- Hypothesis Testing: Definition, Uses, Limitations + Examples

Hypothesis testing is as old as the scientific method and is at the heart of the research process.
Research exists to validate or disprove assumptions about various phenomena. The process of validation involves testing and it is in this context that we will explore hypothesis testing.

What is a Hypothesis?
A hypothesis is a calculated prediction or assumption about a population parameter based on limited evidence. The whole idea behind hypothesis formulation is testing—this means the researcher subjects his or her calculated assumption to a series of evaluations to know whether they are true or false.
Typically, every research starts with a hypothesis—the investigator makes a claim and experiments to prove that this claim is true or false . For instance, if you predict that students who drink milk before class perform better than those who don’t, then this becomes a hypothesis that can be confirmed or refuted using an experiment.
Read: What is Empirical Research Study? [Examples & Method]
What are the Types of Hypotheses?
1. simple hypothesis.
Also known as a basic hypothesis, a simple hypothesis suggests that an independent variable is responsible for a corresponding dependent variable. In other words, an occurrence of the independent variable inevitably leads to an occurrence of the dependent variable.
Typically, simple hypotheses are considered as generally true, and they establish a causal relationship between two variables.
Examples of Simple Hypothesis
- Drinking soda and other sugary drinks can cause obesity.
- Smoking cigarettes daily leads to lung cancer.
2. Complex Hypothesis
A complex hypothesis is also known as a modal. It accounts for the causal relationship between two independent variables and the resulting dependent variables. This means that the combination of the independent variables leads to the occurrence of the dependent variables .
Examples of Complex Hypotheses
- Adults who do not smoke and drink are less likely to develop liver-related conditions.
- Global warming causes icebergs to melt which in turn causes major changes in weather patterns.
3. Null Hypothesis
As the name suggests, a null hypothesis is formed when a researcher suspects that there’s no relationship between the variables in an observation. In this case, the purpose of the research is to approve or disapprove this assumption.
Examples of Null Hypothesis
- This is no significant change in a student’s performance if they drink coffee or tea before classes.
- There’s no significant change in the growth of a plant if one uses distilled water only or vitamin-rich water.
Read: Research Report: Definition, Types + [Writing Guide]
4. Alternative Hypothesis
To disapprove a null hypothesis, the researcher has to come up with an opposite assumption—this assumption is known as the alternative hypothesis. This means if the null hypothesis says that A is false, the alternative hypothesis assumes that A is true.
An alternative hypothesis can be directional or non-directional depending on the direction of the difference. A directional alternative hypothesis specifies the direction of the tested relationship, stating that one variable is predicted to be larger or smaller than the null value while a non-directional hypothesis only validates the existence of a difference without stating its direction.
Examples of Alternative Hypotheses
- Starting your day with a cup of tea instead of a cup of coffee can make you more alert in the morning.
- The growth of a plant improves significantly when it receives distilled water instead of vitamin-rich water.
5. Logical Hypothesis
Logical hypotheses are some of the most common types of calculated assumptions in systematic investigations. It is an attempt to use your reasoning to connect different pieces in research and build a theory using little evidence. In this case, the researcher uses any data available to him, to form a plausible assumption that can be tested.
Examples of Logical Hypothesis
- Waking up early helps you to have a more productive day.
- Beings from Mars would not be able to breathe the air in the atmosphere of the Earth.
6. Empirical Hypothesis
After forming a logical hypothesis, the next step is to create an empirical or working hypothesis. At this stage, your logical hypothesis undergoes systematic testing to prove or disprove the assumption. An empirical hypothesis is subject to several variables that can trigger changes and lead to specific outcomes.
Examples of Empirical Testing
- People who eat more fish run faster than people who eat meat.
- Women taking vitamin E grow hair faster than those taking vitamin K.
7. Statistical Hypothesis
When forming a statistical hypothesis, the researcher examines the portion of a population of interest and makes a calculated assumption based on the data from this sample. A statistical hypothesis is most common with systematic investigations involving a large target audience. Here, it’s impossible to collect responses from every member of the population so you have to depend on data from your sample and extrapolate the results to the wider population.
Examples of Statistical Hypothesis
- 45% of students in Louisiana have middle-income parents.
- 80% of the UK’s population gets a divorce because of irreconcilable differences.
What is Hypothesis Testing?
Hypothesis testing is an assessment method that allows researchers to determine the plausibility of a hypothesis. It involves testing an assumption about a specific population parameter to know whether it’s true or false. These population parameters include variance, standard deviation, and median.
Typically, hypothesis testing starts with developing a null hypothesis and then performing several tests that support or reject the null hypothesis. The researcher uses test statistics to compare the association or relationship between two or more variables.
Explore: Research Bias: Definition, Types + Examples
Researchers also use hypothesis testing to calculate the coefficient of variation and determine if the regression relationship and the correlation coefficient are statistically significant.
How Hypothesis Testing Works
The basis of hypothesis testing is to examine and analyze the null hypothesis and alternative hypothesis to know which one is the most plausible assumption. Since both assumptions are mutually exclusive, only one can be true. In other words, the occurrence of a null hypothesis destroys the chances of the alternative coming to life, and vice-versa.
Interesting: 21 Chrome Extensions for Academic Researchers in 2021
What Are The Stages of Hypothesis Testing?
To successfully confirm or refute an assumption, the researcher goes through five (5) stages of hypothesis testing;
- Determine the null hypothesis
- Specify the alternative hypothesis
- Set the significance level
- Calculate the test statistics and corresponding P-value
- Draw your conclusion
- Determine the Null Hypothesis
Like we mentioned earlier, hypothesis testing starts with creating a null hypothesis which stands as an assumption that a certain statement is false or implausible. For example, the null hypothesis (H0) could suggest that different subgroups in the research population react to a variable in the same way.
- Specify the Alternative Hypothesis
Once you know the variables for the null hypothesis, the next step is to determine the alternative hypothesis. The alternative hypothesis counters the null assumption by suggesting the statement or assertion is true. Depending on the purpose of your research, the alternative hypothesis can be one-sided or two-sided.
Using the example we established earlier, the alternative hypothesis may argue that the different sub-groups react differently to the same variable based on several internal and external factors.
- Set the Significance Level
Many researchers create a 5% allowance for accepting the value of an alternative hypothesis, even if the value is untrue. This means that there is a 0.05 chance that one would go with the value of the alternative hypothesis, despite the truth of the null hypothesis.
Something to note here is that the smaller the significance level, the greater the burden of proof needed to reject the null hypothesis and support the alternative hypothesis.
Explore: What is Data Interpretation? + [Types, Method & Tools]
- Calculate the Test Statistics and Corresponding P-Value
Test statistics in hypothesis testing allow you to compare different groups between variables while the p-value accounts for the probability of obtaining sample statistics if your null hypothesis is true. In this case, your test statistics can be the mean, median and similar parameters.
If your p-value is 0.65, for example, then it means that the variable in your hypothesis will happen 65 in100 times by pure chance. Use this formula to determine the p-value for your data:

- Draw Your Conclusions
After conducting a series of tests, you should be able to agree or refute the hypothesis based on feedback and insights from your sample data.
Applications of Hypothesis Testing in Research
Hypothesis testing isn’t only confined to numbers and calculations; it also has several real-life applications in business, manufacturing, advertising, and medicine.
In a factory or other manufacturing plants, hypothesis testing is an important part of quality and production control before the final products are approved and sent out to the consumer.
During ideation and strategy development, C-level executives use hypothesis testing to evaluate their theories and assumptions before any form of implementation. For example, they could leverage hypothesis testing to determine whether or not some new advertising campaign, marketing technique, etc. causes increased sales.
In addition, hypothesis testing is used during clinical trials to prove the efficacy of a drug or new medical method before its approval for widespread human usage.
What is an Example of Hypothesis Testing?
An employer claims that her workers are of above-average intelligence. She takes a random sample of 20 of them and gets the following results:
Mean IQ Scores: 110
Standard Deviation: 15
Mean Population IQ: 100
Step 1: Using the value of the mean population IQ, we establish the null hypothesis as 100.
Step 2: State that the alternative hypothesis is greater than 100.
Step 3: State the alpha level as 0.05 or 5%
Step 4: Find the rejection region area (given by your alpha level above) from the z-table. An area of .05 is equal to a z-score of 1.645.
Step 5: Calculate the test statistics using this formula

Z = (110–100) ÷ (15÷√20)
10 ÷ 3.35 = 2.99
If the value of the test statistics is higher than the value of the rejection region, then you should reject the null hypothesis. If it is less, then you cannot reject the null.
In this case, 2.99 > 1.645 so we reject the null.
Importance/Benefits of Hypothesis Testing
The most significant benefit of hypothesis testing is it allows you to evaluate the strength of your claim or assumption before implementing it in your data set. Also, hypothesis testing is the only valid method to prove that something “is or is not”. Other benefits include:
- Hypothesis testing provides a reliable framework for making any data decisions for your population of interest.
- It helps the researcher to successfully extrapolate data from the sample to the larger population.
- Hypothesis testing allows the researcher to determine whether the data from the sample is statistically significant.
- Hypothesis testing is one of the most important processes for measuring the validity and reliability of outcomes in any systematic investigation.
- It helps to provide links to the underlying theory and specific research questions.
Criticism and Limitations of Hypothesis Testing
Several limitations of hypothesis testing can affect the quality of data you get from this process. Some of these limitations include:
- The interpretation of a p-value for observation depends on the stopping rule and definition of multiple comparisons. This makes it difficult to calculate since the stopping rule is subject to numerous interpretations, plus “multiple comparisons” are unavoidably ambiguous.
- Conceptual issues often arise in hypothesis testing, especially if the researcher merges Fisher and Neyman-Pearson’s methods which are conceptually distinct.
- In an attempt to focus on the statistical significance of the data, the researcher might ignore the estimation and confirmation by repeated experiments.
- Hypothesis testing can trigger publication bias, especially when it requires statistical significance as a criterion for publication.
- When used to detect whether a difference exists between groups, hypothesis testing can trigger absurd assumptions that affect the reliability of your observation.
Connect to Formplus, Get Started Now - It's Free!
- alternative hypothesis
- alternative vs null hypothesis
- complex hypothesis
- empirical hypothesis
- hypothesis testing
- logical hypothesis
- simple hypothesis
- statistical hypothesis
- busayo.longe
You may also like:
Alternative vs Null Hypothesis: Pros, Cons, Uses & Examples
We are going to discuss alternative hypotheses and null hypotheses in this post and how they work in research.
Internal Validity in Research: Definition, Threats, Examples
In this article, we will discuss the concept of internal validity, some clear examples, its importance, and how to test it.
What is Pure or Basic Research? + [Examples & Method]
Simple guide on pure or basic research, its methods, characteristics, advantages, and examples in science, medicine, education and psychology
Type I vs Type II Errors: Causes, Examples & Prevention
This article will discuss the two different types of errors in hypothesis testing and how you can prevent them from occurring in your research
Formplus - For Seamless Data Collection
Collect data the right way with a versatile data collection tool. try formplus and transform your work productivity today..
- How it works

Hypothesis Testing – A Complete Guide with Examples
Published by Alvin Nicolas at August 14th, 2021 , Revised On October 26, 2023
In statistics, hypothesis testing is a critical tool. It allows us to make informed decisions about populations based on sample data. Whether you are a researcher trying to prove a scientific point, a marketer analysing A/B test results, or a manufacturer ensuring quality control, hypothesis testing plays a pivotal role. This guide aims to introduce you to the concept and walk you through real-world examples.
What is a Hypothesis and a Hypothesis Testing?
A hypothesis is considered a belief or assumption that has to be accepted, rejected, proved or disproved. In contrast, a research hypothesis is a research question for a researcher that has to be proven correct or incorrect through investigation.
What is Hypothesis Testing?
Hypothesis testing is a scientific method used for making a decision and drawing conclusions by using a statistical approach. It is used to suggest new ideas by testing theories to know whether or not the sample data supports research. A research hypothesis is a predictive statement that has to be tested using scientific methods that join an independent variable to a dependent variable.
Example: The academic performance of student A is better than student B
Characteristics of the Hypothesis to be Tested
A hypothesis should be:
- Clear and precise
- Capable of being tested
- Able to relate to a variable
- Stated in simple terms
- Consistent with known facts
- Limited in scope and specific
- Tested in a limited timeframe
- Explain the facts in detail
What is a Null Hypothesis and Alternative Hypothesis?
A null hypothesis is a hypothesis when there is no significant relationship between the dependent and the participants’ independent variables .
In simple words, it’s a hypothesis that has been put forth but hasn’t been proved as yet. A researcher aims to disprove the theory. The abbreviation “Ho” is used to denote a null hypothesis.
If you want to compare two methods and assume that both methods are equally good, this assumption is considered the null hypothesis.
Example: In an automobile trial, you feel that the new vehicle’s mileage is similar to the previous model of the car, on average. You can write it as: Ho: there is no difference between the mileage of both vehicles. If your findings don’t support your hypothesis and you get opposite results, this outcome will be considered an alternative hypothesis.
If you assume that one method is better than another method, then it’s considered an alternative hypothesis. The alternative hypothesis is the theory that a researcher seeks to prove and is typically denoted by H1 or HA.
If you support a null hypothesis, it means you’re not supporting the alternative hypothesis. Similarly, if you reject a null hypothesis, it means you are recommending the alternative hypothesis.
Example: In an automobile trial, you feel that the new vehicle’s mileage is better than the previous model of the vehicle. You can write it as; Ha: the two vehicles have different mileage. On average/ the fuel consumption of the new vehicle model is better than the previous model.
If a null hypothesis is rejected during the hypothesis test, even if it’s true, then it is considered as a type-I error. On the other hand, if you don’t dismiss a hypothesis, even if it’s false because you could not identify its falseness, it’s considered a type-II error.
Hire an Expert Researcher
Orders completed by our expert writers are
- Formally drafted in academic style
- 100% Plagiarism free & 100% Confidential
- Never resold
- Include unlimited free revisions
- Completed to match exact client requirements

How to Conduct Hypothesis Testing?
Here is a step-by-step guide on how to conduct hypothesis testing.
Step 1: State the Null and Alternative Hypothesis
Once you develop a research hypothesis, it’s important to state it is as a Null hypothesis (Ho) and an Alternative hypothesis (Ha) to test it statistically.
A null hypothesis is a preferred choice as it provides the opportunity to test the theory. In contrast, you can accept the alternative hypothesis when the null hypothesis has been rejected.
Example: You want to identify a relationship between obesity of men and women and the modern living style. You develop a hypothesis that women, on average, gain weight quickly compared to men. Then you write it as: Ho: Women, on average, don’t gain weight quickly compared to men. Ha: Women, on average, gain weight quickly compared to men.
Step 2: Data Collection
Hypothesis testing follows the statistical method, and statistics are all about data. It’s challenging to gather complete information about a specific population you want to study. You need to gather the data obtained through a large number of samples from a specific population.
Example: Suppose you want to test the difference in the rate of obesity between men and women. You should include an equal number of men and women in your sample. Then investigate various aspects such as their lifestyle, eating patterns and profession, and any other variables that may influence average weight. You should also determine your study’s scope, whether it applies to a specific group of population or worldwide population. You can use available information from various places, countries, and regions.
Step 3: Select Appropriate Statistical Test
There are many types of statistical tests , but we discuss the most two common types below, such as One-sided and two-sided tests.
Note: Your choice of the type of test depends on the purpose of your study
One-sided Test
In the one-sided test, the values of rejecting a null hypothesis are located in one tail of the probability distribution. The set of values is less or higher than the critical value of the test. It is also called a one-tailed test of significance.
Example: If you want to test that all mangoes in a basket are ripe. You can write it as: Ho: All mangoes in the basket, on average, are ripe. If you find all ripe mangoes in the basket, the null hypothesis you developed will be true.
Two-sided Test
In the two-sided test, the values of rejecting a null hypothesis are located on both tails of the probability distribution. The set of values is less or higher than the first critical value of the test and higher than the second critical value test. It is also called a two-tailed test of significance.
Example: Nothing can be explicitly said whether all mangoes are ripe in the basket. If you reject the null hypothesis (Ho: All mangoes in the basket, on average, are ripe), then it means all mangoes in the basket are not likely to be ripe. A few mangoes could be raw as well.
Get statistical analysis help at an affordable price
- An expert statistician will complete your work
- Rigorous quality checks
- Confidentiality and reliability
- Any statistical software of your choice
- Free Plagiarism Report

Step 4: Select the Level of Significance
When you reject a null hypothesis, even if it’s true during a statistical hypothesis, it is considered the significance level . It is the probability of a type one error. The significance should be as minimum as possible to avoid the type-I error, which is considered severe and should be avoided.
If the significance level is minimum, then it prevents the researchers from false claims.
The significance level is denoted by P, and it has given the value of 0.05 (P=0.05)
If the P-Value is less than 0.05, then the difference will be significant. If the P-value is higher than 0.05, then the difference is non-significant.
Example: Suppose you apply a one-sided test to test whether women gain weight quickly compared to men. You get to know about the average weight between men and women and the factors promoting weight gain.
Step 5: Find out Whether the Null Hypothesis is Rejected or Supported
After conducting a statistical test, you should identify whether your null hypothesis is rejected or accepted based on the test results. It would help if you observed the P-value for this.
Example: If you find the P-value of your test is less than 0.5/5%, then you need to reject your null hypothesis (Ho: Women, on average, don’t gain weight quickly compared to men). On the other hand, if a null hypothesis is rejected, then it means the alternative hypothesis might be true (Ha: Women, on average, gain weight quickly compared to men. If you find your test’s P-value is above 0.5/5%, then it means your null hypothesis is true.
Step 6: Present the Outcomes of your Study
The final step is to present the outcomes of your study . You need to ensure whether you have met the objectives of your research or not.
In the discussion section and conclusion , you can present your findings by using supporting evidence and conclude whether your null hypothesis was rejected or supported.
In the result section, you can summarise your study’s outcomes, including the average difference and P-value of the two groups.
If we talk about the findings, our study your results will be as follows:
Example: In the study of identifying whether women gain weight quickly compared to men, we found the P-value is less than 0.5. Hence, we can reject the null hypothesis (Ho: Women, on average, don’t gain weight quickly than men) and conclude that women may likely gain weight quickly than men.
Did you know in your academic paper you should not mention whether you have accepted or rejected the null hypothesis?
Always remember that you either conclude to reject Ho in favor of Haor do not reject Ho . It would help if you never rejected Ha or even accept Ha .
Suppose your null hypothesis is rejected in the hypothesis testing. If you conclude reject Ho in favor of Haor do not reject Ho, then it doesn’t mean that the null hypothesis is true. It only means that there is a lack of evidence against Ho in favour of Ha. If your null hypothesis is not true, then the alternative hypothesis is likely to be true.
Example: We found that the P-value is less than 0.5. Hence, we can conclude reject Ho in favour of Ha (Ho: Women, on average, don’t gain weight quickly than men) reject Ho in favour of Ha. However, rejected in favour of Ha means (Ha: women may likely to gain weight quickly than men)
Frequently Asked Questions
What are the 3 types of hypothesis test.
The 3 types of hypothesis tests are:
- One-Sample Test : Compare sample data to a known population value.
- Two-Sample Test : Compare means between two sample groups.
- ANOVA : Analyze variance among multiple groups to determine significant differences.
What is a hypothesis?
A hypothesis is a proposed explanation or prediction about a phenomenon, often based on observations. It serves as a starting point for research or experimentation, providing a testable statement that can either be supported or refuted through data and analysis. In essence, it’s an educated guess that drives scientific inquiry.
What are null hypothesis?
A null hypothesis (often denoted as H0) suggests that there is no effect or difference in a study or experiment. It represents a default position or status quo. Statistical tests evaluate data to determine if there’s enough evidence to reject this null hypothesis.
What is the probability value?
The probability value, or p-value, is a measure used in statistics to determine the significance of an observed effect. It indicates the probability of obtaining the observed results, or more extreme, if the null hypothesis were true. A small p-value (typically <0.05) suggests evidence against the null hypothesis, warranting its rejection.
What is p value?
The p-value is a fundamental concept in statistical hypothesis testing. It represents the probability of observing a test statistic as extreme, or more so, than the one calculated from sample data, assuming the null hypothesis is true. A low p-value suggests evidence against the null, possibly justifying its rejection.
What is a t test?
A t-test is a statistical test used to compare the means of two groups. It determines if observed differences between the groups are statistically significant or if they likely occurred by chance. Commonly applied in research, there are different t-tests, including independent, paired, and one-sample, tailored to various data scenarios.
When to reject null hypothesis?
Reject the null hypothesis when the test statistic falls into a predefined rejection region or when the p-value is less than the chosen significance level (commonly 0.05). This suggests that the observed data is unlikely under the null hypothesis, indicating evidence for the alternative hypothesis. Always consider the study’s context.
You May Also Like
A confounding variable can potentially affect both the suspected cause and the suspected effect. Here is all you need to know about accounting for confounding variables in research.
Textual analysis is the method of analysing and understanding the text. We need to look carefully at the text to identify the writer’s context and message.
Sampling methods are used to to draw valid conclusions about a large community, organization or group of people, but they are based on evidence and reasoning.
USEFUL LINKS
LEARNING RESOURCES

COMPANY DETAILS

- How It Works

User Preferences
Content preview.
Arcu felis bibendum ut tristique et egestas quis:
- Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris
- Duis aute irure dolor in reprehenderit in voluptate
- Excepteur sint occaecat cupidatat non proident
Keyboard Shortcuts
S.3 hypothesis testing.
In reviewing hypothesis tests, we start first with the general idea. Then, we keep returning to the basic procedures of hypothesis testing, each time adding a little more detail.
The general idea of hypothesis testing involves:
- Making an initial assumption.
- Collecting evidence (data).
- Based on the available evidence (data), deciding whether to reject or not reject the initial assumption.
Every hypothesis test — regardless of the population parameter involved — requires the above three steps.
Example S.3.1
Is normal body temperature really 98.6 degrees f section .
Consider the population of many, many adults. A researcher hypothesized that the average adult body temperature is lower than the often-advertised 98.6 degrees F. That is, the researcher wants an answer to the question: "Is the average adult body temperature 98.6 degrees? Or is it lower?" To answer his research question, the researcher starts by assuming that the average adult body temperature was 98.6 degrees F.
Then, the researcher went out and tried to find evidence that refutes his initial assumption. In doing so, he selects a random sample of 130 adults. The average body temperature of the 130 sampled adults is 98.25 degrees.
Then, the researcher uses the data he collected to make a decision about his initial assumption. It is either likely or unlikely that the researcher would collect the evidence he did given his initial assumption that the average adult body temperature is 98.6 degrees:
- If it is likely , then the researcher does not reject his initial assumption that the average adult body temperature is 98.6 degrees. There is not enough evidence to do otherwise.
- either the researcher's initial assumption is correct and he experienced a very unusual event;
- or the researcher's initial assumption is incorrect.
In statistics, we generally don't make claims that require us to believe that a very unusual event happened. That is, in the practice of statistics, if the evidence (data) we collected is unlikely in light of the initial assumption, then we reject our initial assumption.
Example S.3.2
Criminal trial analogy section .
One place where you can consistently see the general idea of hypothesis testing in action is in criminal trials held in the United States. Our criminal justice system assumes "the defendant is innocent until proven guilty." That is, our initial assumption is that the defendant is innocent.
In the practice of statistics, we make our initial assumption when we state our two competing hypotheses -- the null hypothesis ( H 0 ) and the alternative hypothesis ( H A ). Here, our hypotheses are:
- H 0 : Defendant is not guilty (innocent)
- H A : Defendant is guilty
In statistics, we always assume the null hypothesis is true . That is, the null hypothesis is always our initial assumption.
The prosecution team then collects evidence — such as finger prints, blood spots, hair samples, carpet fibers, shoe prints, ransom notes, and handwriting samples — with the hopes of finding "sufficient evidence" to make the assumption of innocence refutable.
In statistics, the data are the evidence.
The jury then makes a decision based on the available evidence:
- If the jury finds sufficient evidence — beyond a reasonable doubt — to make the assumption of innocence refutable, the jury rejects the null hypothesis and deems the defendant guilty. We behave as if the defendant is guilty.
- If there is insufficient evidence, then the jury does not reject the null hypothesis . We behave as if the defendant is innocent.
In statistics, we always make one of two decisions. We either "reject the null hypothesis" or we "fail to reject the null hypothesis."
Errors in Hypothesis Testing Section
Did you notice the use of the phrase "behave as if" in the previous discussion? We "behave as if" the defendant is guilty; we do not "prove" that the defendant is guilty. And, we "behave as if" the defendant is innocent; we do not "prove" that the defendant is innocent.
This is a very important distinction! We make our decision based on evidence not on 100% guaranteed proof. Again:
- If we reject the null hypothesis, we do not prove that the alternative hypothesis is true.
- If we do not reject the null hypothesis, we do not prove that the null hypothesis is true.
We merely state that there is enough evidence to behave one way or the other. This is always true in statistics! Because of this, whatever the decision, there is always a chance that we made an error .
Let's review the two types of errors that can be made in criminal trials:
| Jury Decision | Truth | ||
|---|---|---|---|
| Not Guilty | Guilty | ||
| Not Guilty | OK | ERROR | |
| Guilty | ERROR | OK | |
Table S.3.2 shows how this corresponds to the two types of errors in hypothesis testing.
| Decision | |||
|---|---|---|---|
| Null Hypothesis | Alternative Hypothesis | ||
| Do not Reject Null | OK | Type II Error | |
| Reject Null | Type I Error | OK | |
Note that, in statistics, we call the two types of errors by two different names -- one is called a "Type I error," and the other is called a "Type II error." Here are the formal definitions of the two types of errors:
There is always a chance of making one of these errors. But, a good scientific study will minimize the chance of doing so!
Making the Decision Section
Recall that it is either likely or unlikely that we would observe the evidence we did given our initial assumption. If it is likely , we do not reject the null hypothesis. If it is unlikely , then we reject the null hypothesis in favor of the alternative hypothesis. Effectively, then, making the decision reduces to determining "likely" or "unlikely."
In statistics, there are two ways to determine whether the evidence is likely or unlikely given the initial assumption:
- We could take the " critical value approach " (favored in many of the older textbooks).
- Or, we could take the " P -value approach " (what is used most often in research, journal articles, and statistical software).
In the next two sections, we review the procedures behind each of these two approaches. To make our review concrete, let's imagine that μ is the average grade point average of all American students who major in mathematics. We first review the critical value approach for conducting each of the following three hypothesis tests about the population mean $\mu$:
| : = 3 | : > 3 | |
| : = 3 | : < 3 | |
| : = 3 | : ≠ 3 |
In Practice
- We would want to conduct the first hypothesis test if we were interested in concluding that the average grade point average of the group is more than 3.
- We would want to conduct the second hypothesis test if we were interested in concluding that the average grade point average of the group is less than 3.
- And, we would want to conduct the third hypothesis test if we were only interested in concluding that the average grade point average of the group differs from 3 (without caring whether it is more or less than 3).
Upon completing the review of the critical value approach, we review the P -value approach for conducting each of the above three hypothesis tests about the population mean \(\mu\). The procedures that we review here for both approaches easily extend to hypothesis tests about any other population parameter.
Hypothesis Testing
When you conduct a piece of quantitative research, you are inevitably attempting to answer a research question or hypothesis that you have set. One method of evaluating this research question is via a process called hypothesis testing , which is sometimes also referred to as significance testing . Since there are many facets to hypothesis testing, we start with the example we refer to throughout this guide.
An example of a lecturer's dilemma
Two statistics lecturers, Sarah and Mike, think that they use the best method to teach their students. Each lecturer has 50 statistics students who are studying a graduate degree in management. In Sarah's class, students have to attend one lecture and one seminar class every week, whilst in Mike's class students only have to attend one lecture. Sarah thinks that seminars, in addition to lectures, are an important teaching method in statistics, whilst Mike believes that lectures are sufficient by themselves and thinks that students are better off solving problems by themselves in their own time. This is the first year that Sarah has given seminars, but since they take up a lot of her time, she wants to make sure that she is not wasting her time and that seminars improve her students' performance.
The research hypothesis
The first step in hypothesis testing is to set a research hypothesis. In Sarah and Mike's study, the aim is to examine the effect that two different teaching methods – providing both lectures and seminar classes (Sarah), and providing lectures by themselves (Mike) – had on the performance of Sarah's 50 students and Mike's 50 students. More specifically, they want to determine whether performance is different between the two different teaching methods. Whilst Mike is skeptical about the effectiveness of seminars, Sarah clearly believes that giving seminars in addition to lectures helps her students do better than those in Mike's class. This leads to the following research hypothesis:
| Research Hypothesis: | When students attend seminar classes, in addition to lectures, their performance increases. |
Before moving onto the second step of the hypothesis testing process, we need to take you on a brief detour to explain why you need to run hypothesis testing at all. This is explained next.
Sample to population
If you have measured individuals (or any other type of "object") in a study and want to understand differences (or any other type of effect), you can simply summarize the data you have collected. For example, if Sarah and Mike wanted to know which teaching method was the best, they could simply compare the performance achieved by the two groups of students – the group of students that took lectures and seminar classes, and the group of students that took lectures by themselves – and conclude that the best method was the teaching method which resulted in the highest performance. However, this is generally of only limited appeal because the conclusions could only apply to students in this study. However, if those students were representative of all statistics students on a graduate management degree, the study would have wider appeal.
In statistics terminology, the students in the study are the sample and the larger group they represent (i.e., all statistics students on a graduate management degree) is called the population . Given that the sample of statistics students in the study are representative of a larger population of statistics students, you can use hypothesis testing to understand whether any differences or effects discovered in the study exist in the population. In layman's terms, hypothesis testing is used to establish whether a research hypothesis extends beyond those individuals examined in a single study.
Another example could be taking a sample of 200 breast cancer sufferers in order to test a new drug that is designed to eradicate this type of cancer. As much as you are interested in helping these specific 200 cancer sufferers, your real goal is to establish that the drug works in the population (i.e., all breast cancer sufferers).
As such, by taking a hypothesis testing approach, Sarah and Mike want to generalize their results to a population rather than just the students in their sample. However, in order to use hypothesis testing, you need to re-state your research hypothesis as a null and alternative hypothesis. Before you can do this, it is best to consider the process/structure involved in hypothesis testing and what you are measuring. This structure is presented on the next page .
- Skip to secondary menu
- Skip to main content
- Skip to primary sidebar
Statistics By Jim
Making statistics intuitive
Statistical Hypothesis Testing Overview
By Jim Frost 59 Comments
In this blog post, I explain why you need to use statistical hypothesis testing and help you navigate the essential terminology. Hypothesis testing is a crucial procedure to perform when you want to make inferences about a population using a random sample. These inferences include estimating population properties such as the mean, differences between means, proportions, and the relationships between variables.
This post provides an overview of statistical hypothesis testing. If you need to perform hypothesis tests, consider getting my book, Hypothesis Testing: An Intuitive Guide .
Why You Should Perform Statistical Hypothesis Testing

Hypothesis testing is a form of inferential statistics that allows us to draw conclusions about an entire population based on a representative sample. You gain tremendous benefits by working with a sample. In most cases, it is simply impossible to observe the entire population to understand its properties. The only alternative is to collect a random sample and then use statistics to analyze it.
While samples are much more practical and less expensive to work with, there are trade-offs. When you estimate the properties of a population from a sample, the sample statistics are unlikely to equal the actual population value exactly. For instance, your sample mean is unlikely to equal the population mean. The difference between the sample statistic and the population value is the sample error.
Differences that researchers observe in samples might be due to sampling error rather than representing a true effect at the population level. If sampling error causes the observed difference, the next time someone performs the same experiment the results might be different. Hypothesis testing incorporates estimates of the sampling error to help you make the correct decision. Learn more about Sampling Error .
For example, if you are studying the proportion of defects produced by two manufacturing methods, any difference you observe between the two sample proportions might be sample error rather than a true difference. If the difference does not exist at the population level, you won’t obtain the benefits that you expect based on the sample statistics. That can be a costly mistake!
Let’s cover some basic hypothesis testing terms that you need to know.
Background information : Difference between Descriptive and Inferential Statistics and Populations, Parameters, and Samples in Inferential Statistics
Hypothesis Testing
Hypothesis testing is a statistical analysis that uses sample data to assess two mutually exclusive theories about the properties of a population. Statisticians call these theories the null hypothesis and the alternative hypothesis. A hypothesis test assesses your sample statistic and factors in an estimate of the sample error to determine which hypothesis the data support.
When you can reject the null hypothesis, the results are statistically significant, and your data support the theory that an effect exists at the population level.
The effect is the difference between the population value and the null hypothesis value. The effect is also known as population effect or the difference. For example, the mean difference between the health outcome for a treatment group and a control group is the effect.
Typically, you do not know the size of the actual effect. However, you can use a hypothesis test to help you determine whether an effect exists and to estimate its size. Hypothesis tests convert your sample effect into a test statistic, which it evaluates for statistical significance. Learn more about Test Statistics .
An effect can be statistically significant, but that doesn’t necessarily indicate that it is important in a real-world, practical sense. For more information, read my post about Statistical vs. Practical Significance .
Null Hypothesis
The null hypothesis is one of two mutually exclusive theories about the properties of the population in hypothesis testing. Typically, the null hypothesis states that there is no effect (i.e., the effect size equals zero). The null is often signified by H 0 .
In all hypothesis testing, the researchers are testing an effect of some sort. The effect can be the effectiveness of a new vaccination, the durability of a new product, the proportion of defect in a manufacturing process, and so on. There is some benefit or difference that the researchers hope to identify.
However, it’s possible that there is no effect or no difference between the experimental groups. In statistics, we call this lack of an effect the null hypothesis. Therefore, if you can reject the null, you can favor the alternative hypothesis, which states that the effect exists (doesn’t equal zero) at the population level.
You can think of the null as the default theory that requires sufficiently strong evidence against in order to reject it.
For example, in a 2-sample t-test, the null often states that the difference between the two means equals zero.
When you can reject the null hypothesis, your results are statistically significant. Learn more about Statistical Significance: Definition & Meaning .
Related post : Understanding the Null Hypothesis in More Detail
Alternative Hypothesis
The alternative hypothesis is the other theory about the properties of the population in hypothesis testing. Typically, the alternative hypothesis states that a population parameter does not equal the null hypothesis value. In other words, there is a non-zero effect. If your sample contains sufficient evidence, you can reject the null and favor the alternative hypothesis. The alternative is often identified with H 1 or H A .
For example, in a 2-sample t-test, the alternative often states that the difference between the two means does not equal zero.
You can specify either a one- or two-tailed alternative hypothesis:
If you perform a two-tailed hypothesis test, the alternative states that the population parameter does not equal the null value. For example, when the alternative hypothesis is H A : μ ≠ 0, the test can detect differences both greater than and less than the null value.
A one-tailed alternative has more power to detect an effect but it can test for a difference in only one direction. For example, H A : μ > 0 can only test for differences that are greater than zero.
Related posts : Understanding T-tests and One-Tailed and Two-Tailed Hypothesis Tests Explained

P-values are the probability that you would obtain the effect observed in your sample, or larger, if the null hypothesis is correct. In simpler terms, p-values tell you how strongly your sample data contradict the null. Lower p-values represent stronger evidence against the null. You use P-values in conjunction with the significance level to determine whether your data favor the null or alternative hypothesis.
Related post : Interpreting P-values Correctly
Significance Level (Alpha)

For instance, a significance level of 0.05 signifies a 5% risk of deciding that an effect exists when it does not exist.
Use p-values and significance levels together to help you determine which hypothesis the data support. If the p-value is less than your significance level, you can reject the null and conclude that the effect is statistically significant. In other words, the evidence in your sample is strong enough to be able to reject the null hypothesis at the population level.
Related posts : Graphical Approach to Significance Levels and P-values and Conceptual Approach to Understanding Significance Levels
Types of Errors in Hypothesis Testing
Statistical hypothesis tests are not 100% accurate because they use a random sample to draw conclusions about entire populations. There are two types of errors related to drawing an incorrect conclusion.
- False positives: You reject a null that is true. Statisticians call this a Type I error . The Type I error rate equals your significance level or alpha (α).
- False negatives: You fail to reject a null that is false. Statisticians call this a Type II error. Generally, you do not know the Type II error rate. However, it is a larger risk when you have a small sample size , noisy data, or a small effect size. The type II error rate is also known as beta (β).
Statistical power is the probability that a hypothesis test correctly infers that a sample effect exists in the population. In other words, the test correctly rejects a false null hypothesis. Consequently, power is inversely related to a Type II error. Power = 1 – β. Learn more about Power in Statistics .
Related posts : Types of Errors in Hypothesis Testing and Estimating a Good Sample Size for Your Study Using Power Analysis
Which Type of Hypothesis Test is Right for You?
There are many different types of procedures you can use. The correct choice depends on your research goals and the data you collect. Do you need to understand the mean or the differences between means? Or, perhaps you need to assess proportions. You can even use hypothesis testing to determine whether the relationships between variables are statistically significant.
To choose the proper statistical procedure, you’ll need to assess your study objectives and collect the correct type of data . This background research is necessary before you begin a study.
Related Post : Hypothesis Tests for Continuous, Binary, and Count Data
Statistical tests are crucial when you want to use sample data to make conclusions about a population because these tests account for sample error. Using significance levels and p-values to determine when to reject the null hypothesis improves the probability that you will draw the correct conclusion.
To see an alternative approach to these traditional hypothesis testing methods, learn about bootstrapping in statistics !
If you want to see examples of hypothesis testing in action, I recommend the following posts that I have written:
- How Effective Are Flu Shots? This example shows how you can use statistics to test proportions.
- Fatality Rates in Star Trek . This example shows how to use hypothesis testing with categorical data.
- Busting Myths About the Battle of the Sexes . A fun example based on a Mythbusters episode that assess continuous data using several different tests.
- Are Yawns Contagious? Another fun example inspired by a Mythbusters episode.
Share this:

Reader Interactions

January 14, 2024 at 8:43 am
Hello professor Jim, how are you doing! Pls. What are the properties of a population and their examples? Thanks for your time and understanding.

January 14, 2024 at 12:57 pm
Please read my post about Populations vs. Samples for more information and examples.
Also, please note there is a search bar in the upper-right margin of my website. Use that to search for topics.

July 5, 2023 at 7:05 am
Hello, I have a question as I read your post. You say in p-values section
“P-values are the probability that you would obtain the effect observed in your sample, or larger, if the null hypothesis is correct. In simpler terms, p-values tell you how strongly your sample data contradict the null. Lower p-values represent stronger evidence against the null.”
But according to your definition of effect, the null states that an effect does not exist, correct? So what I assume you want to say is that “P-values are the probability that you would obtain the effect observed in your sample, or larger, if the null hypothesis is **incorrect**.”
July 6, 2023 at 5:18 am
Hi Shrinivas,
The correct definition of p-value is that it is a probability that exists in the context of a true null hypothesis. So, the quotation is correct in stating “if the null hypothesis is correct.”
Essentially, the p-value tells you the likelihood of your observed results (or more extreme) if the null hypothesis is true. It gives you an idea of whether your results are surprising or unusual if there is no effect.
Hence, with sufficiently low p-values, you reject the null hypothesis because it’s telling you that your sample results were unlikely to have occurred if there was no effect in the population.
I hope that helps make it more clear. If not, let me know I’ll attempt to clarify!

May 8, 2023 at 12:47 am
Thanks a lot Ny best regards
May 7, 2023 at 11:15 pm
Hi Jim Can you tell me something about size effect? Thanks
May 8, 2023 at 12:29 am
Here’s a post that I’ve written about Effect Sizes that will hopefully tell you what you need to know. Please read that. Then, if you have any more specific questions about effect sizes, please post them there. Thanks!

January 7, 2023 at 4:19 pm
Hi Jim, I have only read two pages so far but I am really amazed because in few paragraphs you made me clearly understand the concepts of months of courses I received in biostatistics! Thanks so much for this work you have done it helps a lot!
January 10, 2023 at 3:25 pm
Thanks so much!

June 17, 2021 at 1:45 pm
Can you help in the following question: Rocinante36 is priced at ₹7 lakh and has been designed to deliver a mileage of 22 km/litre and a top speed of 140 km/hr. Formulate the null and alternative hypotheses for mileage and top speed to check whether the new models are performing as per the desired design specifications.

April 19, 2021 at 1:51 pm
Its indeed great to read your work statistics.
I have a doubt regarding the one sample t-test. So as per your book on hypothesis testing with reference to page no 45, you have mentioned the difference between “the sample mean and the hypothesised mean is statistically significant”. So as per my understanding it should be quoted like “the difference between the population mean and the hypothesised mean is statistically significant”. The catch here is the hypothesised mean represents the sample mean.
Please help me understand this.
Regards Rajat
April 19, 2021 at 3:46 pm
Thanks for buying my book. I’m so glad it’s been helpful!
The test is performed on the sample but the results apply to the population. Hence, if the difference between the sample mean (observed in your study) and the hypothesized mean is statistically significant, that suggests that population does not equal the hypothesized mean.
For one sample tests, the hypothesized mean is not the sample mean. It is a mean that you want to use for the test value. It usually represents a value that is important to your research. In other words, it’s a value that you pick for some theoretical/practical reasons. You pick it because you want to determine whether the population mean is different from that particular value.
I hope that helps!

November 5, 2020 at 6:24 am
Jim, you are such a magnificent statistician/economist/econometrician/data scientist etc whatever profession. Your work inspires and simplifies the lives of so many researchers around the world. I truly admire you and your work. I will buy a copy of each book you have on statistics or econometrics. Keep doing the good work. Remain ever blessed
November 6, 2020 at 9:47 pm
Hi Renatus,
Thanks so much for you very kind comments. You made my day!! I’m so glad that my website has been helpful. And, thanks so much for supporting my books! 🙂

November 2, 2020 at 9:32 pm
Hi Jim, I hope you are aware of 2019 American Statistical Association’s official statement on Statistical Significance: https://www.tandfonline.com/doi/full/10.1080/00031305.2019.1583913 In case you do not bother reading the full article, may I quote you the core message here: “We conclude, based on our review of the articles in this special issue and the broader literature, that it is time to stop using the term “statistically significant” entirely. Nor should variants such as “significantly different,” “p < 0.05,” and “nonsignificant” survive, whether expressed in words, by asterisks in a table, or in some other way."
With best wishes,
November 3, 2020 at 2:09 am
I’m definitely aware of the debate surrounding how to use p-values most effectively. However, I need to correct you on one point. The link you provide is NOT a statement by the American Statistical Association. It is an editorial by several authors.
There is considerable debate over this issue. There are problems with p-values. However, as the authors state themselves, much of the problem is over people’s mindsets about how to use p-values and their incorrect interpretations about what statistical significance does and does not mean.
If you were to read my website more thoroughly, you’d be aware that I share many of their concerns and I address them in multiple posts. One of the authors’ key points is the need to be thoughtful and conduct thoughtful research and analysis. I emphasize this aspect in multiple posts on this topic. I’ll ask you to read the following three because they all address some of the authors’ concerns and suggestions. But you might run across others to read as well.
Five Tips for Using P-values to Avoid Being Misled How to Interpret P-values Correctly P-values and the Reproducibility of Experimental Results

September 24, 2020 at 11:52 pm
HI Jim, i just want you to know that you made explanation for Statistics so simple! I should say lesser and fewer words that reduce the complexity. All the best! 🙂
September 25, 2020 at 1:03 am
Thanks, Rene! Your kind words mean a lot to me! I’m so glad it has been helpful!

September 23, 2020 at 2:21 am
Honestly, I never understood stats during my entire M.Ed course and was another nightmare for me. But how easily you have explained each concept, I have understood stats way beyond my imagination. Thank you so much for helping ignorant research scholars like us. Looking forward to get hardcopy of your book. Kindly tell is it available through flipkart?
September 24, 2020 at 11:14 pm
I’m so happy to hear that my website has been helpful!
I checked on flipkart and it appears like my books are not available there. I’m never exactly sure where they’re available due to the vagaries of different distribution channels. They are available on Amazon in India.
Introduction to Statistics: An Intuitive Guide (Amazon IN) Hypothesis Testing: An Intuitive Guide (Amazon IN)

July 26, 2020 at 11:57 am
Dear Jim I am a teacher from India . I don’t have any background in statistics, and still I should tell that in a single read I can follow your explanations . I take my entire biostatistics class for botany graduates with your explanations. Thanks a lot. May I know how I can avail your books in India
July 28, 2020 at 12:31 am
Right now my books are only available as ebooks from my website. However, soon I’ll have some exciting news about other ways to obtain it. Stay tuned! I’ll announce it on my email list. If you’re not already on it, you can sign up using the form that is in the right margin of my website.

June 22, 2020 at 2:02 pm
Also can you please let me if this book covers topics like EDA and principal component analysis?
June 22, 2020 at 2:07 pm
This book doesn’t cover principal components analysis. Although, I wouldn’t really classify that as a hypothesis test. In the future, I might write a multivariate analysis book that would cover this and others. But, that’s well down the road.
My Introduction to Statistics covers EDA. That’s the largely graphical look at your data that you often do prior to hypothesis testing. The Introduction book perfectly leads right into the Hypothesis Testing book.
June 22, 2020 at 1:45 pm
Thanks for the detailed explanation. It does clear my doubts. I saw that your book related to hypothesis testing has the topics that I am studying currently. I am looking forward to purchasing it.
Regards, Take Care
June 19, 2020 at 1:03 pm
For this particular article I did not understand a couple of statements and it would great if you could help: 1)”If sample error causes the observed difference, the next time someone performs the same experiment the results might be different.” 2)”If the difference does not exist at the population level, you won’t obtain the benefits that you expect based on the sample statistics.”
I discovered your articles by chance and now I keep coming back to read & understand statistical concepts. These articles are very informative & easy to digest. Thanks for the simplifying things.
June 20, 2020 at 9:53 pm
I’m so happy to hear that you’ve found my website to be helpful!
To answer your questions, keep in mind that a central tenant of inferential statistics is that the random sample that a study drew was only one of an infinite number of possible it could’ve drawn. Each random sample produces different results. Most results will cluster around the population value assuming they used good methodology. However, random sampling error always exists and makes it so that population estimates from a sample almost never exactly equal the correct population value.
So, imagine that we’re studying a medication and comparing the treatment and control groups. Suppose that the medicine is truly not effect and that the population difference between the treatment and control group is zero (i.e., no difference.) Despite the true difference being zero, most sample estimates will show some degree of either a positive or negative effect thanks to random sampling error. So, just because a study has an observed difference does not mean that a difference exists at the population level. So, on to your questions:
1. If the observed difference is just random error, then it makes sense that if you collected another random sample, the difference could change. It could change from negative to positive, positive to negative, more extreme, less extreme, etc. However, if the difference exists at the population level, most random samples drawn from the population will reflect that difference. If the medicine has an effect, most random samples will reflect that fact and not bounce around on both sides of zero as much.
2. This is closely related to the previous answer. If there is no difference at the population level, but say you approve the medicine because of the observed effects in a sample. Even though your random sample showed an effect (which was really random error), that effect doesn’t exist. So, when you start using it on a larger scale, people won’t benefit from the medicine. That’s why it’s important to separate out what is easily explained by random error versus what is not easily explained by it.
I think reading my post about how hypothesis tests work will help clarify this process. Also, in about 24 hours (as I write this), I’ll be releasing my new ebook about Hypothesis Testing!

May 29, 2020 at 5:23 am
Hi Jim, I really enjoy your blog. Can you please link me on your blog where you discuss about Subgroup analysis and how it is done? I need to use non parametric and parametric statistical methods for my work and also do subgroup analysis in order to identify potential groups of patients that may benefit more from using a treatment than other groups.
May 29, 2020 at 2:12 pm
Hi, I don’t have a specific article about subgroup analysis. However, subgroup analysis is just the dividing up of a larger sample into subgroups and then analyzing those subgroups separately. You can use the various analyses I write about on the subgroups.
Alternatively, you can include the subgroups in regression analysis as an indicator variable and include that variable as a main effect and an interaction effect to see how the relationships vary by subgroup without needing to subdivide your data. I write about that approach in my article about comparing regression lines . This approach is my preferred approach when possible.

April 19, 2020 at 7:58 am
sir is confidence interval is a part of estimation?

April 17, 2020 at 3:36 pm
Sir can u plz briefly explain alternatives of hypothesis testing? I m unable to find the answer
April 18, 2020 at 1:22 am
Assuming you want to draw conclusions about populations by using samples (i.e., inferential statistics ), you can use confidence intervals and bootstrap methods as alternatives to the traditional hypothesis testing methods.

March 9, 2020 at 10:01 pm
Hi JIm, could you please help with activities that can best teach concepts of hypothesis testing through simulation, Also, do you have any question set that would enhance students intuition why learning hypothesis testing as a topic in introductory statistics. Thanks.

March 5, 2020 at 3:48 pm
Hi Jim, I’m studying multiple hypothesis testing & was wondering if you had any material that would be relevant. I’m more trying to understand how testing multiple samples simultaneously affects your results & more on the Bonferroni Correction
March 5, 2020 at 4:05 pm
I write about multiple comparisons (aka post hoc tests) in the ANOVA context . I don’t talk about Bonferroni Corrections specifically but I cover related types of corrections. I’m not sure if that exactly addresses what you want to know but is probably the closest I have already written. I hope it helps!

January 14, 2020 at 9:03 pm
Thank you! Have a great day/evening.
January 13, 2020 at 7:10 pm
Any help would be greatly appreciated. What is the difference between The Hypothesis Test and The Statistical Test of Hypothesis?
January 14, 2020 at 11:02 am
They sound like the same thing to me. Unless this is specialized terminology for a particular field or the author was intending something specific, I’d guess they’re one and the same.

April 1, 2019 at 10:00 am
so these are the only two forms of Hypothesis used in statistical testing?
April 1, 2019 at 10:02 am
Are you referring to the null and alternative hypothesis? If so, yes, that’s those are the standard hypotheses in a statistical hypothesis test.
April 1, 2019 at 9:57 am
year very insightful post, thanks for the write up

October 27, 2018 at 11:09 pm
hi there, am upcoming statistician, out of all blogs that i have read, i have found this one more useful as long as my problem is concerned. thanks so much
October 27, 2018 at 11:14 pm
Hi Stano, you’re very welcome! Thanks for your kind words. They mean a lot! I’m happy to hear that my posts were able to help you. I’m sure you will be a fantastic statistician. Best of luck with your studies!

October 26, 2018 at 11:39 am
Dear Jim, thank you very much for your explanations! I have a question. Can I use t-test to compare two samples in case each of them have right bias?
October 26, 2018 at 12:00 pm
Hi Tetyana,
You’re very welcome!
The term “right bias” is not a standard term. Do you by chance mean right skewed distributions? In other words, if you plot the distribution for each group on a histogram they have longer right tails? These are not the symmetrical bell-shape curves of the normal distribution.
If that’s the case, yes you can as long as you exceed a specific sample size within each group. I include a table that contains these sample size requirements in my post about nonparametric vs parametric analyses .
Bias in statistics refers to cases where an estimate of a value is systematically higher or lower than the true value. If this is the case, you might be able to use t-tests, but you’d need to be sure to understand the nature of the bias so you would understand what the results are really indicating.
I hope this helps!

April 2, 2018 at 7:28 am
Simple and upto the point 👍 Thank you so much.
April 2, 2018 at 11:11 am
Hi Kalpana, thanks! And I’m glad it was helpful!

March 26, 2018 at 8:41 am
Am I correct if I say: Alpha – Probability of wrongly rejection of null hypothesis P-value – Probability of wrongly acceptance of null hypothesis
March 28, 2018 at 3:14 pm
You’re correct about alpha. Alpha is the probability of rejecting the null hypothesis when the null is true.
Unfortunately, your definition of the p-value is a bit off. The p-value has a fairly convoluted definition. It is the probability of obtaining the effect observed in a sample, or more extreme, if the null hypothesis is true. The p-value does NOT indicate the probability that either the null or alternative is true or false. Although, those are very common misinterpretations. To learn more, read my post about how to interpret p-values correctly .

March 2, 2018 at 6:10 pm
I recently started reading your blog and it is very helpful to understand each concept of statistical tests in easy way with some good examples. Also, I recommend to other people go through all these blogs which you posted. Specially for those people who have not statistical background and they are facing to many problems while studying statistical analysis.
Thank you for your such good blogs.
March 3, 2018 at 10:12 pm
Hi Amit, I’m so glad that my blog posts have been helpful for you! It means a lot to me that you took the time to write such a nice comment! Also, thanks for recommending by blog to others! I try really hard to write posts about statistics that are easy to understand.

January 17, 2018 at 7:03 am
I recently started reading your blog and I find it very interesting. I am learning statistics by my own, and I generally do many google search to understand the concepts. So this blog is quite helpful for me, as it have most of the content which I am looking for.
January 17, 2018 at 3:56 pm
Hi Shashank, thank you! And, I’m very glad to hear that my blog is helpful!

January 2, 2018 at 2:28 pm
thank u very much sir.
January 2, 2018 at 2:36 pm
You’re very welcome, Hiral!

November 21, 2017 at 12:43 pm
Thank u so much sir….your posts always helps me to be a #statistician
November 21, 2017 at 2:40 pm
Hi Sachin, you’re very welcome! I’m happy that you find my posts to be helpful!

November 19, 2017 at 8:22 pm
great post as usual, but it would be nice to see an example.
November 19, 2017 at 8:27 pm
Thank you! At the end of this post, I have links to four other posts that show examples of hypothesis tests in action. You’ll find what you’re looking for in those posts!
Comments and Questions Cancel reply
Tutorial Playlist
Statistics tutorial, everything you need to know about the probability density function in statistics, the best guide to understand central limit theorem, an in-depth guide to measures of central tendency : mean, median and mode, the ultimate guide to understand conditional probability.
A Comprehensive Look at Percentile in Statistics
The Best Guide to Understand Bayes Theorem
Everything you need to know about the normal distribution, an in-depth explanation of cumulative distribution function, a complete guide to chi-square test, what is hypothesis testing in statistics types and examples, understanding the fundamentals of arithmetic and geometric progression, the definitive guide to understand spearman’s rank correlation, mean squared error: overview, examples, concepts and more, all you need to know about the empirical rule in statistics, the complete guide to skewness and kurtosis, a holistic look at bernoulli distribution.
All You Need to Know About Bias in Statistics
A Complete Guide to Get a Grasp of Time Series Analysis
The Key Differences Between Z-Test Vs. T-Test
The Complete Guide to Understand Pearson's Correlation
A complete guide on the types of statistical studies, everything you need to know about poisson distribution, your best guide to understand correlation vs. regression, the most comprehensive guide for beginners on what is correlation, hypothesis testing in statistics - types | examples.
Lesson 10 of 24 By Avijeet Biswal

Table of Contents
In today’s data-driven world, decisions are based on data all the time. Hypothesis plays a crucial role in that process, whether it may be making business decisions, in the health sector, academia, or in quality improvement. Without hypothesis & hypothesis tests, you risk drawing the wrong conclusions and making bad decisions. In this tutorial, you will look at Hypothesis Testing in Statistics.
The Ultimate Ticket to Top Data Science Job Roles
What Is Hypothesis Testing in Statistics?
Hypothesis Testing is a type of statistical analysis in which you put your assumptions about a population parameter to the test. It is used to estimate the relationship between 2 statistical variables.
Let's discuss few examples of statistical hypothesis from real-life -
- A teacher assumes that 60% of his college's students come from lower-middle-class families.
- A doctor believes that 3D (Diet, Dose, and Discipline) is 90% effective for diabetic patients.
Now that you know about hypothesis testing, look at the two types of hypothesis testing in statistics.
Hypothesis Testing Formula
Z = ( x̅ – μ0 ) / (σ /√n)
- Here, x̅ is the sample mean,
- μ0 is the population mean,
- σ is the standard deviation,
- n is the sample size.
How Hypothesis Testing Works?
An analyst performs hypothesis testing on a statistical sample to present evidence of the plausibility of the null hypothesis. Measurements and analyses are conducted on a random sample of the population to test a theory. Analysts use a random population sample to test two hypotheses: the null and alternative hypotheses.
The null hypothesis is typically an equality hypothesis between population parameters; for example, a null hypothesis may claim that the population means return equals zero. The alternate hypothesis is essentially the inverse of the null hypothesis (e.g., the population means the return is not equal to zero). As a result, they are mutually exclusive, and only one can be correct. One of the two possibilities, however, will always be correct.
Your Dream Career is Just Around The Corner!
Null Hypothesis and Alternative Hypothesis
The Null Hypothesis is the assumption that the event will not occur. A null hypothesis has no bearing on the study's outcome unless it is rejected.
H0 is the symbol for it, and it is pronounced H-naught.
The Alternate Hypothesis is the logical opposite of the null hypothesis. The acceptance of the alternative hypothesis follows the rejection of the null hypothesis. H1 is the symbol for it.
Let's understand this with an example.
A sanitizer manufacturer claims that its product kills 95 percent of germs on average.
To put this company's claim to the test, create a null and alternate hypothesis.
H0 (Null Hypothesis): Average = 95%.
Alternative Hypothesis (H1): The average is less than 95%.
Another straightforward example to understand this concept is determining whether or not a coin is fair and balanced. The null hypothesis states that the probability of a show of heads is equal to the likelihood of a show of tails. In contrast, the alternate theory states that the probability of a show of heads and tails would be very different.
Become a Data Scientist with Hands-on Training!
Hypothesis Testing Calculation With Examples
Let's consider a hypothesis test for the average height of women in the United States. Suppose our null hypothesis is that the average height is 5'4". We gather a sample of 100 women and determine that their average height is 5'5". The standard deviation of population is 2.
To calculate the z-score, we would use the following formula:
z = ( x̅ – μ0 ) / (σ /√n)
z = (5'5" - 5'4") / (2" / √100)
z = 0.5 / (0.045)
We will reject the null hypothesis as the z-score of 11.11 is very large and conclude that there is evidence to suggest that the average height of women in the US is greater than 5'4".
Steps in Hypothesis Testing
Hypothesis testing is a statistical method to determine if there is enough evidence in a sample of data to infer that a certain condition is true for the entire population. Here’s a breakdown of the typical steps involved in hypothesis testing:
Formulate Hypotheses
- Null Hypothesis (H0): This hypothesis states that there is no effect or difference, and it is the hypothesis you attempt to reject with your test.
- Alternative Hypothesis (H1 or Ha): This hypothesis is what you might believe to be true or hope to prove true. It is usually considered the opposite of the null hypothesis.
Choose the Significance Level (α)
The significance level, often denoted by alpha (α), is the probability of rejecting the null hypothesis when it is true. Common choices for α are 0.05 (5%), 0.01 (1%), and 0.10 (10%).
Select the Appropriate Test
Choose a statistical test based on the type of data and the hypothesis. Common tests include t-tests, chi-square tests, ANOVA, and regression analysis. The selection depends on data type, distribution, sample size, and whether the hypothesis is one-tailed or two-tailed.
Collect Data
Gather the data that will be analyzed in the test. This data should be representative of the population to infer conclusions accurately.
Calculate the Test Statistic
Based on the collected data and the chosen test, calculate a test statistic that reflects how much the observed data deviates from the null hypothesis.
Determine the p-value
The p-value is the probability of observing test results at least as extreme as the results observed, assuming the null hypothesis is correct. It helps determine the strength of the evidence against the null hypothesis.
Make a Decision
Compare the p-value to the chosen significance level:
- If the p-value ≤ α: Reject the null hypothesis, suggesting sufficient evidence in the data supports the alternative hypothesis.
- If the p-value > α: Do not reject the null hypothesis, suggesting insufficient evidence to support the alternative hypothesis.
Report the Results
Present the findings from the hypothesis test, including the test statistic, p-value, and the conclusion about the hypotheses.
Perform Post-hoc Analysis (if necessary)
Depending on the results and the study design, further analysis may be needed to explore the data more deeply or to address multiple comparisons if several hypotheses were tested simultaneously.
Types of Hypothesis Testing
To determine whether a discovery or relationship is statistically significant, hypothesis testing uses a z-test. It usually checks to see if two means are the same (the null hypothesis). Only when the population standard deviation is known and the sample size is 30 data points or more, can a z-test be applied.
A statistical test called a t-test is employed to compare the means of two groups. To determine whether two groups differ or if a procedure or treatment affects the population of interest, it is frequently used in hypothesis testing.
Chi-Square
You utilize a Chi-square test for hypothesis testing concerning whether your data is as predicted. To determine if the expected and observed results are well-fitted, the Chi-square test analyzes the differences between categorical variables from a random sample. The test's fundamental premise is that the observed values in your data should be compared to the predicted values that would be present if the null hypothesis were true.
Hypothesis Testing and Confidence Intervals
Both confidence intervals and hypothesis tests are inferential techniques that depend on approximating the sample distribution. Data from a sample is used to estimate a population parameter using confidence intervals. Data from a sample is used in hypothesis testing to examine a given hypothesis. We must have a postulated parameter to conduct hypothesis testing.
Bootstrap distributions and randomization distributions are created using comparable simulation techniques. The observed sample statistic is the focal point of a bootstrap distribution, whereas the null hypothesis value is the focal point of a randomization distribution.
A variety of feasible population parameter estimates are included in confidence ranges. In this lesson, we created just two-tailed confidence intervals. There is a direct connection between these two-tail confidence intervals and these two-tail hypothesis tests. The results of a two-tailed hypothesis test and two-tailed confidence intervals typically provide the same results. In other words, a hypothesis test at the 0.05 level will virtually always fail to reject the null hypothesis if the 95% confidence interval contains the predicted value. A hypothesis test at the 0.05 level will nearly certainly reject the null hypothesis if the 95% confidence interval does not include the hypothesized parameter.
Become a Data Scientist through hands-on learning with hackathons, masterclasses, webinars, and Ask-Me-Anything! Start learning now!
Simple and Composite Hypothesis Testing
Depending on the population distribution, you can classify the statistical hypothesis into two types.
Simple Hypothesis: A simple hypothesis specifies an exact value for the parameter.
Composite Hypothesis: A composite hypothesis specifies a range of values.
A company is claiming that their average sales for this quarter are 1000 units. This is an example of a simple hypothesis.
Suppose the company claims that the sales are in the range of 900 to 1000 units. Then this is a case of a composite hypothesis.
One-Tailed and Two-Tailed Hypothesis Testing
The One-Tailed test, also called a directional test, considers a critical region of data that would result in the null hypothesis being rejected if the test sample falls into it, inevitably meaning the acceptance of the alternate hypothesis.
In a one-tailed test, the critical distribution area is one-sided, meaning the test sample is either greater or lesser than a specific value.
In two tails, the test sample is checked to be greater or less than a range of values in a Two-Tailed test, implying that the critical distribution area is two-sided.
If the sample falls within this range, the alternate hypothesis will be accepted, and the null hypothesis will be rejected.
Become a Data Scientist With Real-World Experience
Right Tailed Hypothesis Testing
If the larger than (>) sign appears in your hypothesis statement, you are using a right-tailed test, also known as an upper test. Or, to put it another way, the disparity is to the right. For instance, you can contrast the battery life before and after a change in production. Your hypothesis statements can be the following if you want to know if the battery life is longer than the original (let's say 90 hours):
- The null hypothesis is (H0 <= 90) or less change.
- A possibility is that battery life has risen (H1) > 90.
The crucial point in this situation is that the alternate hypothesis (H1), not the null hypothesis, decides whether you get a right-tailed test.
Left Tailed Hypothesis Testing
Alternative hypotheses that assert the true value of a parameter is lower than the null hypothesis are tested with a left-tailed test; they are indicated by the asterisk "<".
Suppose H0: mean = 50 and H1: mean not equal to 50
According to the H1, the mean can be greater than or less than 50. This is an example of a Two-tailed test.
In a similar manner, if H0: mean >=50, then H1: mean <50
Here the mean is less than 50. It is called a One-tailed test.
Type 1 and Type 2 Error
A hypothesis test can result in two types of errors.
Type 1 Error: A Type-I error occurs when sample results reject the null hypothesis despite being true.
Type 2 Error: A Type-II error occurs when the null hypothesis is not rejected when it is false, unlike a Type-I error.
Suppose a teacher evaluates the examination paper to decide whether a student passes or fails.
H0: Student has passed
H1: Student has failed
Type I error will be the teacher failing the student [rejects H0] although the student scored the passing marks [H0 was true].
Type II error will be the case where the teacher passes the student [do not reject H0] although the student did not score the passing marks [H1 is true].
Our Data Scientist Master's Program covers core topics such as R, Python, Machine Learning, Tableau, Hadoop, and Spark. Get started on your journey today!
Limitations of Hypothesis Testing
Hypothesis testing has some limitations that researchers should be aware of:
- It cannot prove or establish the truth: Hypothesis testing provides evidence to support or reject a hypothesis, but it cannot confirm the absolute truth of the research question.
- Results are sample-specific: Hypothesis testing is based on analyzing a sample from a population, and the conclusions drawn are specific to that particular sample.
- Possible errors: During hypothesis testing, there is a chance of committing type I error (rejecting a true null hypothesis) or type II error (failing to reject a false null hypothesis).
- Assumptions and requirements: Different tests have specific assumptions and requirements that must be met to accurately interpret results.
Learn All The Tricks Of The BI Trade
After reading this tutorial, you would have a much better understanding of hypothesis testing, one of the most important concepts in the field of Data Science . The majority of hypotheses are based on speculation about observed behavior, natural phenomena, or established theories.
If you are interested in statistics of data science and skills needed for such a career, you ought to explore the Post Graduate Program in Data Science.
If you have any questions regarding this ‘Hypothesis Testing In Statistics’ tutorial, do share them in the comment section. Our subject matter expert will respond to your queries. Happy learning!
1. What is hypothesis testing in statistics with example?
Hypothesis testing is a statistical method used to determine if there is enough evidence in a sample data to draw conclusions about a population. It involves formulating two competing hypotheses, the null hypothesis (H0) and the alternative hypothesis (Ha), and then collecting data to assess the evidence. An example: testing if a new drug improves patient recovery (Ha) compared to the standard treatment (H0) based on collected patient data.
2. What is H0 and H1 in statistics?
In statistics, H0 and H1 represent the null and alternative hypotheses. The null hypothesis, H0, is the default assumption that no effect or difference exists between groups or conditions. The alternative hypothesis, H1, is the competing claim suggesting an effect or a difference. Statistical tests determine whether to reject the null hypothesis in favor of the alternative hypothesis based on the data.
3. What is a simple hypothesis with an example?
A simple hypothesis is a specific statement predicting a single relationship between two variables. It posits a direct and uncomplicated outcome. For example, a simple hypothesis might state, "Increased sunlight exposure increases the growth rate of sunflowers." Here, the hypothesis suggests a direct relationship between the amount of sunlight (independent variable) and the growth rate of sunflowers (dependent variable), with no additional variables considered.
4. What are the 3 major types of hypothesis?
The three major types of hypotheses are:
- Null Hypothesis (H0): Represents the default assumption, stating that there is no significant effect or relationship in the data.
- Alternative Hypothesis (Ha): Contradicts the null hypothesis and proposes a specific effect or relationship that researchers want to investigate.
- Nondirectional Hypothesis: An alternative hypothesis that doesn't specify the direction of the effect, leaving it open for both positive and negative possibilities.
Find our PL-300 Microsoft Power BI Certification Training Online Classroom training classes in top cities:
| Name | Date | Place | |
|---|---|---|---|
| 7 Sep -22 Sep 2024, Weekend batch | Your City | ||
| 21 Sep -6 Oct 2024, Weekend batch | Your City | ||
| 12 Oct -27 Oct 2024, Weekend batch | Your City |
About the Author
Avijeet is a Senior Research Analyst at Simplilearn. Passionate about Data Analytics, Machine Learning, and Deep Learning, Avijeet is also interested in politics, cricket, and football.
Recommended Resources
Free eBook: Top Programming Languages For A Data Scientist
Normality Test in Minitab: Minitab with Statistics
Machine Learning Career Guide: A Playbook to Becoming a Machine Learning Engineer
- PMP, PMI, PMBOK, CAPM, PgMP, PfMP, ACP, PBA, RMP, SP, and OPM3 are registered marks of the Project Management Institute, Inc.
- > Machine Learning
- > Statistics
What is Hypothesis Testing? Types and Methods
- Soumyaa Rawat
- Jul 23, 2021

Hypothesis Testing
Hypothesis testing is the act of testing a hypothesis or a supposition in relation to a statistical parameter. Analysts implement hypothesis testing in order to test if a hypothesis is plausible or not.
In data science and statistics , hypothesis testing is an important step as it involves the verification of an assumption that could help develop a statistical parameter. For instance, a researcher establishes a hypothesis assuming that the average of all odd numbers is an even number.
In order to find the plausibility of this hypothesis, the researcher will have to test the hypothesis using hypothesis testing methods. Unlike a hypothesis that is ‘supposed’ to stand true on the basis of little or no evidence, hypothesis testing is required to have plausible evidence in order to establish that a statistical hypothesis is true.
Perhaps this is where statistics play an important role. A number of components are involved in this process. But before understanding the process involved in hypothesis testing in research methodology, we shall first understand the types of hypotheses that are involved in the process. Let us get started!
Types of Hypotheses
In data sampling, different types of hypothesis are involved in finding whether the tested samples test positive for a hypothesis or not. In this segment, we shall discover the different types of hypotheses and understand the role they play in hypothesis testing.
Alternative Hypothesis
Alternative Hypothesis (H1) or the research hypothesis states that there is a relationship between two variables (where one variable affects the other). The alternative hypothesis is the main driving force for hypothesis testing.
It implies that the two variables are related to each other and the relationship that exists between them is not due to chance or coincidence.
When the process of hypothesis testing is carried out, the alternative hypothesis is the main subject of the testing process. The analyst intends to test the alternative hypothesis and verifies its plausibility.
Null Hypothesis
The Null Hypothesis (H0) aims to nullify the alternative hypothesis by implying that there exists no relation between two variables in statistics. It states that the effect of one variable on the other is solely due to chance and no empirical cause lies behind it.
The null hypothesis is established alongside the alternative hypothesis and is recognized as important as the latter. In hypothesis testing, the null hypothesis has a major role to play as it influences the testing against the alternative hypothesis.
(Must read: What is ANOVA test? )
Non-Directional Hypothesis
The Non-directional hypothesis states that the relation between two variables has no direction.
Simply put, it asserts that there exists a relation between two variables, but does not recognize the direction of effect, whether variable A affects variable B or vice versa.
Directional Hypothesis
The Directional hypothesis, on the other hand, asserts the direction of effect of the relationship that exists between two variables.
Herein, the hypothesis clearly states that variable A affects variable B, or vice versa.
Statistical Hypothesis
A statistical hypothesis is a hypothesis that can be verified to be plausible on the basis of statistics.
By using data sampling and statistical knowledge, one can determine the plausibility of a statistical hypothesis and find out if it stands true or not.
(Related blog: z-test vs t-test )
Performing Hypothesis Testing
Now that we have understood the types of hypotheses and the role they play in hypothesis testing, let us now move on to understand the process in a better manner.
In hypothesis testing, a researcher is first required to establish two hypotheses - alternative hypothesis and null hypothesis in order to begin with the procedure.
To establish these two hypotheses, one is required to study data samples, find a plausible pattern among the samples, and pen down a statistical hypothesis that they wish to test.
A random population of samples can be drawn, to begin with hypothesis testing. Among the two hypotheses, alternative and null, only one can be verified to be true. Perhaps the presence of both hypotheses is required to make the process successful.
At the end of the hypothesis testing procedure, either of the hypotheses will be rejected and the other one will be supported. Even though one of the two hypotheses turns out to be true, no hypothesis can ever be verified 100%.
(Read also: Types of data sampling techniques )
Therefore, a hypothesis can only be supported based on the statistical samples and verified data. Here is a step-by-step guide for hypothesis testing.
Establish the hypotheses
First things first, one is required to establish two hypotheses - alternative and null, that will set the foundation for hypothesis testing.
These hypotheses initiate the testing process that involves the researcher working on data samples in order to either support the alternative hypothesis or the null hypothesis.
Generate a testing plan
Once the hypotheses have been formulated, it is now time to generate a testing plan. A testing plan or an analysis plan involves the accumulation of data samples, determining which statistic is to be considered and laying out the sample size.
All these factors are very important while one is working on hypothesis testing.
Analyze data samples
As soon as a testing plan is ready, it is time to move on to the analysis part. Analysis of data samples involves configuring statistical values of samples, drawing them together, and deriving a pattern out of these samples.
While analyzing the data samples, a researcher needs to determine a set of things -
Significance Level - The level of significance in hypothesis testing indicates if a statistical result could have significance if the null hypothesis stands to be true.
Testing Method - The testing method involves a type of sampling-distribution and a test statistic that leads to hypothesis testing. There are a number of testing methods that can assist in the analysis of data samples.
Test statistic - Test statistic is a numerical summary of a data set that can be used to perform hypothesis testing.
P-value - The P-value interpretation is the probability of finding a sample statistic to be as extreme as the test statistic, indicating the plausibility of the null hypothesis.
Infer the results
The analysis of data samples leads to the inference of results that establishes whether the alternative hypothesis stands true or not. When the P-value is less than the significance level, the null hypothesis is rejected and the alternative hypothesis turns out to be plausible.
Methods of Hypothesis Testing
As we have already looked into different aspects of hypothesis testing, we shall now look into the different methods of hypothesis testing. All in all, there are 2 most common types of hypothesis testing methods. They are as follows -
Frequentist Hypothesis Testing
The frequentist hypothesis or the traditional approach to hypothesis testing is a hypothesis testing method that aims on making assumptions by considering current data.
The supposed truths and assumptions are based on the current data and a set of 2 hypotheses are formulated. A very popular subtype of the frequentist approach is the Null Hypothesis Significance Testing (NHST).
The NHST approach (involving the null and alternative hypothesis) has been one of the most sought-after methods of hypothesis testing in the field of statistics ever since its inception in the mid-1950s.
Bayesian Hypothesis Testing
A much unconventional and modern method of hypothesis testing, the Bayesian Hypothesis Testing claims to test a particular hypothesis in accordance with the past data samples, known as prior probability, and current data that lead to the plausibility of a hypothesis.
The result obtained indicates the posterior probability of the hypothesis. In this method, the researcher relies on ‘prior probability and posterior probability’ to conduct hypothesis testing on hand.
On the basis of this prior probability, the Bayesian approach tests a hypothesis to be true or false. The Bayes factor, a major component of this method, indicates the likelihood ratio among the null hypothesis and the alternative hypothesis.
The Bayes factor is the indicator of the plausibility of either of the two hypotheses that are established for hypothesis testing.
(Also read - Introduction to Bayesian Statistics )
To conclude, hypothesis testing, a way to verify the plausibility of a supposed assumption can be done through different methods - the Bayesian approach or the Frequentist approach.
Although the Bayesian approach relies on the prior probability of data samples, the frequentist approach assumes without a probability. A number of elements involved in hypothesis testing are - significance level, p-level, test statistic, and method of hypothesis testing.
(Also read: Introduction to probability distributions )
A significant way to determine whether a hypothesis stands true or not is to verify the data samples and identify the plausible hypothesis among the null hypothesis and alternative hypothesis.
Share Blog :
Be a part of our Instagram community
Trending blogs
5 Factors Influencing Consumer Behavior
Elasticity of Demand and its Types
An Overview of Descriptive Analysis
What is PESTLE Analysis? Everything you need to know about it
What is Managerial Economics? Definition, Types, Nature, Principles, and Scope
5 Factors Affecting the Price Elasticity of Demand (PED)
6 Major Branches of Artificial Intelligence (AI)
Scope of Managerial Economics
Dijkstra’s Algorithm: The Shortest Path Algorithm
Different Types of Research Methods
Latest Comments

An official website of the United States government
The .gov means it’s official. Federal government websites often end in .gov or .mil. Before sharing sensitive information, make sure you’re on a federal government site.
The site is secure. The https:// ensures that you are connecting to the official website and that any information you provide is encrypted and transmitted securely.
- Publications
- Account settings
Preview improvements coming to the PMC website in October 2024. Learn More or Try it out now .
- Advanced Search
- Journal List
- J Korean Med Sci
- v.37(16); 2022 Apr 25
A Practical Guide to Writing Quantitative and Qualitative Research Questions and Hypotheses in Scholarly Articles
Edward barroga.
1 Department of General Education, Graduate School of Nursing Science, St. Luke’s International University, Tokyo, Japan.
Glafera Janet Matanguihan
2 Department of Biological Sciences, Messiah University, Mechanicsburg, PA, USA.
The development of research questions and the subsequent hypotheses are prerequisites to defining the main research purpose and specific objectives of a study. Consequently, these objectives determine the study design and research outcome. The development of research questions is a process based on knowledge of current trends, cutting-edge studies, and technological advances in the research field. Excellent research questions are focused and require a comprehensive literature search and in-depth understanding of the problem being investigated. Initially, research questions may be written as descriptive questions which could be developed into inferential questions. These questions must be specific and concise to provide a clear foundation for developing hypotheses. Hypotheses are more formal predictions about the research outcomes. These specify the possible results that may or may not be expected regarding the relationship between groups. Thus, research questions and hypotheses clarify the main purpose and specific objectives of the study, which in turn dictate the design of the study, its direction, and outcome. Studies developed from good research questions and hypotheses will have trustworthy outcomes with wide-ranging social and health implications.
INTRODUCTION
Scientific research is usually initiated by posing evidenced-based research questions which are then explicitly restated as hypotheses. 1 , 2 The hypotheses provide directions to guide the study, solutions, explanations, and expected results. 3 , 4 Both research questions and hypotheses are essentially formulated based on conventional theories and real-world processes, which allow the inception of novel studies and the ethical testing of ideas. 5 , 6
It is crucial to have knowledge of both quantitative and qualitative research 2 as both types of research involve writing research questions and hypotheses. 7 However, these crucial elements of research are sometimes overlooked; if not overlooked, then framed without the forethought and meticulous attention it needs. Planning and careful consideration are needed when developing quantitative or qualitative research, particularly when conceptualizing research questions and hypotheses. 4
There is a continuing need to support researchers in the creation of innovative research questions and hypotheses, as well as for journal articles that carefully review these elements. 1 When research questions and hypotheses are not carefully thought of, unethical studies and poor outcomes usually ensue. Carefully formulated research questions and hypotheses define well-founded objectives, which in turn determine the appropriate design, course, and outcome of the study. This article then aims to discuss in detail the various aspects of crafting research questions and hypotheses, with the goal of guiding researchers as they develop their own. Examples from the authors and peer-reviewed scientific articles in the healthcare field are provided to illustrate key points.
DEFINITIONS AND RELATIONSHIP OF RESEARCH QUESTIONS AND HYPOTHESES
A research question is what a study aims to answer after data analysis and interpretation. The answer is written in length in the discussion section of the paper. Thus, the research question gives a preview of the different parts and variables of the study meant to address the problem posed in the research question. 1 An excellent research question clarifies the research writing while facilitating understanding of the research topic, objective, scope, and limitations of the study. 5
On the other hand, a research hypothesis is an educated statement of an expected outcome. This statement is based on background research and current knowledge. 8 , 9 The research hypothesis makes a specific prediction about a new phenomenon 10 or a formal statement on the expected relationship between an independent variable and a dependent variable. 3 , 11 It provides a tentative answer to the research question to be tested or explored. 4
Hypotheses employ reasoning to predict a theory-based outcome. 10 These can also be developed from theories by focusing on components of theories that have not yet been observed. 10 The validity of hypotheses is often based on the testability of the prediction made in a reproducible experiment. 8
Conversely, hypotheses can also be rephrased as research questions. Several hypotheses based on existing theories and knowledge may be needed to answer a research question. Developing ethical research questions and hypotheses creates a research design that has logical relationships among variables. These relationships serve as a solid foundation for the conduct of the study. 4 , 11 Haphazardly constructed research questions can result in poorly formulated hypotheses and improper study designs, leading to unreliable results. Thus, the formulations of relevant research questions and verifiable hypotheses are crucial when beginning research. 12
CHARACTERISTICS OF GOOD RESEARCH QUESTIONS AND HYPOTHESES
Excellent research questions are specific and focused. These integrate collective data and observations to confirm or refute the subsequent hypotheses. Well-constructed hypotheses are based on previous reports and verify the research context. These are realistic, in-depth, sufficiently complex, and reproducible. More importantly, these hypotheses can be addressed and tested. 13
There are several characteristics of well-developed hypotheses. Good hypotheses are 1) empirically testable 7 , 10 , 11 , 13 ; 2) backed by preliminary evidence 9 ; 3) testable by ethical research 7 , 9 ; 4) based on original ideas 9 ; 5) have evidenced-based logical reasoning 10 ; and 6) can be predicted. 11 Good hypotheses can infer ethical and positive implications, indicating the presence of a relationship or effect relevant to the research theme. 7 , 11 These are initially developed from a general theory and branch into specific hypotheses by deductive reasoning. In the absence of a theory to base the hypotheses, inductive reasoning based on specific observations or findings form more general hypotheses. 10
TYPES OF RESEARCH QUESTIONS AND HYPOTHESES
Research questions and hypotheses are developed according to the type of research, which can be broadly classified into quantitative and qualitative research. We provide a summary of the types of research questions and hypotheses under quantitative and qualitative research categories in Table 1 .
| Quantitative research questions | Quantitative research hypotheses |
|---|---|
| Descriptive research questions | Simple hypothesis |
| Comparative research questions | Complex hypothesis |
| Relationship research questions | Directional hypothesis |
| Non-directional hypothesis | |
| Associative hypothesis | |
| Causal hypothesis | |
| Null hypothesis | |
| Alternative hypothesis | |
| Working hypothesis | |
| Statistical hypothesis | |
| Logical hypothesis | |
| Hypothesis-testing | |
| Qualitative research questions | Qualitative research hypotheses |
| Contextual research questions | Hypothesis-generating |
| Descriptive research questions | |
| Evaluation research questions | |
| Explanatory research questions | |
| Exploratory research questions | |
| Generative research questions | |
| Ideological research questions | |
| Ethnographic research questions | |
| Phenomenological research questions | |
| Grounded theory questions | |
| Qualitative case study questions |
Research questions in quantitative research
In quantitative research, research questions inquire about the relationships among variables being investigated and are usually framed at the start of the study. These are precise and typically linked to the subject population, dependent and independent variables, and research design. 1 Research questions may also attempt to describe the behavior of a population in relation to one or more variables, or describe the characteristics of variables to be measured ( descriptive research questions ). 1 , 5 , 14 These questions may also aim to discover differences between groups within the context of an outcome variable ( comparative research questions ), 1 , 5 , 14 or elucidate trends and interactions among variables ( relationship research questions ). 1 , 5 We provide examples of descriptive, comparative, and relationship research questions in quantitative research in Table 2 .
| Quantitative research questions | |
|---|---|
| Descriptive research question | |
| - Measures responses of subjects to variables | |
| - Presents variables to measure, analyze, or assess | |
| What is the proportion of resident doctors in the hospital who have mastered ultrasonography (response of subjects to a variable) as a diagnostic technique in their clinical training? | |
| Comparative research question | |
| - Clarifies difference between one group with outcome variable and another group without outcome variable | |
| Is there a difference in the reduction of lung metastasis in osteosarcoma patients who received the vitamin D adjunctive therapy (group with outcome variable) compared with osteosarcoma patients who did not receive the vitamin D adjunctive therapy (group without outcome variable)? | |
| - Compares the effects of variables | |
| How does the vitamin D analogue 22-Oxacalcitriol (variable 1) mimic the antiproliferative activity of 1,25-Dihydroxyvitamin D (variable 2) in osteosarcoma cells? | |
| Relationship research question | |
| - Defines trends, association, relationships, or interactions between dependent variable and independent variable | |
| Is there a relationship between the number of medical student suicide (dependent variable) and the level of medical student stress (independent variable) in Japan during the first wave of the COVID-19 pandemic? | |
Hypotheses in quantitative research
In quantitative research, hypotheses predict the expected relationships among variables. 15 Relationships among variables that can be predicted include 1) between a single dependent variable and a single independent variable ( simple hypothesis ) or 2) between two or more independent and dependent variables ( complex hypothesis ). 4 , 11 Hypotheses may also specify the expected direction to be followed and imply an intellectual commitment to a particular outcome ( directional hypothesis ) 4 . On the other hand, hypotheses may not predict the exact direction and are used in the absence of a theory, or when findings contradict previous studies ( non-directional hypothesis ). 4 In addition, hypotheses can 1) define interdependency between variables ( associative hypothesis ), 4 2) propose an effect on the dependent variable from manipulation of the independent variable ( causal hypothesis ), 4 3) state a negative relationship between two variables ( null hypothesis ), 4 , 11 , 15 4) replace the working hypothesis if rejected ( alternative hypothesis ), 15 explain the relationship of phenomena to possibly generate a theory ( working hypothesis ), 11 5) involve quantifiable variables that can be tested statistically ( statistical hypothesis ), 11 6) or express a relationship whose interlinks can be verified logically ( logical hypothesis ). 11 We provide examples of simple, complex, directional, non-directional, associative, causal, null, alternative, working, statistical, and logical hypotheses in quantitative research, as well as the definition of quantitative hypothesis-testing research in Table 3 .
| Quantitative research hypotheses | |
|---|---|
| Simple hypothesis | |
| - Predicts relationship between single dependent variable and single independent variable | |
| If the dose of the new medication (single independent variable) is high, blood pressure (single dependent variable) is lowered. | |
| Complex hypothesis | |
| - Foretells relationship between two or more independent and dependent variables | |
| The higher the use of anticancer drugs, radiation therapy, and adjunctive agents (3 independent variables), the higher would be the survival rate (1 dependent variable). | |
| Directional hypothesis | |
| - Identifies study direction based on theory towards particular outcome to clarify relationship between variables | |
| Privately funded research projects will have a larger international scope (study direction) than publicly funded research projects. | |
| Non-directional hypothesis | |
| - Nature of relationship between two variables or exact study direction is not identified | |
| - Does not involve a theory | |
| Women and men are different in terms of helpfulness. (Exact study direction is not identified) | |
| Associative hypothesis | |
| - Describes variable interdependency | |
| - Change in one variable causes change in another variable | |
| A larger number of people vaccinated against COVID-19 in the region (change in independent variable) will reduce the region’s incidence of COVID-19 infection (change in dependent variable). | |
| Causal hypothesis | |
| - An effect on dependent variable is predicted from manipulation of independent variable | |
| A change into a high-fiber diet (independent variable) will reduce the blood sugar level (dependent variable) of the patient. | |
| Null hypothesis | |
| - A negative statement indicating no relationship or difference between 2 variables | |
| There is no significant difference in the severity of pulmonary metastases between the new drug (variable 1) and the current drug (variable 2). | |
| Alternative hypothesis | |
| - Following a null hypothesis, an alternative hypothesis predicts a relationship between 2 study variables | |
| The new drug (variable 1) is better on average in reducing the level of pain from pulmonary metastasis than the current drug (variable 2). | |
| Working hypothesis | |
| - A hypothesis that is initially accepted for further research to produce a feasible theory | |
| Dairy cows fed with concentrates of different formulations will produce different amounts of milk. | |
| Statistical hypothesis | |
| - Assumption about the value of population parameter or relationship among several population characteristics | |
| - Validity tested by a statistical experiment or analysis | |
| The mean recovery rate from COVID-19 infection (value of population parameter) is not significantly different between population 1 and population 2. | |
| There is a positive correlation between the level of stress at the workplace and the number of suicides (population characteristics) among working people in Japan. | |
| Logical hypothesis | |
| - Offers or proposes an explanation with limited or no extensive evidence | |
| If healthcare workers provide more educational programs about contraception methods, the number of adolescent pregnancies will be less. | |
| Hypothesis-testing (Quantitative hypothesis-testing research) | |
| - Quantitative research uses deductive reasoning. | |
| - This involves the formation of a hypothesis, collection of data in the investigation of the problem, analysis and use of the data from the investigation, and drawing of conclusions to validate or nullify the hypotheses. | |
Research questions in qualitative research
Unlike research questions in quantitative research, research questions in qualitative research are usually continuously reviewed and reformulated. The central question and associated subquestions are stated more than the hypotheses. 15 The central question broadly explores a complex set of factors surrounding the central phenomenon, aiming to present the varied perspectives of participants. 15
There are varied goals for which qualitative research questions are developed. These questions can function in several ways, such as to 1) identify and describe existing conditions ( contextual research question s); 2) describe a phenomenon ( descriptive research questions ); 3) assess the effectiveness of existing methods, protocols, theories, or procedures ( evaluation research questions ); 4) examine a phenomenon or analyze the reasons or relationships between subjects or phenomena ( explanatory research questions ); or 5) focus on unknown aspects of a particular topic ( exploratory research questions ). 5 In addition, some qualitative research questions provide new ideas for the development of theories and actions ( generative research questions ) or advance specific ideologies of a position ( ideological research questions ). 1 Other qualitative research questions may build on a body of existing literature and become working guidelines ( ethnographic research questions ). Research questions may also be broadly stated without specific reference to the existing literature or a typology of questions ( phenomenological research questions ), may be directed towards generating a theory of some process ( grounded theory questions ), or may address a description of the case and the emerging themes ( qualitative case study questions ). 15 We provide examples of contextual, descriptive, evaluation, explanatory, exploratory, generative, ideological, ethnographic, phenomenological, grounded theory, and qualitative case study research questions in qualitative research in Table 4 , and the definition of qualitative hypothesis-generating research in Table 5 .
| Qualitative research questions | |
|---|---|
| Contextual research question | |
| - Ask the nature of what already exists | |
| - Individuals or groups function to further clarify and understand the natural context of real-world problems | |
| What are the experiences of nurses working night shifts in healthcare during the COVID-19 pandemic? (natural context of real-world problems) | |
| Descriptive research question | |
| - Aims to describe a phenomenon | |
| What are the different forms of disrespect and abuse (phenomenon) experienced by Tanzanian women when giving birth in healthcare facilities? | |
| Evaluation research question | |
| - Examines the effectiveness of existing practice or accepted frameworks | |
| How effective are decision aids (effectiveness of existing practice) in helping decide whether to give birth at home or in a healthcare facility? | |
| Explanatory research question | |
| - Clarifies a previously studied phenomenon and explains why it occurs | |
| Why is there an increase in teenage pregnancy (phenomenon) in Tanzania? | |
| Exploratory research question | |
| - Explores areas that have not been fully investigated to have a deeper understanding of the research problem | |
| What factors affect the mental health of medical students (areas that have not yet been fully investigated) during the COVID-19 pandemic? | |
| Generative research question | |
| - Develops an in-depth understanding of people’s behavior by asking ‘how would’ or ‘what if’ to identify problems and find solutions | |
| How would the extensive research experience of the behavior of new staff impact the success of the novel drug initiative? | |
| Ideological research question | |
| - Aims to advance specific ideas or ideologies of a position | |
| Are Japanese nurses who volunteer in remote African hospitals able to promote humanized care of patients (specific ideas or ideologies) in the areas of safe patient environment, respect of patient privacy, and provision of accurate information related to health and care? | |
| Ethnographic research question | |
| - Clarifies peoples’ nature, activities, their interactions, and the outcomes of their actions in specific settings | |
| What are the demographic characteristics, rehabilitative treatments, community interactions, and disease outcomes (nature, activities, their interactions, and the outcomes) of people in China who are suffering from pneumoconiosis? | |
| Phenomenological research question | |
| - Knows more about the phenomena that have impacted an individual | |
| What are the lived experiences of parents who have been living with and caring for children with a diagnosis of autism? (phenomena that have impacted an individual) | |
| Grounded theory question | |
| - Focuses on social processes asking about what happens and how people interact, or uncovering social relationships and behaviors of groups | |
| What are the problems that pregnant adolescents face in terms of social and cultural norms (social processes), and how can these be addressed? | |
| Qualitative case study question | |
| - Assesses a phenomenon using different sources of data to answer “why” and “how” questions | |
| - Considers how the phenomenon is influenced by its contextual situation. | |
| How does quitting work and assuming the role of a full-time mother (phenomenon assessed) change the lives of women in Japan? | |
| Qualitative research hypotheses | |
|---|---|
| Hypothesis-generating (Qualitative hypothesis-generating research) | |
| - Qualitative research uses inductive reasoning. | |
| - This involves data collection from study participants or the literature regarding a phenomenon of interest, using the collected data to develop a formal hypothesis, and using the formal hypothesis as a framework for testing the hypothesis. | |
| - Qualitative exploratory studies explore areas deeper, clarifying subjective experience and allowing formulation of a formal hypothesis potentially testable in a future quantitative approach. | |
Qualitative studies usually pose at least one central research question and several subquestions starting with How or What . These research questions use exploratory verbs such as explore or describe . These also focus on one central phenomenon of interest, and may mention the participants and research site. 15
Hypotheses in qualitative research
Hypotheses in qualitative research are stated in the form of a clear statement concerning the problem to be investigated. Unlike in quantitative research where hypotheses are usually developed to be tested, qualitative research can lead to both hypothesis-testing and hypothesis-generating outcomes. 2 When studies require both quantitative and qualitative research questions, this suggests an integrative process between both research methods wherein a single mixed-methods research question can be developed. 1
FRAMEWORKS FOR DEVELOPING RESEARCH QUESTIONS AND HYPOTHESES
Research questions followed by hypotheses should be developed before the start of the study. 1 , 12 , 14 It is crucial to develop feasible research questions on a topic that is interesting to both the researcher and the scientific community. This can be achieved by a meticulous review of previous and current studies to establish a novel topic. Specific areas are subsequently focused on to generate ethical research questions. The relevance of the research questions is evaluated in terms of clarity of the resulting data, specificity of the methodology, objectivity of the outcome, depth of the research, and impact of the study. 1 , 5 These aspects constitute the FINER criteria (i.e., Feasible, Interesting, Novel, Ethical, and Relevant). 1 Clarity and effectiveness are achieved if research questions meet the FINER criteria. In addition to the FINER criteria, Ratan et al. described focus, complexity, novelty, feasibility, and measurability for evaluating the effectiveness of research questions. 14
The PICOT and PEO frameworks are also used when developing research questions. 1 The following elements are addressed in these frameworks, PICOT: P-population/patients/problem, I-intervention or indicator being studied, C-comparison group, O-outcome of interest, and T-timeframe of the study; PEO: P-population being studied, E-exposure to preexisting conditions, and O-outcome of interest. 1 Research questions are also considered good if these meet the “FINERMAPS” framework: Feasible, Interesting, Novel, Ethical, Relevant, Manageable, Appropriate, Potential value/publishable, and Systematic. 14
As we indicated earlier, research questions and hypotheses that are not carefully formulated result in unethical studies or poor outcomes. To illustrate this, we provide some examples of ambiguous research question and hypotheses that result in unclear and weak research objectives in quantitative research ( Table 6 ) 16 and qualitative research ( Table 7 ) 17 , and how to transform these ambiguous research question(s) and hypothesis(es) into clear and good statements.
| Variables | Unclear and weak statement (Statement 1) | Clear and good statement (Statement 2) | Points to avoid |
|---|---|---|---|
| Research question | Which is more effective between smoke moxibustion and smokeless moxibustion? | “Moreover, regarding smoke moxibustion versus smokeless moxibustion, it remains unclear which is more effective, safe, and acceptable to pregnant women, and whether there is any difference in the amount of heat generated.” | 1) Vague and unfocused questions |
| 2) Closed questions simply answerable by yes or no | |||
| 3) Questions requiring a simple choice | |||
| Hypothesis | The smoke moxibustion group will have higher cephalic presentation. | “Hypothesis 1. The smoke moxibustion stick group (SM group) and smokeless moxibustion stick group (-SLM group) will have higher rates of cephalic presentation after treatment than the control group. | 1) Unverifiable hypotheses |
| Hypothesis 2. The SM group and SLM group will have higher rates of cephalic presentation at birth than the control group. | 2) Incompletely stated groups of comparison | ||
| Hypothesis 3. There will be no significant differences in the well-being of the mother and child among the three groups in terms of the following outcomes: premature birth, premature rupture of membranes (PROM) at < 37 weeks, Apgar score < 7 at 5 min, umbilical cord blood pH < 7.1, admission to neonatal intensive care unit (NICU), and intrauterine fetal death.” | 3) Insufficiently described variables or outcomes | ||
| Research objective | To determine which is more effective between smoke moxibustion and smokeless moxibustion. | “The specific aims of this pilot study were (a) to compare the effects of smoke moxibustion and smokeless moxibustion treatments with the control group as a possible supplement to ECV for converting breech presentation to cephalic presentation and increasing adherence to the newly obtained cephalic position, and (b) to assess the effects of these treatments on the well-being of the mother and child.” | 1) Poor understanding of the research question and hypotheses |
| 2) Insufficient description of population, variables, or study outcomes |
a These statements were composed for comparison and illustrative purposes only.
b These statements are direct quotes from Higashihara and Horiuchi. 16
| Variables | Unclear and weak statement (Statement 1) | Clear and good statement (Statement 2) | Points to avoid |
|---|---|---|---|
| Research question | Does disrespect and abuse (D&A) occur in childbirth in Tanzania? | How does disrespect and abuse (D&A) occur and what are the types of physical and psychological abuses observed in midwives’ actual care during facility-based childbirth in urban Tanzania? | 1) Ambiguous or oversimplistic questions |
| 2) Questions unverifiable by data collection and analysis | |||
| Hypothesis | Disrespect and abuse (D&A) occur in childbirth in Tanzania. | Hypothesis 1: Several types of physical and psychological abuse by midwives in actual care occur during facility-based childbirth in urban Tanzania. | 1) Statements simply expressing facts |
| Hypothesis 2: Weak nursing and midwifery management contribute to the D&A of women during facility-based childbirth in urban Tanzania. | 2) Insufficiently described concepts or variables | ||
| Research objective | To describe disrespect and abuse (D&A) in childbirth in Tanzania. | “This study aimed to describe from actual observations the respectful and disrespectful care received by women from midwives during their labor period in two hospitals in urban Tanzania.” | 1) Statements unrelated to the research question and hypotheses |
| 2) Unattainable or unexplorable objectives |
a This statement is a direct quote from Shimoda et al. 17
The other statements were composed for comparison and illustrative purposes only.
CONSTRUCTING RESEARCH QUESTIONS AND HYPOTHESES
To construct effective research questions and hypotheses, it is very important to 1) clarify the background and 2) identify the research problem at the outset of the research, within a specific timeframe. 9 Then, 3) review or conduct preliminary research to collect all available knowledge about the possible research questions by studying theories and previous studies. 18 Afterwards, 4) construct research questions to investigate the research problem. Identify variables to be accessed from the research questions 4 and make operational definitions of constructs from the research problem and questions. Thereafter, 5) construct specific deductive or inductive predictions in the form of hypotheses. 4 Finally, 6) state the study aims . This general flow for constructing effective research questions and hypotheses prior to conducting research is shown in Fig. 1 .

Research questions are used more frequently in qualitative research than objectives or hypotheses. 3 These questions seek to discover, understand, explore or describe experiences by asking “What” or “How.” The questions are open-ended to elicit a description rather than to relate variables or compare groups. The questions are continually reviewed, reformulated, and changed during the qualitative study. 3 Research questions are also used more frequently in survey projects than hypotheses in experiments in quantitative research to compare variables and their relationships.
Hypotheses are constructed based on the variables identified and as an if-then statement, following the template, ‘If a specific action is taken, then a certain outcome is expected.’ At this stage, some ideas regarding expectations from the research to be conducted must be drawn. 18 Then, the variables to be manipulated (independent) and influenced (dependent) are defined. 4 Thereafter, the hypothesis is stated and refined, and reproducible data tailored to the hypothesis are identified, collected, and analyzed. 4 The hypotheses must be testable and specific, 18 and should describe the variables and their relationships, the specific group being studied, and the predicted research outcome. 18 Hypotheses construction involves a testable proposition to be deduced from theory, and independent and dependent variables to be separated and measured separately. 3 Therefore, good hypotheses must be based on good research questions constructed at the start of a study or trial. 12
In summary, research questions are constructed after establishing the background of the study. Hypotheses are then developed based on the research questions. Thus, it is crucial to have excellent research questions to generate superior hypotheses. In turn, these would determine the research objectives and the design of the study, and ultimately, the outcome of the research. 12 Algorithms for building research questions and hypotheses are shown in Fig. 2 for quantitative research and in Fig. 3 for qualitative research.

EXAMPLES OF RESEARCH QUESTIONS FROM PUBLISHED ARTICLES
- EXAMPLE 1. Descriptive research question (quantitative research)
- - Presents research variables to be assessed (distinct phenotypes and subphenotypes)
- “BACKGROUND: Since COVID-19 was identified, its clinical and biological heterogeneity has been recognized. Identifying COVID-19 phenotypes might help guide basic, clinical, and translational research efforts.
- RESEARCH QUESTION: Does the clinical spectrum of patients with COVID-19 contain distinct phenotypes and subphenotypes? ” 19
- EXAMPLE 2. Relationship research question (quantitative research)
- - Shows interactions between dependent variable (static postural control) and independent variable (peripheral visual field loss)
- “Background: Integration of visual, vestibular, and proprioceptive sensations contributes to postural control. People with peripheral visual field loss have serious postural instability. However, the directional specificity of postural stability and sensory reweighting caused by gradual peripheral visual field loss remain unclear.
- Research question: What are the effects of peripheral visual field loss on static postural control ?” 20
- EXAMPLE 3. Comparative research question (quantitative research)
- - Clarifies the difference among groups with an outcome variable (patients enrolled in COMPERA with moderate PH or severe PH in COPD) and another group without the outcome variable (patients with idiopathic pulmonary arterial hypertension (IPAH))
- “BACKGROUND: Pulmonary hypertension (PH) in COPD is a poorly investigated clinical condition.
- RESEARCH QUESTION: Which factors determine the outcome of PH in COPD?
- STUDY DESIGN AND METHODS: We analyzed the characteristics and outcome of patients enrolled in the Comparative, Prospective Registry of Newly Initiated Therapies for Pulmonary Hypertension (COMPERA) with moderate or severe PH in COPD as defined during the 6th PH World Symposium who received medical therapy for PH and compared them with patients with idiopathic pulmonary arterial hypertension (IPAH) .” 21
- EXAMPLE 4. Exploratory research question (qualitative research)
- - Explores areas that have not been fully investigated (perspectives of families and children who receive care in clinic-based child obesity treatment) to have a deeper understanding of the research problem
- “Problem: Interventions for children with obesity lead to only modest improvements in BMI and long-term outcomes, and data are limited on the perspectives of families of children with obesity in clinic-based treatment. This scoping review seeks to answer the question: What is known about the perspectives of families and children who receive care in clinic-based child obesity treatment? This review aims to explore the scope of perspectives reported by families of children with obesity who have received individualized outpatient clinic-based obesity treatment.” 22
- EXAMPLE 5. Relationship research question (quantitative research)
- - Defines interactions between dependent variable (use of ankle strategies) and independent variable (changes in muscle tone)
- “Background: To maintain an upright standing posture against external disturbances, the human body mainly employs two types of postural control strategies: “ankle strategy” and “hip strategy.” While it has been reported that the magnitude of the disturbance alters the use of postural control strategies, it has not been elucidated how the level of muscle tone, one of the crucial parameters of bodily function, determines the use of each strategy. We have previously confirmed using forward dynamics simulations of human musculoskeletal models that an increased muscle tone promotes the use of ankle strategies. The objective of the present study was to experimentally evaluate a hypothesis: an increased muscle tone promotes the use of ankle strategies. Research question: Do changes in the muscle tone affect the use of ankle strategies ?” 23
EXAMPLES OF HYPOTHESES IN PUBLISHED ARTICLES
- EXAMPLE 1. Working hypothesis (quantitative research)
- - A hypothesis that is initially accepted for further research to produce a feasible theory
- “As fever may have benefit in shortening the duration of viral illness, it is plausible to hypothesize that the antipyretic efficacy of ibuprofen may be hindering the benefits of a fever response when taken during the early stages of COVID-19 illness .” 24
- “In conclusion, it is plausible to hypothesize that the antipyretic efficacy of ibuprofen may be hindering the benefits of a fever response . The difference in perceived safety of these agents in COVID-19 illness could be related to the more potent efficacy to reduce fever with ibuprofen compared to acetaminophen. Compelling data on the benefit of fever warrant further research and review to determine when to treat or withhold ibuprofen for early stage fever for COVID-19 and other related viral illnesses .” 24
- EXAMPLE 2. Exploratory hypothesis (qualitative research)
- - Explores particular areas deeper to clarify subjective experience and develop a formal hypothesis potentially testable in a future quantitative approach
- “We hypothesized that when thinking about a past experience of help-seeking, a self distancing prompt would cause increased help-seeking intentions and more favorable help-seeking outcome expectations .” 25
- “Conclusion
- Although a priori hypotheses were not supported, further research is warranted as results indicate the potential for using self-distancing approaches to increasing help-seeking among some people with depressive symptomatology.” 25
- EXAMPLE 3. Hypothesis-generating research to establish a framework for hypothesis testing (qualitative research)
- “We hypothesize that compassionate care is beneficial for patients (better outcomes), healthcare systems and payers (lower costs), and healthcare providers (lower burnout). ” 26
- Compassionomics is the branch of knowledge and scientific study of the effects of compassionate healthcare. Our main hypotheses are that compassionate healthcare is beneficial for (1) patients, by improving clinical outcomes, (2) healthcare systems and payers, by supporting financial sustainability, and (3) HCPs, by lowering burnout and promoting resilience and well-being. The purpose of this paper is to establish a scientific framework for testing the hypotheses above . If these hypotheses are confirmed through rigorous research, compassionomics will belong in the science of evidence-based medicine, with major implications for all healthcare domains.” 26
- EXAMPLE 4. Statistical hypothesis (quantitative research)
- - An assumption is made about the relationship among several population characteristics ( gender differences in sociodemographic and clinical characteristics of adults with ADHD ). Validity is tested by statistical experiment or analysis ( chi-square test, Students t-test, and logistic regression analysis)
- “Our research investigated gender differences in sociodemographic and clinical characteristics of adults with ADHD in a Japanese clinical sample. Due to unique Japanese cultural ideals and expectations of women's behavior that are in opposition to ADHD symptoms, we hypothesized that women with ADHD experience more difficulties and present more dysfunctions than men . We tested the following hypotheses: first, women with ADHD have more comorbidities than men with ADHD; second, women with ADHD experience more social hardships than men, such as having less full-time employment and being more likely to be divorced.” 27
- “Statistical Analysis
- ( text omitted ) Between-gender comparisons were made using the chi-squared test for categorical variables and Students t-test for continuous variables…( text omitted ). A logistic regression analysis was performed for employment status, marital status, and comorbidity to evaluate the independent effects of gender on these dependent variables.” 27
EXAMPLES OF HYPOTHESIS AS WRITTEN IN PUBLISHED ARTICLES IN RELATION TO OTHER PARTS
- EXAMPLE 1. Background, hypotheses, and aims are provided
- “Pregnant women need skilled care during pregnancy and childbirth, but that skilled care is often delayed in some countries …( text omitted ). The focused antenatal care (FANC) model of WHO recommends that nurses provide information or counseling to all pregnant women …( text omitted ). Job aids are visual support materials that provide the right kind of information using graphics and words in a simple and yet effective manner. When nurses are not highly trained or have many work details to attend to, these job aids can serve as a content reminder for the nurses and can be used for educating their patients (Jennings, Yebadokpo, Affo, & Agbogbe, 2010) ( text omitted ). Importantly, additional evidence is needed to confirm how job aids can further improve the quality of ANC counseling by health workers in maternal care …( text omitted )” 28
- “ This has led us to hypothesize that the quality of ANC counseling would be better if supported by job aids. Consequently, a better quality of ANC counseling is expected to produce higher levels of awareness concerning the danger signs of pregnancy and a more favorable impression of the caring behavior of nurses .” 28
- “This study aimed to examine the differences in the responses of pregnant women to a job aid-supported intervention during ANC visit in terms of 1) their understanding of the danger signs of pregnancy and 2) their impression of the caring behaviors of nurses to pregnant women in rural Tanzania.” 28
- EXAMPLE 2. Background, hypotheses, and aims are provided
- “We conducted a two-arm randomized controlled trial (RCT) to evaluate and compare changes in salivary cortisol and oxytocin levels of first-time pregnant women between experimental and control groups. The women in the experimental group touched and held an infant for 30 min (experimental intervention protocol), whereas those in the control group watched a DVD movie of an infant (control intervention protocol). The primary outcome was salivary cortisol level and the secondary outcome was salivary oxytocin level.” 29
- “ We hypothesize that at 30 min after touching and holding an infant, the salivary cortisol level will significantly decrease and the salivary oxytocin level will increase in the experimental group compared with the control group .” 29
- EXAMPLE 3. Background, aim, and hypothesis are provided
- “In countries where the maternal mortality ratio remains high, antenatal education to increase Birth Preparedness and Complication Readiness (BPCR) is considered one of the top priorities [1]. BPCR includes birth plans during the antenatal period, such as the birthplace, birth attendant, transportation, health facility for complications, expenses, and birth materials, as well as family coordination to achieve such birth plans. In Tanzania, although increasing, only about half of all pregnant women attend an antenatal clinic more than four times [4]. Moreover, the information provided during antenatal care (ANC) is insufficient. In the resource-poor settings, antenatal group education is a potential approach because of the limited time for individual counseling at antenatal clinics.” 30
- “This study aimed to evaluate an antenatal group education program among pregnant women and their families with respect to birth-preparedness and maternal and infant outcomes in rural villages of Tanzania.” 30
- “ The study hypothesis was if Tanzanian pregnant women and their families received a family-oriented antenatal group education, they would (1) have a higher level of BPCR, (2) attend antenatal clinic four or more times, (3) give birth in a health facility, (4) have less complications of women at birth, and (5) have less complications and deaths of infants than those who did not receive the education .” 30
Research questions and hypotheses are crucial components to any type of research, whether quantitative or qualitative. These questions should be developed at the very beginning of the study. Excellent research questions lead to superior hypotheses, which, like a compass, set the direction of research, and can often determine the successful conduct of the study. Many research studies have floundered because the development of research questions and subsequent hypotheses was not given the thought and meticulous attention needed. The development of research questions and hypotheses is an iterative process based on extensive knowledge of the literature and insightful grasp of the knowledge gap. Focused, concise, and specific research questions provide a strong foundation for constructing hypotheses which serve as formal predictions about the research outcomes. Research questions and hypotheses are crucial elements of research that should not be overlooked. They should be carefully thought of and constructed when planning research. This avoids unethical studies and poor outcomes by defining well-founded objectives that determine the design, course, and outcome of the study.
Disclosure: The authors have no potential conflicts of interest to disclose.
Author Contributions:
- Conceptualization: Barroga E, Matanguihan GJ.
- Methodology: Barroga E, Matanguihan GJ.
- Writing - original draft: Barroga E, Matanguihan GJ.
- Writing - review & editing: Barroga E, Matanguihan GJ.
Quantitative Research Methods
- Introduction
- Descriptive and Inferential Statistics
- Hypothesis Testing
- Regression and Correlation
- Time Series
- Meta-Analysis
- Mixed Methods
- Additional Resources
- Get Research Help
Hypothesis Tests
A hypothesis test is exactly what it sounds like: You make a hypothesis about the parameters of a population, and the test determines whether your hypothesis is consistent with your sample data.
- Hypothesis Testing Penn State University tutorial
- Hypothesis Testing Wolfram MathWorld overview
- Hypothesis Testing Minitab Blog entry
- List of Statistical Tests A list of commonly used hypothesis tests and the circumstances under which they're used.
The p-value of a hypothesis test is the probability that your sample data would have occurred if you hypothesis were not correct. Traditionally, researchers have used a p-value of 0.05 (a 5% probability that your sample data would have occurred if your hypothesis was wrong) as the threshold for declaring that a hypothesis is true. But there is a long history of debate and controversy over p-values and significance levels.
Nonparametric Tests
Many of the most commonly used hypothesis tests rely on assumptions about your sample data—for instance, that it is continuous, and that its parameters follow a Normal distribution. Nonparametric hypothesis tests don't make any assumptions about the distribution of the data, and many can be used on categorical data.
- Nonparametric Tests at Boston University A lesson covering four common nonparametric tests.
- Nonparametric Tests at Penn State Tutorial covering the theory behind nonparametric tests as well as several commonly used tests.
- << Previous: Descriptive and Inferential Statistics
- Next: Regression and Correlation >>
- Last Updated: Aug 16, 2024 1:12 PM
- URL: https://guides.library.duq.edu/quant-methods
- Search Search Please fill out this field.
What Is Hypothesis Testing?
- How It Works
4 Step Process
The bottom line.
- Fundamental Analysis
Hypothesis Testing: 4 Steps and Example
:max_bytes(150000):strip_icc():format(webp)/ChristinaMajaski-5c9433ea46e0fb0001d880b1.jpeg "research that uses hypothesis testing")
Hypothesis testing, sometimes called significance testing, is an act in statistics whereby an analyst tests an assumption regarding a population parameter. The methodology employed by the analyst depends on the nature of the data used and the reason for the analysis.
Hypothesis testing is used to assess the plausibility of a hypothesis by using sample data. Such data may come from a larger population or a data-generating process. The word "population" will be used for both of these cases in the following descriptions.
Key Takeaways
- Hypothesis testing is used to assess the plausibility of a hypothesis by using sample data.
- The test provides evidence concerning the plausibility of the hypothesis, given the data.
- Statistical analysts test a hypothesis by measuring and examining a random sample of the population being analyzed.
- The four steps of hypothesis testing include stating the hypotheses, formulating an analysis plan, analyzing the sample data, and analyzing the result.
How Hypothesis Testing Works
In hypothesis testing, an analyst tests a statistical sample, intending to provide evidence on the plausibility of the null hypothesis. Statistical analysts measure and examine a random sample of the population being analyzed. All analysts use a random population sample to test two different hypotheses: the null hypothesis and the alternative hypothesis.
The null hypothesis is usually a hypothesis of equality between population parameters; e.g., a null hypothesis may state that the population mean return is equal to zero. The alternative hypothesis is effectively the opposite of a null hypothesis. Thus, they are mutually exclusive , and only one can be true. However, one of the two hypotheses will always be true.
The null hypothesis is a statement about a population parameter, such as the population mean, that is assumed to be true.
- State the hypotheses.
- Formulate an analysis plan, which outlines how the data will be evaluated.
- Carry out the plan and analyze the sample data.
- Analyze the results and either reject the null hypothesis, or state that the null hypothesis is plausible, given the data.
Example of Hypothesis Testing
If an individual wants to test that a penny has exactly a 50% chance of landing on heads, the null hypothesis would be that 50% is correct, and the alternative hypothesis would be that 50% is not correct. Mathematically, the null hypothesis is represented as Ho: P = 0.5. The alternative hypothesis is shown as "Ha" and is identical to the null hypothesis, except with the equal sign struck-through, meaning that it does not equal 50%.
A random sample of 100 coin flips is taken, and the null hypothesis is tested. If it is found that the 100 coin flips were distributed as 40 heads and 60 tails, the analyst would assume that a penny does not have a 50% chance of landing on heads and would reject the null hypothesis and accept the alternative hypothesis.
If there were 48 heads and 52 tails, then it is plausible that the coin could be fair and still produce such a result. In cases such as this where the null hypothesis is "accepted," the analyst states that the difference between the expected results (50 heads and 50 tails) and the observed results (48 heads and 52 tails) is "explainable by chance alone."
When Did Hypothesis Testing Begin?
Some statisticians attribute the first hypothesis tests to satirical writer John Arbuthnot in 1710, who studied male and female births in England after observing that in nearly every year, male births exceeded female births by a slight proportion. Arbuthnot calculated that the probability of this happening by chance was small, and therefore it was due to “divine providence.”
What are the Benefits of Hypothesis Testing?
Hypothesis testing helps assess the accuracy of new ideas or theories by testing them against data. This allows researchers to determine whether the evidence supports their hypothesis, helping to avoid false claims and conclusions. Hypothesis testing also provides a framework for decision-making based on data rather than personal opinions or biases. By relying on statistical analysis, hypothesis testing helps to reduce the effects of chance and confounding variables, providing a robust framework for making informed conclusions.
What are the Limitations of Hypothesis Testing?
Hypothesis testing relies exclusively on data and doesn’t provide a comprehensive understanding of the subject being studied. Additionally, the accuracy of the results depends on the quality of the available data and the statistical methods used. Inaccurate data or inappropriate hypothesis formulation may lead to incorrect conclusions or failed tests. Hypothesis testing can also lead to errors, such as analysts either accepting or rejecting a null hypothesis when they shouldn’t have. These errors may result in false conclusions or missed opportunities to identify significant patterns or relationships in the data.
Hypothesis testing refers to a statistical process that helps researchers determine the reliability of a study. By using a well-formulated hypothesis and set of statistical tests, individuals or businesses can make inferences about the population that they are studying and draw conclusions based on the data presented. All hypothesis testing methods have the same four-step process, which includes stating the hypotheses, formulating an analysis plan, analyzing the sample data, and analyzing the result.
Sage. " Introduction to Hypothesis Testing ," Page 4.
Elder Research. " Who Invented the Null Hypothesis? "
Formplus. " Hypothesis Testing: Definition, Uses, Limitations and Examples ."
:max_bytes(150000):strip_icc():format(webp)/null_hypothesis-finalE-56a4132b022f49f0a3d469c6882ddd99.jpg "research that uses hypothesis testing")
- Terms of Service
- Editorial Policy
- Privacy Policy
An official website of the United States government
The .gov means it’s official. Federal government websites often end in .gov or .mil. Before sharing sensitive information, make sure you’re on a federal government site.
The site is secure. The https:// ensures that you are connecting to the official website and that any information you provide is encrypted and transmitted securely.
- Publications
- Account settings
- My Bibliography
- Collections
- Citation manager
Save citation to file
Email citation, add to collections.
- Create a new collection
- Add to an existing collection
Add to My Bibliography
Your saved search, create a file for external citation management software, your rss feed.
- Search in PubMed
- Search in NLM Catalog
- Add to Search
Hypothesis testing
- PMID: 8900794
- DOI: 10.1097/00002800-199607000-00009
Hypothesis testing is the process of making a choice between two conflicting hypotheses. The null hypothesis, H0, is a statistical proposition stating that there is no significant difference between a hypothesized value of a population parameter and its value estimated from a sample drawn from that population. The alternative hypothesis, H1 or Ha, is a statistical proposition stating that there is a significant difference between a hypothesized value of a population parameter and its estimated value. When the null hypothesis is tested, a decision is either correct or incorrect. An incorrect decision can be made in two ways: We can reject the null hypothesis when it is true (Type I error) or we can fail to reject the null hypothesis when it is false (Type II error). The probability of making Type I and Type II errors is designated by alpha and beta, respectively. The smallest observed significance level for which the null hypothesis would be rejected is referred to as the p-value. The p-value only has meaning as a measure of confidence when the decision is to reject the null hypothesis. It has no meaning when the decision is that the null hypothesis is true.
PubMed Disclaimer
Similar articles
- [Principles of tests of hypotheses in statistics: alpha, beta and P]. Riou B, Landais P. Riou B, et al. Ann Fr Anesth Reanim. 1998;17(9):1168-80. doi: 10.1016/s0750-7658(00)80015-5. Ann Fr Anesth Reanim. 1998. PMID: 9835991 French.
- P value and the theory of hypothesis testing: an explanation for new researchers. Biau DJ, Jolles BM, Porcher R. Biau DJ, et al. Clin Orthop Relat Res. 2010 Mar;468(3):885-92. doi: 10.1007/s11999-009-1164-4. Clin Orthop Relat Res. 2010. PMID: 19921345 Free PMC article.
- Statistical reasoning in clinical trials: hypothesis testing. Kelen GD, Brown CG, Ashton J. Kelen GD, et al. Am J Emerg Med. 1988 Jan;6(1):52-61. doi: 10.1016/0735-6757(88)90207-0. Am J Emerg Med. 1988. PMID: 3275456 Review.
- Statistical Significance. Tenny S, Abdelgawad I. Tenny S, et al. 2023 Nov 23. In: StatPearls [Internet]. Treasure Island (FL): StatPearls Publishing; 2024 Jan–. 2023 Nov 23. In: StatPearls [Internet]. Treasure Island (FL): StatPearls Publishing; 2024 Jan–. PMID: 29083828 Free Books & Documents.
- Issues in biomedical statistics: statistical inference. Ludbrook J, Dudley H. Ludbrook J, et al. Aust N Z J Surg. 1994 Sep;64(9):630-6. doi: 10.1111/j.1445-2197.1994.tb02308.x. Aust N Z J Surg. 1994. PMID: 8085981 Review.
- Search in MeSH
LinkOut - more resources
Full text sources.
- Ovid Technologies, Inc.
- Wolters Kluwer

- Citation Manager
NCBI Literature Resources
MeSH PMC Bookshelf Disclaimer
The PubMed wordmark and PubMed logo are registered trademarks of the U.S. Department of Health and Human Services (HHS). Unauthorized use of these marks is strictly prohibited.
Frequently asked questions
What is hypothesis testing.
Hypothesis testing is a formal procedure for investigating our ideas about the world using statistics. It is used by scientists to test specific predictions, called hypotheses , by calculating how likely it is that a pattern or relationship between variables could have arisen by chance.
Frequently asked questions: Methodology
Attrition refers to participants leaving a study. It always happens to some extent—for example, in randomized controlled trials for medical research.
Differential attrition occurs when attrition or dropout rates differ systematically between the intervention and the control group . As a result, the characteristics of the participants who drop out differ from the characteristics of those who stay in the study. Because of this, study results may be biased .
Action research is conducted in order to solve a particular issue immediately, while case studies are often conducted over a longer period of time and focus more on observing and analyzing a particular ongoing phenomenon.
Action research is focused on solving a problem or informing individual and community-based knowledge in a way that impacts teaching, learning, and other related processes. It is less focused on contributing theoretical input, instead producing actionable input.
Action research is particularly popular with educators as a form of systematic inquiry because it prioritizes reflection and bridges the gap between theory and practice. Educators are able to simultaneously investigate an issue as they solve it, and the method is very iterative and flexible.
A cycle of inquiry is another name for action research . It is usually visualized in a spiral shape following a series of steps, such as “planning → acting → observing → reflecting.”
To make quantitative observations , you need to use instruments that are capable of measuring the quantity you want to observe. For example, you might use a ruler to measure the length of an object or a thermometer to measure its temperature.
Criterion validity and construct validity are both types of measurement validity . In other words, they both show you how accurately a method measures something.
While construct validity is the degree to which a test or other measurement method measures what it claims to measure, criterion validity is the degree to which a test can predictively (in the future) or concurrently (in the present) measure something.
Construct validity is often considered the overarching type of measurement validity . You need to have face validity , content validity , and criterion validity in order to achieve construct validity.
Convergent validity and discriminant validity are both subtypes of construct validity . Together, they help you evaluate whether a test measures the concept it was designed to measure.
- Convergent validity indicates whether a test that is designed to measure a particular construct correlates with other tests that assess the same or similar construct.
- Discriminant validity indicates whether two tests that should not be highly related to each other are indeed not related. This type of validity is also called divergent validity .
You need to assess both in order to demonstrate construct validity. Neither one alone is sufficient for establishing construct validity.
- Discriminant validity indicates whether two tests that should not be highly related to each other are indeed not related
Content validity shows you how accurately a test or other measurement method taps into the various aspects of the specific construct you are researching.
In other words, it helps you answer the question: “does the test measure all aspects of the construct I want to measure?” If it does, then the test has high content validity.
The higher the content validity, the more accurate the measurement of the construct.
If the test fails to include parts of the construct, or irrelevant parts are included, the validity of the instrument is threatened, which brings your results into question.
Face validity and content validity are similar in that they both evaluate how suitable the content of a test is. The difference is that face validity is subjective, and assesses content at surface level.
When a test has strong face validity, anyone would agree that the test’s questions appear to measure what they are intended to measure.
For example, looking at a 4th grade math test consisting of problems in which students have to add and multiply, most people would agree that it has strong face validity (i.e., it looks like a math test).
On the other hand, content validity evaluates how well a test represents all the aspects of a topic. Assessing content validity is more systematic and relies on expert evaluation. of each question, analyzing whether each one covers the aspects that the test was designed to cover.
A 4th grade math test would have high content validity if it covered all the skills taught in that grade. Experts(in this case, math teachers), would have to evaluate the content validity by comparing the test to the learning objectives.
Snowball sampling is a non-probability sampling method . Unlike probability sampling (which involves some form of random selection ), the initial individuals selected to be studied are the ones who recruit new participants.
Because not every member of the target population has an equal chance of being recruited into the sample, selection in snowball sampling is non-random.
Snowball sampling is a non-probability sampling method , where there is not an equal chance for every member of the population to be included in the sample .
This means that you cannot use inferential statistics and make generalizations —often the goal of quantitative research . As such, a snowball sample is not representative of the target population and is usually a better fit for qualitative research .
Snowball sampling relies on the use of referrals. Here, the researcher recruits one or more initial participants, who then recruit the next ones.
Participants share similar characteristics and/or know each other. Because of this, not every member of the population has an equal chance of being included in the sample, giving rise to sampling bias .
Snowball sampling is best used in the following cases:
- If there is no sampling frame available (e.g., people with a rare disease)
- If the population of interest is hard to access or locate (e.g., people experiencing homelessness)
- If the research focuses on a sensitive topic (e.g., extramarital affairs)
The reproducibility and replicability of a study can be ensured by writing a transparent, detailed method section and using clear, unambiguous language.
Reproducibility and replicability are related terms.
- Reproducing research entails reanalyzing the existing data in the same manner.
- Replicating (or repeating ) the research entails reconducting the entire analysis, including the collection of new data .
- A successful reproduction shows that the data analyses were conducted in a fair and honest manner.
- A successful replication shows that the reliability of the results is high.
Stratified sampling and quota sampling both involve dividing the population into subgroups and selecting units from each subgroup. The purpose in both cases is to select a representative sample and/or to allow comparisons between subgroups.
The main difference is that in stratified sampling, you draw a random sample from each subgroup ( probability sampling ). In quota sampling you select a predetermined number or proportion of units, in a non-random manner ( non-probability sampling ).
Purposive and convenience sampling are both sampling methods that are typically used in qualitative data collection.
A convenience sample is drawn from a source that is conveniently accessible to the researcher. Convenience sampling does not distinguish characteristics among the participants. On the other hand, purposive sampling focuses on selecting participants possessing characteristics associated with the research study.
The findings of studies based on either convenience or purposive sampling can only be generalized to the (sub)population from which the sample is drawn, and not to the entire population.
Random sampling or probability sampling is based on random selection. This means that each unit has an equal chance (i.e., equal probability) of being included in the sample.
On the other hand, convenience sampling involves stopping people at random, which means that not everyone has an equal chance of being selected depending on the place, time, or day you are collecting your data.
Convenience sampling and quota sampling are both non-probability sampling methods. They both use non-random criteria like availability, geographical proximity, or expert knowledge to recruit study participants.
However, in convenience sampling, you continue to sample units or cases until you reach the required sample size.
In quota sampling, you first need to divide your population of interest into subgroups (strata) and estimate their proportions (quota) in the population. Then you can start your data collection, using convenience sampling to recruit participants, until the proportions in each subgroup coincide with the estimated proportions in the population.
A sampling frame is a list of every member in the entire population . It is important that the sampling frame is as complete as possible, so that your sample accurately reflects your population.
Stratified and cluster sampling may look similar, but bear in mind that groups created in cluster sampling are heterogeneous , so the individual characteristics in the cluster vary. In contrast, groups created in stratified sampling are homogeneous , as units share characteristics.
Relatedly, in cluster sampling you randomly select entire groups and include all units of each group in your sample. However, in stratified sampling, you select some units of all groups and include them in your sample. In this way, both methods can ensure that your sample is representative of the target population .
A systematic review is secondary research because it uses existing research. You don’t collect new data yourself.
The key difference between observational studies and experimental designs is that a well-done observational study does not influence the responses of participants, while experiments do have some sort of treatment condition applied to at least some participants by random assignment .
An observational study is a great choice for you if your research question is based purely on observations. If there are ethical, logistical, or practical concerns that prevent you from conducting a traditional experiment , an observational study may be a good choice. In an observational study, there is no interference or manipulation of the research subjects, as well as no control or treatment groups .
It’s often best to ask a variety of people to review your measurements. You can ask experts, such as other researchers, or laypeople, such as potential participants, to judge the face validity of tests.
While experts have a deep understanding of research methods , the people you’re studying can provide you with valuable insights you may have missed otherwise.
Face validity is important because it’s a simple first step to measuring the overall validity of a test or technique. It’s a relatively intuitive, quick, and easy way to start checking whether a new measure seems useful at first glance.
Good face validity means that anyone who reviews your measure says that it seems to be measuring what it’s supposed to. With poor face validity, someone reviewing your measure may be left confused about what you’re measuring and why you’re using this method.
Face validity is about whether a test appears to measure what it’s supposed to measure. This type of validity is concerned with whether a measure seems relevant and appropriate for what it’s assessing only on the surface.
Statistical analyses are often applied to test validity with data from your measures. You test convergent validity and discriminant validity with correlations to see if results from your test are positively or negatively related to those of other established tests.
You can also use regression analyses to assess whether your measure is actually predictive of outcomes that you expect it to predict theoretically. A regression analysis that supports your expectations strengthens your claim of construct validity .
When designing or evaluating a measure, construct validity helps you ensure you’re actually measuring the construct you’re interested in. If you don’t have construct validity, you may inadvertently measure unrelated or distinct constructs and lose precision in your research.
Construct validity is often considered the overarching type of measurement validity , because it covers all of the other types. You need to have face validity , content validity , and criterion validity to achieve construct validity.
Construct validity is about how well a test measures the concept it was designed to evaluate. It’s one of four types of measurement validity , which includes construct validity, face validity , and criterion validity.
There are two subtypes of construct validity.
- Convergent validity : The extent to which your measure corresponds to measures of related constructs
- Discriminant validity : The extent to which your measure is unrelated or negatively related to measures of distinct constructs
Naturalistic observation is a valuable tool because of its flexibility, external validity , and suitability for topics that can’t be studied in a lab setting.
The downsides of naturalistic observation include its lack of scientific control , ethical considerations , and potential for bias from observers and subjects.
Naturalistic observation is a qualitative research method where you record the behaviors of your research subjects in real world settings. You avoid interfering or influencing anything in a naturalistic observation.
You can think of naturalistic observation as “people watching” with a purpose.
A dependent variable is what changes as a result of the independent variable manipulation in experiments . It’s what you’re interested in measuring, and it “depends” on your independent variable.
In statistics, dependent variables are also called:
- Response variables (they respond to a change in another variable)
- Outcome variables (they represent the outcome you want to measure)
- Left-hand-side variables (they appear on the left-hand side of a regression equation)
An independent variable is the variable you manipulate, control, or vary in an experimental study to explore its effects. It’s called “independent” because it’s not influenced by any other variables in the study.
Independent variables are also called:
- Explanatory variables (they explain an event or outcome)
- Predictor variables (they can be used to predict the value of a dependent variable)
- Right-hand-side variables (they appear on the right-hand side of a regression equation).
As a rule of thumb, questions related to thoughts, beliefs, and feelings work well in focus groups. Take your time formulating strong questions, paying special attention to phrasing. Be careful to avoid leading questions , which can bias your responses.
Overall, your focus group questions should be:
- Open-ended and flexible
- Impossible to answer with “yes” or “no” (questions that start with “why” or “how” are often best)
- Unambiguous, getting straight to the point while still stimulating discussion
- Unbiased and neutral
A structured interview is a data collection method that relies on asking questions in a set order to collect data on a topic. They are often quantitative in nature. Structured interviews are best used when:
- You already have a very clear understanding of your topic. Perhaps significant research has already been conducted, or you have done some prior research yourself, but you already possess a baseline for designing strong structured questions.
- You are constrained in terms of time or resources and need to analyze your data quickly and efficiently.
- Your research question depends on strong parity between participants, with environmental conditions held constant.
More flexible interview options include semi-structured interviews , unstructured interviews , and focus groups .
Social desirability bias is the tendency for interview participants to give responses that will be viewed favorably by the interviewer or other participants. It occurs in all types of interviews and surveys , but is most common in semi-structured interviews , unstructured interviews , and focus groups .
Social desirability bias can be mitigated by ensuring participants feel at ease and comfortable sharing their views. Make sure to pay attention to your own body language and any physical or verbal cues, such as nodding or widening your eyes.
This type of bias can also occur in observations if the participants know they’re being observed. They might alter their behavior accordingly.
The interviewer effect is a type of bias that emerges when a characteristic of an interviewer (race, age, gender identity, etc.) influences the responses given by the interviewee.
There is a risk of an interviewer effect in all types of interviews , but it can be mitigated by writing really high-quality interview questions.
A semi-structured interview is a blend of structured and unstructured types of interviews. Semi-structured interviews are best used when:
- You have prior interview experience. Spontaneous questions are deceptively challenging, and it’s easy to accidentally ask a leading question or make a participant uncomfortable.
- Your research question is exploratory in nature. Participant answers can guide future research questions and help you develop a more robust knowledge base for future research.
An unstructured interview is the most flexible type of interview, but it is not always the best fit for your research topic.
Unstructured interviews are best used when:
- You are an experienced interviewer and have a very strong background in your research topic, since it is challenging to ask spontaneous, colloquial questions.
- Your research question is exploratory in nature. While you may have developed hypotheses, you are open to discovering new or shifting viewpoints through the interview process.
- You are seeking descriptive data, and are ready to ask questions that will deepen and contextualize your initial thoughts and hypotheses.
- Your research depends on forming connections with your participants and making them feel comfortable revealing deeper emotions, lived experiences, or thoughts.
The four most common types of interviews are:
- Structured interviews : The questions are predetermined in both topic and order.
- Semi-structured interviews : A few questions are predetermined, but other questions aren’t planned.
- Unstructured interviews : None of the questions are predetermined.
- Focus group interviews : The questions are presented to a group instead of one individual.
Deductive reasoning is commonly used in scientific research, and it’s especially associated with quantitative research .
In research, you might have come across something called the hypothetico-deductive method . It’s the scientific method of testing hypotheses to check whether your predictions are substantiated by real-world data.
Deductive reasoning is a logical approach where you progress from general ideas to specific conclusions. It’s often contrasted with inductive reasoning , where you start with specific observations and form general conclusions.
Deductive reasoning is also called deductive logic.
There are many different types of inductive reasoning that people use formally or informally.
Here are a few common types:
- Inductive generalization : You use observations about a sample to come to a conclusion about the population it came from.
- Statistical generalization: You use specific numbers about samples to make statements about populations.
- Causal reasoning: You make cause-and-effect links between different things.
- Sign reasoning: You make a conclusion about a correlational relationship between different things.
- Analogical reasoning: You make a conclusion about something based on its similarities to something else.
Inductive reasoning is a bottom-up approach, while deductive reasoning is top-down.
Inductive reasoning takes you from the specific to the general, while in deductive reasoning, you make inferences by going from general premises to specific conclusions.
In inductive research , you start by making observations or gathering data. Then, you take a broad scan of your data and search for patterns. Finally, you make general conclusions that you might incorporate into theories.
Inductive reasoning is a method of drawing conclusions by going from the specific to the general. It’s usually contrasted with deductive reasoning, where you proceed from general information to specific conclusions.
Inductive reasoning is also called inductive logic or bottom-up reasoning.
A hypothesis states your predictions about what your research will find. It is a tentative answer to your research question that has not yet been tested. For some research projects, you might have to write several hypotheses that address different aspects of your research question.
A hypothesis is not just a guess — it should be based on existing theories and knowledge. It also has to be testable, which means you can support or refute it through scientific research methods (such as experiments, observations and statistical analysis of data).
Triangulation can help:
- Reduce research bias that comes from using a single method, theory, or investigator
- Enhance validity by approaching the same topic with different tools
- Establish credibility by giving you a complete picture of the research problem
But triangulation can also pose problems:
- It’s time-consuming and labor-intensive, often involving an interdisciplinary team.
- Your results may be inconsistent or even contradictory.
There are four main types of triangulation :
- Data triangulation : Using data from different times, spaces, and people
- Investigator triangulation : Involving multiple researchers in collecting or analyzing data
- Theory triangulation : Using varying theoretical perspectives in your research
- Methodological triangulation : Using different methodologies to approach the same topic
Many academic fields use peer review , largely to determine whether a manuscript is suitable for publication. Peer review enhances the credibility of the published manuscript.
However, peer review is also common in non-academic settings. The United Nations, the European Union, and many individual nations use peer review to evaluate grant applications. It is also widely used in medical and health-related fields as a teaching or quality-of-care measure.
Peer assessment is often used in the classroom as a pedagogical tool. Both receiving feedback and providing it are thought to enhance the learning process, helping students think critically and collaboratively.
Peer review can stop obviously problematic, falsified, or otherwise untrustworthy research from being published. It also represents an excellent opportunity to get feedback from renowned experts in your field. It acts as a first defense, helping you ensure your argument is clear and that there are no gaps, vague terms, or unanswered questions for readers who weren’t involved in the research process.
Peer-reviewed articles are considered a highly credible source due to this stringent process they go through before publication.
In general, the peer review process follows the following steps:
- First, the author submits the manuscript to the editor.
- Reject the manuscript and send it back to author, or
- Send it onward to the selected peer reviewer(s)
- Next, the peer review process occurs. The reviewer provides feedback, addressing any major or minor issues with the manuscript, and gives their advice regarding what edits should be made.
- Lastly, the edited manuscript is sent back to the author. They input the edits, and resubmit it to the editor for publication.
Exploratory research is often used when the issue you’re studying is new or when the data collection process is challenging for some reason.
You can use exploratory research if you have a general idea or a specific question that you want to study but there is no preexisting knowledge or paradigm with which to study it.
Exploratory research is a methodology approach that explores research questions that have not previously been studied in depth. It is often used when the issue you’re studying is new, or the data collection process is challenging in some way.
Explanatory research is used to investigate how or why a phenomenon occurs. Therefore, this type of research is often one of the first stages in the research process , serving as a jumping-off point for future research.
Exploratory research aims to explore the main aspects of an under-researched problem, while explanatory research aims to explain the causes and consequences of a well-defined problem.
Explanatory research is a research method used to investigate how or why something occurs when only a small amount of information is available pertaining to that topic. It can help you increase your understanding of a given topic.
Clean data are valid, accurate, complete, consistent, unique, and uniform. Dirty data include inconsistencies and errors.
Dirty data can come from any part of the research process, including poor research design , inappropriate measurement materials, or flawed data entry.
Data cleaning takes place between data collection and data analyses. But you can use some methods even before collecting data.
For clean data, you should start by designing measures that collect valid data. Data validation at the time of data entry or collection helps you minimize the amount of data cleaning you’ll need to do.
After data collection, you can use data standardization and data transformation to clean your data. You’ll also deal with any missing values, outliers, and duplicate values.
Every dataset requires different techniques to clean dirty data , but you need to address these issues in a systematic way. You focus on finding and resolving data points that don’t agree or fit with the rest of your dataset.
These data might be missing values, outliers, duplicate values, incorrectly formatted, or irrelevant. You’ll start with screening and diagnosing your data. Then, you’ll often standardize and accept or remove data to make your dataset consistent and valid.
Data cleaning is necessary for valid and appropriate analyses. Dirty data contain inconsistencies or errors , but cleaning your data helps you minimize or resolve these.
Without data cleaning, you could end up with a Type I or II error in your conclusion. These types of erroneous conclusions can be practically significant with important consequences, because they lead to misplaced investments or missed opportunities.
Data cleaning involves spotting and resolving potential data inconsistencies or errors to improve your data quality. An error is any value (e.g., recorded weight) that doesn’t reflect the true value (e.g., actual weight) of something that’s being measured.
In this process, you review, analyze, detect, modify, or remove “dirty” data to make your dataset “clean.” Data cleaning is also called data cleansing or data scrubbing.
Research misconduct means making up or falsifying data, manipulating data analyses, or misrepresenting results in research reports. It’s a form of academic fraud.
These actions are committed intentionally and can have serious consequences; research misconduct is not a simple mistake or a point of disagreement but a serious ethical failure.
Anonymity means you don’t know who the participants are, while confidentiality means you know who they are but remove identifying information from your research report. Both are important ethical considerations .
You can only guarantee anonymity by not collecting any personally identifying information—for example, names, phone numbers, email addresses, IP addresses, physical characteristics, photos, or videos.
You can keep data confidential by using aggregate information in your research report, so that you only refer to groups of participants rather than individuals.
Research ethics matter for scientific integrity, human rights and dignity, and collaboration between science and society. These principles make sure that participation in studies is voluntary, informed, and safe.
Ethical considerations in research are a set of principles that guide your research designs and practices. These principles include voluntary participation, informed consent, anonymity, confidentiality, potential for harm, and results communication.
Scientists and researchers must always adhere to a certain code of conduct when collecting data from others .
These considerations protect the rights of research participants, enhance research validity , and maintain scientific integrity.
In multistage sampling , you can use probability or non-probability sampling methods .
For a probability sample, you have to conduct probability sampling at every stage.
You can mix it up by using simple random sampling , systematic sampling , or stratified sampling to select units at different stages, depending on what is applicable and relevant to your study.
Multistage sampling can simplify data collection when you have large, geographically spread samples, and you can obtain a probability sample without a complete sampling frame.
But multistage sampling may not lead to a representative sample, and larger samples are needed for multistage samples to achieve the statistical properties of simple random samples .
These are four of the most common mixed methods designs :
- Convergent parallel: Quantitative and qualitative data are collected at the same time and analyzed separately. After both analyses are complete, compare your results to draw overall conclusions.
- Embedded: Quantitative and qualitative data are collected at the same time, but within a larger quantitative or qualitative design. One type of data is secondary to the other.
- Explanatory sequential: Quantitative data is collected and analyzed first, followed by qualitative data. You can use this design if you think your qualitative data will explain and contextualize your quantitative findings.
- Exploratory sequential: Qualitative data is collected and analyzed first, followed by quantitative data. You can use this design if you think the quantitative data will confirm or validate your qualitative findings.
Triangulation in research means using multiple datasets, methods, theories and/or investigators to address a research question. It’s a research strategy that can help you enhance the validity and credibility of your findings.
Triangulation is mainly used in qualitative research , but it’s also commonly applied in quantitative research . Mixed methods research always uses triangulation.
In multistage sampling , or multistage cluster sampling, you draw a sample from a population using smaller and smaller groups at each stage.
This method is often used to collect data from a large, geographically spread group of people in national surveys, for example. You take advantage of hierarchical groupings (e.g., from state to city to neighborhood) to create a sample that’s less expensive and time-consuming to collect data from.
No, the steepness or slope of the line isn’t related to the correlation coefficient value. The correlation coefficient only tells you how closely your data fit on a line, so two datasets with the same correlation coefficient can have very different slopes.
To find the slope of the line, you’ll need to perform a regression analysis .
Correlation coefficients always range between -1 and 1.
The sign of the coefficient tells you the direction of the relationship: a positive value means the variables change together in the same direction, while a negative value means they change together in opposite directions.
The absolute value of a number is equal to the number without its sign. The absolute value of a correlation coefficient tells you the magnitude of the correlation: the greater the absolute value, the stronger the correlation.
These are the assumptions your data must meet if you want to use Pearson’s r :
- Both variables are on an interval or ratio level of measurement
- Data from both variables follow normal distributions
- Your data have no outliers
- Your data is from a random or representative sample
- You expect a linear relationship between the two variables
Quantitative research designs can be divided into two main categories:
- Correlational and descriptive designs are used to investigate characteristics, averages, trends, and associations between variables.
- Experimental and quasi-experimental designs are used to test causal relationships .
Qualitative research designs tend to be more flexible. Common types of qualitative design include case study , ethnography , and grounded theory designs.
A well-planned research design helps ensure that your methods match your research aims, that you collect high-quality data, and that you use the right kind of analysis to answer your questions, utilizing credible sources . This allows you to draw valid , trustworthy conclusions.
The priorities of a research design can vary depending on the field, but you usually have to specify:
- Your research questions and/or hypotheses
- Your overall approach (e.g., qualitative or quantitative )
- The type of design you’re using (e.g., a survey , experiment , or case study )
- Your sampling methods or criteria for selecting subjects
- Your data collection methods (e.g., questionnaires , observations)
- Your data collection procedures (e.g., operationalization , timing and data management)
- Your data analysis methods (e.g., statistical tests or thematic analysis )
A research design is a strategy for answering your research question . It defines your overall approach and determines how you will collect and analyze data.
Questionnaires can be self-administered or researcher-administered.
Self-administered questionnaires can be delivered online or in paper-and-pen formats, in person or through mail. All questions are standardized so that all respondents receive the same questions with identical wording.
Researcher-administered questionnaires are interviews that take place by phone, in-person, or online between researchers and respondents. You can gain deeper insights by clarifying questions for respondents or asking follow-up questions.
You can organize the questions logically, with a clear progression from simple to complex, or randomly between respondents. A logical flow helps respondents process the questionnaire easier and quicker, but it may lead to bias. Randomization can minimize the bias from order effects.
Closed-ended, or restricted-choice, questions offer respondents a fixed set of choices to select from. These questions are easier to answer quickly.
Open-ended or long-form questions allow respondents to answer in their own words. Because there are no restrictions on their choices, respondents can answer in ways that researchers may not have otherwise considered.
A questionnaire is a data collection tool or instrument, while a survey is an overarching research method that involves collecting and analyzing data from people using questionnaires.
The third variable and directionality problems are two main reasons why correlation isn’t causation .
The third variable problem means that a confounding variable affects both variables to make them seem causally related when they are not.
The directionality problem is when two variables correlate and might actually have a causal relationship, but it’s impossible to conclude which variable causes changes in the other.
Correlation describes an association between variables : when one variable changes, so does the other. A correlation is a statistical indicator of the relationship between variables.
Causation means that changes in one variable brings about changes in the other (i.e., there is a cause-and-effect relationship between variables). The two variables are correlated with each other, and there’s also a causal link between them.
While causation and correlation can exist simultaneously, correlation does not imply causation. In other words, correlation is simply a relationship where A relates to B—but A doesn’t necessarily cause B to happen (or vice versa). Mistaking correlation for causation is a common error and can lead to false cause fallacy .
Controlled experiments establish causality, whereas correlational studies only show associations between variables.
- In an experimental design , you manipulate an independent variable and measure its effect on a dependent variable. Other variables are controlled so they can’t impact the results.
- In a correlational design , you measure variables without manipulating any of them. You can test whether your variables change together, but you can’t be sure that one variable caused a change in another.
In general, correlational research is high in external validity while experimental research is high in internal validity .
A correlation is usually tested for two variables at a time, but you can test correlations between three or more variables.
A correlation coefficient is a single number that describes the strength and direction of the relationship between your variables.
Different types of correlation coefficients might be appropriate for your data based on their levels of measurement and distributions . The Pearson product-moment correlation coefficient (Pearson’s r ) is commonly used to assess a linear relationship between two quantitative variables.
A correlational research design investigates relationships between two variables (or more) without the researcher controlling or manipulating any of them. It’s a non-experimental type of quantitative research .
A correlation reflects the strength and/or direction of the association between two or more variables.
- A positive correlation means that both variables change in the same direction.
- A negative correlation means that the variables change in opposite directions.
- A zero correlation means there’s no relationship between the variables.
Random error is almost always present in scientific studies, even in highly controlled settings. While you can’t eradicate it completely, you can reduce random error by taking repeated measurements, using a large sample, and controlling extraneous variables .
You can avoid systematic error through careful design of your sampling , data collection , and analysis procedures. For example, use triangulation to measure your variables using multiple methods; regularly calibrate instruments or procedures; use random sampling and random assignment ; and apply masking (blinding) where possible.
Systematic error is generally a bigger problem in research.
With random error, multiple measurements will tend to cluster around the true value. When you’re collecting data from a large sample , the errors in different directions will cancel each other out.
Systematic errors are much more problematic because they can skew your data away from the true value. This can lead you to false conclusions ( Type I and II errors ) about the relationship between the variables you’re studying.
Random and systematic error are two types of measurement error.
Random error is a chance difference between the observed and true values of something (e.g., a researcher misreading a weighing scale records an incorrect measurement).
Systematic error is a consistent or proportional difference between the observed and true values of something (e.g., a miscalibrated scale consistently records weights as higher than they actually are).
On graphs, the explanatory variable is conventionally placed on the x-axis, while the response variable is placed on the y-axis.
- If you have quantitative variables , use a scatterplot or a line graph.
- If your response variable is categorical, use a scatterplot or a line graph.
- If your explanatory variable is categorical, use a bar graph.
The term “ explanatory variable ” is sometimes preferred over “ independent variable ” because, in real world contexts, independent variables are often influenced by other variables. This means they aren’t totally independent.
Multiple independent variables may also be correlated with each other, so “explanatory variables” is a more appropriate term.
The difference between explanatory and response variables is simple:
- An explanatory variable is the expected cause, and it explains the results.
- A response variable is the expected effect, and it responds to other variables.
In a controlled experiment , all extraneous variables are held constant so that they can’t influence the results. Controlled experiments require:
- A control group that receives a standard treatment, a fake treatment, or no treatment.
- Random assignment of participants to ensure the groups are equivalent.
Depending on your study topic, there are various other methods of controlling variables .
There are 4 main types of extraneous variables :
- Demand characteristics : environmental cues that encourage participants to conform to researchers’ expectations.
- Experimenter effects : unintentional actions by researchers that influence study outcomes.
- Situational variables : environmental variables that alter participants’ behaviors.
- Participant variables : any characteristic or aspect of a participant’s background that could affect study results.
An extraneous variable is any variable that you’re not investigating that can potentially affect the dependent variable of your research study.
A confounding variable is a type of extraneous variable that not only affects the dependent variable, but is also related to the independent variable.
In a factorial design, multiple independent variables are tested.
If you test two variables, each level of one independent variable is combined with each level of the other independent variable to create different conditions.
Within-subjects designs have many potential threats to internal validity , but they are also very statistically powerful .
Advantages:
- Only requires small samples
- Statistically powerful
- Removes the effects of individual differences on the outcomes
Disadvantages:
- Internal validity threats reduce the likelihood of establishing a direct relationship between variables
- Time-related effects, such as growth, can influence the outcomes
- Carryover effects mean that the specific order of different treatments affect the outcomes
While a between-subjects design has fewer threats to internal validity , it also requires more participants for high statistical power than a within-subjects design .
- Prevents carryover effects of learning and fatigue.
- Shorter study duration.
- Needs larger samples for high power.
- Uses more resources to recruit participants, administer sessions, cover costs, etc.
- Individual differences may be an alternative explanation for results.
Yes. Between-subjects and within-subjects designs can be combined in a single study when you have two or more independent variables (a factorial design). In a mixed factorial design, one variable is altered between subjects and another is altered within subjects.
In a between-subjects design , every participant experiences only one condition, and researchers assess group differences between participants in various conditions.
In a within-subjects design , each participant experiences all conditions, and researchers test the same participants repeatedly for differences between conditions.
The word “between” means that you’re comparing different conditions between groups, while the word “within” means you’re comparing different conditions within the same group.
Random assignment is used in experiments with a between-groups or independent measures design. In this research design, there’s usually a control group and one or more experimental groups. Random assignment helps ensure that the groups are comparable.
In general, you should always use random assignment in this type of experimental design when it is ethically possible and makes sense for your study topic.
To implement random assignment , assign a unique number to every member of your study’s sample .
Then, you can use a random number generator or a lottery method to randomly assign each number to a control or experimental group. You can also do so manually, by flipping a coin or rolling a dice to randomly assign participants to groups.
Random selection, or random sampling , is a way of selecting members of a population for your study’s sample.
In contrast, random assignment is a way of sorting the sample into control and experimental groups.
Random sampling enhances the external validity or generalizability of your results, while random assignment improves the internal validity of your study.
In experimental research, random assignment is a way of placing participants from your sample into different groups using randomization. With this method, every member of the sample has a known or equal chance of being placed in a control group or an experimental group.
“Controlling for a variable” means measuring extraneous variables and accounting for them statistically to remove their effects on other variables.
Researchers often model control variable data along with independent and dependent variable data in regression analyses and ANCOVAs . That way, you can isolate the control variable’s effects from the relationship between the variables of interest.
Control variables help you establish a correlational or causal relationship between variables by enhancing internal validity .
If you don’t control relevant extraneous variables , they may influence the outcomes of your study, and you may not be able to demonstrate that your results are really an effect of your independent variable .
A control variable is any variable that’s held constant in a research study. It’s not a variable of interest in the study, but it’s controlled because it could influence the outcomes.
Including mediators and moderators in your research helps you go beyond studying a simple relationship between two variables for a fuller picture of the real world. They are important to consider when studying complex correlational or causal relationships.
Mediators are part of the causal pathway of an effect, and they tell you how or why an effect takes place. Moderators usually help you judge the external validity of your study by identifying the limitations of when the relationship between variables holds.
If something is a mediating variable :
- It’s caused by the independent variable .
- It influences the dependent variable
- When it’s taken into account, the statistical correlation between the independent and dependent variables is higher than when it isn’t considered.
A confounder is a third variable that affects variables of interest and makes them seem related when they are not. In contrast, a mediator is the mechanism of a relationship between two variables: it explains the process by which they are related.
A mediator variable explains the process through which two variables are related, while a moderator variable affects the strength and direction of that relationship.
There are three key steps in systematic sampling :
- Define and list your population , ensuring that it is not ordered in a cyclical or periodic order.
- Decide on your sample size and calculate your interval, k , by dividing your population by your target sample size.
- Choose every k th member of the population as your sample.
Systematic sampling is a probability sampling method where researchers select members of the population at a regular interval – for example, by selecting every 15th person on a list of the population. If the population is in a random order, this can imitate the benefits of simple random sampling .
Yes, you can create a stratified sample using multiple characteristics, but you must ensure that every participant in your study belongs to one and only one subgroup. In this case, you multiply the numbers of subgroups for each characteristic to get the total number of groups.
For example, if you were stratifying by location with three subgroups (urban, rural, or suburban) and marital status with five subgroups (single, divorced, widowed, married, or partnered), you would have 3 x 5 = 15 subgroups.
You should use stratified sampling when your sample can be divided into mutually exclusive and exhaustive subgroups that you believe will take on different mean values for the variable that you’re studying.
Using stratified sampling will allow you to obtain more precise (with lower variance ) statistical estimates of whatever you are trying to measure.
For example, say you want to investigate how income differs based on educational attainment, but you know that this relationship can vary based on race. Using stratified sampling, you can ensure you obtain a large enough sample from each racial group, allowing you to draw more precise conclusions.
In stratified sampling , researchers divide subjects into subgroups called strata based on characteristics that they share (e.g., race, gender, educational attainment).
Once divided, each subgroup is randomly sampled using another probability sampling method.
Cluster sampling is more time- and cost-efficient than other probability sampling methods , particularly when it comes to large samples spread across a wide geographical area.
However, it provides less statistical certainty than other methods, such as simple random sampling , because it is difficult to ensure that your clusters properly represent the population as a whole.
There are three types of cluster sampling : single-stage, double-stage and multi-stage clustering. In all three types, you first divide the population into clusters, then randomly select clusters for use in your sample.
- In single-stage sampling , you collect data from every unit within the selected clusters.
- In double-stage sampling , you select a random sample of units from within the clusters.
- In multi-stage sampling , you repeat the procedure of randomly sampling elements from within the clusters until you have reached a manageable sample.
Cluster sampling is a probability sampling method in which you divide a population into clusters, such as districts or schools, and then randomly select some of these clusters as your sample.
The clusters should ideally each be mini-representations of the population as a whole.
If properly implemented, simple random sampling is usually the best sampling method for ensuring both internal and external validity . However, it can sometimes be impractical and expensive to implement, depending on the size of the population to be studied,
If you have a list of every member of the population and the ability to reach whichever members are selected, you can use simple random sampling.
The American Community Survey is an example of simple random sampling . In order to collect detailed data on the population of the US, the Census Bureau officials randomly select 3.5 million households per year and use a variety of methods to convince them to fill out the survey.
Simple random sampling is a type of probability sampling in which the researcher randomly selects a subset of participants from a population . Each member of the population has an equal chance of being selected. Data is then collected from as large a percentage as possible of this random subset.
Quasi-experimental design is most useful in situations where it would be unethical or impractical to run a true experiment .
Quasi-experiments have lower internal validity than true experiments, but they often have higher external validity as they can use real-world interventions instead of artificial laboratory settings.
A quasi-experiment is a type of research design that attempts to establish a cause-and-effect relationship. The main difference with a true experiment is that the groups are not randomly assigned.
Blinding is important to reduce research bias (e.g., observer bias , demand characteristics ) and ensure a study’s internal validity .
If participants know whether they are in a control or treatment group , they may adjust their behavior in ways that affect the outcome that researchers are trying to measure. If the people administering the treatment are aware of group assignment, they may treat participants differently and thus directly or indirectly influence the final results.
- In a single-blind study , only the participants are blinded.
- In a double-blind study , both participants and experimenters are blinded.
- In a triple-blind study , the assignment is hidden not only from participants and experimenters, but also from the researchers analyzing the data.
Blinding means hiding who is assigned to the treatment group and who is assigned to the control group in an experiment .
A true experiment (a.k.a. a controlled experiment) always includes at least one control group that doesn’t receive the experimental treatment.
However, some experiments use a within-subjects design to test treatments without a control group. In these designs, you usually compare one group’s outcomes before and after a treatment (instead of comparing outcomes between different groups).
For strong internal validity , it’s usually best to include a control group if possible. Without a control group, it’s harder to be certain that the outcome was caused by the experimental treatment and not by other variables.
An experimental group, also known as a treatment group, receives the treatment whose effect researchers wish to study, whereas a control group does not. They should be identical in all other ways.
Individual Likert-type questions are generally considered ordinal data , because the items have clear rank order, but don’t have an even distribution.
Overall Likert scale scores are sometimes treated as interval data. These scores are considered to have directionality and even spacing between them.
The type of data determines what statistical tests you should use to analyze your data.
A Likert scale is a rating scale that quantitatively assesses opinions, attitudes, or behaviors. It is made up of 4 or more questions that measure a single attitude or trait when response scores are combined.
To use a Likert scale in a survey , you present participants with Likert-type questions or statements, and a continuum of items, usually with 5 or 7 possible responses, to capture their degree of agreement.
In scientific research, concepts are the abstract ideas or phenomena that are being studied (e.g., educational achievement). Variables are properties or characteristics of the concept (e.g., performance at school), while indicators are ways of measuring or quantifying variables (e.g., yearly grade reports).
The process of turning abstract concepts into measurable variables and indicators is called operationalization .
There are various approaches to qualitative data analysis , but they all share five steps in common:
- Prepare and organize your data.
- Review and explore your data.
- Develop a data coding system.
- Assign codes to the data.
- Identify recurring themes.
The specifics of each step depend on the focus of the analysis. Some common approaches include textual analysis , thematic analysis , and discourse analysis .
There are five common approaches to qualitative research :
- Grounded theory involves collecting data in order to develop new theories.
- Ethnography involves immersing yourself in a group or organization to understand its culture.
- Narrative research involves interpreting stories to understand how people make sense of their experiences and perceptions.
- Phenomenological research involves investigating phenomena through people’s lived experiences.
- Action research links theory and practice in several cycles to drive innovative changes.
Operationalization means turning abstract conceptual ideas into measurable observations.
For example, the concept of social anxiety isn’t directly observable, but it can be operationally defined in terms of self-rating scores, behavioral avoidance of crowded places, or physical anxiety symptoms in social situations.
Before collecting data , it’s important to consider how you will operationalize the variables that you want to measure.
When conducting research, collecting original data has significant advantages:
- You can tailor data collection to your specific research aims (e.g. understanding the needs of your consumers or user testing your website)
- You can control and standardize the process for high reliability and validity (e.g. choosing appropriate measurements and sampling methods )
However, there are also some drawbacks: data collection can be time-consuming, labor-intensive and expensive. In some cases, it’s more efficient to use secondary data that has already been collected by someone else, but the data might be less reliable.
Data collection is the systematic process by which observations or measurements are gathered in research. It is used in many different contexts by academics, governments, businesses, and other organizations.
There are several methods you can use to decrease the impact of confounding variables on your research: restriction, matching, statistical control and randomization.
In restriction , you restrict your sample by only including certain subjects that have the same values of potential confounding variables.
In matching , you match each of the subjects in your treatment group with a counterpart in the comparison group. The matched subjects have the same values on any potential confounding variables, and only differ in the independent variable .
In statistical control , you include potential confounders as variables in your regression .
In randomization , you randomly assign the treatment (or independent variable) in your study to a sufficiently large number of subjects, which allows you to control for all potential confounding variables.
A confounding variable is closely related to both the independent and dependent variables in a study. An independent variable represents the supposed cause , while the dependent variable is the supposed effect . A confounding variable is a third variable that influences both the independent and dependent variables.
Failing to account for confounding variables can cause you to wrongly estimate the relationship between your independent and dependent variables.
To ensure the internal validity of your research, you must consider the impact of confounding variables. If you fail to account for them, you might over- or underestimate the causal relationship between your independent and dependent variables , or even find a causal relationship where none exists.
Yes, but including more than one of either type requires multiple research questions .
For example, if you are interested in the effect of a diet on health, you can use multiple measures of health: blood sugar, blood pressure, weight, pulse, and many more. Each of these is its own dependent variable with its own research question.
You could also choose to look at the effect of exercise levels as well as diet, or even the additional effect of the two combined. Each of these is a separate independent variable .
To ensure the internal validity of an experiment , you should only change one independent variable at a time.
No. The value of a dependent variable depends on an independent variable, so a variable cannot be both independent and dependent at the same time. It must be either the cause or the effect, not both!
You want to find out how blood sugar levels are affected by drinking diet soda and regular soda, so you conduct an experiment .
- The type of soda – diet or regular – is the independent variable .
- The level of blood sugar that you measure is the dependent variable – it changes depending on the type of soda.
Determining cause and effect is one of the most important parts of scientific research. It’s essential to know which is the cause – the independent variable – and which is the effect – the dependent variable.
In non-probability sampling , the sample is selected based on non-random criteria, and not every member of the population has a chance of being included.
Common non-probability sampling methods include convenience sampling , voluntary response sampling, purposive sampling , snowball sampling, and quota sampling .
Probability sampling means that every member of the target population has a known chance of being included in the sample.
Probability sampling methods include simple random sampling , systematic sampling , stratified sampling , and cluster sampling .
Using careful research design and sampling procedures can help you avoid sampling bias . Oversampling can be used to correct undercoverage bias .
Some common types of sampling bias include self-selection bias , nonresponse bias , undercoverage bias , survivorship bias , pre-screening or advertising bias, and healthy user bias.
Sampling bias is a threat to external validity – it limits the generalizability of your findings to a broader group of people.
A sampling error is the difference between a population parameter and a sample statistic .
A statistic refers to measures about the sample , while a parameter refers to measures about the population .
Populations are used when a research question requires data from every member of the population. This is usually only feasible when the population is small and easily accessible.
Samples are used to make inferences about populations . Samples are easier to collect data from because they are practical, cost-effective, convenient, and manageable.
There are seven threats to external validity : selection bias , history, experimenter effect, Hawthorne effect , testing effect, aptitude-treatment and situation effect.
The two types of external validity are population validity (whether you can generalize to other groups of people) and ecological validity (whether you can generalize to other situations and settings).
The external validity of a study is the extent to which you can generalize your findings to different groups of people, situations, and measures.
Cross-sectional studies cannot establish a cause-and-effect relationship or analyze behavior over a period of time. To investigate cause and effect, you need to do a longitudinal study or an experimental study .
Cross-sectional studies are less expensive and time-consuming than many other types of study. They can provide useful insights into a population’s characteristics and identify correlations for further research.
Sometimes only cross-sectional data is available for analysis; other times your research question may only require a cross-sectional study to answer it.
Longitudinal studies can last anywhere from weeks to decades, although they tend to be at least a year long.
The 1970 British Cohort Study , which has collected data on the lives of 17,000 Brits since their births in 1970, is one well-known example of a longitudinal study .
Longitudinal studies are better to establish the correct sequence of events, identify changes over time, and provide insight into cause-and-effect relationships, but they also tend to be more expensive and time-consuming than other types of studies.
Longitudinal studies and cross-sectional studies are two different types of research design . In a cross-sectional study you collect data from a population at a specific point in time; in a longitudinal study you repeatedly collect data from the same sample over an extended period of time.
| Longitudinal study | Cross-sectional study |
|---|---|
| observations | Observations at a in time |
| Observes the multiple times | Observes (a “cross-section”) in the population |
| Follows in participants over time | Provides of society at a given point |
There are eight threats to internal validity : history, maturation, instrumentation, testing, selection bias , regression to the mean, social interaction and attrition .
Internal validity is the extent to which you can be confident that a cause-and-effect relationship established in a study cannot be explained by other factors.
In mixed methods research , you use both qualitative and quantitative data collection and analysis methods to answer your research question .
The research methods you use depend on the type of data you need to answer your research question .
- If you want to measure something or test a hypothesis , use quantitative methods . If you want to explore ideas, thoughts and meanings, use qualitative methods .
- If you want to analyze a large amount of readily-available data, use secondary data. If you want data specific to your purposes with control over how it is generated, collect primary data.
- If you want to establish cause-and-effect relationships between variables , use experimental methods. If you want to understand the characteristics of a research subject, use descriptive methods.
A confounding variable , also called a confounder or confounding factor, is a third variable in a study examining a potential cause-and-effect relationship.
A confounding variable is related to both the supposed cause and the supposed effect of the study. It can be difficult to separate the true effect of the independent variable from the effect of the confounding variable.
In your research design , it’s important to identify potential confounding variables and plan how you will reduce their impact.
Discrete and continuous variables are two types of quantitative variables :
- Discrete variables represent counts (e.g. the number of objects in a collection).
- Continuous variables represent measurable amounts (e.g. water volume or weight).
Quantitative variables are any variables where the data represent amounts (e.g. height, weight, or age).
Categorical variables are any variables where the data represent groups. This includes rankings (e.g. finishing places in a race), classifications (e.g. brands of cereal), and binary outcomes (e.g. coin flips).
You need to know what type of variables you are working with to choose the right statistical test for your data and interpret your results .
You can think of independent and dependent variables in terms of cause and effect: an independent variable is the variable you think is the cause , while a dependent variable is the effect .
In an experiment, you manipulate the independent variable and measure the outcome in the dependent variable. For example, in an experiment about the effect of nutrients on crop growth:
- The independent variable is the amount of nutrients added to the crop field.
- The dependent variable is the biomass of the crops at harvest time.
Defining your variables, and deciding how you will manipulate and measure them, is an important part of experimental design .
Experimental design means planning a set of procedures to investigate a relationship between variables . To design a controlled experiment, you need:
- A testable hypothesis
- At least one independent variable that can be precisely manipulated
- At least one dependent variable that can be precisely measured
When designing the experiment, you decide:
- How you will manipulate the variable(s)
- How you will control for any potential confounding variables
- How many subjects or samples will be included in the study
- How subjects will be assigned to treatment levels
Experimental design is essential to the internal and external validity of your experiment.
I nternal validity is the degree of confidence that the causal relationship you are testing is not influenced by other factors or variables .
External validity is the extent to which your results can be generalized to other contexts.
The validity of your experiment depends on your experimental design .
Reliability and validity are both about how well a method measures something:
- Reliability refers to the consistency of a measure (whether the results can be reproduced under the same conditions).
- Validity refers to the accuracy of a measure (whether the results really do represent what they are supposed to measure).
If you are doing experimental research, you also have to consider the internal and external validity of your experiment.
A sample is a subset of individuals from a larger population . Sampling means selecting the group that you will actually collect data from in your research. For example, if you are researching the opinions of students in your university, you could survey a sample of 100 students.
In statistics, sampling allows you to test a hypothesis about the characteristics of a population.
Quantitative research deals with numbers and statistics, while qualitative research deals with words and meanings.
Quantitative methods allow you to systematically measure variables and test hypotheses . Qualitative methods allow you to explore concepts and experiences in more detail.
Methodology refers to the overarching strategy and rationale of your research project . It involves studying the methods used in your field and the theories or principles behind them, in order to develop an approach that matches your objectives.
Methods are the specific tools and procedures you use to collect and analyze data (for example, experiments, surveys , and statistical tests ).
In shorter scientific papers, where the aim is to report the findings of a specific study, you might simply describe what you did in a methods section .
In a longer or more complex research project, such as a thesis or dissertation , you will probably include a methodology section , where you explain your approach to answering the research questions and cite relevant sources to support your choice of methods.
Ask our team
Want to contact us directly? No problem. We are always here for you.
- Email [email protected]
- Start live chat
- Call +1 (510) 822-8066
- WhatsApp +31 20 261 6040

Our team helps students graduate by offering:
- A world-class citation generator
- Plagiarism Checker software powered by Turnitin
- Innovative Citation Checker software
- Professional proofreading services
- Over 300 helpful articles about academic writing, citing sources, plagiarism, and more
Scribbr specializes in editing study-related documents . We proofread:
- PhD dissertations
- Research proposals
- Personal statements
- Admission essays
- Motivation letters
- Reflection papers
- Journal articles
- Capstone projects
Scribbr’s Plagiarism Checker is powered by elements of Turnitin’s Similarity Checker , namely the plagiarism detection software and the Internet Archive and Premium Scholarly Publications content databases .
The add-on AI detector is powered by Scribbr’s proprietary software.
The Scribbr Citation Generator is developed using the open-source Citation Style Language (CSL) project and Frank Bennett’s citeproc-js . It’s the same technology used by dozens of other popular citation tools, including Mendeley and Zotero.
You can find all the citation styles and locales used in the Scribbr Citation Generator in our publicly accessible repository on Github .
Hypothesis testing
When interpreting research findings, researchers need to assess whether these findings may have occurred by chance. Hypothesis testing is a systematic procedure for deciding whether the results of a research study support a particular theory which applies to a population.
Hypothesis testing uses sample data to evaluate a hypothesis about a population . A hypothesis test assesses how unusual the result is, whether it is reasonable chance variation or whether the result is too extreme to be considered chance variation.
Basic concepts
- Null and research hypothesis
Probability value and types of errors
Effect size and statistical significance.
- Directional and non-directional hypotheses
Null and research hypotheses
To carry out statistical hypothesis testing, research and null hypothesis are employed:
- Research hypothesis : this is the hypothesis that you propose, also known as the alternative hypothesis HA. For example:
H A: There is a relationship between intelligence and academic results.
H A: First year university students obtain higher grades after an intensive Statistics course.
H A; Males and females differ in their levels of stress.
- The null hypothesis (H o ) is the opposite of the research hypothesis and expresses that there is no relationship between variables, or no differences between groups; for example:
H o : There is no relationship between intelligence and academic results.
H o: First year university students do not obtain higher grades after an intensive Statistics course.
H o : Males and females will not differ in their levels of stress.
The purpose of hypothesis testing is to test whether the null hypothesis (there is no difference, no effect) can be rejected or approved. If the null hypothesis is rejected, then the research hypothesis can be accepted. If the null hypothesis is accepted, then the research hypothesis is rejected.
In hypothesis testing, a value is set to assess whether the null hypothesis is accepted or rejected and whether the result is statistically significant:
- A critical value is the score the sample would need to decide against the null hypothesis.
- A probability value is used to assess the significance of the statistical test. If the null hypothesis is rejected, then the alternative to the null hypothesis is accepted.
The probability value, or p value , is the probability of an outcome or research result given the hypothesis. Usually, the probability value is set at 0.05: the null hypothesis will be rejected if the probability value of the statistical test is less than 0.05. There are two types of errors associated to hypothesis testing:
- What if we observe a difference – but none exists in the population?
- What if we do not find a difference – but it does exist in the population?
These situations are known as Type I and Type II errors:
- Type I Error: is the type of error that involves the rejection of a null hypothesis that is actually true (i.e. a false positive).
- Type II Error: is the type of error that occurs when we do not reject a null hypothesis that is false (i.e. a false negative).

These errors cannot be eliminated; they can be minimised, but minimising one type of error will increase the probability of committing the other type.
The probability of making a Type I error depends on the criterion that is used to accept or reject the null hypothesis: the p value or alpha level . The alpha is set by the researcher, usually at .05, and is the chance the researcher is willing to take and still claim the significance of the statistical test.). Choosing a smaller alpha level will decrease the likelihood of committing Type I error.
For example, p<0.05 indicates that there are 5 chances in 100 that the difference observed was really due to sampling error – that 5% of the time a Type I error will occur or that there is a 5% chance that the opposite of the null hypothesis is actually true.
With a p<0.01, there will be 1 chance in 100 that the difference observed was really due to sampling error – 1% of the time a Type I error will occur.
The p level is specified before analysing the data. If the data analysis results in a probability value below the α (alpha) level, then the null hypothesis is rejected; if it is not, then the null hypothesis is not rejected.
When the null hypothesis is rejected, the effect is said to be statistically significant. However, statistical significance does not mean that the effect is important.
A result can be statistically significant, but the effect size may be small. Finding that an effect is significant does not provide information about how large or important the effect is. In fact, a small effect can be statistically significant if the sample size is large enough.
Information about the effect size, or magnitude of the result, is given by the statistical test. For example, the strength of the correlation between two variables is given by the coefficient of correlation, which varies from 0 to 1.
- A hypothesis that states that students who attend an intensive Statistics course will obtain higher grades than students who do not attend would be directional.
- A non-directional hypothesis states that there will be differences between students who attend do or don’t attend an intensive Statistics course, but we don’t know what group will get higher grades than the other. The hypothesis only states that they will obtain different grades.
The hypothesis testing process
The hypothesis testing process can be divided into five steps:
- Restate the research question as research hypothesis and a null hypothesis about the populations.
- Determine the characteristics of the comparison distribution.
- Determine the cut off sample score on the comparison distribution at which the null hypothesis should be rejected.
- Determine your sample’s score on the comparison distribution.
- Decide whether to reject the null hypothesis.
This example illustrates how these five steps can be applied to text a hypothesis:
- Let’s say that you conduct an experiment to investigate whether students’ ability to memorise words improves after they have consumed caffeine.
- The experiment involves two groups of students: the first group consumes caffeine; the second group drinks water.
- Both groups complete a memory test.
- A randomly selected individual in the experimental condition (i.e. the group that consumes caffeine) has a score of 27 on the memory test. The scores of people in general on this memory measure are normally distributed with a mean of 19 and a standard deviation of 4.
- The researcher predicts an effect (differences in memory for these groups) but does not predict a particular direction of effect (i.e. which group will have higher scores on the memory test). Using the 5% significance level, what should you conclude?
Step 1 : There are two populations of interest.
Population 1: People who go through the experimental procedure (drink coffee).
Population 2: People who do not go through the experimental procedure (drink water).
- Research hypothesis: Population 1 will score differently from Population 2.
- Null hypothesis: There will be no difference between the two populations.
Step 2 : We know that the characteristics of the comparison distribution (student population) are:
Population M = 19, Population SD= 4, normally distributed. These are the mean and standard deviation of the distribution of scores on the memory test for the general student population.
Step 3 : For a two-tailed test (the direction of the effect is not specified) at the 5% level (25% at each tail), the cut off sample scores are +1.96 and -1.99.
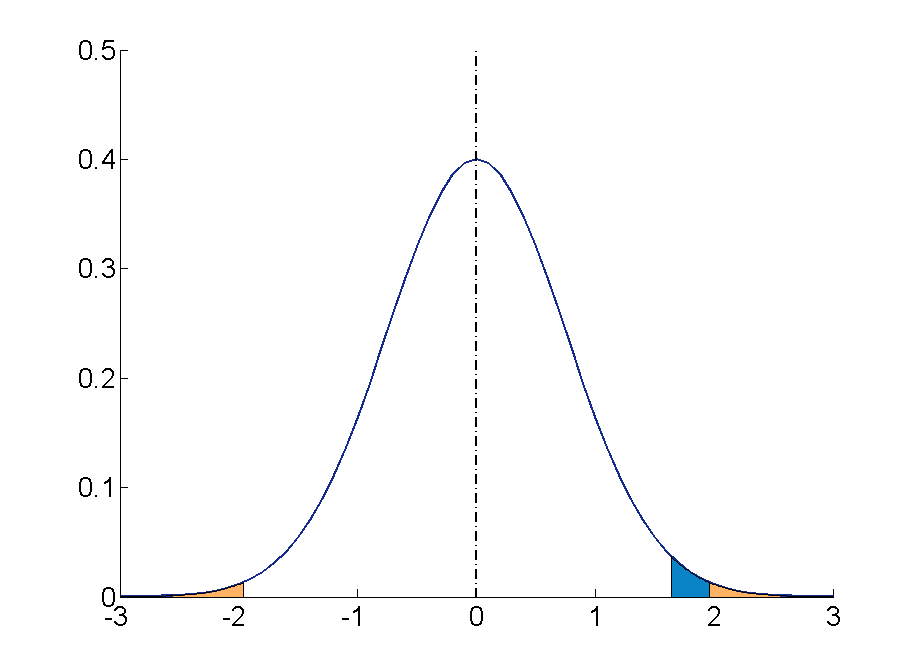
Step 4 : Your sample score of 27 needs to be converted into a Z value. To calculate Z = (27-19)/4= 2 ( check the Converting into Z scores section if you need to review how to do this process)
Step 5 : A ‘Z’ score of 2 is more extreme than the cut off Z of +1.96 (see figure above). The result is significant and, thus, the null hypothesis is rejected.
You can find more examples here:
- Statistics (RMIT Learning Lab)
Some commonly used statistical techniques
Correlation analysis, multiple regression.
- Analysis of variance
Chi-square test for independence
Correlation analysis explores the association between variables . The purpose of correlational analysis is to discover whether there is a relationship between variables, which is unlikely to occur by sampling error. The null hypothesis is that there is no relationship between the two variables. Correlation analysis provides information about:
- The direction of the relationship: positive or negative- given by the sign of the correlation coefficient.
- The strength or magnitude of the relationship between the two variables- given by the correlation coefficient, which varies from 0 (no relationship between the variables) to 1 (perfect relationship between the variables).
- Direction of the relationship.
A positive correlation indicates that high scores on one variable are associated with high scores on the other variable; low scores on one variable are associated with low scores on the second variable . For instance, in the figure below, higher scores on negative affect are associated with higher scores on perceived stress

A negative correlation indicates that high scores on one variable are associated with low scores on the other variable. The graph shows that a person who scores high on perceived stress will probably score low on mastery. The slope of the graph is downwards- as it moves to the right. In the figure below, higher scores on mastery are associated with lower scores on perceived stress.

Fig 2. Negative correlation between two variables. Adapted from Pallant, J. (2013). SPSS survival manual: A step by step guide to data analysis using IBM SPSS (5th ed.). Sydney, Melbourne, Auckland, London: Allen & Unwin
2. The strength or magnitude of the relationship
The strength of a linear relationship between two variables is measured by a statistic known as the correlation coefficient , which varies from 0 to -1, and from 0 to +1. There are several correlation coefficients; the most widely used are Pearson’s r and Spearman’s rho. The strength of the relationship is interpreted as follows:
- Small/weak: r= .10 to .29
- Medium/moderate: r= .30 to .49
- Large/strong: r= .50 to 1
It is important to note that correlation analysis does not imply causality. Correlation is used to explore the association between variables, however, it does not indicate that one variable causes the other. The correlation between two variables could be due to the fact that a third variable is affecting the two variables.
Multiple regression is an extension of correlation analysis. Multiple regression is used to explore the relationship between one dependent variable and a number of independent variables or predictors . The purpose of a multiple regression model is to predict values of a dependent variable based on the values of the independent variables or predictors. For example, a researcher may be interested in predicting students’ academic success (e.g. grades) based on a number of predictors, for example, hours spent studying, satisfaction with studies, relationships with peers and lecturers.
A multiple regression model can be conducted using statistical software (e.g. SPSS). The software will test the significance of the model (i.e. does the model significantly predicts scores on the dependent variable using the independent variables introduced in the model?), how much of the variance in the dependent variable is explained by the model, and the individual contribution of each independent variable.
Example of multiple regression model

From Dunn et al. (2014). Influence of academic self-regulation, critical thinking, and age on online graduate students' academic help-seeking.
In this model, help-seeking is the dependent variable; there are three independent variables or predictors. The coefficients show the direction (positive or negative) and magnitude of the relationship between each predictor and the dependent variable. The model was statistically significant and predicted 13.5% of the variance in help-seeking.
t-Tests are employed to compare the mean score on some continuous variable for two groups . The null hypothesis to be tested is there are no differences between the two groups (e.g. anxiety scores for males and females are not different).
If the significance value of the t-test is equal or less than .05, there is a significant difference in the mean scores on the variable of interest for each of the two groups. If the value is above .05, there is no significant difference between the groups.
t-Tests can be employed to compare the mean scores of two different groups (independent-samples t-test ) or to compare the same group of people on two different occasions ( paired-samples t-test) .
In addition to assessing whether the difference between the two groups is statistically significant, it is important to consider the effect size or magnitude of the difference between the groups. The effect size is given by partial eta squared (proportion of variance of the dependent variable that is explained by the independent variable) and Cohen’s d (difference between groups in terms of standard deviation units).
In this example, an independent samples t-test was conducted to assess whether males and females differ in their perceived anxiety levels. The significance of the test is .004. Since this value is less than .05, we can conclude that there is a statistically significant difference between males and females in their perceived anxiety levels.

Whilst t-tests compare the mean score on one variable for two groups, analysis of variance is used to test more than two groups . Following the previous example, analysis of variance would be employed to test whether there are differences in anxiety scores for students from different disciplines.
Analysis of variance compare the variance (variability in scores) between the different groups (believed to be due to the independent variable) with the variability within each group (believed to be due to chance). An F ratio is calculated; a large F ratio indicates that there is more variability between the groups (caused by the independent variable) than there is within each group (error term). A significant F test indicates that we can reject the null hypothesis; i.e. that there is no difference between the groups.
Again, effect size statistics such as Cohen’s d and eta squared are employed to assess the magnitude of the differences between groups.
In this example, we examined differences in perceived anxiety between students from different disciplines. The results of the Anova Test show that the significance level is .005. Since this value is below .05, we can conclude that there are statistically significant differences between students from different disciplines in their perceived anxiety levels.

Chi-square test for independence is used to explore the relationship between two categorical variables. Each variable can have two or more categories.
For example, a researcher can use a Chi-square test for independence to assess the relationship between study disciplines (e.g. Psychology, Business, Education,…) and help-seeking behaviour (Yes/No). The test compares the observed frequencies of cases with the values that would be expected if there was no association between the two variables of interest. A statistically significant Chi-square test indicates that the two variables are associated (e.g. Psychology students are more likely to seek help than Business students). The effect size is assessed using effect size statistics: Phi and Cramer’s V .
In this example, a Chi-square test was conducted to assess whether males and females differ in their help-seeking behaviour (Yes/No). The crosstabulation table shows the percentage of males of females who sought/didn't seek help. The table 'Chi square tests' shows the significance of the test (Pearson Chi square asymp sig: .482). Since this value is above .05, we conclude that there is no statistically significant difference between males and females in their help-seeking behaviour.

- << Previous: Probability and the normal distribution
- Next: Statistical techniques >>
- Open access
- Published: 28 August 2024
Conservation of wild food plants from wood uses: evidence supporting the protection hypothesis in Northeastern Brazil
- Roberta de Almeida Caetano 1 , 3 ,
- Emilly Luize Gomes da Silva 3 ,
- Luis Fernando Colin-Nolasco 2 , 3 ,
- Rafael Ricardo Vasconcelos da Silva 1 , 3 ,
- Adriana Rosa Carvalho 4 &
- Patrícia Muniz de Medeiros 1 , 3
Journal of Ethnobiology and Ethnomedicine volume 20 , Article number: 81 ( 2024 ) Cite this article
Metrics details
The interplay between different uses of woody plants remains underexplored, obscuring our understanding of how a plant’s value for one purpose might shield it from other, more harmful uses. This study examines the protection hypothesis by determining if food uses can protect woody plants (trees and shrubs) from wood uses. We approached the hypothesis from two distinct possibilities: (1) the protective effect is proportional to the intensity of a species’ use for food purposes, and (2) the protective effect only targets key species for food purposes.
The research was conducted in a rural community within “Restinga” vegetation in Northeast Brazil. To identify important food species for both consumption and income (key species) and the collection areas where they naturally occur, we conducted participatory workshops. We then carried out a floristic survey in these areas to identify woody species that coexist with the key species. Voucher specimens were used to create a field herbarium, which, along with photographs served as visual stimuli during the checklist interviews. The interviewees used a five-point Likert scale to evaluate the species in terms of perceived wood quality, perceived availability, and use for food and wood purposes. To test our hypothesis, we used Cumulative Link Mixed Models (CLMMs), with the wood use as the response variable, food use, perceived availability and perceived quality as the explanatory variables and the interviewee as a random effect. We performed the same model replacing food use for key species food use (a binary variable that had value 1 when the information concerned a key species with actual food use, and value 0 when the information did not concern a key species or concerned a key species that was not used for food purposes).
Consistent with our hypothesis, we identified a protective effect of food use on wood use. However, this effect is not directly proportional to the species’ food use, but is confined to plants with considerable domestic food importance. Perceived availability and quality emerged as notable predictors for wood uses.
We advocate for biocultural conservation strategies that enhance the food value of plants for their safeguarding, coupled with measures for non-edible woody species under higher use-pressure.
A growing body of research points to the potential effects of chronic anthropogenic disturbances leading to the gradual extinction of local species and alterations in vegetation structure [ 1 , 2 ]. Among these disturbances, the impact of forest product utilization has been highlighted, demonstrating that while wood use is crucial for local communities, especially in developing countries, it often results in more pronounced impacts on plant populations [ 3 , 4 ].
While wood uses exerts considerable pressure on plant resources, in some socio-ecological contexts, the extraction of non-timber forest products (NTFP) can also be harmful to plant populations [ 5 , 6 ]. For example, the intensive harvesting of foliage and bark from tree species [ 6 ]. Nevertheless, the extraction of NTFPs, particularly the harvesting of wild fruits, generally has a lesser impact on forest structure and ecosystem functions than other uses [ 7 ]. Moreover, the consumption of NTFPs fulfills multiple roles, frequently underpinning rural livelihoods and local economies, aiding food security, fostering trade, and preserving cultural traditions and knowledge [ 8 ]. These species are also excellent sources of micro and macronutrients [ 9 , 10 ].
Hence, some researchers argue that discouraging the commercialization of wild food plants may adversely affect the subsistence and income of local populations, potentially leading to greater reliance on other forest resources with more harmful consequences than food collection itself [ 11 ]. One of these harmful consequences is deforestation, caused using wood for firewood and the construction of fences and houses, which require substantial amounts of green wood. Conversely, the commercial value of NTFPs, coupled with the opportunity for income generation, may incentivize conservation efforts among local communities for the forests that supply these resources [ 12 ].
Since the 1990s, investigations into the sustainability of food plant use have sought to determine the impact on species populations without conclusively addressing whether such use confers protective benefits. In contrast, research on plant domestication supports the notion that significant food value may lead to conservation practices, such as tolerance, protection, and promotion [ 13 ]. Plants with desirable traits may be maintained during deforestation or other disturbances, promoted through distribution and dispersal, and specifically safeguarded against competitors and herbivory [ 13 ].
However, the extent to which a plant’s significance for one use can shield it from more destructive applications, Footnote 1 namely the interaction effects among different utilization types, remains underexamined. This gap hinders our comprehension of protective dynamics in socio-ecological systems and their economic benefits for humans. Such insights are vital for shaping biocultural conservation frameworks that recognize the multifaceted advantages of maintaining cultural practices intertwined with biodiversity.
It is conceivable that certain NTFP uses, including for food, may exert a protective effect against more damaging activities such as wood uses. Although overharvesting of fruits has been shown to affect the regeneration of wild fruit trees adversely [ 14 , 15 ], food use is typically seen as specialized, with minimal impact on plant populations, whereas wood uses is often deemed generalist, posing broader threats [ 3 ].
The classification of plant uses as specialized or generalist may vary depending on the social-ecological context. In the context of several South American communities, specialized uses are defined by a narrower range of suitable plants meeting specific requirements, with the specialization premise reinforced by observations that plant availability exerts little to no influence on such uses [ 16 , 17 ]. In contrast, generalist uses accommodate a broader spectrum of species, with the most utilized often being the most accessible, as with many wood uses practices [ 18 ]. For example, the use of wood for firewood (fuel category) is often classified as generalist because, although factors like durability and high calorific leads to a species’ preference, potentially all woody species would be useful for this purpose [ 19 , 20 ]. As fuelwood use often requires large amounts of wood and/or frequent collection, it commonly targets the most abundant species [ 21 ]. Despite the fact that the uses in the construction (e.g., house and fence construction) and technology (e.g., tools, kitchen utensils) categories often require quality wood and are considered less generalist uses compared to the fuel category [ 3 ], they are still more generalist than the food use.
For woody species with edible fruits, some requirements such as nutritional value and flavor [ 22 , 23 ] are needed, and a much smaller proportion of species meet these requirements. Thus, in general, regardless of how generalist the use of wood is, any tree can meet some wood application (fuel, construction, technology), but not every tree has edible fruits. Although quality may also be an important predictor of plant importance for generalist uses [ 20 ], the generalist nature of wood use is supported by studies investigating the apparency (availability) hypothesis, which posits a correlation between environmental availability and species utilization [ 18 , 24 , 25 ]. Therefore, for generalist applications, alternatives may spare certain species for specialized uses, such as food, where fewer species can act as substitutes.
Silva et al. [ 26 ] were the first to test the protection hypothesis. They analyzed woody plants from the Caatinga used domestically for medicinal and wood purposes to evaluate whether the importance of medicinal use (specialized use) had an impact on wood use (generalist use). Their findings revealed a modest yet significant medicinal use effect on wood uses, providing supportive evidence for the hypothesis as plants of greater medicinal value saw less wood utilization. Moreover, Silva et al suggested that the protective effect could be more pronounced in species with high medicinal importance.
The use of plants for food is also considered a likely candidate for conferring protective effects against wood uses. Wild food plants are often crucial for providing essential nutrients or for supplementing diets, playing a vital role in ensuring food security and offering economic benefits through the trade of these resources. Given food use’s specialized nature, dietary importance, and economic potential, there is a presumption that communities may prefer to preserve these plants from irreversible harm, such as wood uses. For the latter, alternative species are available due to the generalist nature of wood use.
In this context, we investigate the protection hypothesis from two distinct possibilities. We hypothesize that food uses (specialized) protect plants from wood uses (generalist). We examined: (1) whether the protective effect is proportional to the intensity of a species’ use for food purposes, and (2) if a protective effect only targets key species for food purposes. Here, ‘key species’ refer to wild food plants of high regional importance, which are well-established within the local community for both consumption and income generation.
This study is the inaugural inquiry into the protection hypothesis concerning the protective effect stemming from food use. Moreover, unlike Silva et al. [ 26 ], our study incorporates the commercial relevance of woody plants (trees and shrubs), providing income for the local population. Methodologically, we refine hypothesis testing by employing the checklist-interview technique [ 27 ] to boost respondent recall, ensuring all associated uses (food and wood) are considered.
Materials and methods
The research was carried out in a rural community within the coastal “Restinga” vegetation of Piaçabuçu, situated on the southern coast of Alagoas state. Piaçabuçu spans an area of 243.686 km 2 , housing a population of 15,908 individuals [ 28 ]. It features a tropical ‘As’ climate in the Köppen and Geiger classification, with an average annual temperature of 25.3 °C and an annual rainfall average of 1283 mm [ 29 ]. Notably, the municipality is designated with two sustainable use Conservation Units: the federally instituted Piaçabuçu Environmental Protection Area, established in 1983, and the state-sanctioned Marituba do Peixe Environmental Protection Area, created in 1988.
The Marituba do Peixe Environmental Protection Area spans 18,556 hectares and extends over portions of the Alagoan municipalities of Piaçabuçu (45%), Feliz Deserto (43%), and Penedo (6%) [ 30 ]. This area boasts diverse vegetation, including native “Restinga”, “Várzea”, and other forest formations [ 30 ]. Within the Indirect Influence Area of Marituba do Peixe Environmental Protection Area lies the village of Retiro (depicted in Fig. 1 ), which was the focal point for the ethnobiological segment of this study.

Geographic Location of the Retiro Community in the Municipality of Piaçabuçu-Alagoas, Brazil
The Retiro community is structured with a residents’ association and a family farmers’ association. It is equipped with a primary healthcare unit and a municipal elementary school. The predominant faith among residents is Christianity, represented by two Catholic and two evangelical churches. Currently, the community comprises approximately 288 families, a decrease of 81 families since before the COVID-19 pandemic, as reported by Gomes et al. [ 31 ]. This discrepancy may be partly due to some families not being documented, a requirement for health unit registration.
Retiro was selected for this study due to the local reliance on plant resources for both food and wood. The community’s economy is significantly driven by the extraction and commercialization of wild food plant fruits [ 31 ], along with shrimp and fish [ 32 ]. Wood resource extraction for personal use and commerce, particularly firewood, charcoal, and materials for fencing, is also prevalent. These resources are marketed through open markets or direct orders in Piaçabuçu and Penedo, whereas wood products are solely distributed by order.
Firewood is the primary cooking fuel in the community, though some households use both cooking gas and firewood. Meals are typically prepared on traditional clay or makeshift brick stoves. Firewood also serves in roasting shrimp and baking cakes from rice straw, a common bait for shrimp in local fishing gear known as “cóvu.”
Architecturally, many “taipa” houses (rammed earth) are present within the community, often serving as dwellings for individuals from other regions staying temporarily in the area.
Ethical and legal aspects of the research
This research project received approval from the Research Ethics Committee by Federal University of Alagoas (UFAL), No. 1998673, securing authorization for studies involving human participants as per the stipulations of National Health Council Resolution 466/2012. Additionally, scientific activities involving the collection and transport of botanical specimens within the Marituba do Peixe Environmental Protection Area were duly registered with Chico Mendes Institute for Biodiversity Conservation/Biodiversity Authorization and Information System (ICMBio/SISBIO), No. 87,112-1.
To ensure ethical compliance, all community members aged 18 or over—to whom the objectives of the research were explained—and who consented to participate, were asked to provide a signature or thumbprint on the Informed Consent Form (ICF), as well as on the image use authorization form.
Data collection
Data collection was carried out in three distinct phases: a participatory workshop, a forest inventory, and checklist-interviews.
1st data collection stage: participatory workshops
Participatory workshops with the residents of the Retiro community aimed to identify significant wild food plant species for consumption and commercial use, as well as their harvesting locations. These workshops were facilitated by local leaders and a researcher from the Laboratory of Biocultural Ecology, Conservation, and Evolution (LECEB), who had previously interviewed community members. The residents were recruited through door-to-door invitations on the day before the workshop was held.
In the inaugural participatory workshop, participants were asked to list the wild plants they harvested for sale or consumption. They recorded the common names on a piece of cardboard, selecting eleven for further discussion. We then asked which of those species were most important for sale and consumption within the community, and they ranked the top five in order of importance . Additionally, the workshop served to note wood resources tied to food plants and their utilization for consumption and commerce within the community.
Thirteen women and three men, ranging in age from 31 to 82, contributed to this first workshop. While all were identified as gatherers, some also engaged in agriculture and fishing. A follow-up workshop sought to enrich this data with contributions from another set of gatherers ( n = 17), including eight newcomers. This session, comprising thirteen women and four men from the same age bracket, validated the initial findings regarding species and harvesting sites.
Participants utilized a detailed satellite image from Google Earth to denote areas frequented for food and wood collection. An overlay of transparent acetate allowed them to make corrections directly on the map.
After pinpointing these areas, we selected those most frequented for the harvesting of both food plants and wood, prioritizing locations where the ranked key species were prevalent. Among the listed key species— Myrciaria floribunda (H. West ex Willd.) O. Berg (“cambuí”), Genipa americana L. (“jenipapo”), Psidium guineense Sw. (“araçá”), Spondias mombin L . (“cajá”), and Tamarindus indica L. (“tamarino”)—only the first three were represented in the forest surveys due to their presence in forests. Although S. mombin and T. indica are also key species in the region, the former occurred at the edges of roads or in backyards, while the last is found in fenced area with wire, with reports of increasing cultivation for pulp production by large landowners. Therefore, our study only included three out of the five key species, as well as the species that co-occur with them.
Three sites were thus chosen for the forest inventory: two with a natural predominance of key species and one characterized by a more generalized distribution of various plant species, including those bearing edible fruits.
Gomes et al. [ 31 ], the research design we adopted gave precedence to examining species that occurred alongside the key species; consequently, not all food and wood plants were included in our scope. Notably, Schinus terebinthifolia Raddi, while not a key species within Retiro, is a significant commercial species in the community and the most important commercial plant in neighboring areas, such as the Fazenda Paraíso settlement [ 31 ].
2nd data collection stage: forest inventory and field herbarium
The research included a forest inventory as part of a larger investigation of our research group into plant resource utilization within the region, although ecological data is not part of this study. For the purposes of this study, the forest inventory was only used to identify and collect species that co-occur with the key species. Without the forest inventory, we would have no baseline for the field herbarium (notebook with exsiccates of the species used as a visual stimulus during the application of the checklist-interview technique), since we would not know which woody plants co-occur with our key species. Therefore, although it is not our purpose to present results on forest structure and composition, the inventory was fundamental for the research. Exsiccates of these species were included in the field herbarium based on their abundance, as detailed below.
The sites selected for the inventory were privately owned yet accessible to local gatherers. Two of these sites fell within the Marituba do Peixe Environmental Protection Area boundaries in Piaçabuçu, while the third was in the municipality of Penedo, not included in this protection area but still proximal to the community.
We established five permanent plots, each measuring 50 × 20 m, and further divided these into 50 smaller subplots of 10 × 10 m situated within the primary native vegetation gathering sites designated during the workshops. This amounted to 0.5 hectares per area, with a total of 1.5 hectares surveyed across all areas.
During the inventory, we collected at least three reproductive samples of each plant species within the plots for identification and to assemble a field herbarium for use in subsequent interviews. Certain species, commonly referred to as “ingá” and “pau d’arco”, lacked fertile material at the time of collection, leading us to categorize them as ethnospecies for the purposes of this study. Consequently, in our identification records, we referred to these simply as “ingá” and “pau d’arco”, acknowledging that these common names might represent multiple botanical species. Furthermore, the ethnospecies “cambuí”, although biologically uniform—belonging to the species Myrciaria floribunda (H. West ex Willd.) O. Berg—was recognized by some residents as having different ethnovarieties—a distinction not universally acknowledged. In our analysis, we accounted for each mention of “cambuí” by participants, even though the general data summary did not differentiate between ethnovarieties. For instance, if interviewee A identified two types of “cambuí” (Yellow and Red) and Interviewee B referred to one (a general “cambuí”), we recorded two entries for A and one for B in our database.
For the field herbarium, we mounted exsiccates from species with more than 15 individuals in the surveyed areas onto duplex paper of dimensions 42 × 29.7 cm and stored them in folders of matching size. The herbarium included 24 species in total and 2 taxa that were treated as ethnospecies.
Photography of each species was conducted in situ, capturing images that emphasized the plants’ distinguishing features: overall appearance, flowers and/or fruits, branches, and stems. These photographs were compiled into folders on a tablet, which was employed to display the images during interviews. Both the exsiccates and the photo folders were numerically coded to correspond with the identifiers on the interview forms, ensuring that interviewees were unaware of the plant names and assisting the interviewer.
The botanical collection phase commenced in November 2021 and concluded in April 2023, an extended period due to intermittent interruptions from COVID-19 peaks and flooding that hindered fieldwork.
A local guide with extensive knowledge of the vegetation provided assistance for all fieldwork involving local vegetation access. We adhered to standard botanical collection protocols, and the exsiccate samples were deposited at the Dárdano de Andrade Lima herbarium of the Agronomic Institute of Pernambuco.
3rd data collection stage: checklist interview
Before commencing the interviews (third stage), we mapped all Retiro households in May 2023. This mapping was imperative for sample size calculation due to the absence of a census record; the health unit’s data was limited to registered families. We determined that household heads (one per household) aged 18 or older present during our visit would be interviewed. Considering that some individuals reside in the community only for short periods, we established an inclusion criterion that only families living in the area for more than one year would be eligible for the study.
We ascertained the number of residences, including both occupied and vacant, to be 361, initially yielding a sample size of 187 residences based on a 95% confidence level and a 5% margin of error. Subsequently, we conducted a simple random selection.
As every house in the community was recorded, including unoccupied ones, some selected residences were vacant. Additionally, given the research’s focus on potentially harmful wood resource use within the Environmental Protection Area, some families were reluctant to participate. Therefore, from the 187 chosen residences, we could only conduct interviews in 81 interviews of them. To overcome refusals, flood-affected houses, and temporary residents, additional draws were made.
After all draws, we excluded unoccupied houses ( n = 82), residences on flood-impacted streets ( n = 12), households temporary inhabitants ( n = 18) and refusals or unavailability ( n = 74) from the sample. After three unsuccessful attempts to locate a household head, we inferred their non-participation.
A notable number of individuals opted out of the study, a figure aligned with expectations for wood use research in protected areas, mirroring findings from Medeiros et al. [ 3 ]. The considerable number of unoccupied houses in the community can be primarily attributed to their use as summer residences by individuals from nearby municipalities, taking advantage of the community’s closeness to the beach. Additionally, a number of these houses are situated in areas susceptible to flooding during the rainy season, which also contributes to their vacancy.
The final sample consisted of 115 individuals—81 women and 34 men. Interviews were conducted from May to July 2023. During interviews, we applied the checklist-interview technique [ 27 ] to ensure uniform visual stimuli across all informants, enhancing recall of all plant-associated uses.
Interviewees were shown photos of each species and queried on whether they recognized the species. Affirmative responses led to further questions on the plant’s name, its uses (food and wood), whether the interviewee actually used the species, parts utilized, commercial harvesting, and collection and sale sites. For recognized plants, a Likert scale rated: perceived availability (only for those interviewees that often frequent vegetation areas), wood quality by use category (fuel, construction, technology), domestic use for wood and food, and commercial use.
In the fuel category, wood is used as firewood or charcoal for generating energy, cooking food, and heating water or spaces. The construction category encompasses the use of wood in structures for territorial demarcation, building homes, shelters for animals, and storage of items (e.g., fences, posts, house lines, rafters, battens, doors, windows). Technology refers to the use of wood in manipulated items that are not intended for demarcating spaces, such as tool handles, benches, tables, chairs, canoes, and oars, among others [ 33 ].
The ratings and responses in Likert scale are presented in Fig. 2 .

Information collected using a Likert scale on the variables considered in this study
This classification facilitated the synthesis of scoring for perceived wood quality, allowing individuals to assign ratings by category rather than for each specific use. If a participant identified a plant as useful for wood but did not personally use it, we probed for the reasons behind this choice. We also asked if there were any of the mentioned plants that, despite being good for wood uses, the interviewee did not harvested. These questions were included to gather information on self-conscious protective behaviors associated with the food use of woody species.
Only for the ethnospecies “ingá” and “pau d’arco”, instead of showing the photos and exsiccate, we asked directly if the person knew them for food or wood uses. In case of a positive answer, we asked the same cycle of questions conducted for the other species. This was done because we did not obtain sufficient fertile material for the taxonomic identification of all species of “ingá” and “pau d’arco” during the various collection events.
Additionally, we gathered socio-economic data from all informants through structured interviews, including gender, age, occupation, income, place of origin, education, and length of residence. This information enabled the characterization of the socio-economic profile of the interviewees.
In this sense, the primary livelihoods include gathering, particularly collecting edible fruits, as well as pension, fishing, and agriculture, with some engaging in multiple occupations. A variety of other professions are represented to a lesser extent. The age of interviewees spans ages 18 to 82, with an average age of 48.14 years.
Most interviewees are literate (76.65%) are literate, of whom 73.91% have completed or partially completed basic education, and 1.74% have higher education qualifications.
The number of people occupying the residences ranges from one to seven residents. However, the majority of houses are occupied by: two or three residents (29.57%), followed by one or four resident(s) (15.65%).
Household incomes show substantial variation: (a) under one minimum wage (28.70%), (b) exactly one minimum wage (14.78%), (c) one and a half to two minimum wages (41.74%), (d) up to three minimum wages (13.04%), with a minority exceeding five minimum wages (1.74%).
Data analysis
For statistical analyses, we removed from the database any instances where species were identified for food purposes but not for wood purposes, as the focus of the research was on criteria for selecting wood plants. Consequently, non-wood plants were disregarded. Similarly, we excluded data from individuals who did not frequent forest environments to ensure that our information on species availability came from realistic assessments.
Our response variable, domestic wood use, was ordinal, as depicted in Fig. 3 . Therefore, we utilized Cumulative Link Mixed Models (CLMMs), incorporating the interviewee as a random effect to account for the non-independence of information from the same individual. The CLMMs were executed using the clmm function from the R package ordinal .

Widespread species model and key species-based model with their variables and respective measures
To evaluate the stability of our models and check for multicollinearity, we used the omcdiag function from the mctest package in R. We determined an absence of multicollinearity if none or at most one of the six indicators were positive. To circumvent multicollinearity, we constructed two models. The first model, termed the widespread protection model, assigned domestic and commercial food use values on a 5-point Likert scale based on reported usage intensity. For the key species-based protection model, food use was a binary variable: it took the value of 1 if the mention included the use of a key species, and 0 if the mention involved a key species only known but not used, or non-key species, regardless of usage.
Model selection was based on the most parsimonious option, as indicated by the lowest Akaike Information Criterion corrected for small sample sizes (AICc). We interpreted a ΔAICc (difference from the lowest AICc) of less than 2 as substantial support for the model’s inclusion among the best set of models, following Burnham and Anderson [ 34 ]. Following model selection, we computed a model average, which considered the average beta of all variables within the parsimonious models. Since the variables were standardized via z-standardization, we compared the relative effect sizes of all variables.
The variable ‘commercial wood use’ was not included in the models due to its limited mentions ( n = 5) within the community and only six citations of species that are commercially traded for wood, exclusive of domestic use.
In addition to the explanatory variables related to food use, both models incorporated control variables for availability and quality, as previously identified in the literature as predictors of wood use [ 20 , 24 , 25 ]. Our quality indicator was the maximum perceived quality. It was determined by the highest Likert scale quality rating given by an interviewee for a species across the three categories of wood use. For example, if, for a given species, values of 3, 4, and 5 were assigned by an interviewee to the categories of construction, technology, and fuelwood, respectively, the maximum perceived quality would be recorded as 5.
To analyze the qualitative data on protection behaviors, we examined the responses, categorized them, and used descriptive statistics.
Wood and food uses: general aspects
All plants were recognized to varying extents by the interviewees. The most recognized species/ethnospecies were: Genipa americana L. (“jenipapo"), Inga spp. (“ingá”), Myrciaria floribunda (H. West ex Willd.) O. Berg (“cambuí”), Manilkara salzmannii (A.DC.) H.J.Lam (Massaranduba), Psidium guineense Sw. (“araçá”), Mouriri sp. (“cruirí"), and Bignoniaceae spp. (“pau d’arco”), with recognition rates of 56.5% or higher during interviews. The first five species achieved high recognition levels, exceeding 80%. Notably, G. americana , M. floribunda , and P. guineeense were identified as key species during the workshops. A comprehensive list of all species included in the checklist, along with their recognition and citation frequencies, is presented in Table 1 .
Over half of the species on the checklist (57.69% or n = 15) were recognized for both food and wood uses. Within the three categories of wood use addressed in this study, fuelwood (37.89%) and construction (36.93%) had the highest citation percentages. Technology accounted for only 25.18% of wood citations. Within the fuelwood category, firewood led with the highest percentage (62.82%) of citations relative to the total uses in the category, followed by charcoal (37.18%). The construction category comprised 25 wood uses, with over half (50.55%) the citations pertaining to fences, and the remainder divided among uses such as line (11.98%) and rafter (10.74%). The technology category included 67 wood uses, featuring lower usage percentages compared to the other categories. Uses such as hoe handle (11.92%) and hoe shaft (10.30%) were the only applications exceeding 10% of citations in relation to the total uses within this category. All wood uses attributed to the species are detailed in Supplementary Material 1 .
Widespread protection model
In the widespread protection model, domestic and commercial food use did not significantly influence domestic wood use when controlling for availability and quality variables (Fig. 4 ). This means that there is no linear relationship between food use and domestic wood use.

Impact of Predictor Parameters (quality, availability, domestic food use, commercial food use, domestic use of key species, and commercial use of key species) on domestic wood utilization of wild edible plants. Left: widespread protection model. Right: key species-based protection model. The central circles indicate the median coefficient estimates of the associations, and the horizontal lines delineate the 95% credibility intervals. The parameter coefficient estimates are plotted along the x -axis, while the predictor levels are represented on the y -axis. The vertical line intersecting the zero point on the x -axis (indicating no effect) facilitates comparison of the sizes of positive, negative, and null effect coefficients. In the parameter level grouping, non-overlapping horizontal bars denote significant differences. Horizontal bars intersecting the zero line on the x -axis signify a non-significant effect
Quality and availability were significant predictors of domestic wood use in the model. This suggests that, within the local context, there is a tendency to use woody plants for wood purposes based on their higher quality and greater availability.
Key species-based protection model
We observed a pronounced protective effect on key species, where the domestic use variable was more influential than both perceived availability and wood quality (see Fig. 4 ). However, the variable indicating commercial use did not significantly affect the use of wood for domestic purposes.
Within the model focusing on key species, both availability and wood quality (considered as control variables) had a significant impact on wood use. Consequently, our findings imply the existence of a threshold level of importance for the protective effect of food use on wood uses. This indicates that only those plants with substantial domestic food importance are shielded from being utilized for wood by the local population. The complete statistical results are available in the Supplementary Material 2 .
Evidence of protection based on qualitative data
When inquiring whether individuals refrained from using any of the recognized plants for wood purposes, despite acknowledging their suitability for such use, we gathered responses that support a tendency to protect certain species with dual edible and wood functions. The key species identified during the participatory workshop as significant to the local community, and which garnered substantial recognition in the checklist, were notably prominent in this context.
Out of the 60 respondents to this question, 37 reported no restraint in using plants suitable for wood purposes. Among the 23 participants that chose not to collect certain plants, 12 indicated not collecting species had both edible and wood uses.
Of all mentions of plants with both edible and wood applications, seven pertained to key species (as shown in Table 2 ). The primary rationale for sparing these species from wood harvesting, or only using their dry branches, is their provision of edible fruits valued within the community. This rationale is illustrated by the testimonies concerning P. guineense , G. americana , and M. floribunda .
Manilkara salzmannii though having a limited role in commerce, garners mixed views on its suitability for consumption within the community. Nonetheless, six interviewees mentioned the species, with two specifically expressing their intent to conserve it from being used for wood purposes: (1) “I don’t take it, thinking about the fruits and the future. I don’t like to take it (wood) while it’s still green, I only pick up the dry branches that have fallen on the ground.” (2) "Because it’s a plant that bears fruit, and it doesn’t sprout again if you cut it."
Despite M. salzmannii not being designated as a key species during the participatory workshop, it nonetheless received noteworthy acknowledgment in the checklist-interview. This suggests that M. salzmannii may possess a certain degree of importance for food-related uses within the community.
In our widespread protection model, neither commercial nor domestic food use significantly explains domestic wood use. By contrast, in the key species-based protection model, domestic use emerges as the primary explanatory variable. In both models, perceived availability and quality significantly explain wood use, with quality being more important than availability.
Consistent with our hypothesis, we identify a protective effect of food use on wood use. This effect is not directly proportionate to the food use of the species but is confined to plants with considerable domestic food importance. Research conducted in the Brazilian Caatinga region, which initially tested the protection hypothesis using medicinal (specialized) and wood (generalist) use, suggested this possibility [ 26 ]. Although they observed a modest yet significant linear trend supporting the hypothesis, the authors graphically demonstrated that the protective effect intensified specifically among highly valued medicinal plants. This study furnishes statistical substantiation for what was previously inferred graphically.
Given that the protective effect is selective for key species, it indicates that merely having intermediate or low food importance is insufficient for wild food plants to evade wood use. Protection is afforded only to those species recognized as highly important. Indeed, key species not only receive high acknowledgment in the checklist (> 80%) but are also extensively consumed and increasingly traded within the community, in forms such as fresh fruit, juice pulp, and in the manufacture of alcoholic beverages, ice pops, among other products. Literature highlights that elevating the value of non-timber forest products for local populations acts as an incentive for forest species conservation [ 12 , 35 ].
Our findings suggest that protection is predominantly correlated with domestic consumption. The domestic use of non-timber forest products can be a way for poorer local populations to save money [ 36 ], as is the case with wild fruits that can replace commercially purchased foods. Although wild food plants serve only as supplementary food resources within the community—with staple crops like rice and beans constituting the primary plant food intake—the importance of key wild food plants likely motivates the observed protection behaviors. Moreover, the emotional connection with natural environments resulting from direct experiences with nature can lead to pro-environmental behaviors (actions that reduce negative environmental impacts or enhance the sustainable use of natural resources) or intentions to engage in nature protection, as environmental psychology research has demonstrated [ 37 , 38 ]. For example, Hinds and Sparks [ 39 ] found that individuals who grew up in rural areas tend to report more positive emotional connections, a stronger sense of identification, and more intense behavioral intentions regarding engagement with nature compared to those who were raised in urban environments. In this sense, the protective behaviors associated with the domestic consumption of key species may be related to the emotional bond linked to positive emotions built over a lifetime and across generations.
The low adherence to protective behaviors reported in interviews (see Evidence of protection based on qualitative data) could stem from various factors. Not all protective actions are necessarily conscious. Additionally, individuals may inadvertently omit mention of such behaviors in response to indirect inquiries like those posed in our study. Furthermore, protection may not be universally practiced within the community, and while the pressure to use wood from wild food plants may not be entirely eliminated, it could be reduced by fewer community members intensively exploiting key food plants for wood purposes.
Wood quality and species availability are significant determinants of wood use. It appears that, aside from key food species—whose utilization for wood is limited due to their value as food—other species are more likely to be used for wood purposes when they offer better trade-offs between availability and quality. Most studies that investigate the drivers of wood use tend to analyze quality or availability indicators separately, rather than in combination. These studies have found that either quality or availability can influence wood use [ 20 , 24 , 25 ].
Studies that consider multiple predictors of wood use have yielded divergent results. While availability seems to be a consistent predictor across different contexts, quality may or may not be a determinant of wood use [ 19 , 40 ].
In various social-ecological contexts, research has indicated that trade-offs between multiple variables act as drivers of plant resource use [ 19 , 41 ]. However, these trade-offs are often considered within a single use-category (e.g., the trade-off between quality and availability to explain fuelwood use). Therefore, the evidence of protection underscores the necessity of considering interactions between use-categories when evaluating criteria for plant resource selection (Fig. 5 ).

Hypothetical example of a trade-off between availability and quality explaining fuelwood use. In a simplified scenario where these are the only predictors of plant use within the fuelwood category, the most utilized species would be those exhibiting the highest trade-offs between availability and quality (represented by the blue dots in the right and left graphs). When considering the interaction with the food use-category under the key-species based protection model, the use of wood species with low to intermediate food importance would be proportional to the trade-off between quality and availability (graph on the right). However, for species that are considered key food plants (indicated by the dark green dot), their utilization for fuelwood would be less than what is predicted by their quality and availability alone
Recommendations for conservation strategies for plant species
The practical implication of a protective effect that acts solely on species of high food importance is that species recognized as having intermediate or lower importance remain unprotected, as do wood species without any associated food use. Moreover, if only a few species are highly valued for food, they might experience intense pressure from their use as food or be protected at the expense of other species. Therefore, we recommend that conservation strategies take into account the interactions between food and wood use-categories, i.e., the effects of one category on the other.
For species with intermediate or lower food importance, popularization strategies could prove beneficial to enhance their perceived value. Programs aimed at popularizing such species are crucial, as they may significantly contribute to food and nutritional security, while their use as food might concurrently protect them from being exploited for wood. These programs should establish incentives that encourage community members to use these resources sustainably. However, the effectiveness of this approach should be continuously monitored, as if importance is the primary factor driving protective behaviors, integrating other wild food plants into the set of key species may prove challenging.
Although the commercial importance of key species did not lead to protection in this study, the inclusion of certain species in local markets could also positively influence domestic use. Thus, popularization strategies could extend beyond local communities, emphasizing the importance of these plants for diet diversification and their potential nutritional value to generate demand for products sourced from local communities. One method to achieve this is through marketing campaigns that raise awareness about the significance of these plants in local markets and across social and conventional media platforms [ 42 ].
However, it is crucial to approach the popularization of highly important food species with caution to prevent the oversimplification of the plant community, as observed with açaí ( Euterpe oleracea Mart.), where management practices have simplified estuarine communities in the Amazon Rainforest [ 43 ].
For wood species that lack an associated food use, conservation strategies must be implemented to mitigate the pressure on their exploitation. Considering that the primary wood uses in the community are for fuel (firewood) and construction (fencing), conservation efforts should be tailored to these applications. Firewood is the most commonly cited use in the Retiro community, and due to its characteristics regarding short replenishment time and large volume of wood used, it poses a significant threat to species conservation, depending on the collection method (green or dry). For people with greater social vulnerability, firewood is an important resource for cooking. To address this, we recommend the use of efficient wood stoves. These stoves, through their structural configuration, reduce cooking time and, consequently, the daily volume of wood used and deforestation compared to traditional stoves [ 44 ].
Although there is controversy in the literature regarding the long-term economic costs and benefits of improved stove use in developing countries [ 45 ] and their efficiency[ 46 ], several studies have shown significant reductions in firewood use with the adoption of this technology [ 44 , 47 , 48 ]. For instance, a study based on an improved stove intervention in the Chalaco District, Northern Andes of Peru, recorded a 46% reduction in firewood consumption (approximately 650 kg of firewood per household throughout the rainy season) among households that properly used improved stoves during winter [ 48 ]. Similarly, Bensch and Peters [ 47 ], who evaluated the impact of these stoves in rural Senegal through a randomized clinical trial, found a total 31% reduction in firewood consumption over one week. Additionally, the use of efficient stoves can contribute to a higher quality of life for users by reducing smoke from wood combustion, which can cause respiratory diseases [ 49 ]. However, for successful implementation of efficient stoves, besides local community interest, factors influencing long-term adoption, such as maintenance costs, need to be considered.
An alternative to replacing firewood use is increased investment in public policies that ensure access to Liquefied Petroleum Gas (LPG). While families receiving the gas voucher through the federal government program (Bolsa Família) still use a mix of LPG and firewood in the community, education, health, and human well-being initiatives, combined with these public policies, may have a better response in the community during the transition from firewood to LPG use. This is especially important considering that the use of firewood, for the most part, spans generations. The same applies to the transition from traditional or makeshift brick stoves to efficient stoves.
To reduce the use of species employed in the construction of dead fences—where trunks and branches of woody plants are cut green for use—we recommend a gradual replacement with species used as living fences, which are kept alive. This strategy has been indicated as effective as it represents a gene bank of native species and contributes to the maintenance of these species [ 50 ]. “rompe gibão” ( Phyllanthus sp.) and “cruirí” ( Mouriri sp.) were mentioned by some interviewees as species used for living fences, and “peroba” ( Tabebuia elliptica (DC.) Sandwith) was mentioned as having the ability for its stake to remain green in a humid environment. They are considered hard and resistant woods (“fixe”) by the interviewees who recognized them on the checklist. These species could potentially be used for this purpose, but they need to be evaluated in terms of their characteristics and ecological status.
Finally, although our results admit that there is a protective effect on species with high food importance (key species) regarding wood uses, it is necessary to investigate the ecological status of these species to assess whether harvesting is being done sustainably and if overexploitation of these species is not occurring, as has been identified in other studies with non-timber forest products [ 5 , 14 , 15 ].
Recommendations for future ethnobiological studies
Some challenges for testing the protection hypothesis in future studies include:
Studies should account for the interactions not only between two use-categories but also among all use-categories associated with the plant species. For instance, a plant might be protected from wood uses not solely due to its food or medicinal value, but because it serves multiple purposes. Thus, protection may only become apparent when evaluating the full spectrum of plant use dynamics.
Gender and age variables ought to be incorporated into the tests of the protection hypothesis, given that individuals of different ages or genders may protect plants for varied purposes.
Studies could delve into the affective aspects of protection, as these may inspire individuals to spare certain species from wood uses due to resources that evoke positive affective memories. For example, a fruit that was greatly cherished during one’s childhood or that constituted the main sustenance for a person’s family might be protected. While affective reasons are personal, common patterns may surface, especially among individuals with similar cultural or community backgrounds who may share collective memories.
It is necessary to further investigate the influence of social organization on the protective behavior of local peoples toward wild food species. For instance, in contexts where there are associations of fruit gatherers or cooperatives, protective behavior may increase compared to rural communities where social organization is poorly established or absent. Alternatively, protective behavior may be directed on an individual basis.
Research designs should enhance the methodological approach concerning qualitative evidence for protection. The questioning should be crafted to elicit precise responses without leading the participant, yet still addressing the core issue effectively. Our study utilized indirect questions that may not have fully captured our main objective. We propose that future research adopting discourse analysis techniques (underpinned by multiple theoretical frameworks) would yield valuable insights.
Limitations of this study
For two groups of plants treated in this study as ethnospecies ( “ pau d’arco” and “ingá”), we were unable to elucidate their taxonomies despite our efforts. Our results suggest that these ethnospecies are not under the protective effect of food use, and the lack of botanical identification complicates the targeting of conservation strategies, especially for future studies in this region. Although we do not know the quantity and specific species, we suspect they are at risk of threat due to logging, especially for “pau d’arco” (Bignoniaceae spp.). At least two species of “pau d’arco” are listed in the International Union for Conservation of Nature Red List with concerning ecological statuses: Handroanthus impetiginosus (Mart. ex DC.) Mattos (“pau d’arco rosa”) listed as near-threatened and Handroanthus serratifolius (Vahl) S. Grose (“pau d’arco amarelo”), listed as endangered [ 51 ]. Both were assessed for the list in 2020. As respondents mentioned three types of “ pau d’arco” (“roxo”, “amarelo”, and “branco"), it is possible that species of this genus are included. Through botanical identification, we identified that a plant known in the community as “peroba” is the species Tabebuia elliptica (DC.) Sandwith (“pau d’arco branco”), specified on the Red List with a status of least concern. This makes this area an interesting occurrence for this plant group. In light of this, we acknowledge this limitation in our study and invite other researchers specializing in these plant groups to direct research efforts in this region and clarify the taxonomy of these species.
Our data on the perceived quality of wood were collected from a single Likert scale value considering all wood uses of the plant reported by the interviewee for each wood use category, instead of considering the quality for each reported wood use in each category. This optimized data collection. However, the heterogeneous nature of categories such as technology, where the wood quality of the plant can vary significantly among uses (e.g., tools, furniture, boat), can be challenging for the interviewee to assign a single rating considering various distinct uses. This may have biased our results with very generic perceptions of species quality. Given that wood use is diverse, future studies could consider a more meticulous design, such as focusing on the most relevant uses within each category in the local community and assessing their perceived quality independently.
In this study, we did not monitor the collection activity, so we were unable to differentiate between wood collected from fallen stems and branches (with less impact on plants) and wood removed directly from the plants (with greater impact). However, this does not compromise our results, as the aim was to assess general usage behaviors, and other studies have already recorded the predominance of cutting practices, whether for dry or green, live or dead wood [ 3 , 21 ].
The inclusion of species for the composition of the checklist interview was based on their availability in areas of co-occurrence with key species. Although greater availability of species is a potential indicator of higher use, it is not universal. There may be species in the sampled vegetation areas that are less available precisely because they are under greater use pressure or due to other environmental or intrinsic factors not considered in this study. Therefore, it is essential to also consider ecological approaches in research to have an overall assessment of the impact of such uses on the plant community structure, even if the focus of the research is on the most important plant species.
Overall, we found that there is a protective effect that acts primarily on plant species of high food importance (key species), rather than proportionally to the importance of the species . Consequently, we encourage future studies to test the protection hypothesis within various socio-environmental contexts and we suggest considering two distinct possibilities: generalized protection and protection targeted at key species.
In light of our findings, we advise that species demonstrating an overlap between food and wood uses, yet possessing intermediate or lower food importance should be prioritized in popularization strategies to raise their significance. Moreover, species solely used for timber, which do not benefit from food-related protection, also require attention through biocultural conservation strategies. Given that the protective effect is limited to a select number of plant species, these species warrant further ecological investigation to determine their conservation status within their natural habitats, to identify whether they face increased pressure from their use as food, and to ascertain if their prominence is leading to a reduction in plant diversity.
Availability of data and materials
Data are provided within the manuscript or supplementary information files.
Here, we consider destructive applications, those that compromise the individual plant and its population in the short term. For example, a shallow cut or a substantial cut of the branches of a tree, which can hinder its growth. In contrast to the fruit, which is collected, and the individual plant remains intact, it can cause damage to the population in the long term.
Abbreviations
Cumulative link mixed models
Non-timber forest products
Universidade Federal de Alagoas (Federal University of Alagoas)
Sistema de Autorização e Informação em Biodiversidade (Biodiversity Authorization and Information System)
Instituto Chico Mendes de Conservação da Biodiversidade (Chico Mendes Institute for Biodiversity Conservation)
Informed consent form
Laboratory of Biocultural Ecology, Conservation, and Evolution
Akaike information criterion
Liquefied Petroleum Gas
Ribeiro EMS, Arroyo-Rodríguez V, Santos BA, Tabarelli M, Leal IR. Chronic anthropogenic disturbance drives the biological impoverishment of the Brazilian Caatinga vegetation. J Appl Ecol. 2015;52(3):611–20.
Article Google Scholar
Ribeiro DA, de Macedo DG, de Oliveira LGS, de Oliveira Santos M, de Almeida BV, Macedo JGF, et al. Conservation priorities for medicinal woody species in a cerrado area in the Chapada do Araripe, northeastern Brazil. Environ Dev Sustain. 2019;21(1):61–77.
Medeiros PM, De Almeida ALS, Da Silva TC, De Albuquerque UP. Pressure indicators of wood resource use in an atlantic forest area, Northeastern Brazil. Environ Manag. 2011;47(3):410–24.
Ros-Tonen MAF. The role of non-timber forest products in sustainable tropical forest management. Holz Roh Werkstoff. 2000;58(3):196–201.
Brokamp G, Borgtoft Pedersen H, Montúfar R, Jácome J, Weigend M, Balslev H. Productivity and management of Phytelephas aequatorialis (Arecaceae) in Ecuador. Ann Appl Biol. 2014;164(2):257–69.
Gaoue OG, Ticktin T. Patterns of harvesting foliage and bark from the multipurpose tree Khaya senegalensis in Benin: variation across ecological regions and its impacts on population structure. Biol Conserv. 2007;137(3):424–36.
Stanley D, Voeks R, Short L. Is non-timber forest product harvest sustainable in the less developed world? A systematic review of the recent economic and ecological literature. Ethnobiol Conserv. 2012;2012(1):1–39.
Google Scholar
Shackleton CM. Non-timber forest products in livelihoods. In: Ecological Sustainability for Non-timber Forest Products. Milton Park: Routledge; 2015. p. 12–30.
Chapter Google Scholar
Jacob MCM, de Medeiros MFA, Albuquerque UP. Biodiverse food plants in the semiarid region of Brazil have unknown potential: A systematic review. PLoS ONE. 2020;15(5):e0230936.
Article CAS PubMed PubMed Central Google Scholar
Bacchetta L, Visioli F, Cappelli G, Caruso E, Martin G, Nemeth E, et al. A manifesto for the valorization of wild edible plants. J Ethnopharmacol. 2016;191:180–7. https://doi.org/10.1016/j.jep.2016.05.061 .
Article PubMed Google Scholar
Delang CO. The role of wild food plants in poverty alleviation and biodiversity conservation in tropical countries. Prog Dev Stud. 2006;6:275–86.
Lowore J. Understanding the livelihood implications of reliable honey trade in the miombo Woodlands in Zambia. Front For Glob Change. 2020;3(March):1–16.
Casas A, Caballero J, Mapes C, Zárate S. Manejo de la vegetación, domesticación de plantas y origen de la agricultura en Mesoamérica. Bot Sci. 2017;47(61):31.
Almeida A. Avaliação ecológica do extrativismo do pequi (Caryocar coriaceum Wittm.) na Floresta Nacional do Araripe, Ceará: informações para um plano de uso sustentável. Tese de Doutorado. 2014;164.
Avocèvou-Ayisso C, Sinsin B, Adégbidi A, Dossou G, Van Damme P. Sustainable use of non-timber forest products: impact of fruit harvesting on Pentadesma butyracea regeneration and financial analysis of its products trade in Benin. For Ecol Manag. 2009;257(9):1930–8.
Ribeiro JPO, Carvalho TKN, da Silva Ribeiro JE, de Sousa RF, de Farias Lima JR, de Oliveira RS, et al. Can ecological apparency explain the use of plant species in the semi-arid depression of Northeastern Brazil? Acta Bot Brasilica. 2014;28(3):476–83.
Soldati GT, de Medeiros PM, Duque-Brasil R, Coelho FMG, Albuquerque UP. How do people select plants for use? Matching the ecological apparency hypothesis with optimal foraging theory. Environ Dev Sustain. 2017;19(6):2143–61.
Gonçalves PHS, Albuquerque UP, De Medeiros PM. The most commonly available woody plant species are the most useful for human populations: A meta-analysis. Ecol Appl. 2016;26(7):2238–53.
Hora JSL, Feitosa IS, Albuquerque UP, Ramos MA, Medeiros PM. Drivers of species’ use for fuelwood purposes: a case study in the Brazilian semiarid region. J Arid Environ. 2021;185:104324.
Cardoso MB, Ladio AH, Dutrus SM, Lozada M. Preference and calorific value of fuelwood species in rural populations in northwestern Patagonia. Biomass Bioenergy. 2015;81(October):514–20. https://doi.org/10.1016/j.biombioe.2015.08.003 .
Article CAS Google Scholar
Gonçalves PHS, Medeiros PMD, Albuquerque UP. Effects of domestic wood collection on tree community structure in a human-dominated seasonally dry tropical forest. J Arid Environ. 2021;193:104554.
Cruz MP, Medeiros PM, Combariza IS, Peroni N, Albuquerque UP. “I eat the manofê so it is not forgotten”: local perceptions and consumption of native wild edible plants from seasonal dry forests in Brazil. J Ethnobiol Ethnomed. 2014;10(1):1–11.
do Nascimento VT, de Lucena RFP, Maciel MIS, de Albuquerque UP. Knowledge and use of wild food plants in areas of dry seasonal forests in Brazil. Ecol Food Nutr. 2013;52(4):317–43.
Lucena RFP, Araújo EDL, De Albuquerque UP. Does the local availability of woody Caatinga plants (Northeastern Brazil) explain their use value? Econ Bot. 2007;61(4):347–61.
Lucena RFP, Lucena CM, Araújo EL, Alves ÂGC, de Albuquerque UP. Conservation priorities of useful plants from different techniques of collection and analysis of ethnobotanical data. An Acad Bras Cienc. 2013;85(1):169–86.
da Silva JPC, Gonçalves PH, Albuquerque UP, da Silva RRV, de Medeiros PM. Can medicinal use protect plant species from wood uses? Evidence from Northeastern Brazil. J Environ Manag. 2021;279:111800.
Alexiades MN, Sheldon JWS. Selected guidelines for ethnobotanical research: a field manual. New York: New York Botanical Garden; 1996.
IBGE. Instituto Brasileiro de Geografia e Estatísticas. Cidades [Internet]. 2022 [cited 2023 Aug 19]. Available from: http://cidades.ibge.gov.br/download/mapa_e_municipios.php?lang=&uf=al
CLIMATE-DATA.ORG. Climate data, 2020. < https://pt.climate-data.org/america-do-sul/brasil .
IMA. Instituto do Meio Ambiente. APA Marituba do Peixe [Internet]. 2023 [cited 2023 May 1]. Available from: https://dados.al.gov.br/catalogo/dataset/apa-da-marituba-do-peixe
Gomes DL, Ferreira RPDS, Santos ÉMDC, Da SRRV, De MPM. Local criteria for the selection of wild food plants for consumption and sale in Alagoasm, Brazil. Ethnobiol Conserv. 2020;9(May):1–15.
CAS Google Scholar
Cabral SAS, de Azevedo Júnior SM, de Larrazábal ME. Abundância sazonal de aves migratórias na Área de Proteção Ambiental de Piaçabuçu, Alagoas, Brasil. Rev Bras Zool. 2006;23(3):865–9.
Ramos MA, Medeiros PM, Albuquerque UP. Methods and techniques applied to ethnobotanical studies of timber resources. In: de Albuquerque UP, Cunha LVFC, editors. Methods and techniques in ethnobiology and ethnoecology. New York: Springer; 2014. p. 15–23.
Burnham KP, Anderson DR. Multimodel inference: Understanding AIC and BIC in model selection. Sociol Methods Res. 2004;33(2):261–304.
Evans, M.I. (1993). Conservation by commercialization. In: Hladik CM, Hladik A, Linares OF, Pagezy H, Semple A, Hadley M, editors. Tropical forests, people and food: biocultural interactions and applications to development, vol. 13. 1993. Pp. 815–822.
Shackleton CM, Garekae H, Sardeshpande M, Sinasson Sanni G, Twine WC. Non-timber forest products as poverty traps: Fact or fiction? For Policy Econ. 2024;158:103114. https://doi.org/10.1016/j.forpol.2023.103114 .
Collado S, Staats H, Corraliza JA. Experiencing nature in children’s summer camps: affective, cognitive and behavioural consequences. J Environ Psychol. 2013;33:37–44. https://doi.org/10.1016/j.jenvp.2012.08.002 .
Cheng JCH, Monroe MC. Connection to nature: children’s affective attitude toward nature. Environ Behav. 2012;44(1):31–49.
Hinds J, Sparks P. Engaging with the natural environment: the role of affective connection and identity. J Environ Psychol. 2008;28(2):109–20.
Marquez-Reynoso MI, Ramírez-Marcial N, Cortina-Villar S, Ochoa-Gaona S. Purpose, preferences and fuel value index of trees used for firewood in El Ocote Biosphere Reserve, Chiapas, Mexico. Biomass Bioenergy. 2017;100:1–9. https://doi.org/10.1016/j.biombioe.2017.03.006 .
Bahru T, Kidane B, Tolessa A. Prioritization and selection of high fuelwood producing plant species at Boset District, Central Ethiopia: an ethnobotanical approach. J Ethnobiol Ethnomed. 2021;17(1):1–15. https://doi.org/10.1186/s13002-021-00474-9 .
Barbosa DM, dos Santos GMC, Gomes DL, Santos EMD, da Silva RRV, de Medeiros PM. Does the label “unconventional food plant” influence food acceptance by potential consumers? A first approach. Heliyon. 2021;7(4):E0673.
Freitas MAB, Magalhães JLL, Carmona CP, Arroyo-Rodríguez V, Vieira ICG, Tabarelli M. Intensification of açaí palm management largely impoverishes tree assemblages in the Amazon estuarine forest. Biol Conserv. 2021;261:109251.
Nazmul Alam SM, Chowdhury SJ. Improved earthen stoves in coastal areas in Bangladesh: economic, ecological and socio-cultural evaluation. Biomass Bioenergy. 2010;34(12):1954–60. https://doi.org/10.1016/j.biombioe.2010.08.007 .
Jeuland MA, Pattanayak SK. Benefits and costs of improved cookstoves: assessing the implications of variability in health, forest and climate impacts. PLoS ONE. 2012;7(2):e30338.
Hanna R, Esther D, Greenstone M. Up in smoke: the influence of household behavior on the long-run impact of improved cooking stoves. Am Econ J Econ Policy 2016;8(1):80–114. http://www.jstor.org/stable/247391 . Am Econ J Econ Policy ;2012;66:37–9.
Bensch G, Peters J. A recipe for success? Randomized free distribution of improved cooking stoves in Senegal. SSRN Electron J 2012.
Agurto AM. Improved cooking stoves and firewood consumption: quasi-experimental evidence from the Northern Peruvian Andes. Ecol Econ. 2013;89:135–43. https://doi.org/10.1016/j.ecolecon.2013.02.010 .
Alam SMN, Chowdhury SJ, Begum A, Rahman M. Effect of improved earthen stoves: improving health for rural communities in Bangladesh. Energy Sustain Dev. 2006;10(3):46–53. https://doi.org/10.1016/S0973-0826(08)60543-8 .
Nascimento VT, Sousa LG, Alves AGC, Araújo EL, Albuquerque UP. Rural fences in agricultural landscapes and their conservation role in an area of caatinga (dryland vegetation) in northeast Brazil. Environ Dev Sustain. 2009;11(5):1005–29.
IUCN. The red list of threatened species (IUCN). Version 2022-2. 2022 [cited 2022 Oct 24]. Available from: https://www.iucnredlist.org
Download references
Acknowledgements
We extend our gratitude to the residents of the Retiro community for their support in this research, particularly to Mr. José Antônio and Mrs. Maria das Dores, who warmly welcomed us and facilitated our requests within the community. Our appreciation also goes to Dr. Marcos Sobral, a Myrtaceae expert, who graciously identified the species of this family in our study. Likewise, we express our thanks to the researcher from the Agronomic Institute of Pernambuco, Maria Olivia de Oliveira Cano, for her receptiveness and efficiency in assisting us during all visits throughout the COVID-19 pandemic. We also extend our heartfelt thanks to the members of the Laboratory of Biocultural Ecology, Conservation and Evolution for their support in fieldwork activities.
This study was funded by the Brazilian Biodiversity Fund—FUNBIO, the HUMANIZE and Eurofins Foundations (FUNBIO—Fellowships Conserving the Future, granted to RAC, No. 025/2022), the National Council for Scientific and Technological Development (CNPq) (Doctoral fellowship for RAC, No 141873/2020-5 and productivity grant to PMM, No. 304866/2020-2) and the Research Support Foundation of the State of Alagoas (FAPEAL) (Granted to PMM, No. APQ2022021000027).
Author information
Authors and affiliations.
Postgraduate Program in Biological Diversity and Conservation in the Tropics, Federal University of Alagoas, Avenida Lourival Melo Mota, S/N, Tabuleiro do Martins, Maceió, AL, 57072-900, Brazil
Roberta de Almeida Caetano, Rafael Ricardo Vasconcelos da Silva & Patrícia Muniz de Medeiros
Postgraduate Program in Ethnobiology and Nature Conservation (PPGEtno), Federal Rural University of Pernambuco, Rua Dom Manoel de Medeiros, S/N – Dois Irmãos, Recife, PE, 52171-900, Brazil
Luis Fernando Colin-Nolasco
Laboratory of Biocultural Ecology, Conservation and Evolution (LECEB), Campus of Engineering and Agricultural Sciences (CECA), BR-104, Km 85, S/N, Rio Largo, AL, 57100-000, Brazil
Roberta de Almeida Caetano, Emilly Luize Gomes da Silva, Luis Fernando Colin-Nolasco, Rafael Ricardo Vasconcelos da Silva & Patrícia Muniz de Medeiros
Department of Ecology, Federal University of Rio Grande Do Norte, University Campus S/N, Lagoa Nova, Natal, RN, 59098-970, Brazil
Adriana Rosa Carvalho
You can also search for this author in PubMed Google Scholar
Contributions
RAC—Conceptualization; Investigation; Methodology; Writing—original draft and final. ELGS—Writing—revision and editing. LFCN—Writing—revision and editing; Data compilation; RRVS and ARC—Supervision; Writing—revision and editing. PMM—Conceptualization; Methodology; Supervision and Writing—final version and editing. All authors read and approved the final version.
Corresponding authors
Correspondence to Roberta de Almeida Caetano or Patrícia Muniz de Medeiros .
Ethics declarations
Ethics approval and consent to participate.
This study was approved by the Ethics Committee in research by Federal University of Alagoas (UFAL), No. 1998673. Furthermore, all participants previously signed the Informed Consent Form (ICF).
Consent for publication
Not applicable.
Competing interests
I declare that the authors have no competing interests as defined by BMC, or other interests that might be perceived to influence the results and/or discussion reported in this paper.
Additional information
Publisher's note.
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Supplementary material 1., supplementary material 2., rights and permissions.
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/ .
Reprints and permissions
About this article
Cite this article.
Caetano, R.d., da Silva, E.L.G., Colin-Nolasco, L.F. et al. Conservation of wild food plants from wood uses: evidence supporting the protection hypothesis in Northeastern Brazil. J Ethnobiology Ethnomedicine 20 , 81 (2024). https://doi.org/10.1186/s13002-024-00719-3
Download citation
Received : 04 May 2024
Accepted : 02 August 2024
Published : 28 August 2024
DOI : https://doi.org/10.1186/s13002-024-00719-3
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Conservation through use
- Ethnobiology
- Traditional management
- Wild edible plants
Journal of Ethnobiology and Ethnomedicine
ISSN: 1746-4269
- General enquiries: [email protected]
IMAGES
VIDEO
COMMENTS
Example 1: Biology. Hypothesis tests are often used in biology to determine whether some new treatment, fertilizer, pesticide, chemical, etc. causes increased growth, stamina, immunity, etc. in plants or animals. For example, suppose a biologist believes that a certain fertilizer will cause plants to grow more during a one-month period than ...
It is most often used by scientists to test specific predictions, called hypotheses, that arise from theories. There are 5 main steps in hypothesis testing: State your research hypothesis as a null hypothesis and alternate hypothesis (H o) and (H a or H 1). Collect data in a way designed to test the hypothesis. Perform an appropriate ...
Medical providers often rely on evidence-based medicine to guide decision-making in practice. Often a research hypothesis is tested with results provided, typically with p values, confidence intervals, or both. Additionally, statistical or research significance is estimated or determined by the investigators. Unfortunately, healthcare providers may have different comfort levels in interpreting ...
Mean Population IQ: 100. Step 1: Using the value of the mean population IQ, we establish the null hypothesis as 100. Step 2: State that the alternative hypothesis is greater than 100. Step 3: State the alpha level as 0.05 or 5%. Step 4: Find the rejection region area (given by your alpha level above) from the z-table.
Hypothesis testing is a scientific method used for making a decision and drawing conclusions by using a statistical approach. It is used to suggest new ideas by testing theories to know whether or not the sample data supports research. A research hypothesis is a predictive statement that has to be tested using scientific methods that join an ...
HYPOTHESIS TESTING. A clinical trial begins with an assumption or belief, and then proceeds to either prove or disprove this assumption. In statistical terms, this belief or assumption is known as a hypothesis. Counterintuitively, what the researcher believes in (or is trying to prove) is called the "alternate" hypothesis, and the opposite ...
A hypothesis test is a procedure used in statistics to assess whether a particular viewpoint is likely to be true. They follow a strict protocol, and they generate a 'p-value', on the basis of which a decision is made about the truth of the hypothesis under investigation.All of the routine statistical 'tests' used in research—t-tests, χ 2 tests, Mann-Whitney tests, etc.—are all ...
Formulate the Hypotheses: Write your research hypotheses as a null hypothesis (H 0) and an alternative hypothesis (H A).; Data Collection: Gather data specifically aimed at testing the hypothesis.; Conduct A Test: Use a suitable statistical test to analyze your data.; Make a Decision: Based on the statistical test results, decide whether to reject the null hypothesis or fail to reject it.
S.3 Hypothesis Testing. In reviewing hypothesis tests, we start first with the general idea. Then, we keep returning to the basic procedures of hypothesis testing, each time adding a little more detail. The general idea of hypothesis testing involves: Making an initial assumption. Collecting evidence (data).
The above image shows a table with some of the most common test statistics and their corresponding tests or models.. A statistical hypothesis test is a method of statistical inference used to decide whether the data sufficiently supports a particular hypothesis. A statistical hypothesis test typically involves a calculation of a test statistic.Then a decision is made, either by comparing the ...
In layman's terms, hypothesis testing is used to establish whether a research hypothesis extends beyond those individuals examined in a single study. Another example could be taking a sample of 200 breast cancer sufferers in order to test a new drug that is designed to eradicate this type of cancer.
Abstract. Statistical hypothesis testing is common in research, but a conventional understanding sometimes leads to mistaken application and misinterpretation. The logic of hypothesis testing presented in this article provides for a clearer understanding, application, and interpretation. Key conclusions are that (a) the magnitude of an estimate ...
Hypothesis testing is a crucial procedure to perform when you want to make inferences about a population using a random sample. These inferences include estimating population properties such as the mean, differences between means, proportions, and the relationships between variables. This post provides an overview of statistical hypothesis testing.
The first step in testing hypotheses is the transformation of the research question into a null hypothesis, H 0, and an alternative hypothesis, H A. 6 The null and alternative hypotheses are concise statements, usually in mathematical form, of 2 possible versions of "truth" about the relationship between the predictor of interest and the outcome in the population.
To determine whether a discovery or relationship is statistically significant, hypothesis testing uses a z-test. It usually checks to see if two means are the same (the null hypothesis). ... Hypothesis testing provides evidence to support or reject a hypothesis, but it cannot confirm the absolute truth of the research question.
Alternative Hypothesis (H1) or the research hypothesis states that there is a relationship between two variables (where one variable affects the other). The alternative hypothesis is the main driving force for hypothesis testing. ... Test statistic - Test statistic is a numerical summary of a data set that can be used to perform hypothesis ...
4. Photo by Anna Nekrashevich from Pexels. Hypothesis testing is a common statistical tool used in research and data science to support the certainty of findings. The aim of testing is to answer how probable an apparent effect is detected by chance given a random data sample. This article provides a detailed explanation of the key concepts in ...
Hypothesis-testing (Quantitative hypothesis-testing research) - Quantitative research uses deductive reasoning. - This involves the formation of a hypothesis, collection of data in the investigation of the problem, analysis and use of the data from the investigation, and drawing of conclusions to validate or nullify the hypotheses.
P-Values. The p-value of a hypothesis test is the probability that your sample data would have occurred if you hypothesis were not correct. Traditionally, researchers have used a p-value of 0.05 (a 5% probability that your sample data would have occurred if your hypothesis was wrong) as the threshold for declaring that a hypothesis is true.
Hypothesis testing is an act in statistics whereby an analyst tests an assumption regarding a population parameter. The methodology employed by the analyst depends on the nature of the data used ...
Hypothesis testing Clin Nurse Spec. 1996 Jul;10(4):186-8. doi: 10.1097/00002800-199607000-00009. Author H N Yarandi. PMID: 8900794 DOI: 10.1097/00002800-199607000-00009 Abstract Hypothesis testing is the process of making a choice between two conflicting hypotheses. ... Nursing Research Reproducibility of Results ...
The research methods you use depend on the type of data you need to answer your research question. If you want to measure something or test a hypothesis, use quantitative methods. If you want to explore ideas, thoughts and meanings, use qualitative methods. If you want to analyze a large amount of readily-available data, use secondary data.
Hypothesis testing is a systematic procedure for deciding whether the results of a research study support a particular theory which applies to a population. Hypothesis testing uses sample data to evaluate a hypothesis about a population.
The interplay between different uses of woody plants remains underexplored, obscuring our understanding of how a plant's value for one purpose might shield it from other, more harmful uses. This study examines the protection hypothesis by determining if food uses can protect woody plants (trees and shrubs) from wood uses. We approached the hypothesis from two distinct possibilities: (1) the ...