loss severity or configuration as factors (mild, moderate, moderately-severe/severe, steeply sloping). Phoneme scores were arcsine transformed before data analysis to stabilize the error variance ( Studebaker, 1985 ). As noted previously, a level of 95 dB SPL was uncomfortably loud for one person with a mild gradually sloping loss and one person with a steeply sloping loss. Based on the criteria adopted for this study, this level would not be appropriate because it exceeded the UCL. The analyses run with and without the 95 dB SPL scores were similar. Therefore, for illustrative purposes, scores for 95 dB SPL were included in the analyses reported here. A significant interaction was observed between presentation level method and hearing loss [F (12, 147) = 2.55, p < .01].
Newman-Keuls post-hoc analyses were completed to further evaluate differences among the five methods. The focus of the post-hoc analyses was to determine if the various presentation level methods differed from the UCL-5 dB approach, which was designated the “gold standard” for this study. A significance level of .05 was used in all analyses. In Figure 3 , significant differences between UCL-5 dB and the other four methods are indicated by asterisks and connecting arrows. For the mild hearing loss group there were no significant differences between the phoneme recognition scores obtained using any of the methods ( p > .05). For the moderate group, mean scores for all methods except the 2-kHz SL reference were significantly lower than scores for UCL-5 dB. For the steeply sloping group, only scores obtained in the SRT reference method were significantly lower than scores for UCL-5 dB. Finally, for the moderately-severe/severe group, scores for UCL-5 dB were significantly higher than scores for all the other presentation levels.
Based on these results, any of the five methods should produce equivalent results for mild gradually-sloping hearing loss. For moderately-severe/severe losses, only UCL-5 dB resulted in maximum recognition scores. Only the 2-kHz SL reference was equivalent to UCL-5 dB in the remaining two participant groups.
Individual scores
Figure 4 illustrates individual recognition scores for UCL-5 dB plotted against scores for the alternative presentation levels. Data points below the diagonal indicate nominally higher scores for UCL-5 dB. The shaded area represents the 90% confidence intervals of the binomial distribution. It can be seen that comparison methods are clustered fairly close to the diagonal (similar to UCL-5 dB scores) for mild, moderate, and steeply sloping losses. For moderately-severe/severe losses, larger deviations are apparent. The largest deviations from the UCL-5 dB scores are for the 95 dB SPL presentation level (moderately-severe/severe losses) and for the SRT reference (steeply sloping losses).

Scatterplot of phoneme recognition scores obtained using the fixed level, MCL, SRT reference, and 2-kHz reference plotted against the scores obtained using the UCL – 5 dB method for the 4 participant groups. The shaded area indicates the 90% confidence intervals based on the binomial distribution.
As a first step in determining the presentation level for maximal performance without discomfort, UCLs for speech were examined for different sensation levels. It was determined that a presentation level of 40 dB SL re: SRT exceeded UCL for 69% of those with an SRT of 35 dB HL or greater. Kamm, Dirks, and Mickey (1978) also found that 40 dB SL re: SRT exceeded UCL for the majority of participants with hearing loss greater than 50 dB HL. Based on the results of the current study, the commonly used presentation level of 40 dB SL re: SRT would exceed the loudness discomfort levels for many individuals with hearing loss. Even a more conservative level of 30 dB SL would exceed the tolerance levels of listeners with SRTs of 55 dB HL and greater.
Contrary to the prediction, the 2-kHz SL reference chosen for this study did not result in phoneme recognition scores equivalent to scores for UCL-5 dB for all participant groups. Scores for the 2-kHz SL reference were significantly lower than scores for UCL-5 dB for one of the four participant groups (moderately-severe/severe). The variability of UCLs for the different 2-kHz ranges and criteria adopted for this study prevented the use of a higher 2-kHz sensation level. Nevertheless, the findings support the use of the 2-kHz reference for all participant groups except those with moderately-severe/severe hearing loss. For the moderately-severe/severe group, only the UCL-5 dB level resulted in maximum phoneme scores.
For mild hearing losses, all five presentation levels resulted in similar phoneme scores. The sensation level re: SRT resulted in lower phoneme recognition scores than those obtained using UCL – 5 dB for all of the remaining participant groups and MCL resulted in lower phoneme recognition scores than UCL-5 dB for the moderate and moderately-severe/severe groups. The results from the present study are consistent with studies by Beattie and colleagues ( Beattie and Raffin, 1985 ; Beattie and Warren, 1982 ; Beattie and Ziff, 1990 ), who found that maximal speech recognition scores were obtained at or near UCL rather than at MCL.
The finding that scores using the SRT sensation level reference were lower than UCL-5 dB for three of the four groups may be related to the choice of sensation levels and the constraints imposed by the criteria selected. Higher sensation levels may have been used, but would have violated criteria related to the UCL, the monotonic function, or both. The lower scores for the SRT reference may be related to the fact that the SRT typically reflects the low- to mid-frequency hearing sensitivity. Thus, a level referenced to SRT may not ensure audibility at important higher frequencies such as 2-kHz. For steeply sloping hearing losses, in particular, basing the presentation level on the SRT can result in lower presentation levels, essentially filtering out crucial speech information at 2-kHz. Despite the popularity of using presentation levels referenced to the SRT, the results of the current study do not support the use of this reference level if the objective is to maximize scores for a wide range of hearing losses.
The fixed-level method (95 dB SPL) reached UCL for two participants and was, therefore, not considered optimal based on the criteria used in the study. Of the remaining 38 participants, 26% had scores for 95 dB SPL that were significantly lower than UCL-5 dB. The mean scores obtained using the 95 dB SPL method were significantly lower than those obtained using UCL – 5 dB for both the moderate and moderately-severe/severe hearing loss groups. The findings for moderate hearing loss contrast with those of Kamm et al. (1983) who found that 95 dB SPL corresponded to maximum recognition performance for most participants with mild-moderate hearing loss. However, a direct comparison is difficult because they combined mild and moderate hearing losses in their analyses.
There are several additional factors that should be considered when choosing a presentation level. One factor is related to test efficiency. For clinicians who do not routinely include speech UCL measures as part of the diagnostic battery, the use of the 2-kHz reference avoids the need for additional testing. In addition, the UCL measure is more variable than threshold measures and may require several repetitions to stabilize ( Morgan and Dirks, 1974 ). Finally, UCL-5 dB may not result in maximum word recognition scores for people whose recognition scores decrease at higher levels (i.e. rollover). A significant decrease in scores at UCL – 5 dB (based on 90% confidence intervals of the binomial distribution) was observed in two of the 40 participants in the current study. Given the potential trade-offs between efficiency and optimization of recognition scores, a hybrid method may be the best approach. This method would consist of using the 2-kHz reference for people with less than a moderately-severe/severe hearing loss and UCL – 5 dB for listeners with more severe losses. The 2-kHz reference could be used as a starting level for measuring the speech UCL with the goal of testing at UCL-5 dB.
It is important to bear in mind that results are based on data for a relatively small number of participants. No single rule will work for all listeners. As such, administration of word recognition tests at multiple presentation levels should still be considered “best practice”. Testing at multiple levels allows for the optimal listening range to be determined ( Boothroyd, 2008 ). Because phoneme scoring increases the number of scoreable items in a word list without increasing test time, it is possible to use shorter 10-word lists without compromising test sensitivity. Using this approach, measurement of phoneme recognition over a range of intensity levels becomes a clinically viable option.
While the population of participants in the present study represented a fairly wide range of sensorineural hearing losses, generalization of the findings to all degrees and configurations of hearing loss is not possible. Participants with steeply sloping losses in the present study, for example, had pure-tone averages in the mild to moderate hearing loss range. It is not known whether similar results would be found for those with more severe steeply sloping hearing losses. In addition, it is likely that the optimal presentation level, as defined in this study, would be different for people with a conductive component to the hearing loss, people with rising configurations, and people with severe to profound hearing loss. Further work should be extended to these populations.
- One method is to set the level to 5 dB below the speech UCL
- ▪ 2-kHz threshold < 50 dB HL: Use 25 dB SL re: 2-kHz
- ▪ 2-kHz threshold 50–55 dB HL: Use 20 dB SL re: 2-kHz
- ▪ 2-kHz threshold 60–65 dB HL: Use 15 dB SL re: 2-kHz
- ▪ 2-kHz threshold 70–75 dB HL: Use 10 dB SL re: 2-kHz
- For listeners with moderately-severe/severe losses, UCL-5 dB resulted in the highest phoneme recognition scores.
- A fixed level of 95 dB SPL and the conventional method using a sensation level referenced to the SRT are not supported by the results of this study if the goal is to maximize recognition scores while avoiding loudness discomfort.
Abbreviations
| CASPA | Computer-Assisted Speech Perception Assessment |
| MCL | most comfortable level |
| PTA | average of pure tone thresholds for .5, 1, and 2 kHz |
| SL | sensation level |
| UCL | uncomfortable level |
- American Speech-Language-Hearing Association Guidelines for determining threshold level for speech. ASHA. 1988:85–89. [ PubMed ] [ Google Scholar ]
- Beattie RC, Raffin MJ. Reliability of threshold, slope, and PB max for monosyllabic words. J Speech Hear Dis. 1985; 50 :166–178. [ PubMed ] [ Google Scholar ]
- Beattie RC, Warren VG. Relationships among speech threshold, loudness discomfort, comfortable loudness, and PB max in the elderly hearing impaired. Am J Otol. 1982; 3 :353–358. [ PubMed ] [ Google Scholar ]
- Beattie RC, Zipp JA. Range of intensities yielding PB max and the threshold for monosyllabic words for hearing-impaired subjects. J Speech Hear Dis. 1990; 55 :417–426. [ PubMed ] [ Google Scholar ]
- Boothroyd A. Developments in speech audiometry. Brit J Audiol. 1968; 2 :3–10. [ Google Scholar ]
- Boothroyd A. Computer-Assisted Speech Perception Assessment (CASPA) Version 3.0. 1999. computer software. [ Google Scholar ]
- Boothroyd A. The performance/intensity function: an underused resource. Ear Hear. 2008; 29 :479–491. [ PubMed ] [ Google Scholar ]
- DeBow A, Green W. A survey of Canadian audiological practices: pure tone and speech audiometry. J Speech Path Audiol. 2000; 24 :153–161. [ Google Scholar ]
- Downs D, Minard P. A fast valid method to measure speech-recognition threshold. Hear J. 1996; 49 :39–44. [ Google Scholar ]
- Dirks DD, Kamm CA, Dubno JR, Velde TM. Speech recognition performance at loudness discomfort level. Scand Audiol. 1981; 10 :239–246. [ PubMed ] [ Google Scholar ]
- Fletcher H. A method of calculating hearing loss for speech from an audiogram. J Acoust Soc Am. 1950; 22 :1–5. [ PubMed ] [ Google Scholar ]
- French NR, Steinberg JC. Factors governing the intelligibility of speech sounds. J Acoust Soc Am. 1947; 19 :90–119. [ Google Scholar ]
- Hawkins DB, Walden BE, Montgomery A, Prosek RA. Description and validation of an LDL procedure designed to select SSPL90. Ear Hear. 1987; 8 :162–169. [ PubMed ] [ Google Scholar ]
- Hughson W, Westlake H. Manual for program outline for rehabilitation of aural casualties both military and civilian. Trans. Am. Acad. Opthamol. Otolaryngol. 1944; 48 (Suppl):1–15. [ Google Scholar ]
- Kamm CA, Dirks DD, Mickey MR. Effect of sensorineural hearing loss on loudness discomfort level and most comfortable loudness judgments. J Speech Hear Res. 1978; 21 :668–681. [ PubMed ] [ Google Scholar ]
- Kamm CA, Morgan DE, Dirks DD. Accuracy of adaptive procedure estimates of PB max level. J Speech Hear Dis. 1983; 48 :202–209. [ PubMed ] [ Google Scholar ]
- Mackersie CL, Boothroyd A, Minniear D. Evaluation of a computer-assisted speech perception assessment test (CASPA) J Am Acad Audiol. 2001; 12 :390–396. [ PubMed ] [ Google Scholar ]
- Martin FN, Champlin CA, Chambers JA. Seventh survey of audiometric practices in United States. J Am Acad Audiol. 1998; 9 :95–104. [ PubMed ] [ Google Scholar ]
- Martin FN, Forbis NK. The present state of audiometric practice: A follow-up study. Asha, 1978; 20 :531–541. [ PubMed ] [ Google Scholar ]
- Martin FN, Morris LJ. Current audiological practices in the United States. Hear J. 1989; 42 :25–42. [ Google Scholar ]
- Morgan D, Dirks D. Loudness discomfort levels under earphone and in the free field: the effects of calibration. J Acoust Soc Am. 1974; 56 :172–178. [ PubMed ] [ Google Scholar ]
- Studebaker G. A “rationalized” arcsine transformation. J Speech Hear Res, 1985; 28 :455–462. [ PubMed ] [ Google Scholar ]
- Ullrich K, Grimm D. Most comfortable listening level presentation versus maximum discrimination for word discrimination material. Audiol, 1976; 15 :338–347. [ PubMed ] [ Google Scholar ]
- Wilson R, Strouse A. Speech recognition and identification materials; Disc 2.0. Department of Veterans Affairs, VA Medical Center; Mountain Home, TN: 1998. compact disc. [ Google Scholar ]
- AudioStar Pro
- TympStar Pro
- Video Library
- 60 Minute Courses
- 30 Minute Courses
- Testing Guides
- All Content
- Get a Quote
- Select Language
Speech Audiometry
Audiometry guides, introduction.
Speech audiometry is an important component of a comprehensive hearing evaluation. There are several kinds of speech audiometry, but the most common uses are to 1) verify the pure tone thresholds 2) determine speech understanding and 3) determine most comfortable and uncomfortable listening levels. The results are used with the other tests to develop a diagnosis and treatment plan.
SDT = Speech Detection Threshold, SAT = Speech Awareness Threshold. These terms are interchangeable and they describe the lowest level at which a patient can hear the presence of speech 50% of the time. They specifically refer to the speech being AUDIBLE, not INTELLIGIBLE.
This test is performed by presenting spondee (two-syllable) words such as baseball, ice cream, hotdog and the patient is to respond when they hear the speech. This is often used with non-verbal patients such as infants or other difficult to test populations. The thresholds should correspond to the PTA and is used to verify the pure tone threshold testing.
How to Test:
Instruct the patient that he or she will be hearing words that have two parts, such as “mushroom” or “baseball.” The patient should repeat the words and if not sure, he or she should not be afraid to guess.
Using either live voice or recorded speech, present the spondee word lists testing the better ear first. Start 20 dB above the 1000 Hz pure tone threshold level. Present one word on the list and, if the response is correct, lower the level by 5 dB. Continue until the patient has difficulty with the words. When this occurs, present more words for each 5 dB step.
Speech Reception Threshold (SRT)
SRT, or speech reception threshold, is a fast way to help verify that the pure tone thresholds are valid. Common compound words - or spondee words - are presented at varying degrees of loudness until it is too soft for the patient to hear. SRT scores are compared to the pure tone average as part of the cross check principle. When these two values agree, the reliability of testing is improved.
Word Recognition
Instruct the patient that he or she is to repeat the words presented. Using either live voice or recorded speech, present the standardized PB word list of your choice. Present the words at a level comfortable to the patient; at least 30 dB and generally 35 to 50 dB above the 1000 Hz pure tone threshold. Using the scorer buttons on the front panel, press the “Correct” button each time the right response is given and the “Incorrect” button each time a wrong response is given.

The Discrimination Score is the percentage of words repeated correctly: Discrimination % at HL = 100 x Number of Correct Responses/Number of Trials.
WRS = Word Recognition Score, SRS = Speech Reception Score, Speech Discrimination Score. These terms are interchangeable and describe the patient’s capability to correctly repeat a list of phonetically balanced (PB) words at a comfortable level. The score is a percentage of correct responses and indicates the patient’s ability to understand speech.
Word Recognition Score (WRS)
WRS, or word recognition score, is a type of speech audiometry that is designed to measure speech understanding. Sometimes it is called word discrimination. The words used are common and phonetically balanced and typically presented at a level that is comfortable for the patient. The results of WRS can be used to help set realistic expectations and formulate a treatment plan.
Speech In Noise Test
Speech in noise testing is a critical component to a comprehensive hearing evaluation. When you test a patient's ability to understand speech in a "real world setting" like background noise, the results influence the diagnosis, the recommendations, and the patient's understanding of their own hearing loss.
Auditory Processing
Sometimes, a patient's brain has trouble making sense of auditory information. This is called an auditory processing disorder. It's not always clear that this lack of understanding is a hearing issue, so it requires a very specialized battery of speech tests to identify what kind of processing disorder exists and develop recommendations to improve the listening and understanding for the patient.
QuickSIN is a quick sentence in noise test that quantifies how a patient hears in noise. The patient repeats sentences that are embedded in different levels of restaurant noise and the result is an SNR loss - or Signal To Noise ratio loss. Taking a few additional minutes to measure the SNR loss of every patient seen in your clinic provides valuable insights on the overall status of the patient' s auditory system and allows you to counsel more effectively about communication in real-world situations. Using the Quick SIN to make important decisions about hearing loss treatment and rehabilitation is a key differentiator for clinicians who strive to provide patient-centered care.

BKB-SIN is a sentence in noise test that quantifies how patients hear in noise. The patient repeats sentences that are embedded in different levels of restaurant noise an the result is an SNR loss - or signal to noise ratio loss. This test is designed to evaluate patients of many ages and has normative corrections for children and adults. Taking a few additional minutes to measure the SNR loss of every patient seen in your clinic is a key differentiator for clinicians who strive to provide patient-centered care.
- Education >
- Testing Guides >
- Speech Audiometry >
GRASON-STADLER
- Our Approach
- Cookie Policy
- AMTAS Pro
Corporate Headquarters 10395 West 70th St. Eden Prairie, MN 55344
General Inquires +1 800-700-2282 +1 952-278-4402 [email protected] (US) [email protected] (International)
Technical Support Hardware: +1 877-722-4490 Software: +1 952-278-4456
DISTRIBUTOR LOGIN
- GSI Extranet
- Request an Account
- Forgot Password?
Get Connected
- Distributor Locator
© Copyright 2024
Masks Strongly Recommended but Not Required in Maryland
Respiratory viruses continue to circulate in Maryland, so masking remains strongly recommended when you visit Johns Hopkins Medicine clinical locations in Maryland. To protect your loved one, please do not visit if you are sick or have a COVID-19 positive test result. Get more resources on masking and COVID-19 precautions .
- Vaccines
- Masking Guidelines
- Visitor Guidelines
Speech Audiometry

Speech audiometry involves two different tests:
One checks how loud speech needs to be for you to hear it.
The other checks how clearly you can understand and distinguish different words when you hear them spoken.
What Happens During the Test
The tests take 10-15 minutes. You are seated in a sound booth and wear headphones. You will hear a recording of a list of common words spoken at different volumes, and be asked to repeat those words.
Your audiologist will ask you to repeat a list of words to determine your speech reception threshold (SRT) or the lowest volume at which you can hear and recognize speech.
Then, the audiologist will measure speech discrimination — also called word recognition ability. He or she will either say words to you or you will listen to a recording, and then you will be asked to repeat the words. The audiologist will measure your ability to understand speech at a comfortable listening level.
Getting Speech Audiology Test Results
The audiologist will share your test results with you at the completion of testing. Speech discrimination ability is typically measured as a percentage score.
Find a Doctor
Specializing In:
- Sudden Hearing Loss
- Hearing Aids
- Hearing Disorders
- Hearing Loss
- Hearing Restoration
- Implantable Hearing Devices
- Cochlear Implantation
Find a Treatment Center
- Otolaryngology-Head and Neck Surgery
Find Additional Treatment Centers at:
- Howard County Medical Center
- Sibley Memorial Hospital
- Suburban Hospital

Request an Appointment

The Hidden Risks of Hearing Loss

Hearing Loss in Children

What Is an Audiologist
Related Topics
- Aging and Hearing
Speech Audiometry
- Author: Suzanne H Kimball, AuD, CCC-A/FAAA; Chief Editor: Arlen D Meyers, MD, MBA more...
- Sections Speech Audiometry
- Indications
- Contraindications
- Pediatric Speech Materials
Speech audiometry has become a fundamental tool in hearing-loss assessment. In conjunction with pure-tone audiometry, it can aid in determining the degree and type of hearing loss. Speech audiometry also provides information regarding discomfort or tolerance to speech stimuli and information on word recognition abilities.
In addition, information gained by speech audiometry can help determine proper gain and maximum output of hearing aids and other amplifying devices for patients with significant hearing losses and help assess how well they hear in noise. Speech audiometry also facilitates audiological rehabilitation management.
The Technique section of this article describes speech audiometry for adult patients. For pediatric patients, see the Pediatric Speech Materials section below.
Speech audiometry can be used for the following:
Assessment of degree and type of hearing loss
Examination of word recognition abilities
Examination of discomfort or tolerance to speech stimuli
Determination of proper gain and maximum output of amplifying devices
Speech audiometry should not be done if the patient is uncooperative.
No anesthesia is required for speech audiometry.
In most circumstances, speech audiometry is performed in a 2-room testing suite. Audiologists work from the audiometric equipment room, while patients undergo testing in the evaluation room. The audiometric equipment room contains the speech audiometer, which is usually part of a diagnostic audiometer. The speech-testing portion of the diagnostic audiometer usually consists of 2 channels that provide various inputs and outputs.
Speech audiometer input devices include microphones (for live voice testing), tape recorders, and CDs for recorded testing. Various output devices, including earphones, ear inserts, bone-conduction vibrators, and loudspeakers, are located in the testing suite. [ 1 ]
Tests using speech materials can be performed using earphones, with test material presented into 1 or both earphones. Testing can also be performed via a bone-conduction vibrator. In addition to these methods, speech material can be presented using loudspeakers in the sound-field environment.
Speech-awareness thresholds
Speech-awareness threshold (SAT) is also known as speech-detection threshold (SDT). The objective of this measurement is to obtain the lowest level at which speech can be detected at least half the time. This test does not have patients repeat words; it requires patients to merely indicate when speech stimuli are present.
Speech materials usually used to determine this measurement are spondees. Spondaic words are 2-syllable words spoken with equal emphasis on each syllable (eg, pancake, hardware, playground). Spondees are used because they are easily understandable and contain information within each syllable sufficient to allow reasonably accurate guessing.
The SAT is especially useful for patients too young to understand or repeat words. It may be the only behavioral measurement that can be made with this population. The SAT may also be used for patients who speak another language or who have impaired language function because of neurological insult.
For patients with normal hearing or somewhat flat hearing loss, this measure is usually 10-15 dB better than the speech-recognition threshold (SRT) that requires patients to repeat presented words. For patients with sloping hearing loss, this measurement can be misleading with regard to identifying the overall degree of loss.
If a patient has normal hearing in a low frequency, the SAT will be closely related to the threshold for that frequency, and it will not indicate greater loss in higher frequencies.
Speech-recognition threshold
The speech-recognition threshold (SRT) is sometimes referred to as the speech-reception threshold. [ 2 ] The objective of this measure is to obtain the lowest level at which speech can be identified at least half the time.
Spondees are usually used for this measurement. Lists of spondaic words commonly used to obtain the SRT are contained within the Central Institute for the Deaf (CID) Auditory List W-1 and W-2.
In addition to determining softest levels at which patients can hear and repeat words, the SRT is also used to validate pure-tone thresholds because of high correlation between the SRT and the average of pure-tone thresholds at 500, 1000, and 2000 Hz.
In clinical practice, the SRT and 3-frequency average should be within 5-12 dB. This correlation holds true if hearing loss in the 3 measured frequencies is relatively similar. If 1 threshold within the 3 frequencies is significantly higher than the others, the SRT will usually be considerably better than the 3-frequency average. In this case, a 2-frequency average is likely to be calculated and assessed for agreement with the SRT.
Other clinical uses of the SRT include establishing the sound level to present suprathreshold measures and determining appropriate gain during hearing aid selection.
Suprathreshold word-recognition testing
The primary purpose of suprathreshold word-recognition testing is to estimate ability to understand and repeat single-syllable words presented at conversational or another suprathreshold level. This type of testing is also referred to as word-discrimination testing or speech-discrimination testing.
Initial word lists compiled for word-recognition testing were phonetically balanced (PB). This term indicated that phonetic composition of the lists was equivalent and representative of connected English discourse.
The original PB lists were created at the Harvard Psycho-Acoustic Laboratory and are referred to as the PB-50 lists. The PB-50 lists contain 50 single-syllable words in 20 lists consisting of 1000 different monosyllabic words. Several years later, the CID W-22 word lists were devised, primarily using words selected from the PB-50 lists. Another word list (devised from a grouping of 200 consonant-nucleus-consonant [CNC] words) is called the Northwestern University Test No. 6 (NU-6). Recorded tape and CD versions of all these word-recognition tests are commercially available.
The PB-50, CID W-22, and NU-6 word lists each contain 50 words that are presented at specified sensation levels. Words can be presented via tape, CD, or monitored live voice. Patients are asked to repeat words to the audiologist. Each word repeated correctly is valued at 2%, and scores are tallied as a percent-correct value.
Varying the presentation level of monosyllabic words reveals a variety of performance-intensity functions for these word lists. In general, presenting words at 25-40 dB sensation level (refer to the SRT) allows patients to achieve maximum scores. Lowering the level results in lower scores. For individuals with hearing loss, words can be presented at a comfortable loudness level or at the highest reasonable level before discomfort occurs.
When words are presented at the highest reasonable level and the word-recognition score is 80% or better, testing can be discontinued. If the score is lower than 80%, further testing at lower presentation levels is recommended. If scores at lower levels are better than those obtained at higher presentation levels, "roll over" has occurred, and these scores indicate a possible retrocochlear (or higher) site of lesion.
Another use of suprathreshold word-recognition testing is to verify speech-recognition improvements achieved by persons with hearing aids . Testing can be completed at conversational levels in the sound field without the use of hearing aids and then again with hearing aids fitted to the patient. Score differences can be used as a method to assess hearing with hearing aids and can be used as a pretest and posttest to provide a percent-improvement score
Sentence testing
To evaluate ability to hear and understand everyday speech, various tests have been developed that use sentences as test items. Sentences can provide information regarding the time domain of everyday speech and can approximate contextual characteristics of conversational speech.
Everyday sentence test
This is the first sentence test developed at the CID in the 1950s.
Clinical use of this test is limited, because its reliability as a speech-recognition test for sentences remains undemonstrated.
Synthetic-sentence identification test
The synthetic-sentence identification (SSI) test was developed in the late 1960s. SSI involves a set of 10 synthetic sentences. Sentences used in this test were constructed so that each successive group of 3 words in a sentence is itself meaningful but the entire sentence is not.
Because the sentences are deemed insufficiently challenging in quiet environments, a recommendation has been made that sentences be administered in noise at a signal-to-noise (S/N) ratio of 0 dB, which presents both sentences and noise at equal intensity level.
Speech perception in noise test
The speech perception in noise (SPIN) test is another sentence-identification test. The SPIN test was originally developed in the late 1970s and was revised in the mid 1980s.
The revised SPIN test consists of 8 lists of 50 sentences. The last word of each sentence is considered the test item. Half of listed sentences contain test items classified as having high predictability, indicating that the word is very predictable given the sentence context. The other half of listed sentences contain test items classified as having low predictability, indicating that the word is not predictable given sentence context. Recorded sentences come with a speech babble-type noise that can be presented at various S/N ratios.
Speech in noise test
The speech in noise (SIN) test, developed in the late 1990s, contains 5 sentences with 5 key words per test condition. Two signal levels (70 and 40 dB) and 4 S/N ratios are used at each level. A 4-talker babble is used as noise. This recorded test can be given to patients with hearing aids in both the unaided and aided conditions.
Results are presented as performance-intensity functions in noise. A shorter version of the SIN, the QuickSIN, was developed in 2004. The QuickSIN has been shown to be effective, particularly when verifying open-fit behind-the-ear hearing aids.
Hearing in noise test
The hearing in noise test (HINT) is designed to measure speech recognition thresholds in both quiet and noise. The test consists of 25 lists of 10 sentences and noise matched to long-term average speech.
Using an adaptive procedure, a reception threshold for sentences is obtained while noise is presented at a constant level. Results can be compared with normative data to determine the patient's relative ability to hear in noise.
Words in noise test
The Words-in-Noise Test (WIN), developed in the early 2000s, provides an open set word-recognition task without linguistic context. The test is composed of monosyllabic words from the NU-6 word lists presented in multitalker babble. The purpose of the test is to determine the signal-to-babble (S/B) ratio in decibels for those with normal and impaired hearing. The WIN is similar to the QuickSIN in providing information about speech recognition performance.
The WIN is used to measure performance of basic auditory function when working memory and linguistic context is reduced or eliminated. This measure, by using monosyllabic words in isolation, evaluates the listener's ability to recognize speech using acoustic cues alone and by eliminating syntactical and semantic cues founds in sentences. The WIN materials allow for the same words to be spoken by the same speaker for both speech-in-quiet and speech-in-noise data collection.
Bamford-Kowal-Bench speech in noise test
Bamford-Kowal-Bench Speech-in-Noise Test (BKB-SIN) was developed by Etymotic Research in the early to mid 2000s. The primary population for this test include children and candidates or recipients of cochlear implants .
Like the HINT, the BKB-SIN uses Americanized BKB sentences. [ 3 ] These words are characterized as short, and the sentences are highly redundant; they contain semantic and syntactic contextual cues developed at a first grade reading level. Compared to the HINT, which uses speech-spectrum noise, the BKB-SIN uses multitalker babble. Clinicians can expect better recognition performance on the BKB-SIN and HINT in comparison to the QuickSIN and WIN because of the additional semantic context provided by the BKB sentences.
Selecting proper speech in noise testing
QuickSIN and WIN materials are best for use in discriminating those who have hearing loss from normal hearing individuals. The BKB-SIN and HINT materials are less able to identify those with hearing loss. [ 4 , 5 ] Therefore, the QuickSIN or WIN is indicated as part of the routine clinical protocol as a speech in noise task. The choice of QuickSIN or WIN is strictly a matter of clinician preference; however, the clinician must also consider whether or not the patient can handle monosyllabic words (WIN) or needs some support from sentence context (QuickSIN).
The BKB-SIN and HINT materials are easier to recognize because of the semantic content, making them excellent tools for young children or individuals with substantial hearing loss, including cochlear implant candidates and new recipients.
Most comfortable loudness level and uncomfortable loudness level
Most comfortable loudness level
The test that determines the intensity level of speech that is most comfortably loud is called the most comfortable loudness level (MCL) test.
For most patients with normal hearing, speech is most comfortable at 40-50 dB above the SRT. This sensation level is reduced for many patients who have sensorineural hearing loss (SNHL). Because of this variation, MCL can be used to help determine hearing aid gain for patients who are candidates for amplification.
MCL measurement can be obtained using cold running or continuous speech via recorded or monitored live-voice presentation. Patients are instructed to indicate when speech is perceived to be at the MCL. Initial speech levels may be presented at slightly above SRT and then progressively increased until MCL is achieved. Once MCL is achieved, a speech level is presented above initial MCL and reduced until another MCL is obtained. This bracketing technique provides average MCL.
Uncomfortable loudness level
One reason to establish uncomfortable loudness level (UCL) is to determine the upper hearing limit for speech. This level provides the maximum level at which word-recognition tests can be administered. UCL can also indicate maximum tolerable amplification.
Another reason to establish UCL is to determine the dynamic speech range. Dynamic range represents the limits of useful hearing in each ear and is computed by subtracting SRT from UCL. For many patients with SNHL, this range can be extremely limited because of recruitment or abnormal loudness perception.
UCL speech materials can be the same as for MCL. The normal ear should be able to accept hearing levels of 90-100 dB. Patients are instructed to indicate when presented speech is uncomfortably loud. Instructions are critical, since patients must allow speech above MCL before indicating discomfort.
While the use of speech testing in general has not necessarily been shown to predict hearing aid satisfaction, [ 6 ] the use of loudness discomfort levels (UCLs) has been shown to be useful in successful hearing aid outcomes. [ 7 ]
The Acceptable Noise Level (ANL) test is a measure of the amount of background noise that a person is willing to tolerate. [ 8 ] In recent years it has gained interest among researchers and hearing-care professionals because of its ability to predict, with 85% accuracy, who will be successful with hearing aids. [ 9 ]
For very young children with limited expressive and receptive language skills, picture cards representing spondaic words can be used to establish the SRT. Before testing, the tester must ensure that the child understands what the card represents. Once the child has been taught to point to the correct picture card, 4-6 cards are chosen and presented to the child. Then, the softest level at which the child can select the correct card at least half the time is established.
For children with typical kindergarten or first-grade language skills, the Children's Spondee Word List can be used instead of adult word lists. The CID W-1 list is appropriate for use with older children.
Word-recognition testing for children can be classified as open-message response testing or closed-response testing. Closed-response testing uses the picture-pointing technique.
Word intelligibility by picture identification test
One of the more popular closed-response tests is the word intelligibility by picture identification (WIPI) test. This test consists of 25 pages; on each page are 6 colored pictures representing an item named by a monosyllabic word. Four pictures represent a test item, while the other 2 serve to decrease probability of a correct guess.
WIPI was developed for use with children with hearing impairment and can be used for children aged 4 years and older.
Northwestern University children's perception of speech test
Another popular closed-response test is the Northwestern University children's perception of speech (NU-CHIPS) test. NU-CHIPS consists of 50 pages with 4 pictures per page.
This test was developed for use with children aged 3 years and older.
Pediatric speech intelligibility test
The pediatric speech intelligibility (PSI) test uses both monosyllabic words and sentence test items. The PSI test consists of 20 monosyllabic words and 10 sentences. Children point to the appropriate picture representing the word or sentence presented.
Test materials are applicable for children aged as young as 3 years.
Phonetically balanced kindergarten test
One of the more popular open-message response tests for children is the phonetically balanced kindergarten (PBK) test, which contains 50 monosyllabic words that the child repeats.
The PKB test is most appropriate for children aged 5-7 years.
Bamford-Kowal-Bench Speech-in-Noise Test
As mentioned prior, the BKB-SIN materials are easier due to the amount of semantic content utilized which makes it an excellent tool for use with young children. [ 10 ]
Lewis MS, Crandell CC, Valente M, Horn JE. Speech perception in noise: directional microphones versus frequency modulation (FM) systems. J Am Acad Audiol . 2004 Jun. 15(6):426-39. [QxMD MEDLINE Link] .
Harris RW, McPherson DL, Hanson CM, Eggett DL. Psychometrically equivalent bisyllabic words for speech recognition threshold testing in Vietnamese. Int J Audiol . 2017 Aug. 56 (8):525-537. [QxMD MEDLINE Link] .
Bench J, Kowal A, Bamford J. The BKB (Bamford-Kowal-Bench) sentence lists for partially-hearing children. Br J Audiol . 1979 Aug. 13(3):108-12. [QxMD MEDLINE Link] .
Wilson RH, McArdle RA, Smith SL. An Evaluation of the BKB-SIN, HINT, QuickSIN, and WIN Materials on Listeners With Normal Hearing and Listeners With Hearing Loss. J Speech Lang Hear Res . 2007 Aug. 50(4):844-56. [QxMD MEDLINE Link] .
Carlson ML, Sladen DP, Gurgel RK, Tombers NM, Lohse CM, Driscoll CL. Survey of the American Neurotology Society on Cochlear Implantation: Part 1, Candidacy Assessment and Expanding Indications. Otol Neurotol . 2018 Jan. 39 (1):e12-e19. [QxMD MEDLINE Link] .
Killion MC, Gudmundsen GI. Fitting hearing aids using clinical prefitting speech measures: an evidence-based review. J Am Acad Audiol . 2005 Jul-Aug. 16(7):439-47. [QxMD MEDLINE Link] .
Mueller HG, Bentler RA. Fitting hearing aids using clinical measures of loudness discomfort levels: an evidence-based review of effectiveness. J Am Acad Audiol . 2005 Jul-Aug. 16(7):461-72. [QxMD MEDLINE Link] .
Nabelek AK, Tucker FM, Letowski TR. Toleration of background noises: relationship with patterns of hearing aid use by elderly persons. J Speech Hear Res . 1991 Jun. 34 (3):679-85. [QxMD MEDLINE Link] .
Nabelek AK, Freyaldenhoven MC, Tampas JW, Burchfiel SB, Muenchen RA. Acceptable noise level as a predictor of hearing aid use. J Am Acad Audiol . 2006 Oct. 17 (9):626-39. [QxMD MEDLINE Link] .
Neave-DiToro D, Rubinstein A, Neuman AC. Speech Recognition in Nonnative versus Native English-Speaking College Students in a Virtual Classroom. J Am Acad Audiol . 2017 May. 28 (5):404-414. [QxMD MEDLINE Link] .
- Speech audiogram. Video courtesy of Benjamin Daniel Liess, MD.

Contributor Information and Disclosures
Suzanne H Kimball, AuD, CCC-A/FAAA Assistant Professor, University of Oklahoma Health Sciences Center Suzanne H Kimball, AuD, CCC-A/FAAA is a member of the following medical societies: American Academy of Audiology , American Speech-Language-Hearing Association Disclosure: Nothing to disclose.
Francisco Talavera, PharmD, PhD Adjunct Assistant Professor, University of Nebraska Medical Center College of Pharmacy; Editor-in-Chief, Medscape Drug Reference Disclosure: Received salary from Medscape for employment. for: Medscape.
Peter S Roland, MD Professor, Department of Neurological Surgery, Professor and Chairman, Department of Otolaryngology-Head and Neck Surgery, Director, Clinical Center for Auditory, Vestibular, and Facial Nerve Disorders, Chief of Pediatric Otology, University of Texas Southwestern Medical Center; Chief of Pediatric Otology, Children’s Medical Center of Dallas; President of Medical Staff, Parkland Memorial Hospital; Adjunct Professor of Communicative Disorders, School of Behavioral and Brain Sciences, Chief of Medical Service, Callier Center for Communicative Disorders, University of Texas School of Human Development Peter S Roland, MD is a member of the following medical societies: Alpha Omega Alpha , American Academy of Otolaryngic Allergy , American Academy of Otolaryngology-Head and Neck Surgery , American Auditory Society , American Neurotology Society , American Otological Society , North American Skull Base Society , Society of University Otolaryngologists-Head and Neck Surgeons , The Triological Society Disclosure: Received honoraria from Alcon Labs for consulting; Received honoraria from Advanced Bionics for board membership; Received honoraria from Cochlear Corp for board membership; Received travel grants from Med El Corp for consulting.
Arlen D Meyers, MD, MBA Emeritus Professor of Otolaryngology, Dentistry, and Engineering, University of Colorado School of Medicine Arlen D Meyers, MD, MBA is a member of the following medical societies: American Academy of Facial Plastic and Reconstructive Surgery , American Academy of Otolaryngology-Head and Neck Surgery , American Head and Neck Society Disclosure: Serve(d) as a director, officer, partner, employee, advisor, consultant or trustee for: Cerescan; Neosoma; MI10;<br/>Received income in an amount equal to or greater than $250 from: Neosoma; Cyberionix (CYBX)<br/>Received ownership interest from Cerescan for consulting for: Neosoma, MI10 advisor.
Cliff A Megerian, MD, FACS Medical Director of Adult and Pediatric Cochlear Implant Program, Director of Otology and Neurotology, University Hospitals of Cleveland; Chairman of Otolaryngology-Head and Neck Surgery, Professor of Otolaryngology-Head and Neck Surgery and Neurological Surgery, Case Western Reserve University School of Medicine Cliff A Megerian, MD, FACS is a member of the following medical societies: American Academy of Otolaryngology-Head and Neck Surgery , American College of Surgeons , American Neurotology Society , American Otological Society , Association for Research in Otolaryngology , Massachusetts Medical Society , Society for Neuroscience , Society of University Otolaryngologists-Head and Neck Surgeons , Triological Society Disclosure: Nothing to disclose.
Medscape Reference thanks Benjamin Daniel Liess, MD, Assistant Professor, Department of Otolaryngology, University of Missouri-Columbia School of Medicine, for the video contributions to this article.
What would you like to print?
- Print this section
- Print the entire contents of
- Print the entire contents of article
- Otolaryngologic Manifestations of Granulomatosis With Polyangiitis
- Skill Checkup: Peritonsillar Abscess Drainage
- Biologic Therapies in Refractory Chronic Rhinosinusitis With Nasal Polyps
- Fast Five Quiz: How Much Do You Know About Bell Palsy?
- Pierre Robin Syndrome
- Common Comorbidities of Chronic Rhinosinusitis With Nasal Polyps
- Targeted Treatment in Chronic Rhinosinusitis With Nasal Polyps

- Drug Interaction Checker
- Pill Identifier
- Calculators

- 2001/viewarticle/980727 Private Equity Firms Increasing Purchases of Otolaryngology Practices

An official website of the United States government
The .gov means it’s official. Federal government websites often end in .gov or .mil. Before sharing sensitive information, make sure you’re on a federal government site.
The site is secure. The https:// ensures that you are connecting to the official website and that any information you provide is encrypted and transmitted securely.
- Publications
- Account settings
- My Bibliography
- Collections
- Citation manager
Save citation to file
Email citation, add to collections.
- Create a new collection
- Add to an existing collection
Add to My Bibliography
Your saved search, create a file for external citation management software, your rss feed.
- Search in PubMed
- Search in NLM Catalog
- Add to Search
A comparison of presentation levels to maximize word recognition scores
Affiliation.
- 1 School of Speech, Language and Hearing Sciences, San Diego State University, 5500 Campanile Dr. - MC: 1518, San Diego, CA 92182-1518, USA. [email protected]
- PMID: 19594086
- PMCID: PMC2948673
- DOI: 10.3766/jaaa.20.6.6
Background: While testing suprathreshold word recognition at multiple levels is considered best practice, studies on practice patterns do not suggest that this is common practice. Audiologists often test at a presentation level intended to maximize recognition scores, but methods for selecting this level are not well established for a wide range of hearing losses.
Purpose: To determine the presentation level methods that resulted in maximum suprathreshold phoneme-recognition scores while avoiding loudness discomfort.
Research design: Performance-intensity functions were obtained for 40 participants with sensorineural hearing loss using the Computer-Assisted Speech Perception Assessment. Participants had either gradually sloping (mild, moderate, moderately severe/severe) or steeply sloping losses. Performance-intensity functions were obtained at presentation levels ranging from 10 dB above the SRT to 5 dB below the UCL (uncomfortable level). In addition, categorical loudness ratings were obtained across a range of intensities using speech stimuli. Scores obtained at UCL - 5 dB (maximum level below loudness discomfort) were compared to four alternative presentation-level methods. The alternative presentation-level methods included sensation level (SL; 2 kHz reference, SRT reference), a fixed-level (95 dB SPL) method, and the most comfortable loudness level (MCL). For the SL methods, scores used in the analysis were selected separately for the SRT and 2 kHz references based on several criteria. The general goal was to choose levels that represented asymptotic performance while avoiding loudness discomfort. The selection of SLs varied across the range of hearing losses.
Results: Scores obtained using the different presentation-level methods were compared to scores obtained using UCL - 5 dB. For the mild hearing loss group, the mean phoneme scores were similar for all presentation levels. For the moderately severe/severe group, the highest mean score was obtained using UCL - 5 dB. For the moderate and steeply sloping groups, the mean scores obtained using 2 kHz SL were equivalent to UCL - 5 dB, whereas scores obtained using the SRT SL were significantly lower than those obtained using UCL - 5 dB. The mean scores corresponding to MCL and 95 dB SPL were significantly lower than scores for UCL - 5 dB for the moderate and the moderately severe/severe group.
Conclusions: For participants with mild to moderate gradually sloping losses and for those with steeply sloping losses, the UCL - 5 dB and the 2 kHz SL methods resulted in the highest scores without exceeding listeners' UCLs. For participants with moderately severe/severe losses, the UCL - 5 dB method resulted in the highest phoneme recognition scores.
PubMed Disclaimer
Mean audiograms for the four…
Mean audiograms for the four participant groups. The error bars indicate ± 1…
Mean phoneme recognition scores obtained…
Mean phoneme recognition scores obtained at the different sensation levels for the 2-kHz…
Mean phoneme recognition scores obtained using the five different methods for the four…
Scatterplot of phoneme recognition scores…
Scatterplot of phoneme recognition scores obtained using the fixed level, MCL, SRT reference,…
Similar articles
- Variability of most comfortable and uncomfortable loudness levels to speech stimuli in the hearing impaired. Sammeth CA, Birman M, Hecox KE. Sammeth CA, et al. Ear Hear. 1989 Apr;10(2):94-100. doi: 10.1097/00003446-198904000-00003. Ear Hear. 1989. PMID: 2707507
- A Comparison of Word-Recognition Performances on the Auditec and VA Recorded Versions of Northwestern University Auditory Test No. 6 by Young Listeners with Normal Hearing and by Older Listeners with Sensorineural Hearing Loss Using a Randomized Presentation-Level Paradigm. Wilson RH. Wilson RH. J Am Acad Audiol. 2019 May;30(5):370-395. doi: 10.3766/jaaa.17135. Epub 2019 Apr 4. J Am Acad Audiol. 2019. PMID: 30969910 Clinical Trial.
- Evaluation of a wide range of amplitude-frequency responses for the hearing impaired. van Buuren RA, Festen JM, Plomp R. van Buuren RA, et al. J Speech Hear Res. 1995 Feb;38(1):211-21. doi: 10.1044/jshr.3801.211. J Speech Hear Res. 1995. PMID: 7731212
- Most comfortable and uncomfortable loudness levels: six decades of research. Punch J, Joseph- A, Rakerd B. Punch J, et al. Am J Audiol. 2004 Dec;13(2):144-57. doi: 10.1044/1059-0889(2004/019). Am J Audiol. 2004. PMID: 15903140 Review.
- A Sound Therapy-Based Intervention to Expand the Auditory Dynamic Range for Loudness among Persons with Sensorineural Hearing Losses: Case Evidence Showcasing Treatment Efficacy. Formby C, Sherlock LP, Hawley ML, Gold SL. Formby C, et al. Semin Hear. 2017 Feb;38(1):130-150. doi: 10.1055/s-0037-1598069. Semin Hear. 2017. PMID: 28286368 Free PMC article. Review.
- Effects of presentation level on speech-on-speech masking by voice-gender difference and spatial separation between talkers. Oh Y, Friggle P, Kinder J, Tilbrook G, Bridges SE. Oh Y, et al. Front Neurosci. 2023 Dec 14;17:1282764. doi: 10.3389/fnins.2023.1282764. eCollection 2023. Front Neurosci. 2023. PMID: 38192513 Free PMC article.
- Description of the Baseline Audiologic Characteristics of the Participants Enrolled in the Aging and Cognitive Health Evaluation in Elders Study. Sanchez VA, Arnold ML, Betz JF, Reed NS, Faucette S, Anderson E, Burgard S, Coresh J, Deal JA, Eddins AC, Goman AM, Glynn NW, Gravens-Mueller L, Hampton J, Hayden KM, Huang AR, Liou K, Mitchell CM, Mosley TH Jr, Neil HN, Pankow JS, Pike JR, Schrack JA, Sherry L, Teece KH, Witherell K, Lin FR, Chisolm TH; ACHIEVE Collaborative Study. Sanchez VA, et al. Am J Audiol. 2024 Jan 2;33(1):1-17. doi: 10.1044/2023_AJA-23-00066. Online ahead of print. Am J Audiol. 2024. PMID: 38166200 Free PMC article.
- Hyperacusis Diagnosis and Management in the United States: Clinical Audiology Practice Patterns. Jahn KN, Koach CE. Jahn KN, et al. Am J Audiol. 2023 Dec 4;32(4):950-961. doi: 10.1044/2023_AJA-23-00118. Epub 2023 Nov 2. Am J Audiol. 2023. PMID: 37917915 Free PMC article.
- Speech Perception in Ménière Disease. Fernandes PC, Takegawa B, Ganança FF, Gil D. Fernandes PC, et al. Int Arch Otorhinolaryngol. 2023 Sep 5;27(4):e613-e619. doi: 10.1055/s-0043-1767677. eCollection 2023 Oct. Int Arch Otorhinolaryngol. 2023. PMID: 37876685 Free PMC article.
- The Influence of the Psychophysical Assessment Paradigm on Pitch Discrimination for Adults (and a Pilot Sample of Children). Flagge AG, Puranen L, Mulekar MS. Flagge AG, et al. Percept Mot Skills. 2021 Dec;128(6):2582-2604. doi: 10.1177/00315125211044063. Epub 2021 Sep 2. Percept Mot Skills. 2021. PMID: 34474624 Free PMC article.
- American Speech-Language-Hearing Association Guidelines for determining threshold level for speech. ASHA. 1988:85–89. - PubMed
- Beattie RC, Raffin MJ. Reliability of threshold, slope, and PB max for monosyllabic words. J Speech Hear Dis. 1985;50:166–178. - PubMed
- Beattie RC, Warren VG. Relationships among speech threshold, loudness discomfort, comfortable loudness, and PB max in the elderly hearing impaired. Am J Otol. 1982;3:353–358. - PubMed
- Beattie RC, Zipp JA. Range of intensities yielding PB max and the threshold for monosyllabic words for hearing-impaired subjects. J Speech Hear Dis. 1990;55:417–426. - PubMed
- Boothroyd A. Developments in speech audiometry. Brit J Audiol. 1968;2:3–10.
Publication types
- Search in MeSH
Related information
Grants and funding.
- R03 DC007500/DC/NIDCD NIH HHS/United States
- R03 DC007500-02/DC/NIDCD NIH HHS/United States
LinkOut - more resources
Full text sources.
- Europe PubMed Central
- Ovid Technologies, Inc.
- PubMed Central
Miscellaneous
- NCI CPTAC Assay Portal
- Citation Manager
NCBI Literature Resources
MeSH PMC Bookshelf Disclaimer
The PubMed wordmark and PubMed logo are registered trademarks of the U.S. Department of Health and Human Services (HHS). Unauthorized use of these marks is strictly prohibited.
AUDIOLOGY PRACTICE MANAGEMENT SOFTWARE

Auditdata Manage, a cloud-based, data-driven practice management software, optimizes audiology practices with paperless protocols, automated tasks, and insightful patient management, enabling higher quality care and efficiency.
PRACTICE MANAGEMENT SOFTWARE
Explore all our features
Integrations
Onboarding and Support
Security and Configuration
Audiological Equipment & Software

Auditdata Measure offers a modular, PC-based audiological testing and fitting suite that improves accuracy, patient comfort, and workflow efficiency, reducing return rates and enhancing customer satisfaction.
Comprehensive Solutions for Every Need
Hearing Assessment
Hearing Instrument Fitting
Looking for Equipment and Software?
Audiometer & Fitting Unit
Tympanometer
Measure Software
iPad Hearing Screener

Auditdata Engage transforms early hearing impairment screening with an iPad-based solution that engages potential customers, streamlines lead conversion for audiologists and clinics through data-driven pre-screening insights.
Most Popular Features
Customize Screener Flow
Configure Testing Protocols
Add Clinic Branding
iPad Screener Reports
Tailored for Small and Medium-Sized Businesses and Large Enterprises
Engage | Hearing Screener
Measure | Audiological Equipment & Software
Manage | Practice Management Software
Discover | Add-on BI tool
Hospital Solutions
Primus and Auditbase integration
Tailored for public audiology
Patient flow optimisation
Optimise your clinic
Facilitating ENT, CI and Otology Surgeons
Schedule a demo today!
See how Auditdata can help you transform the way your practice will attract and retain customers by efficiently manage and deliver your services with increased sales and happier customers.

Best Care Experience
Pre-clinic: Awareness and screening
In-clinic: Testing and fitting
Aftercare: Adoption and Follow-up
Ebooks & Guides
Customer stories
Personal Stories
Auditdata Insights
Improving quality of life by enabling the best care experience for all.
Our insights delve into Auditdata's holistic approach to hearing care, emphasizing innovations in pre-clinic awareness and screening, in-clinic testing and fitting, and aftercare adoption and follow-up. These strategies aim to shorten the journey from detection to treatment, enhance the in-clinic experience, and ensure successful long-term use of hearing aids through personalized care and advanced technology.
Meet Our Global Team
Board of Directors
Download Annual Report 2022
Environment Social Governance
Get in touch
Talk to a member of our team.
We’ll help you find the right products and pricing for your business

Explore our Help Center
A knowledge base of how-to-guides, information, documentation and FAQs for Auditdata's products

Auditdata Engage
Auditdata Manage
Auditdata Measure
Create Support Ticket
Calibration service
Contact support
Terms and conditions
What is Speech Audiometry?
Speech audiometry is a speech test or battery of tests performed to understand the client’s ability to discriminate speech sounds, detect speech in background noise, understand the signals being presented, and recall the information presented.
Experience our New Audiometer & Fitting Unit
Our sleek and stackable audiometer and fitting unit seamlessly integrates into any clinic decor, optimizing space while maintaining a modern aesthetic. With advanced features like portability and precise diagnostic capabilities, our audiometer revolutionizes testing and increases efficiency and accuracy.
Transform Your Audiology Practice Today!
Experience the perfect synergy of cutting-edge hardware and software solutions. Elevate patient care, streamline workflows, and achieve outstanding results. Discover how our innovative solutions can revolutionize your audiology practice and generate leads for your business. Take the first step towards unlocking your practice's full potential by contacting us now.
Streamline your speech audiometry tests and elevate patient care with our intuitive and configurable software. Designed for efficiency and flexibility, our platform fits any clinic's needs and budget.

Frequently Asked Questions
When should you do speech audiometry.
Most individuals seeking help with their hearing cite difficulties understanding speech, and more often speech in noise . While pure tone audiometry provides invaluable data regarding the nature and severity of hearing loss at a variety of frequencies – of which speech is made up – it cannot provide data on the individual's understanding of speech. Speech stimuli are used in the audiometric test battery to ascertain this data.
There are a variety of commonly used speech stimuli and tests that help paint a complete patient picture.
What Is Speech Recognition (Reception) Threshold (SRT)
Speech recognition threshold (SRT) testing is often used to validate your pure tone audiometric results. In other words, does the lowest level an individual can detect speech correlate to the hearing loss obtained through pure tone audiometry? This score is also often used as a starting point in determining your presentation level when performing suprathreshold speech testing like word recognition scores (WRS).
When obtaining an SRT, spondee words, or phonetically balanced words, like hotdog or baseball, are used. A list of these words is presented to the patient at a comfortable level first – this is called conditioning. Once the patient is familiar with the word list, those same words will be presented in a random order at a decreasing volume level. The patient will be asked to repeat back the words presented. The threshold is defined as the level at which 50% of the words are successfully repeated.
Words can be presented through monitored live voice or recorded speech. With the Measure audiometer , clinicians have the flexibility to use whichever they prefer. Recorded spondee word lists can be made available in the testing software for a seamless transition from pure tones to speech testing. When using monitored live-voice, a VU meter is clearly displayed so clinicians can observe the level of their voice.
What is a Speech Detection Threshold (SDT)
A speech detection threshold (SDT) describes the lowest intensity level that an individual can detect speech. An SDT is obtained in the same manner as a speech recognition threshold, but the patient is asked to respond to the words in a developmentally appropriate way, like when performing pure tone audiometry, rather than repeating them back. This is useful when testing young children or individuals with very poor speech discrimination who are unable to repeat back words.
What Is a Word Recognition Score (WRS) and How to Get It
A word recognition score (or a speech discrimination score) provides clinicians with valuable information regarding not only an individual’s hearing loss, but which treatment options will be the most appropriate.
WRS information not only assists in determining whether an individual is a good candidate for hearing aids or if another device like a cochlear implant may be indicated, but it can also help determine if there is a neural component to the hearing loss.
Scores are often classified into 1 of 5 categorized; excellent, good, fair, poor, and very poor.
Excellent or within normal limits = 90 - 100% on whole word scoring
Good or slight difficulty = 78 - 88%
Fair to moderate difficulty = 66 - 76%
Poor or great difficulty = 54 - 64 %
Very poor is < 52%
During speech audiometry, an individual's speech recognition threshold is used to determine an appropriate presentation level for obtaining a word recognition score. Alternatively, clinicians can measure a patient’s most comfortable loudness level (MCL) and present there.
Testing is most often performed in quiet but can be completed using background noise as well. Standardized word lists, like the W22 or NU-6 lists, are presented and the individual is asked to repeat back the words heard. A carrier phrase, for example “say the word” is often used. Having this phrase presented before the target word helps the patient prepare to listen and respond and helps the clinician adjust their voice to the proper level before the target word during monitored live-voice presentations.
Note that like with speech reception threshold testing, a recorded word list or live voice can be used derive a word recognition score. When using live voice, a clinician can watch the VU meter included in the Measure Software during the carrier phrase to check presentation level.
Why Use Speech Audiometry?
While pure tones are an invaluable stimulus for measuring hearing loss, they don’t represent what individuals are experiencing day-to-day. Using speech stimuli helps to measure a client’s hearing using words they may encounter in everyday life.
Additionally, a speech test assesses the client’s full auditory pathway. In other words, the question is, once sound is detected, is the ear able to accurately send that sound to the brain? At times, although able to hear the words presented, individuals may have difficulty processing those words. This is something that can only be detected by using speech audiometry.
Measure E-learning
Welcome to Our E-Learning Course on Speech Audiometry in the Measure Software
Delve into Speech Audiometry with our targeted e-learning course. Learn key concepts like Speech Recognition and Discrimination Thresholds, Word Recognition Scores, and Quick SIN testing. Configure and navigate Measure Software settings, perform accurate tests, and analyze results to assess a client's real-world hearing capabilities. Equip yourself with the knowledge to improve both test accuracy and patient care.


- Get new issue alerts Get alerts
Secondary Logo
Journal logo.
Colleague's E-mail is Invalid
Your message has been successfully sent to your colleague.
Save my selection
Measuring Speech Perception Gap: Part Three
McCraney, Anna L. AuD
Dr. McCraney is a director of audiology who specializes in middle ear implants. She has co-authored studies on middle ear implant outcomes, as well as the phenomenon of aided word recognition falling short of actual cochlear potential for word recognition, known as the speech perception gap. She presents regularly as an invited guest in clinics and classrooms, as well as at professional conventions, including AAA, ACIA, JDVAC, TSHA, and NHCA.
Editor's note: This is the third installment of a four-part series. Read part one in our April 2020 issue ( https://bit.ly/2z61wvV ) and part two in our June 2020 issue ( https://bit.ly/2Mzi82p ).
In parts one and two, we discussed speech perception gaps (SP gaps), why they occur, and whom they affect. To review, an SP gap is a discrepancy between a patient's cochlear potential for word recognition (WR), namely the PB max, and the actual aided WR (WR aided ) It is the result of a simple anatomical inefficiency, not a shortcoming of the hearing aid (HA) or its programming. Affecting about a quarter of patients with sensorineural hearing loss (SNHL) who wear hearing aids, SP gaps can only be identified through aided testing conducted to validate treatment effectiveness. Having established in part two that hearing care clinicians should look for SP gaps in all patients with HA, especially those with moderate to severe high-frequency loss, the next step is to discuss how to measure these gaps.

MEASURING PB MAX
Only two values are needed to measure SP gaps: maximum unaided WR (PB max) and WR aided . While unaided WR is routinely tested as part of basic diagnostic audiometry giving us half of the information we need to diagnose an SP gap, it bears a closer look. The usual practice rarely results in determining PB max. Multiple studies conducted in the past 30-plus years have found that most unaided WR testing is done at a single presentation level, i.e., +30-40 dB re SRT. 1-3 However, evidence shows that this approach regularly underestimates PB max. 1 Wea've known since at least the 1960s that a performance-intensity (PI) function is the most accurate way to find PB max. 4 But modern clinical time constraints often do not allow for completion of a full PI function, so using a single presentation level has been the practical and predominant approach. Most audiologists use +40 dB re SRT as the single presentation level—a strategy that likely stemmed from early research on how subjects with normal hearing understand speech at normal conversational levels (i.e., 40 dB SL). 5 Although we know that hearing-impaired ears don't work like normal-hearing ones, some habits are hard to break.
To provide a better alternative to single-level WR testing, Guthrie and Mackersie 1 compared the five most commonly used presentation levels: (1) 95 dB SPL, (2) MCL, (3) UCL-5, (4) SL re SRT, and (5) SL re 2 kHz threshold. They concluded that testing at UCL-5 would most closely approximate PB max for the greatest variety of audiometric configurations. So with no significant additional time expenditure, testing at UCL-5 allows clinicians to define a patient's cochlear potential for word understanding and provide information regarding asymmetrical or disproportionately poor WR, which is what most clinicians look for when testing single words in quiet. It also provides better information regarding a patient's true cochlear potential and therefore what may be expected from HA treatment.
Aside from testing at the presentation level that most closely approximates PB max, testing should also be done using full 50-word lists and recorded materials. As an industry, we seem to resist this reality, but failure to test in compliance with the way these tools were normed and validated yields results with such great test-retest variability as to render the results largely meaningless and therefore a waste of time to have done at all. 5
MEASURING WR aided
Once the PB max is identified, the WR aided should be determined. WR aided used to be routinely included in HA fittings. Comparative fittings were done, and patients were fit with whichever aid that yielded the best WR aided . As HA technology improved, HAs have become consistently good across manufacturers, so it was no longer necessary to try multiple aids. Instead, a single HA was fit, and gain and output were objectively verified using in situ measures. The assumption was that the patient would do equally well with any hearing aid as long as it matched real-ear measurement (REM) targets. This led to the abandonment of routine WR aided testing in favor of REM as the benchmark of a successful fitting.
Guidelines for testing WR aided are defined in the New Minimum Speech Test Battery (see Figure for a summary). 6 Testing monaurally with the non-test ear plugged allows the aided performance of each ear to be compared against the corresponding ear-specific PB max for calculation of the SP gaps. It is not unusual for an SP gap to be present in only one ear. Because the psychometric characteristics can vary between word lists (i.e., NU6s, W22s), 7-8 the cleanest comparisons can be made if words from the same family of word lists are used in both unaided and aided tests. For example, if using MSTB CNC words for aided testing, consider also using them for PB max testing. Likewise, if NU-6s are used for testing unaided WR, also use them for testing aided WR. Regardless of which word list is used, a full 50-word recorded list should be administered to each ear for comparison to ear-specific unaided WR scores. While this may sound time-consuming, the six minutes it takes to present a full list to both ears reveal the extent to which treatment has been effective. This also takes considerably less time than engaging in what will be fruitless fine-tuning if the patient has an SP gap.
For the roughly 75 percent of patients who will not have an SP gap, showing them in black and white that they're reaching their full cochlear potential as a result of treatment is a powerful way to demonstrate money well spent. For the other 25 percent who will have SP gaps, it allows clinicians to immediately discuss other treatment options rather than wait until patients are frustrated and we've eaten into our profit margins by spending multiple visits trying to make a HA do what their anatomy won't allow.
The reality of all treatment is that patients simply respond differently and often unpredictably. Hearing loss treatment is no different. As such, validating treatment effectiveness cannot be avoided if we are to ensure patients are reaching their full cochlear potential rather than merely doing better with treatment than without. As hearing health care professionals, that's the commitment we make to our patients. Fortunately, we have the speech perception gap tool that allows us to distinguish between those who have unrealistic expectations from those who are truly not reaching their full cochlear potential. With some easy modifications, including testing PB max at UCL-5 and measuring WR aided at least for those patients with moderate-to-severe hearing loss, we will be well-positioned to identify patients who have not responded as well to treatment and offer them an alternative, which will be discussed in part four of this article series.
- Cited Here |
- Google Scholar
- + Favorites
- View in Gallery
Toggle Menu
Tous droits réservés © NeurOreille (loi sur la propriété intellectuelle 85-660 du 3 juillet 1985). Ce produit ne peut être copié ou utilisé dans un but lucratif.
Journey into the world of hearing
Speech audiometry
Authors: Benjamin Chaix Rebecca Lewis Contributors: Diane Lazard Sam Irving
Facebook Twitter Google+
Speech audiometry is routinely carried out in the clinic. It is complementary to pure tone audiometry, which only gives an indication of absolute perceptual thresholds of tonal sounds (peripheral function), whereas speech audiometry determines speech intelligibility and discrimination (between phonemes). It is of major importance during hearing aid fitting and for diagnosis of certain retrocochlear pathologies (tumour of the auditory nerve, auditory neuropathy, etc.) and tests both peripheral and central systems.
Speech audiogram
Normal hearing and hearing impaired subjects.
The speech recognition threshold (SRT) is the lowest level at which a person can identify a sound from a closed set list of disyllabic words.
The word recognition score (WRS) testrequires a list of single syllable words unknown to the patient to be presented at the speech recognition threshold + 30 dBHL. The number of correct words is scored out of the number of presented words to give the WRS. A score of 85-100% correct is considered normal when pure tone thresholds are normal (A), but it is common for WRS to decrease with increasing sensorineural hearing loss.
The curve 'B', on the other hand, indicates hypoacusis (a slight hearing impairment), and 'C' indicates a profound loss of speech intelligibility with distortion occurring at intensities greater than 80 dB HL.
It is important to distinguish between WRS, which gives an indication of speech comprehension, and SRT, which is the ability to distinguish phonemes.
Phonetic materials and testing conditions
Various tests can be carried out using lists of sentences, monosyllabic or dissyllabic words, or logatomes (words with no meaning, also known as pseudowords). Dissyllabic words require mental substitution (identification by context), the others do not.
A few examples
|
|
| ||
|
Laud Boat Pool Nag Limb Shout Sub Vine Dime Goose |
Pick Room Nice Said Fail South White Keep Dead Loaf | Greyhound Schoolboy Inkwell Whitewash Pancake Mousetrap Eardrum Headlight Birthday Duck pond | |
The test stimuli can be presented through headphones to test each ear separately, or in freefield in a sound attenuated booth to allow binaural hearing to be tested with and without hearing aids or cochlear implants. Test material is adapted to the individual's age and language ability.
What you need to remember
In the case of a conductive hearing loss:
- the response curve has a normal 'S' shape, there is no deformation
- there is a shift to the right compared to the reference (normal threshold)
- there is an increase in the threshold of intelligibility
In the case of sensorineural hearing loss:
- there is an increased intelligibility threshold
- the curve can appear normal except in the higher intensity regions, where deformations indicate distortions
Phonetic testing is also carried out routinely in the clinic (especially in the case of rehabilitation after cochlear implantation). It is relatively long to carry out, but enables the evaluation of the real social and linguistic handicaps experienced by hearing impaired individuals. Cochlear deficits are tested using the “CNC (Consonant Nucleus Consonant) Test” (short words requiring little mental recruitment - errors are apparent on each phoneme and not over the complete word) and central deficits are tested with speech in noise tests, such as the “HINT (Hearing In Noise Test)” or “QuickSIN (Quick Speech In Noise)” tests, which are sentences carried out in noise.
Speech audiometry generally confirms pure tone audiometry results, and provides insight to the perceptual abilities of the individual. The intelligibility threshold is generally equivalent to the average of the intensity of frequencies 500, 1000 and 2000 Hz, determined by tonal audiometry (conversational frequencies). In the case of mismatch between the results of these tests, the diagnostic test used, equipment calibration or the reliability of the responses should be called into question.
Finally, remember that speech audiometry is a more sensitive indicator than pure tone audiometry in many cases, including rehabilitation after cochlear implantation.
Last update: 16/04/2020 8:57 pm
Connexion | Powered by eZPublish - Ligams
Speech Reception Threshold (SRT)
- What is the Speech Reception Threshold (SRT)?
Speech reception threshold (SRT) is a measure of hearing ability that is used to assess the lowest intensity level at which an individual can repeat familiar two-syllable words, known as spondee words, more than half of the time. Spondee words are chosen because they are easy to understand and are not affected by the pitch or voice quality of the speaker.
- How is SRT performed?
SRT is performed by a hearing healthcare professional using a calibrated audiometer. The audiometer presents a series of spondee words at different intensity levels, starting at a very soft level and gradually increasing in volume. The individual is asked to repeat each word as they hear it. The lowest intensity level at which the individual can repeat 50% of the words correctly is their SRT.
- What is the difference between SRT and speech discrimination?
SRT and speech discrimination are two different measures of hearing ability. SRT measures the lowest intensity level at which an individual can hear speech, while speech discrimination measures the ability to understand speech in noise. Speech discrimination is typically measured using a test of word recognition, in which the individual is asked to identify a list of words presented at a fixed intensity level.
- What is a normal speech recognition score?
A normal speech recognition score is typically considered to be 90% or higher. However, this can vary depending on the age of the individual and the type of hearing loss they have.
- What is a good SRT score?
A good SRT score is typically considered to be 20 dB HL or lower. However, this can vary depending on the age of the individual and the type of hearing loss they have.
SRT is a valuable measure of hearing ability that can help to assess the severity of hearing loss and the need for hearing amplification. It is also a useful tool for monitoring the progression of hearing loss over time.
If you are concerned about your hearing, you should talk to your doctor or a hearing healthcare professional. They can perform a hearing test, including SRT, to assess your hearing ability and recommend the best course of treatment.
©2024 Ask An Audiologist. All rights reserved.
Website maintenance is scheduled for Saturday, September 7, and Sunday, September 8. Short disruptions may occur during these days.

JENNIFER JUNNILA WALKER, MD, MPH, LEANNE M. CLEVELAND, AuD, JENNY L. DAVIS, AuD, AND JENNIFER S. SEALES, AuD
A more recent article on audiometry interpretation for hearing loss in adults is available.
Am Fam Physician. 2013;87(1):41-47
Author disclosure: No relevant financial affiliations to disclose.
The prevalence of hearing loss varies with age, affecting at least 25 percent of patients older than 50 years and more than 50 percent of those older than 80 years. Adolescents and young adults represent groups in which the prevalence of hearing loss is increasing and may therefore benefit from screening. If offered, screening can be performed periodically by asking the patient or family if there are perceived hearing problems, or by using clinical office tests such as whispered voice, finger rub, or audiometry. Audiometry in the family medicine clinic setting is a relatively simple procedure that can be interpreted by a trained health care professional. Pure-tone testing presents tones across the speech spectrum (500 to 4,000 Hz) to determine if the patient's hearing levels fall within normal limits. A quiet testing environment, calibrated audiometric equipment, and appropriately trained personnel are required for in-office testing. Pure-tone audiometry may help physicians appropriately refer patients to an audiologist or otolaryngologist. Unilateral or asymmetrical hearing loss can be symptomatic of a central nervous system lesion and requires additional evaluation.
Nearly 30 million American adults have some degree of hearing loss. 1 The prevalence of hearing loss varies with age; at least 25 percent of patients between 51 and 65 years of age, and more than 50 percent of patients older than 80 years, have objective evidence of hearing loss. 2 , 3 Particularly concerning is the increasing prevalence of hearing loss in adolescents and young adults, which affects between 8 and 19 percent of this population. 1 , 4 The U.S. Preventive Services Task Force (USPSTF) finds insufficient evidence for or against screening for hearing loss in asymptomatic adults 50 years or older. 3 However, the USPSTF does affirm the effectiveness of screening questionnaires and clinical techniques such as the whispered voice, finger rub, and watch tick tests, all of which can be performed in the primary care clinic. 3 , 5 , 6 Other guidelines list subjective hearing screening as a preventive service that should be offered to adults starting at 40 years of age. 7
| The U.S. Preventive Services Task Force concludes that the current evidence is insufficient to assess the balance of benefits and harms of screening for hearing loss in asymptomatic adults 50 years and older. | C | |
| Patients reporting regular exposure to loud music or occupational noise are good candidates for screening audiometry. | C | – |
| Patients should avoid loud noise for at least 14 hours before pure-tone testing to minimize temporary threshold shift confounding of test results. | C | |
| Patients with persistent unilateral or asymmetrical hearing loss should be offered additional evaluation and imaging. | C | , |
Audiometry is a relatively simple procedure that can be performed and interpreted by a trained health care professional. Family physicians should feel comfortable performing this testing on adults and cooperative children. Physicians may consider performing audiometry when a patient reports a subjective sense of diminished hearing, or when a family member reports a patient's decreased conversational interaction. 8
Although the USPSTF also found insufficient evidence to recommend for or against routinely screening asymptomatic working-age adolescents and adults younger than 50 years for hearing impairment, 3 other organizations have recommended regular periodic objective testing throughout childhood and adolescence. 9 , 10 One survey of adolescents and young adults (mean age 19.2 years) revealed that 43 percent of respondents experienced hearing loss associated with exposure to loud music within the past six months. 11 Adolescents often listen to music through headphones at maximum volume, and underestimate their vulnerability to music-induced hearing loss. 12 Therefore, patients reporting exposure to loud music or occupational noise are good candidates for audiometry. 13
Testing may be expanded to include patients who are exposed to excessive noise while at work or at play who have not used adequate hearing protection. Unilateral or asymmetrical hearing loss is common in hunters and military veterans exposed to acoustic trauma from prolonged use of firearms. 14
Pure-Tone Audiometry
When hearing loss is suspected, pure-tone audiometry may be used to evaluate hearing deficits by spot-checking certain frequencies, or to evaluate deficits more completely. 15 Pure-tone audiometry is performed with the use of an audiometer. Handheld audiometers have a sensitivity of 92 percent and a specificity of 94 percent in detecting sensorineural hearing impairment. 16 There are several types of audiometers available, but all function similarly by allowing the tester to increase and decrease the intensity (loudness, in decibels [dB]) and frequency (pitch, in cycles per second or Hz) of the signal as desired.
Pure-tone audiometry is broadly defined as either screening or threshold search. Screening audiometry presents tones across the speech spectrum (500 to 4,000 Hz) at the upper limits of normal hearing (25 to 30 dB for adults, and 15 to 20 dB for children). 17 Results are recorded as pass, indicating that the patient's hearing levels are within normal limits, or refer, indicating that hearing loss is possible and a repeat screening test or a threshold search test is recommended.
Threshold search audiometry determines the softest sound a patient can hear at each frequency 50 percent of the time. This testing requires more time and expertise than screening audiometry. The American Speech-Language-Hearing Association has a recommended procedure for pure-tone threshold search tests known as the modified Hughson-Westlake method. 18 Testing begins with the ear in which the patient perceives to have better hearing. The tester presents a pure tone at a clearly audible level. After the patient responds to the pure-tone signal, the tester decreases intensity by 10 dB and presents the tone again. If the patient responds to this tone, a “down 10” pattern is employed, with the tester decreasing the intensity of the tone by 10 dB and presenting a tone until the patient no longer responds. 18 The tester then increases tone intensity by 5 dB until the patient responds. This is the patient's initial ascending response.
To check for accuracy, the tester should decrease the intensity of the tone by 10 dB one more time to check for no response, then increase the intensity of the signal in 5 dB increments until the patient responds again to the signal. If the patient responds consistently (minimum two out of three responses in ascending order), the tester records the dB level at which the patient responds as the air conduction threshold. After testing the ear that is perceived to have better hearing, the tester then performs the same tests on the patient's other ear.
Testing should begin at 1,000 Hz, because this frequency is easily heard by most patients and has the greatest test-retest reliability. 18 A common frequency sequence for pure-tone threshold search testing is to test at 1,000, 2,000, 3,000, 4,000, 8,000, 1,000 (repeat), 500, and 250 Hz. 15
Sound frequency (ranging from low to high pitch) is recorded on the audiogram's horizontal axis. Sound intensity is recorded on the vertical axis. Right ear thresholds are manually recorded as a red circle on the audiogram. Left ear thresholds are manually recorded as a blue X ( Figures 1 to 4B ) .
Conventional pure-tone testing is used for adults and older children. Audiometry is more challenging in patients younger than five years, and these patients should be referred to an audiologist with experience treating children. 19 In many cases, the accuracy of pure-tone testing during well-child visits is overwhelmingly poor. 20
Special Considerations Affecting Audiometry Interpretation
Environment.
Pure-tone audiometry requires a quiet testing environment with low levels of background noise. Background noise can cause elevated thresholds, especially in low frequencies ( eFigures 1A and 1B ). To minimize the number of false-positive results, sound levels in the test environment should not exceed American National Standards Institute (ANSI) requirements. 21 A quiet booth that features sound-absorptive materials such as carpeting, acoustic foam, or tiles is considered standard practice. Industrial hygienists, biomedical maintenance technicians, and audiologists can evaluate environmental noise levels in the test area using a sound level meter to ensure that ANSI specifications are met.
Several types of audiometers are available for purchase, ranging from handheld screening audiometers to those with full diagnostic capabilities extending to higher frequencies. Screening audiometers for office use, for example, generally test at frequencies in the speech range of 500 to 4,000 Hz.
There are many purchase options to consider for earphones and transducers. Circumaural headphones have a cushion covering the entire external ear. These help reduce background noise when the testing environment is not ideal. Supra-aural headphones sit directly on the pinna, and are the least effective headphone at attenuating background noise. Insert earphones are inserted directly into the ear canal. They reduce the possibility of collapsing canals, provide some background noise attenuation, and reduce the possibility of sound detection from the opposite ear.
All audiometers and audiometric equipment require annual calibrations to meet ANSI specifications. 22 Audiometer supplier information is listed in Table 1 .
| Grason-Stadler, Inc. | |
| 800-700-2282 | |
| Handtronix | |
| 866-950-2573 | |
| Maico Diagnostics | |
| 888-941-4201 | |
| Micro Audiometrics | |
| 800-729-9509 | |
| Welch Allyn, Inc. | |
| 800-535-6663 | |
Support personnel can be trained to perform audiometry in formal courses lasting 20 hours. 23 Physicians should check with their state and local agencies for licensing requirements of audiometry personnel. In the absence of state or local requirements, guidelines for the use of support personnel to perform audiometry are listed in Table 2 . 24 – 26
| American Academy of Audiology | Support personnel are defined as “people who, after appropriate training, perform tasks that are prescribed, directed, and supervised by an audiologist.” |
| American Academy of Otolaryngology–Head and Neck Surgery | “Technicians can only perform diagnostic tests that do not require the skills of an audiologist…. Technicians must be under the direct supervision of a physician.” |
| American Speech-Language-Hearing Association (ASHA) | “Regardless of job title, preparation, tasks, and other credentials, all persons who provide support services in audiology and speech-language pathology should be directed and supervised by ASHA-certified audiologists and/or speech-language pathologists.” |
PATIENT HISTORY
Patients may feign or exaggerate hearing loss for personal reasons, and may intentionally or unintentionally misreport on testing. Patients with constant, bothersome tinnitus (ringing or buzzing in the ears) often have difficulty discerning pure tones. Many combat veterans have a history of blast exposures, mild concussion, or posttraumatic stress disorder. 27 – 29 These patients may have difficulty completing audiometry for reasons related to headaches, memory problems, irritability, or fatigue. Taking a history before the hearing test will alert the physician to these possibilities. Supplemental, objective tests such as evoked otoacoustic emissions testing (stimulation of hair cells to produce sound) and patient questionnaires can assist with difficult-to-test populations. 30
Recent noise exposure before pure-tone testing may affect the validity of the test results. Riding a loud motorcycle or listening to music through headphones may result in a temporary hearing threshold shift, and may not reflect the patient's true hearing thresholds. Patients should minimize or avoid exposure to loud noise for at least 14 hours before pure-tone testing. 31
PHYSICAL FINDINGS
Audiometry results may be affected in patients with anatomic anomalies, such as narrow or collapsing ear canals (stenosis of the ear canal), complete canal occlusion, or absence of an ear canal (atresia). Impacted cerumen can cause a conductive hearing loss ( Figure 1 ) that typically resolves following cerumen removal. Collapsed ear canals occur in many older patients whose cartilage has become flaccid. Placing an over-the-ear headphone over already narrow or closed ear canals may add sufficient pressure to collapse the ear canals even further, resulting in a false high-frequency hearing loss. An otoscopic examination should be performed before the hearing test to ensure that the tympanic membrane is at least partially visible.
Differentiating conductive hearing loss from sensorineural hearing loss requires bone conduction testing. Audiometry relies on techniques similar to the Weber and Rinne tests to compare air and bone conduction. Bone conduction audiometry measures pure-tone thresholds using a mechanical device that transmits sounds via vibration through the forehead or mastoid bone. Figures 2A and 2B demonstrate differences in air and bone conduction thresholds (an air-bone gap) for a patient with a tympanic membrane rupture. 32 Figures 3A and 3B illustrate no air-bone gap for a patient with bilateral hearing loss. Unilateral or asymmetrical hearing loss ( Figures 4A and 4B ) can be symptomatic of a central nervous system lesion, including vestibular schwannoma (commonly though incorrectly called an acoustic neuroma), and warrants additional evaluation and imaging. 33 , 34
If the pure-tone threshold difference or asymmetry between ears at any frequency is equal to or greater than 40 dB, the sound energy from the test ear can stimulate the nontest ear, causing the nontest ear to respond to the stimulus. To prevent this crossover of sound from one ear to the other, narrow band noise is presented to the nontest ear and thresholds are recorded as masked. 32 Right ear masked air conduction thresholds are manually recorded as a red triangle on the audiogram. Left ear masked air conduction thresholds are manually recorded as a blue box. Right ear masked bone conductions are manually recorded as a red square bracket (open on the right side). Left ear masked bone conduction thresholds are manually recorded as a blue square bracket (open on the left side). Figures 4A and 4B show masked bone conduction thresholds in the left ear.
| American Academy of Audiology | Consumer guides including a fact sheet on noise-induced hearing loss; position statement on preventing noise-induced occupational hearing loss | |
| National Hearing Conservation Association | Practical guides on hearing conservation related to music, firearms, farming, children, and noise; Noise Destroys poster of damaged hair cells within the cochlea | |
| National Institute for Occupational Safety and Health | Noise and Hearing Loss Prevention: current research, training tools, frequently asked questions, and more | |
| National Institute on Deafness and Other Communication Disorders | Ten Ways to Recognize Hearing Loss patient questionnaire | |
Additional audiometric testing by an audiologist is recommended for patients whose pure-tone thresholds fall outside the range of normal limits. 35
Reimbursement Considerations
Pure-tone audiometry threshold diagnostic testing of both ears (interpreted as pass/fail) should be billed under Current Procedural Terminology (CPT) code 92552 (pure tone audiometry [threshold]; air only) or 92553 for Medicare reimbursement. 36 The average reimbursement for pure-tone audiometry threshold diagnostic testing of both ears is $28.71. Medicare does not cover the pure-tone audiometry screening test of both ears under CPT code 92551 (screening test, pure tone, air only). 36 For non-Medicare claims, testing will be billed under the International Classification of Diseases, Ninth Revision, Clinical Modification (ICD-9-CM) diagnosis code 389.9 (unspecified hearing loss). 37 , 38 Private insurance companies may cover this service as billed under the ICD-9-CM code V72.1 (special investigations and examinations; examination of ears and hearing). 39
As part of a preventive approach to hearing loss, physicians may consider placing educational materials on hearing loss prevention, and a dispenser of earplugs for patients to use when anticipating exposure to loud noise, in their office waiting rooms. Table 3 provides a sample of educational resources for hearing conservation.
Data Sources: A PubMed search was completed in Clinical Queries using the key terms audiometry, screening, prevalence, and hearing loss. The search included meta-analyses, cross-sectional studies, and reviews. Also searched were the Agency for Healthcare Research and Quality evidence reports, and the National Guideline Clearinghouse, and Cochrane Database of Systematic Reviews. Search date: September 2011.
Agrawal Y, Platz EA, Niparko JK. Prevalence of hearing loss and differences by demographic characteristics among US adults: data from the National Health and Nutrition Examination Survey, 1999–2004. Arch Intern Med. 2008;168(14):1522-1530.
Mulrow CD, Lichtenstein MJ. Screening for hearing impairment in the elderly: rationale and strategy. J Gen Intern Med. 1991;6(3):249-258.
U.S. Preventive Services Task Force. Screening for hearing impairment in older adults. http://www.uspreventiveservicestaskforce.org/uspstf/uspshear.htm . Accessed September 10, 2012.
Shargorodsky J, Curhan SG, Curhan GC, Eavey R. Change in prevalence of hearing loss in US adolescents. JAMA. 2010;304(7):772-778.
Elsawy B, Higgins KE. The geriatric assessment. Am Fam Physician. 2011;83(1):48-56.
Torres-Russotto D, Landau WM, Harding GW, Bohne BA, Sun K, Sinatra PM. Calibrated finger rub auditory screening test (CALFRAST). Neurology. 2009;72(18):1595-1600.
Institute for Clinical Systems Improvement. Health care guideline: preventive services for adults. http://www.icsi.org/preventiveservices_for_adults/preventive_services_for_adults_4.html . Accessed September 22, 2011.
Barnett S. A hearing problem. Am Fam Physician . 2002;66(5):911-912.
American Academy of Pediatrics Committee on Practice and Ambulatory Medicine. Recommendations for preventive pediatric health care. Pediatrics. 1995;96(2):373-374.
American Academy of Pediatrics Bright Futures Steering Committee. Bright Futures guidelines for health supervision of infants, children, and adolescents, middle childhood, 5 to 10 years. http://brightfutures.aap.org/pdfs/Guidelines_PDF/17-Middle_Childhood.pdf . Accessed September 22, 2011.
Chung JH, Des Roches CM, Meunier J, Eavey RD. Evaluation of noise-induced hearing loss in young people using a web-based survey technique. Pediatrics. 2005;115(4):861-867.
Vogel I, Brug J, Hosli EJ, van der Ploeg CP, Raat H. MP3 players and hearing loss: adolescents' perceptions of loud music and hearing conservation. J Pediatr. 2008;152(3):400-404.
Rabinowitz PM. Noise-induced hearing loss. Am Fam Physician . 2000;61(9):2749-2756.
Klockhoff I, Lyttkens L, Svedberg A. Hearing damage in military service. A study on 38, 294 conscripts. Scand Audiol. 1986;15(4):217-222.
Forzley GJ. Audiometry. In: Pfenninger JL, Fowler GC, eds. Pfenninger & Fowler's Procedures for Primary Care . 2nd ed. St. Louis, Mo.: Mosby; 2003:409–415.
Frank T, Petersen DR. Accuracy of a 40 dB HL audioscope and audiometer screening for adults. Ear Hear. 1987;8(3):180-183.
Fausti SA, Wilmington DJ, Helt PV, Helt WJ, Konrad-Martin D. Hearing health and care: the need for improved hearing loss prevention and hearing conservation practices. J Rehabil Res Dev. 2005;42(4 Suppl 2):45-62.
Harrell RW. Pure tone evaluation. In: Katz J, ed. Handbook of Clinical Audiology . 5th ed. Philadelphia, Pa.: Lippincott Williams & Wilkins; 2002:71–87.
Cunningham M, Cox EO Committee on Practice and Ambulatory Medicine and the Section on Otolaryngology and Bronchoesophagology. Hearing assessment in infants and children: recommendations beyond neonatal screening. Pediatrics. 2003;111(2):436-440.
Halloran DR, Hardin JM, Wall TC. Validity of pure-tone hearing screening at well-child visits. Arch Pediatr Adolesc Med. 2009;163(2):158-163.
American National Standards Institute. Maximum permissible ambient noise levels for audiometric test rooms. ANSI/ASA S3. 1–1999 (R2008). http://webstore.ansi.org (subscription required).
American National Standards Institute. Specification for audiometers, ANSI S3.6-2010. http://webstore.ansi.org (subscription required).
Council for Accreditation in Occupational Hearing Conservation. Courses leading to certification and recertification as an occupational hearing conservationist. http://www.caohc.org/ohc/ohccurriculumrevised.php. Accessed September 22, 2011.
American Academy of Audiology. Position statement & guidelines of the consensus panel on support personnel in audiology; January 1997. http://www.audiology.org/resources/documentlibrary/Pages/SupportPersonnelinAudiology.aspx . Accessed September 22, 2011.
American Academy of Otolaryngology–Head and Neck Surgery. FAQs on CMS audiology transmittals. http://www.entnet.org/Practice/upload/FAQ-for-web-082908.pdf . Accessed September 22, 2011.
American Speech-Language-Hearing Association. Support personnel [issues in ethics]; 2004. http://www.asha.org/docs/pdf/ET2004-00182.pdf . Accessed September 22, 2011.
Cave KM, Cornish EM, Chandler DW. Blast injury of the ear: clinical update from the global war on terror. Mil Med. 2007;172(7):726-730.
Terrio H, Brenner LA, Ivins BJ, et al. Traumatic brain injury screening: preliminary findings in a U.S. Army brigade combat team. J Head Trauma Rehabil. 2009;24(1):14-23.
Brenner LA, Ivins BJ, Schwab K, et al. Traumatic brain injury, posttraumatic stress disorder, and postconcussive symptom reporting among troops returning from Iraq. J Head Trauma Rehabil. 2010;25(5):307-312.
Jupiter T. Screening for hearing loss in the elderly using distortion product otoacoustic emissions, pure tones, and a self-assessment tool. Am J Audiol. 2009;18(2):99-107.
Army Publishing Directorate. Department of the Army pamphlet 40–501: hearing conservation program. Washington DC: Department of the Army; December 10, 1998. http://www.apd.army.mil/pdffiles/p40_501.pdf . Accessed April 2, 2012.
Katz J, Lezynski J. Clinical masking. In: Katz J, ed. Handbook of Clinical Audiology . 5th ed. Philadelphia, Pa.: Lippincott Williams & Wilkins; 2002:124–141.
Saliba I, Martineau G, Chagnon M. Asymmetric hearing loss: rule 3,000 for screening vestibular schwannoma. Otol Neurotol. 2009;30(4):515-521.
Durmaz A, Karahatay S, Satar B, Birkent H, Hidir Y. Efficiency of Stenger test in confirming profound, unilateral pseudohypacusis. J Laryngol Otol. 2009;123(8):840-844.
Bogardus ST, Yueh B, Shekelle PG. Screening and management of adult hearing loss in primary care: clinical applications. JAMA. 2003;289(15):1986-1990.
Abraham M. CPT 2012: Current Procedural Terminology . Chicago, Ill.: American Medical Association; 2011.
Moore KJ. Coding and documentation. Fam Pract Manag. 2003;10(1):17-18.
Centers for Medicare and Medicaid Services. Physician fee schedule search. http://www.cms.gov/apps/physician-fee-schedule/search/search-criteria.aspx . Accessed March 30, 2012.
U.S. Department of Health and Human Services Centers for Disease Control and Prevention, Centers for Medicare & Medicaid Services. ICD-9-CM: International Classification of Diseases, Ninth Revision, Clinical Modification . Washington, DC; 2007.
Continue Reading

More in AFP
More in pubmed.
Copyright © 2013 by the American Academy of Family Physicians.
This content is owned by the AAFP. A person viewing it online may make one printout of the material and may use that printout only for his or her personal, non-commercial reference. This material may not otherwise be downloaded, copied, printed, stored, transmitted or reproduced in any medium, whether now known or later invented, except as authorized in writing by the AAFP. See permissions for copyright questions and/or permission requests.
Copyright © 2024 American Academy of Family Physicians. All Rights Reserved.
COMMENTS
Speech Detection Threshold (SDT). The speech detection threshold is the minimum hearing level for speech at which an individual can just discern the presence of a speech material 50% of the time. The listener does not have to identify the material as speech, but must indicate awareness of the presence of sound.
Masking will always be needed for suprathreshold testing when the presentation level in the test ear is 40 dB or greater above the best bone conduction threshold in the non-test ear if supra-aural phones are used. ... Another application or future direction for speech audiometry is to more realistically assess hearing aid performance in "real ...
Speech audiometry can be challenging to perform in subjects with severe-to-profound hearing losses as well as asymmetrical hearing losses where the level of stimulation and ... The goal is to identify the level at which the patient detects speech in 50% of the trials. ... D S is the level of dial setting in dB HL for presentation of speech to ...
Speech audiometry is used to measure the ability of a patient to perceive speech signals. Speech materials (pre-recorded or read by examiner) are presented; the ... suitable presentation level for supra-threshold tests. Supra-threshold tests are used to determine the percentage of speech recog-nition a patient can obtain. It also provides
There is inconsistent support for the use of speech UCL as a presentation level. ... DeBow A, Green W. A survey of Canadian audiological practices: pure tone and speech audiometry. J Speech Path Audiol. 2000; 24:153-161. [Google Scholar] Downs D, Minard P. A fast valid method to measure speech-recognition threshold. Hear J. 1996; 49:39-44.
Speech audiometry is an important component of a comprehensive hearing evaluation. There are several kinds of speech audiometry, but the most common uses are to 1) verify the pure tone thresholds 2) determine speech understanding and 3) determine most comfortable and uncomfortable listening levels. The results are used with the other tests to ...
Speech Audiometry
Level of first presentation. The level of the first presentation of the test tone shall be well below the expected threshold. ... initial 1000-Hz threshold measurement if there is a question of reliability or discrepancy with other measures such as speech audiometry thresholds or to minimize retesting time if a discrepancy for the 1000-Hz ...
The SRT or SDT is used to cross-check the accuracy of the pure-tone thresholds and determine the presentation level of the speech recognition ... In adults, normal hearing is defined as a threshold of less than 20 dB at all frequencies tested. Speech audiometry determines the lowest intensity level at which speech stimuli (spondees) is repeated ...
Speech Audiometry: Overview, Indications, Contraindications
obtained through pure tone audiometry. SRT and pure-tone average (or PT. ) should be within 10dB of each other. You can see the br. akdown of the correlation in figu. Contact Us - Sage Hall 170 - (940) 369-7006. [email protected] - @UNTLearningCenterdegree of hearing loss and to determine the presentation lev.
Performance-intensity functions were obtained at presentation levels ranging from 10 dB above the SRT to 5 dB below the UCL (uncomfortable level). In addition, categorical loudness ratings were obtained across a range of intensities using speech stimuli. Scores obtained at UCL - 5 dB (maximum level below loudness discomfort) were compared to ...
Loudness discomfort level for speech: Comparison of two instructional sets for saturation sound pressure level selection. ... Speech audiometry. In Audiology (pp. 183-184). Englewood Cliffs, NJ: Prentice Hall. ... Most comfortable listening level presentation versus maximum discrimination for word discrimination material. Audiology, 15, 338 ...
amplify most speech sounds without significant difficulty, at least in the range extending from 250 to 4000 Hz. Speech Audiometry Results This individual's hearing sensitivity was sufficient for hearing and recog-nizing spondees (obtaining speech reception thresholds) at a level of 50 dB HL in the right ear and 55 dB HL in the left ear.
During speech audiometry, an individual's speech recognition threshold is used to determine an appropriate presentation level for obtaining a word recognition score. Alternatively, clinicians can measure a patient's most comfortable loudness level (MCL) and present there.
Most audiologists use +40 dB re SRT as the single presentation level—a strategy that likely stemmed from early research on how subjects with normal hearing understand speech at normal conversational levels (i.e., 40 dB SL). 5 Although we know that hearing-impaired ears don't work like normal-hearing ones, some habits are hard to break.
- Speech Audiometry: Masking is necessary when there is a 40 dB or greater difference (60 dB with inserts) when comparing the presentation level of a test ear and the best bone conduction threshold in the non-test ear. • If masking is needed but could not be done, you must provide the reason. Failure to comply with this guidance will result ...
The speech recognition threshold (SRT) is the lowest level at which a person can identify a sound from a closed set list of disyllabic words. ... Speech audiometry generally confirms pure tone audiometry results, and provides insight to the perceptual abilities of the individual. The intelligibility threshold is generally equivalent to the ...
Speech reception threshold (SRT) is a measure of hearing ability that is used to assess the lowest intensity level at which an individual can repeat familiar two-syllable words, known as spondee words, more than half of the time. Spondee words are chosen because they are easy to understand and are not affected by the pitch or voice quality of ...
Screening audiometry presents tones across the speech spectrum (500 to 4,000 Hz) at the upper limits of normal hearing (25 to 30 dB for adults, and 15 to 20 dB for children). 17 Results are ...
Speech audiometry in noise based on sentence tests is an important diagnostic tool to assess listeners' speech recognition threshold ... With smart speakers, there is no control over the absolute presentation level, potential errors from the automated response logging, and room acoustics. ...
Speech audiometry includes speech detection (awareness) thresholds (SDTs), speech recognition thresholds (SRTs), word recognition testing, and SIN testing. Speech audiometry can be used to evaluate hearing sensitivity and speech perception ability as well as for site-of-lesion assessment. ... The methods differ in the initial presentation level ...
How to Read an Audiogram | Iowa Head and Neck Protocols